Appendix 1: Description of the weighted compositional regression
advertisement

Appendix 1: Description of the weighted compositional regression method for projection of multi-category BMI
prevalence, including estimation of prediction intervals, goodness of fit and sensitivity analyses
Each step of the weighted compositional projection method will be described in this Appendix. Vector and matrix
notation will be used when possible for conciseness, and familiarity with standard multivariate regression and GLS
(generalized least squares) estimation theory is presumed.
1. Construct measured BMI prevalence compositions and covariance matrix time series from survey data
Let 𝑃̅𝑗𝑘 (𝑡) = {𝑃𝑖𝑗𝑘 (𝑡), 𝑖 = 0 … 3} be the set of 4 BMI prevalences specific age group ′𝑗′, sex ′𝑘′ and measured from
survey timepoint ′𝑡′; the index ′𝑖′ corresponds to BMI category. 𝑃̅𝑗𝑘 (𝑡) is said to form a 4-dimensional ‘composition’
(Aitchison J 1986; Mills T 2009). Let 𝑉̿𝑗𝑘 (𝑡) be the 4x4 measured covariance matrix of 𝑃̅𝑗𝑘 (𝑡). The diagonal elements
of 𝑉̿𝑗𝑘 (𝑡) represent the variances of the prevalences of each BMI category, while the off-diagonal elements represent
the covariances between different BMI categories. In the current study, time series in 𝑃̅𝑗𝑘 (𝑡) and 𝑉̿𝑗𝑘 (𝑡) comprise 14
survey cycles corresponding to timepoints 𝑡 ∈ (1987, 1992.5, 1994.5, 1996.5, 1998, 1998.5, 2000.5, 2002, 2003,
2005, 2007, 2008, 2009, 2010).
2. Transformation of 4-dimensional prevalence compositions to 3-dimensional real space
Statistical modelling or analyses of 𝑃̅𝑗𝑘 (𝑡) must account for its particular numerical properties that include bounded
support (each prevalence component is bounded between 0 and 1), positivity (prevalence components cannot be
negative), summation constraint (∑3𝑖=0 𝑃𝑖𝑗𝑘 (𝑡) = 1), and correlation between the components (including but not
limited to, the effect of the common denominator). As shown by Aitchison (1986) and Aitchison and Shen (1980)
(Aitchison J & Shen SM 1980; Aitchison J 1986), if 𝑃̅𝑗𝑘 (𝑡) has a multivariate logistic-normal distribution, the additive
log-ratio transformation, 𝑦̅𝑗𝑘 (𝑡) = 𝑎𝑙𝑟 (𝑃̅𝑗𝑘 (𝑡)), can be applied to map 𝑃̅𝑗𝑘 (𝑡) to a 3-dimensional real space such that
𝑦̅𝑗𝑘 (𝑡) is multivariate normal. The wide range of inference tools developed for multivariate normal data (including
multivariate regression) can then be applied to 𝑦̅𝑗𝑘 (𝑡); results are then backtransformed to recover the original
prevalence space. This compositional approach has distinct advantages over the use of simple linear regression; the
latter method can result in biased projection estimates (Mills T 2009) as well as estimated values that violate the
numerical properties described.
The alr-transformation is shown below:
̅𝒋𝒌 (𝒕) = {𝒚𝒊𝒋𝒌 (𝒕), 𝒊 = 𝟏 … 𝟑} = {𝒍𝒐𝒈 (
𝒚
𝑷𝒊𝒋𝒌 (𝒕)
) , 𝒊 = 𝟏 … 𝟑}
𝟏 − ∑𝟑𝒊=𝟏 𝑷𝒊𝒋𝒌 (𝒕)
The prevalence component 𝑃0𝑗𝑘 (𝑡) is termed the ‘fill-up’ value and was assigned to the underweight BMI category;
however the results of the analysis are in fact invariant to the choice of category for 𝑃0𝑗𝑘 (𝑡) (Aitchison J 1982).
3. Calculation of the transformed covariance matrices
̿𝑗𝑘 (𝑡) = 𝑉𝑎𝑟 (𝑦̅𝑗𝑘 (𝑡)) denote the 3x3 covariance matrix of the transformed BMI composition corresponding to
Let Ω
̿𝑗𝑘 (𝑡) is estimated from 𝑉̿𝑗𝑘 (𝑡) using the delta method:
age category ′𝑗′, sex ′𝑘′ and timepoint ′𝑡′. Ω
𝜕𝑦̅ (𝑡)
𝜕𝑦̅ (𝑡)
̿𝑗𝑘 (𝑡) = ( 𝑗𝑘 ) 𝑉̿𝑗𝑘 (𝑡) ( 𝑗𝑘 )
Ω
𝜕𝑃̅𝑗𝑘 (𝑡)
𝜕𝑃̅𝑗𝑘 (𝑡)
𝑇
4. Projection analysis using weighted multivariate regression
1
Multivariate regression is used to fit and extrapolate trends in 𝑦̅𝑗𝑘 (𝑡):
̿
𝑦̿𝑗𝑘 = 𝑋̿𝛽𝑗𝑘
For the current study 𝑦̿𝑗𝑘 is the 14x3 matrix representing the time series in each component of 𝑦̅𝑗𝑘 (𝑡), 𝑋̿ is the 14x2
̿ is the 2x3 matrix of regression coefficients. To
covariate matrix consisting of intercept and time columns, and 𝛽𝑗𝑘
account for the covariance matrix unique to each survey timepoint, the preceding regression equation is reduced to
a univariate form by ‘stacking’ the matrix terms (Jobson JD 1991):
∗
̅∗ ,
𝑦̅𝑗𝑘
= 𝑋̿ ∗ 𝛽𝑗𝑘
∗ ̿∗
̅ ∗ are the corresponding 42x1, 42x6 and 6x1 stacked matrices.
where 𝑦̅𝑗𝑘
, 𝑋 and 𝛽𝑗𝑘
The regression coefficients can then be estimated using the standard GLS estimator (Kutner M et al. 2005):
∗−1 ̿ ∗ ̿ ∗𝑇 ̿ ∗−1 ∗
∗
̅ ∗ = (𝑋̿ ∗𝑇 Ω
̿𝑗𝑘
̿𝑗𝑘
𝛽𝑗𝑘
𝑋 )𝑋 Ω𝑗𝑘 𝑦̅𝑗𝑘 , where Ω
is the ‘stacked’ covariance matrix that includes the transformed
covariances for all 14 timepoints.
5. Estimation of projected prevalence
The projection estimate for future time 𝑡′ ∈ (2011, 2012, … , 2030) is determined by extrapolation of the regression
model, for example using the stacked notation:
∗
̅∗ ,
𝑦𝑗𝑘 (𝑡 ′ ) = 𝑦̅𝑗𝑘
= 𝑥̿ ∗ 𝛽𝑗𝑘
where 𝑥̿ ∗ is a 3x6 matrix that specifies the intercept and particular future time 𝑡 ′ for each component of 𝑦𝑗𝑘 (𝑡 ′ ).
Backtransformation 𝑃̅𝑗𝑘 (𝑡 ′ ) = 𝑎𝑙𝑟 −1 (𝑦̅𝑗𝑘 (𝑡 ′ )) is used to recover the projected BMI prevalences. The back
transformation equations are shown below:
𝑃𝑖𝑗𝑘
(𝑡 ′ )
=
𝑃0𝑗𝑘 (𝑡 ′ ) =
𝑒𝑥𝑝 (𝑦𝑖𝑗𝑘 (𝑡 ′ ))
1 − ∑3𝑖=1 𝑒𝑥𝑝 (𝑦𝑖𝑗𝑘 (𝑡 ′ ))
, for 𝑖 = 1 … 3
1
1 − ∑3𝑖=1 𝑒𝑥𝑝 (𝑦𝑖𝑗𝑘 (𝑡 ′ ))
References
Aitchison J 1982. The Statistical Analysis of Compositional Data. J. R. Statist. Soc. B 44: 139-177.
Aitchison J 1986. The Statistical Analysis of Compositional Data. Chapman and Hall, London.
Aitchison J and Shen SM 1980. Logistic-normal distributions: Some properties and uses. Biometrika 67: 261.
Jobson JD 1991. Applied Multivariate Data Analysis: Regression and Experimental Design, Volume 1. Springer-Verlag.
Kutner M, Nachtsheim C, Neter J, and Li W 2005. Applied Linear Statistical Models. Fifth ed. McGraw-Hill Irwin, New
York.
Mills T 2009. Forecasting obesity trends in England. J. R. Statist. Soc. A 172, Part 1: 107-117.
2
Appendix 2: Prediction Intervals, Goodness of Fit and Sensitivity Analyses
1. Estimation of Prediction Intervals
The prediction variance of a projected BMI prevalence at time 𝑡 ′ is the sum of variance in estimated mean response
and future measurement error (Kutner M et al. 2005): 𝑝𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )) = 𝑒𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )) + 𝑚𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )), where
the prevalence specific to BMI category ′𝑖′, age group ′𝑗′, sex ′𝑘′ and measured from survey timepoint ′𝑡′ is
considered.
The covariance matrix of the estimated mean value of 𝑦̅𝑗𝑘 at future time 𝑡 ′ (represented by 𝑥̿ ∗ ) is calculated using
̅∗ ) =
̿𝑗𝑘 (𝑡 ′ ) = 𝑥̿ ∗ 𝑉̿𝛽∗ 𝑥̿ ∗𝑇 , where 𝑉̿𝛽∗ = 𝑉𝑎𝑟(𝛽𝑗𝑘
standard GLS (generalized least squares) theory: 𝑉𝑎𝑟 (𝑦̅𝑗𝑘 (𝑡 ′ )) = Ω
−1
∗−1 ̿ ∗
̿𝑗𝑘
𝑋 )
(𝑋̿ ∗𝑇 Ω
is the covariance matrix of the estimated regression coefficients. The covariance matrix of the
corresponding backtransformed prevalence composition at time 𝑡 ′ , is then estimated using the delta method:
′
̅
′
̅
𝑇
𝜕𝑃𝑗𝑘 (𝑡 )
̿𝑗𝑘 (𝑡 ′ ) (𝜕𝑃𝑗𝑘 (𝑡 ′ )) . The variance in estimated mean response, 𝑒𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )),
𝑉𝑎𝑟 (𝑃̅𝑗𝑘 (𝑡 ′ )) = 𝑉̿𝑗𝑘 (𝑡 ′ ) = (𝜕𝑦̅ (𝑡 ′ )) Ω
𝜕𝑦̅ (𝑡 )
𝑗𝑘
𝑗𝑘
is obtained from the diagonal elements of 𝑉𝑎𝑟 (𝑃̅𝑗𝑘 (𝑡 ′ )).
𝑚𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )) is estimated by the variance structure of the 2010 CCHS, under the approximation that the survey
design and sampling size of a future survey at time 𝑡 ′ will be similar: 𝑚𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )) ≈ 𝑉𝑎𝑟 (𝑃𝑖𝑗𝑘 (t =2010)).
The prediction intervals for the projected prevalence of BMI category ′𝑖 ′ , age category ′𝑗′, sex ′𝑘′ at future time ′𝑡 ′ ′
are then estimated using a Normal approximation, by: 𝑃𝑖𝑗𝑘 (𝑡 ′ ) ± 1.96 × √𝑒𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )) + 𝑚𝑉𝑎𝑟(𝑃𝑖𝑗𝑘 (𝑡 ′ )).
Prediction intervals represent estimates of the statistical uncertainty caused by variability in the measured data and
the model estimation process. Prediction intervals in projection analyses are always underestimates of the actual
error since they do not account for the structural error component, and thus they should not be interpreted as
reliable bounds on estimated future values (Hakulinen et al. 1986; Moller et al. 2005). Prediction intervals are useful
however for indicating the statistical stability of the projection model as well as providing a lower bound on the
actual error. Prediction intervals for age aggregated BMI prevalence projections are shown in Figure A2 below.
3
Figure A2 Projections (2011 to 2030) of age-aggregated prevalence by BMI category, for men and women. The
linear scenario is indicated by the black line (―), the deceleration scenario is indicated by the gray line (―), and
the historical BMI time series data are indicated by the open circles (○). The dotted black (…) and gray (…) lines
indicate prediction intervals for the linear and deceleration scenarios. The blue (―) and red (―) lines indicate the
sensitivity analysis results for the linear and deceleration scenarios.
4
2. Goodness of Fit
Visual Assessment
Both linear and log models appeared to fit the age-aggregated (Figure 1 of the main text) and age-category specific
(Appendix 4) measured prevalence trends well. The fitted models followed trends that were clearly apparent in the
measured data, and residuals did not indicate the presence of any systematic bias.
Quantitative Assessment
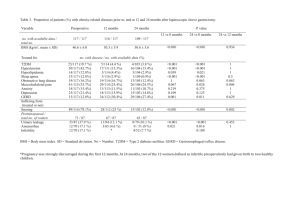
2
Buse 1973 (Buse A 1973) derived the 𝑅𝐺𝐿𝑆
statistic to assess goodness of fit for a GLS model that accounts for the
weighting matrix in computing the residual sums of squares and the mean response:
𝑇
(𝑌 − 𝑌̂) 𝑉 −1 (𝑌 − 𝑌̂)
=1−
,
(𝑌 − 𝑌̅𝑒)𝑇 𝑉 −1 (𝑌 − 𝑌̅𝑒)
where 𝑉 −1 is the weighting matrix, 𝑒 𝑇 = (1, … ,1), and 𝑌̅ is the weighted mean of the response variable: 𝑌 =
2
𝑅𝐺𝐿𝑆
𝑒 𝑇 𝑉 −1 𝑌
.
𝑒 𝑇 𝑉 −1 𝑒
2
This measure is analogous to the OLS (ordinary least squares) 𝑅𝑂𝐿𝑆
, and measures the proportion of the
2
2
generalized sums of squares attributable to the regression model. 𝑅𝐺𝐿𝑆
ranges from 0 to 1 and reduces to the 𝑅𝑂𝐿𝑆
2
when the weighting matrix is identity. 𝑅𝐺𝐿𝑆
was computed for each of the eight age by sex regression analyses, and
for both linear and deceleration scenarios, as shown in Table A2.1 below. All values were found to be > 0.96
indicating goodness of fit.
Table A2.1
However as each regression analysis comprises fitting to all 3 transformed BMI categories simultaneously, this can
2
lead to large and uninformative values of 𝑅𝐺𝐿𝑆
as the between BMI category variation can mask within BMI category
2
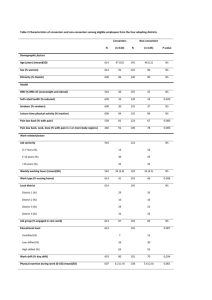
variation. Thus 𝑅𝐺𝐿𝑆 was further applied to assess goodness of fit within the obese BMI category only, using subsets
of the measured and fitted backtransformed data and covariance matrices. Results are shown in Table A2.2 below.
2
It can be seen that 𝑅𝐺𝐿𝑆
> 0.6 for fitted obesity trends in all age and sex categories, except for 18-24 year old women.
2
As can be seen in Appendix 3, Figure A3.1 however, the low values of 𝑅𝐺𝐿𝑆
for this stratum are due to the ‘flatness’
of the obesity trend and consequent low percentage of variability explained by the fitted trend, rather than poor
goodness of fit.
Table A2.2
5
3. Sensitivity Analyses
Sensitivity analyses were performed to assess the robustness and validity of the projection results. These analyses
comprised estimations of projected age-aggregated prevalence trends that used only the seven CCHS general health
surveys from 2000-2001 to 2010. The purpose of the analyses was to assess primarily if projected trends might
change if only the more recent historical data were used, and thus if the older historical data might be exerting
undue influence on the projections. The analysis was further used to examine if additional stabilisation or ‘levellingoff’ in recent obesity prevalence trends might be present, as well as if the analysis of a more homogeneous time
series might yield different results.
Results of the sensitivity analyses are shown superimposed on projection results, in Figure A2. It can be concluded
that the projection results are robust to the use of more recent historical data. Projected trends using the data
subset follow the full dataset projections. In particular, the projected obesity prevalence spanned by the linear and
deceleration scenarios using the data subset lie within the span projected by the full dataset, for both men and
women.
References
Buse A 1973. Goodness of Fit in Generalized Least Squares Estimation. The American Statistician 27: 106-108.
Hakulinen,T., Teppo,L., and Saxen,E. 1986. Do the predictions for cancer incidence come true? Experience from
Finland. Cancer. 57: 2454-2458.
Kutner M, Nachtsheim C, Neter J, and Li W 2005. Applied Linear Statistical Models. Fifth ed. McGraw-Hill Irwin, New
York.
Moller,B., Weedon-Fekjaer,H., and Haldorsen,T. 2005. Empirical evaluation of prediction intervals for cancer
incidence. BMC. Med Res Methodol. 5: 21.
6
Appendix 3: Projection of type 2 diabetes: (1) separation of epidemiologic and demographic components, and (2)
survey estimates of BMI, age and sex-specific prevalence of type 2 diabetes
1. Separation of epidemiologic and demographic components
As described in the Methods (Projected impact of BMI on chronic disease prevalence) section of the manuscript, the
projected BMI, age and sex specific numbers of cases of type 2 diabetes (𝜂𝑖𝑗𝑘 (𝑡)) is equal to the product of the type
2 diabetes prevalence in 2009-2010 (𝜋𝑖𝑗𝑘 ) and projected numbers of individuals (𝑁𝑖𝑗𝑘 (𝑡)) corresponding to the same
category. 𝑁𝑖𝑗𝑘 (𝑡) itself is the product of the projected BMI prevalence (𝑃𝑖𝑗𝑘 (𝑡)) and population (𝑛𝑗𝑘 (𝑡)). Thus,
𝜂𝑖𝑗𝑘 (𝑡) = 𝜋𝑖𝑗𝑘 × 𝑁𝑖𝑗𝑘 (𝑡) = 𝜋𝑖𝑗𝑘 × 𝑃𝑖𝑗𝑘 (𝑡) × 𝑛𝑗𝑘 (𝑡)
Total projected numbers of cases (𝜂𝑘 (𝑡)) and prevalence (𝜋𝑘 (𝑡)) by sex is obtained by aggregation over BMI and age
categories as was described in the main manuscript (Methods, Projected impact of BMI on chronic disease
prevalence). The equations for 𝜂𝑘 (𝑡) and 𝜋𝑘 (𝑡) are shown below, showing the respective dependence of these
quantities on BMI prevalence (termed the epidemiologic component) and population projections (the demographic
component):
𝜂𝑘 (𝑡) = ∑ 𝜋𝑖𝑗𝑘 × 𝑃𝑖𝑗𝑘 (𝑡) × 𝑛𝑗𝑘 (𝑡)
𝑖,𝑗
𝜋𝑘 (𝑡) =
1
∑ 𝜋𝑖𝑗𝑘 × 𝑃𝑖𝑗𝑘 (𝑡) × 𝑛𝑗𝑘 (𝑡)
𝑛𝑘 (𝑡)
𝑖,𝑗
Estimation of the demographic contribution to type 2 diabetes numbers (𝜂𝑘 (𝑡)) and prevalence (𝜋𝑘 (𝑡)) is done by
holding the age and sex specific BMI prevalences at a fixed reference level 𝑃𝑖𝑗𝑘 (𝑡𝑟𝑒𝑓 ) and allowing only the
population to evolve. Thus:
𝑑𝑒𝑚𝑜
(𝑡) = ∑ 𝜋𝑖𝑗𝑘 × 𝑃𝑖𝑗𝑘 (𝑡𝑟𝑒𝑓 ) × 𝑛𝑗𝑘 (𝑡)
𝜂𝑘𝑑𝑒𝑚𝑜 (𝑡) = ∑ 𝜂𝑖𝑗𝑘
𝑖,𝑗
𝑖,𝑗
1
1
𝑑𝑒𝑚𝑜
(𝑡) =
𝜋𝑘𝑑𝑒𝑚𝑜 (𝑡) =
∑ 𝜂𝑖𝑗𝑘
∑ 𝜋𝑖𝑗𝑘 × 𝑃𝑖𝑗𝑘 (𝑡𝑟𝑒𝑓 ) × 𝑛𝑗𝑘 (𝑡)
𝑛𝑘 (𝑡)
𝑛𝑘 (𝑡)
𝑖,𝑗
𝑖,𝑗
The epidemiologic contribution (due to BMI related change) is estimated by subtracting the demographic effect from
the overall trends for both numbers and prevalence. Thus
𝑒𝑝𝑖
𝜂𝑘 (𝑡) = 𝜂𝑘 (𝑡) − 𝜂𝑘𝑑𝑒𝑚𝑜 (𝑡)
𝑒𝑝𝑖
𝜋𝑘 (𝑡) = 𝜋𝑘 (𝑡) − 𝜋𝑘𝑑𝑒𝑚𝑜 (𝑡)
𝑒𝑝𝑖
𝜋𝑘 (𝑡) can be interpreted as the component of change in prevalence amenable to intervention on population BMI,
𝑒𝑝𝑖
and 𝜂𝑘 (𝑡) as the estimated number of avoidable cases of type 2 diabetes.
7
2. 2009-2010 cross-sectional survey estimates of BMI, age and sex-specific prevalence of type 2 diabetes
In the current projections, the BMI, age and sex specific prevalence of type 2 diabetes (𝜋𝑖𝑗𝑘 ) is estimated from the
2009-2010 Canadian Community Health Survey (CCHS), and is assumed to remain constant over the projected time
horizon.
Figures A3a and A3b show plots of the values of 𝜋𝑖𝑗𝑘 for men and women respectively. BMI categories are indicated
on the x-axis and the age categories are represented by separate curves. The marked increase in type 2 diabetes
prevalence with BMI can be seen by the upward trends in the curves for both men and women. There is also a
substantial increase in prevalence with age, as shown by the separation of the different curves in both plots. Thus it
is expected that increasing BMI and population aging will likely combine to drive projected future increases in type 2
diabetes prevalence.
Figure A3, Type 2 diabetes prevalence vs. BMI plotted by age, for (a) Men and (b) Women.
8
Appendix 4: Age-specific BMI prevalence projections
Figure A4.1, Projections of obesity prevalence by age category and sex for men and women. The linear scenario is
indicated by the black line (―), the deceleration scenario is indicated by the gray line (―), and the historical BMI
time series data are indicated by the open circles (○). The dotted black (…) and gray (…) lines indicate prediction
intervals for the linear and deceleration scenarios.
9
Figure A4.2, Projections of overweight prevalence by age category and sex for men and women. The linear
scenario is indicated by the black line (―), the deceleration scenario is indicated by the gray line (―), and the
historical BMI time series data are indicated by the open circles (○). The dotted black (…) and gray (…) lines
indicate prediction intervals for the linear and deceleration scenarios.
10
Figure A4.3, Projections of normal weight prevalence by age category and sex for men and women. The linear
scenario is indicated by the black line (―), the deceleration scenario is indicated by the gray line (―), and the
historical BMI time series data are indicated by the open circles (○). The dotted black (…) and gray (…) lines
indicate prediction intervals for the linear and deceleration scenarios.
11
Figure A4.4, Projections of underweight prevalence by age category and sex for men and women. The linear
scenario is indicated by the black line (―), the deceleration scenario is indicated by the gray line (―), and the
historical BMI time series data are indicated by the open circles (○). The dotted black (…) and gray (…) lines
indicate prediction intervals for the linear and deceleration scenarios.
12