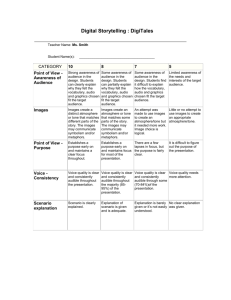
The second chunk of the program has just been completed. The library of
code I am using comes with a demo app which generates tones by pressing keys
on a keypad, and then recognizing them and decoding the character from the
generated audio. In this section I have used the code behind the keypad tone
generator to convert any given string to a sequence tones. Under the hood there
is a lot of code converting things like hashtags to dots and vice versa, as I have not
changed the actual number protocol from DTMF(phone). The code in its current
state is rather messy and generally awkward but functions nonetheless(I will clean
this up as I wrap up the project). Currently I am able to generate and decode a
tone every 34ms which equates to about 29.411 baud… To say the least pretty
bad. However it does work and is relatively stable. Also while programming this I
ran into an issue with audio generation and decoding not being in sync and
creating duplicate characters. I fixed this by measuring the time in MS that the
tone is generated by dividing the audio sample count, then adding a delay to my
decoding loop and an iterator to keep things in sync. So basically my program
generates a tone, waits 34ms for the tone to generate and play, and then decodes
it. This results in a bit of audio stutter with each tone played but it’s functional
regardless. And before I explain how all this works I noticed an interesting quirk
where certain frequency combinations yield different recognition times by the
algorithm. Anyway now I’ll give a basic run-down on how it works.
1. An input string is taken using a basic scanner.
2. The string is encrypted using the same class as the chat program(with a
predefined password for now).
3. The returned double list is converted to a list of chars; meanwhile replacing
each ‘.’ And space with a ‘*’ and ‘#’ respectively.
4. A loop calls a method for each character in the array which generates a
tone, converts that tone to a float buffer, and then forks off that float
buffer to an audio player and decoding method. The decoder loops each
detected character into a string until the original loop is done calling the
generator.
5. The string gets basically reversed steps 2 and 3. It’s turned back to a list of
doubles and decoded.
6. Finally the result prints.
So on the user-end a message asks to input text, and after input the tones begin
generating, and all detected characters are printed and once the audio stops the
decoded lines are printed out. So far I am quite satisfied with my progress and the
next step will be to decode from grabbed audio not just a direct buffer pass.
 0
0