File
advertisement

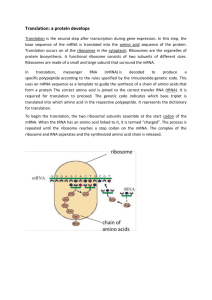
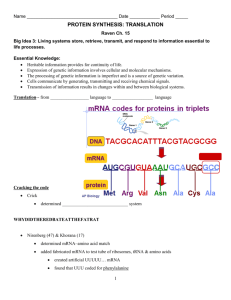
Translation (biology) From Wikipedia, the free encyclopedia Jump to: navigation, search Overview of the translation of eukaryotic messenger RNA Diagram showing the translation of mRNA and the synthesis of proteins by a ribosome 1 According to the Central dogma of molecular biology, "DNA makes RNA makes protein." Translation is the process by which RNA makes protein. In the cell, DNA makes messenger RNA (mRNA). mRNA travels to the ribosome which reads its sequence and makes protein coded to that sequence. In molecular biology and genetics, translation is the third stage of protein biosynthesis (part of the overall process of gene expression). In translation, messenger RNA (mRNA) produced by transcription is decoded by the ribosome to produce a specific amino acid chain, or polypeptide, that will later fold into an active protein. In bacteria, translation occurs in the cell's cytoplasm, where the large and small subunits of the ribosome are located, and bind to the mRNA. In eukaryotes, translation occurs across the membrane of the endoplasmic reticulum in a process called vectorial synthesis. The ribosome facilitates decoding by inducing the binding of tRNAs with complementary anticodon sequences to that of the mRNA. The tRNAs carry specific amino acids that are chained together into a polypeptide as the mRNA passes through and is "read" by the ribosome in a fashion reminiscent to that of a stock ticker and ticker tape. In many instances, the entire ribosome/mRNA complex bind to the outer membrane of the rough endoplasmic reticulum and release the nascent protein polypeptide inside for later vesicle transport and secretion outside of the cell. Many types of transcribed RNA, such as transfer RNA, ribosomal RNA, and small nuclear RNA, do not undergo translation into proteins. Translation proceeds in four phases: initiation, elongation, translocation and termination (all describing the growth of the amino acid chain, or polypeptide that is the product of translation). Amino acids are brought to ribosomes and assembled into proteins. In activation, the correct amino acid is covalently bonded to the correct transfer RNA (tRNA). The amino acid is joined by its carboxyl group to the 3' OH of the tRNA by an ester bond. When the tRNA has an amino acid linked to it, it is termed "charged". Initiation involves the small subunit of the ribosome binding to the 5' end of mRNA with the help of initiation factors (IF). Termination of the polypeptide happens when the A site of the ribosome faces a stop codon (UAA, UAG, or UGA). No tRNA can recognize or bind to this codon. Instead, the stop codon induces the binding of a release factor protein that prompts the disassembly of the entire ribosome/mRNA complex. A number of antibiotics act by inhibiting translation; these include anisomycin, cycloheximide, chloramphenicol, tetracycline, streptomycin, erythromycin, and puromycin, among others. Prokaryotic ribosomes have a different structure from that of eukaryotic ribosomes, and thus antibiotics can specifically target bacterial infections without any detriment to a eukaryotic host's cells. Contents 1 Basic mechanisms 2 Genetic code o 2.1 Translation tables 2 3 See also 4 References 5 Further reading 6 External links Basic mechanisms Further information: Prokaryotic translation and Eukaryotic translation A ribosome translating a protein that is secreted into the endoplasmic reticulum. tRNAs are colored dark blue. Tertiary structure of tRNA. CCA tail in orange, Acceptor stem in purple, D arm in red, Anticodon arm in blue with Anticodon in black, T arm in green. The basic process of protein production is addition of one amino acid at a time to the end of a protein. This operation is performed by a ribosome. The choice of amino acid type to add is determined by an mRNA molecule. Each amino acid added is matched to a three nucleotide subsequence of the mRNA. For each such triplet possible, only one particular amino acid type is 3 accepted. The successive amino acids added to the chain are matched to successive nucleotide triplets in the mRNA. In this way the sequence of nucleotides in the template mRNA chain determines the sequence of amino acids in the generated amino acid chain.[1] Addition of an amino acid occurs at the C-terminus of the peptide and thus translation is said to be amino-tocarboxyl directed.[2] The mRNA carries genetic information encoded as a ribonucleotide sequence from the chromosomes to the ribosomes. The ribonucleotides are "read" by translational machinery in a sequence of nucleotide triplets called codons. Each of those triplets codes for a specific amino acid. The ribosome molecules translate this code to a specific sequence of amino acids. The ribosome is a multisubunit structure containing rRNA and proteins. It is the "factory" where amino acids are assembled into proteins. tRNAs are small noncoding RNA chains (74-93 nucleotides) that transport amino acids to the ribosome. tRNAs have a site for amino acid attachment, and a site called an anticodon. The anticodon is an RNA triplet complementary to the mRNA triplet that codes for their cargo amino acid. Aminoacyl tRNA synthetase (an enzyme) catalyzes the bonding between specific tRNAs and the amino acids that their anticodon sequences call for. The product of this reaction is an aminoacyltRNA molecule. This aminoacyl-tRNA travels inside the ribosome, where mRNA codons are matched through complementary base pairing to specific tRNA anticodons. The ribosome has three sites for tRNA to bind. They are the aminoacyl site (abbreviated A), the peptidyl site (abbreviated P) and the exit site (abbreviated E). With respect to the mRNA, the three sites are oriented 5’ to 3’ E-P-A, because ribosomes moves toward the 3' end of mRNA. The A site binds the incoming tRNA with the complementary codon on the mRNA. The P site holds the tRNA with the growing polypeptide chain. The E site holds the tRNA without its amino acid. When an aminoacyl-tRNA initially binds to its corresponding codon on the mRNA, it is in the A site. Then, a peptide bond forms between the amino acid of the tRNA in the A site and the amino acid of the charged tRNA in the P site. The growing polypeptide chain is transferred to the tRNA in the A site. Translocation occurs, moving the tRNA in the P site, now without an amino acid, to the E site; the tRNA that was in the A site, now charged with the polypeptide chain, is moved to the P site. The tRNA in the E site leaves and another aminoacyl-tRNA enters the A site to repeat the process.[3] After the new amino acid is added to the chain, the energy provided by the hydrolysis of a GTP bound to the translocase EF-G (in prokaryotes) and eEF-2 (in eukaryotes) moves the ribosome down one codon towards the 3' end. The energy required for translation of proteins is significant. For a protein containing n amino acids, the number of high-energy phosphate bonds required to translate it is 4n-1[citation needed]. The rate of translation varies; it is significantly higher in prokaryotic cells (up to 17-21 amino acid residues per second) than in eukaryotic cells (up to 6-9 amino acid residues per second).[4] Genetic code Main article: Genetic code 4 Whereas other aspects such as the 3D structure, called tertiary structure, of protein can only be predicted using sophisticated algorithms, the amino acid sequence, called primary structure, can be determined solely from the nucleic acid sequence with the aid of a translation table. This approach may not give the correct amino acid composition of the protein, in particular if unconventional amino acids such as selenocysteine are incorporated into the protein, which is coded for by a conventional stop codon in combination with a downstream hairpin (SElenoCysteine Insertion Sequence, or SECIS). There are many computer programs capable of translating a DNA/RNA sequence into a protein sequence. Normally this is performed using the Standard Genetic Code; many bioinformaticians have written at least one such program at some point in their education. However, few programs can handle all the "special" cases, such as the use of the alternative initiation codons. For instance, the rare alternative start codon CTG codes for Methionine when used as a start codon, and for Leucine in all other positions. Example: Condensed translation table for the Standard Genetic Code (from the NCBI Taxonomy webpage). AAs Starts Base1 Base2 Base3 = = = = = FFLLSSSSYY**CC*WLLLLPPPPHHQQRRRRIIIMTTTTNNKKSSRRVVVVAAAADDEEGGGG ---M---------------M---------------M---------------------------TTTTTTTTTTTTTTTTCCCCCCCCCCCCCCCCAAAAAAAAAAAAAAAAGGGGGGGGGGGGGGGG TTTTCCCCAAAAGGGGTTTTCCCCAAAAGGGGTTTTCCCCAAAAGGGGTTTTCCCCAAAAGGGG TCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAG Translation tables Even when working with ordinary eukaryotic sequences such as the Yeast genome, it is often desired to be able to use alternative translation tables—namely for translation of the mitochondrial genes. Currently the following translation tables are defined by the NCBI Taxonomy Group for the translation of the sequences in GenBank: 1: The Standard 2: The Vertebrate Mitochondrial Code 3: The Yeast Mitochondrial Code 4: The Mold, Protozoan, and Coelenterate Mitochondrial Code and the Mycoplasma/Spiroplasma Code 5: The Invertebrate Mitochondrial Code 6: The Ciliate, Dasycladacean and Hexamita Nuclear Code 9: The Echinoderm and Flatworm Mitochondrial Code 10: The Euplotid Nuclear Codecbn dxh 11: The Bacterial and Plant Plastid Code 12: The Alternative Yeast Nuclear Code 13: The Ascidian Mitochondrial Code 14: The Alternative Flatworm Mitochondrial Code 15: Blepharisma Nuclear Code 16: Chlorophycean Mitochondrial Code 21: Trematode Mitochondrial Code 22: Scenedesmus obliquus mitochondrial Code 23: Thraustochytrium Mitochondrial Code 5 See also DNA codon table Expanded genetic code Protein methods References 1. ^ Neill, Campbell (1996). Biology; Fourth edition. The Benjamin/Cummings Publishing Company. p. 309,310. ISBN 0-8053-1940-9. 2. ^ Stryer, Lubert (2002). Biochemistry; Fifth edition. W. H. Freeman and Company. p. 826. ISBN 0-7167-4684-0. 3. ^ Griffiths, Anthony (2008). "9". Introduction to Genetic Analysis (9th ed.). New York: W.H. Freeman and Company. pp. 335–339. ISBN 978-0-7167-6887-6. 4. ^ Ross JF, Orlowski M (February 1982). "Growth-rate-dependent adjustment of ribosome function in chemostat-grown cells of the fungus Mucor racemosus". J. Bacteriol. 149 (2): 650–3. PMC 216554. PMID 6799491. Further reading Champe, Pamela C; Harvey, Richard A; Ferrier, Denise R (2004). Lippincott's Illustrated Reviews: Biochemistry (3rd ed.). Hagerstwon, MD: Lippincott Williams & Wilkins. ISBN 0-7817-2265-9. Cox, Michael; Nelson, David R.; Lehninger, Albert L (2005). Lehninger principles of biochemistry (4th ed.). San Francisco...: W.H. Freeman. ISBN 0-7167-4339-6. Malys N, McCarthy JEG (2010). "Translation initiation: variations in the mechanism can be anticipated". Cellular and Molecular Life Sciences 68 (6): 991–1003. doi:10.1007/s00018-010-0588-z. PMID 21076851. 6