The Weather Turbulence
advertisement

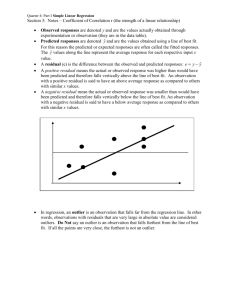
Algebra 1 Summer Institute 2014 The Weather Turbulence The National Climate Data Center collects data on weather conditions at various locations. They classify each day as clear, partly cloudy, or cloudy. Using data taken over a number of years, they provide data on the following variables: 𝐱 = elevation above sea level (in feet) 𝐲 = mean number of clear days per year 𝐰= mean number of partly cloudy days per year 𝐳 = mean number of cloudy days per year Could a city’s elevation above sea level be used to predict the number of clear, partly cloudy, or cloudy days per year a city experiences? After observing a scatter plot of the data, linear models (or the least-squares linear model obtained from a calculator or computer software) can provide a reasonable description of the relationship between these two variables. The linear model will be evaluated by considering how close the data points are to the corresponding graph of the line. The equation of the linear model will be used to answer the statistical question. We will mostly concentrate on the associating between elevation and the number of clear days. The table below shows data for 14 U.S. cities City Albany, NY Albuquerque, NM Anchorage, AK Boise, ID Boston, MA Helena, MT Lander, WY Milwaukee, WI New Orleans, LA Raleigh, NC Rapid City, SD Salt Lake City, 69 𝐰= Mean Number of Partly Cloudy Days per Year 111 𝐳= Mean Number of Cloudy Days per Year 185 5,311 167 111 87 114 2,838 15 3,828 5,557 672 40 120 98 82 114 90 60 90 103 104 122 100 265 155 164 179 129 175 4 101 118 146 434 3,162 4,221 111 111 125 106 115 101 149 139 139 𝐱= Elevation Above Sea Level (ft.) 𝐲 = Mean Number of Clear Days per Year 275 1 Algebra 1 Summer Institute 2014 UT Spokane, WA Tampa, FL 2,356 19 86 101 88 143 191 121 Data Source: http://www.ncdc.noaa.gov/oa/climate/online/ccd/cldy.html 1. Work in groups of two. Create a scatter plot in Excel or GeoGebra of the data on elevation and mean number of clear days. 2. Do you see a pattern in the scatter plot, or does it look like the data points are scattered? 3. How would you describe the relationship between elevation and mean number of clear days for these 14 cities? That is, does the mean number of clear days tend to increase as elevation increases, or does the mean number of clear days tend to decrease as elevation increases? 4. Do you think that a straight line would be a good way to describe the relationship between the mean number of clear days and elevation? Why do you think this? 2 Algebra 1 Summer Institute 2014 We have noticed that the pattern is not very strong. How strong or weak is it? We will look at a number, correlation coefficient, used when we suspect a linear association between patterns called the Pearson product-moment coefficient that can measure the strength between two variables. Generally, the correlation coefficient of a sample is denoted by r, and the correlation coefficient of a population is denoted by ρ or R. The sign and the absolute value of a correlation coefficient describe the direction and the magnitude of the relationship between two variables. The value of a correlation coefficient ranges between -1 and 1. The greater the absolute value of a correlation coefficient, the stronger the linear relationship. The strongest linear relationship is indicated by a correlation coefficient of -1 or 1. The weakest linear relationship is indicated by a correlation coefficient equal to 0. A positive correlation means that if one variable gets bigger, the other variable tends to get bigger. A negative correlation means that if one variable gets bigger, the other variable tends to get smaller. Keep in mind that the Pearson product-moment correlation coefficient only measures linear relationships. Therefore, a correlation of 0 does not mean zero relationship between two variables; rather, it means zero linear relationship. (It is possible for two variables to have zero linear relationship and a strong curvilinear relationship at the same time.) The scatterplots below show how different patterns of data produce different degrees of correlation. Maximum positive correlation (r = 1.0) Strong positive correlation (r = 0.80) Zero correlation (r = 0) 3 Algebra 1 Summer Institute 2014 Maximum negative correlation (r = -1.0) Moderate negative correlation (r = -0.43) Strong correlation & outlier (r = 0.71) Several points are evident from the scatterplots. When the slope of the line in the plot is negative, the correlation is negative; and vice versa. The strongest correlations (r = 1.0 and r = -1.0 ) occur when data points fall exactly on a straight line. The correlation becomes weaker as the data points become more scattered. If the data points fall in a random pattern, the correlation is equal to zero. Correlation is affected by outliers. Compare the first scatterplot with the last scatterplot. The single outlier in the last plot greatly reduces the correlation (from 1.00 to 0.71). How to Calculate a Correlation Coefficient The formula is based on the Deviation scores, the difference between a raw score and the mean scores. For example, the deviation score for x is: xi = Xi -𝑋̅ Where: xi is the deviation for observation “i” Xi is the raw score for observation “i” 𝑋̅ is the mean of all raw scores The most common formula for computing a product-moment correlation coefficient (r) between two variables is: 𝑟= ∑(𝑥𝑦) √(∑ 𝑥 2 ) ∙ (∑ 𝑦 2 ) Where: Σ is the summation symbol, 4 Algebra 1 Summer Institute 2014 xi = Xi -𝑋̅, xi is the deviation score, Xi is the raw score for observation i, 𝑋̅ is the mean x value, yi = Yi -𝑌̅, yi is the deviation score, Yi is the raw score for observation i, and 𝑌̅ is the mean y value. 5. Using Excel, let’s calculate the correlation coefficient r. Open Excel, and enter the data to find the means for x and y, the deviation scores for x and y, and the sums. You will need the following columns: The Coefficient of Determination The coefficient of determination (denoted by R2) is a key output of regression analysis. It is interpreted as the proportion of the variance in the dependent variable that is predictable from the independent variable. The coefficient of determination ranges from 0 to 1. An R2 of 0 means that the dependent variable cannot be predicted from the independent variable. An R2 of 1 means the dependent variable can be predicted without error from the independent variable. An R2 between 0 and 1 indicates the extent to which the dependent variable is predictable. An R2 of 0.10 means that 10 percent of the variance in Y is predictable from X; an R2 of 0.20 means that 20 percent is predictable; and so on. If you know the linear correlation (r) between two variables, then the coefficient of determination (R2) is easily computed using the following formula: R2 = r2. 6. Compute the R2 for our example. What does the coefficient of determination tell us in the context of the problem? 5 Algebra 1 Summer Institute 2014 In the last activity, we created some lines and experimented with residuals to determine which line was a better fit. In this activity we will figure out mathematically how to come up with the equation of the least square regression line. The Least Squares Regression Line Linear regression finds the straight line, called the least squares regression line or LSRL, that best represents observations in a bivariate data set. Suppose Y is a dependent variable, and X is an independent variable. The population regression line is: Y = Β0 + Β1X Where Β0 is a constant, Β1 is the regression coefficient, X is the value of the independent variable, and Y is the value of the dependent variable. Given a random sample of observations, the population regression line is estimated by: ŷ = b0 + b1x Where b0 is a constant, b1 is the regression coefficient, x is the value of the independent variable, and ŷ is the predicted value of the dependent variable. Normally, you will use a computational tool - a software package (e.g., Excel) or a graphing calculator - to find b0 and b1. You enter the X and Y values into your program or calculator, and the tool solves for each parameter. In the unlikely event that you find yourself on a desert island without a computer or a graphing calculator, you can solve for b0 and b1 "by hand". Here are the equations. b1 = Σ [ (xi - x)(yi - y) ] / Σ [ (xi - x)2] b1 = r * (sy / sx) b0 = y - b1 * x Where: b0 is the constant in the regression equation, b1 is the regression coefficient, r is the correlation between x and y, xi is the X value of observation i, yi is the Y value of observation i, x is the mean of X, y is the mean of Y, sx is the standard deviation of X, and sy is the standard deviation of Y 7. Using Excel do the computations to find the equation of the regression line. 6 Algebra 1 Summer Institute 2014 Properties of the Regression Line When the regression parameters (b0 and b1) are defined as described above, the regression line has the following properties. The line minimizes the sum of squared differences between observed values (the y values) and predicted values (the ŷ values computed from the regression equation). The regression line passes through the mean of the X values (x) and through the mean of the Y values (y). The regression constant (b0) is equal to the y intercept of the regression line. The regression coefficient (b1) is the average change in the dependent variable (Y) for a 1-unit change in the independent variable (X). It is the slope of the regression line. The least squares regression line is the only straight line that has all of these properties. 8. Construct a scatter plot that displays the data for 𝐱 = elevation above sea level (in feet) and 𝐰 = mean number of partly cloudy days per year. Based on the scatter plot you constructed, is there a relationship between elevation and the mean number of partly cloudy days per year? If so, how would you describe the relationship? Explain your reasoning. 7