MorePower 6.0 for t-test of Means, z-test of Proportions, and Simple
advertisement

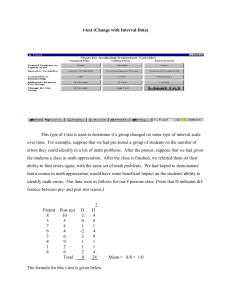
MorePower 6.0 for t-test of Means, z-test of Proportions, and Simple Correlation Jamie I. D. Campbell jamie.campbell@usask.ca University of Saskatchewan, Department of Psychology The power estimates used in these routines are all based on the Campbell and Thompson (2002) procedure for calculating power for the t-test. Equation 1 solves for tβ, which is the t value under the alternativehypothesis distribution corresponding to d relative to tα, the rejection criterion under the null hypothesis. The quantity d is the effect size in original units and its divisor (the denominator in Equation 1) is the SE of d. The probability that t is greater than tβ is the power to reject the null hypothesis for a given α level for a one-tailed test or α/2 for a two-tailed test. Equation 1 can be rearranged to solve for sample size (n) or effect size (d) (see Campbell & Thompson, 2002) and this capacity is built in to MorePower. The probability value entered or appearing in the Power field of MorePower corresponds to the upper tail of the tβ distribution. For two-tailed tests, the probability associated with the lower tail usually is trivial from a practical standpoint, but the calculator displays power for the combined upper and lower tail probabilities in the main output window. Probabilities for the central tdistribution are calculated using the BETAI algorithm for the incomplete beta function presented in Sprott (1996, p. 105). (1) ABSTRACT This document is supplementary to Campbell and Thompson (2012), which provides a complete introduction to MorePower 6.0 and takes the reader through a series of examples to illustrate its application to ANOVA. The focus here is on the other analysis types handled by MorePower 6.0, which includes routines to calculate sample size, effect size, and power for one or two sample t-tests of means, z-test of binomial proportions, and simple correlation. For the t-tests of means, MorePower 6. 0 also calculates Bayesian posterior odds for the null and alternative hypotheses based on formulas in Masson (2011) and graphical confidence intervals based on formulas from Jarmasz and Hollands (2009). MorePower 6.0 is available at https://wiki.usask.ca/pages/viewpageattachm ents.action?pageId=420413544. Power Calculations This research was supported by a grant from the Natural Sciences and Engineering Research Council of Canada. Address correspondence to Jamie Campbell, Department of Psychology, University of Saskatchewan, 9 Campus Drive, Saskatoon, SK, Canada, S7N 5A5 (phone 306966-6664, fax 306-966-1959. This version of the document created June 1, 2012. t t 1 d sd2 n Jamie I. D. Campbell This approach does not compute exact power because it uses the central tdistribution to represent both the null and alternative hypotheses. Unlike the null hypothesis distribution, the alternative hypothesis is more precisely characterized by a noncentral t-distribution that is skewed, with skewness decreasing as df increases (Cumming & Finch, 2001). For this reason, MorePower’s power calculations for t may be slightly conservative relative to exact power when df are relatively small. The ANOVA option in MorePower can be used to compute exact probabilities for two-tailed t-tests because the t-test corresponds to an ANOVA with one two-level factor. The non-central F-distribution used by MorePower to compute power for ANOVA does not simply extrapolate to one-tailed t-tests. For purposes of comparison, Table 1 presents exact power for values of t ranging from .5 to 4.5 for df = 5, 15, and 45 with centrally-computed power in brackets when the two do not agree to at least two decimal places. The two power estimates generally agree to two decimal places when power ≥ .80 or df ≥ 45 and, with the exception of very small df, the non-central correction amounts to only 1 or 2%. Consequently, MorePower’s approximate power estimates for t are accurate enough for many practical applications in psychological experiments. Furthermore, the approximation based on central t is computationally efficient and has no practical limits with respect to calculation of sample size, unlike the ANOVA sample size routine that is limited to a maximum of 2500 per cell. In the output window after each calculation, power is displayed to two decimal places, including both upper and lower tail probabilities for two-tailed tests. Upper-tail power for these tests is displayed to five digits in the Power text field because this more precise quantity is required by the algorithms to limit rounding error. Table 1 Comparison of computed power for the t-test from non-central and central distributions Degrees of Freedom t 5 15 45 0.5 .07 (.06) .08 (.07) .08 1.0 .13 (.10) .16 (.14) .16 1.5 .23 (.17) .29 (.27) .31 2.0 .37 (.30) .46 (.45) .50 (.49) 2.5 .52 (.48) .65 (.64) .69 3.0 .67 (.66) .80 .84 3.5 .80 .90 .93 4.0 .89 .96 .97 4.5 .94 .98 .99 Note. Two-tailed power rounded to two decimal places. Calculation based on central t distribution in parentheses (if different from non-central distribution). t-test of the Difference Between two Means The MorePower interface for t-tests is generally the same as that for the ANOVA, except the Design Factor and Effect of Interest sections are preset to one fact with two levels and greyed out. MorePower provides the same flexibility as for the ANOVA to solve for sample size, effect size (eta2, t or difference), or power. The user may select between a one-sample or twosample t-test and a one-tailed or two-tailed test. To illustrate MorePower for the t-test of two independent means, the following duplicates the example of the corresponding test for G*Power in Faul et al. (2007, p. 178). We want the sample size for a onetailed test with α = .05 and power = .95 for a medium effect size with Cohen’s d = .5. Cohen’s d is related to η2 by the relation Cohen’s d = 2 ⋅ f = 2 ⋅ √𝜂2 ÷ (1 − 𝜂2 ) (see 2 MorePower 6.0 Supplementary Documentation Cohen, 1988, p. 276); consequently the corresponding η2 = .059 (medium effect size = .06 in terms of η2). Click the radio button for a two-sample t-test and select Sample in the Solve For section. The Sample field is cleared and highlighted with a light blue background. Click the left Alpha radio button to select a one-sided test (α is .05 by default), enter power, and η2, then click the Solve button. The required total sample size of 176 appears in the Sample box (see Figure 1), which agrees with G*Power 3. Bayes Factor (BF), and the posterior odds pBIC(Ho|D) and pBIC(H1|D), while the following two lines report information about the Jarmasz and Holland’s (2009) graphical confidence interval (see Campbell & Thompson, 2011, for details about the Bayesian analysis and graphical confidence intervals). The mean difference (d) in original units is presented based on Equation 1 using the quantity provided in the Variability section, the standard error of the difference, and the margin of error for the 95% confidence interval of the mean difference. Finally, the output includes the one-tailed test of the null hypothesis that the mean difference is 0 (observed t-value and significance level) and the critical value of t for this test. t-test for Simple Correlation Click the r button under the analysis section to select power analysis for the correlation coefficient, r (see Figure 2). The sample size, effect size and power calculations for r are identical to those for the t-test of means with effect size specified in terms of η2. This follows from the fact that η may be considered a generalization of the Pearson r and similarly η2 a generalization of r2 (Cohen, 1988, p. 280). In MorePower, the correlation coefficient r is squared and processed as η2. The application of the t-test follows from the relation t = r/((1-r2)/(n-2)). The Effect Size scroll bars remain enabled but the defaults (r in the upper field and t in the lower field) should be maintained for analysis of correlation. The Variability section is greyed out but displays S = 1. This is because the calculator requires that a variability be specified, although the specific value does not affect the results in this case because error variability is implicit in η2. Figure 1. MorePower sample size calculation for the two-sample t-test The output window displays additional information, including the observed or requested power and total sample, followed by eta2 and Cohen’s d. The next two lines present the Bayesian analysis, including ΔBIC (dBIC in the display), the calculated 3 Jamie I. D. Campbell Figure 2. MorePower sample size calculation for the simple correlation. Figure 3. MorePower sample size calculation for one sample binomial proportion. z-test of Binomial Proportions Equation 1, but substituting z for t. For the one-sample case the variance of the difference (sd2 in Equation 1) is based on the nullhypothesis proportion and computed by P0⋅ (1 - P0). For the two-sample case, the difference variance is given by P0⋅ (1 - P0) + P1⋅ (1 - P1). Select the one-sample binomial option. Enter a sample size in the Sample field, specify the null (P0) and alternative (P1) proportions, and click Solve to calculate the corresponding power. The output window displays the approximate power to twodecimal places, standard error of the difference between proportions, and the odds ratio, a measure of effect size calculated as (P1 / (1 - P1)) / (P0 / (1 - P0)). The total N is also displayed, followed by the z-test of the binomial null hypothesis (observed z and If z-test of proportion is selected in the Analysis section, the Effect Size section is replaced by the Binomial Hypotheses section (see Figure 3). MorePower performs one- or two-tailed hypotheses tests for one or two-sample binomial proportions, and calculates sample size, effect size, and power estimates in relation to these tests. The one-sample case refers to comparing an observed proportion (P1; e.g., proportion of heads in 10 flips of a coin) to a nullhypothesis proportion (P0; e.g., the expected proportion of heads is .5). The two-sample case refers to a comparison of binomial proportions in two independent groups of observations. Calculation of power is based on 4 MorePower 6.0 Supplementary Documentation significance level) and critical value of z. Solve for sample size or effect size by selecting the corresponding button under Solve For. A continuity correction can be made to adjust for using a continuous distribution (z) to approximate the distribution of a discrete variable (the binomial event). The continuity correction for the difference (d = P0 - P1) expressed in terms of np (i.e., the expected number of binomial “successes” in n trials) is z = (n ⋅ d - .5) /√(𝑛 ⋅ 𝑝 ⋅ 𝑞), where q = 1 - p. In terms of p, therefore, z = (d - .5 / n) /√(𝑝 ⋅ 𝑞/𝑛). Click on the Continuity Correction check box to apply this correction to the specified or calculated difference in proportions: Difference - .5/N, where N is the total sample size. Cohen, J. Statistical power analysis for the behavioral sciences, 2nd ed., New Jersey: Lawrence Erlbaum Associates, Inc., 1988. Cumming, G., & Finch, S. (2001). A primer on the understanding, use, and calculation of confidence intervals that are based on central and noncentral distributions. Educational and Psychological Measurement, 61, 530–572. doi: 10.1177/0013164401614002 Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioural and biomedical sciences. Behaviour Research Methods, 39, 175-191. doi: 10.3758/BF03193146 Jarmasz, J., & Hollands, J. G. (2009). Confidence intervals in repeated-measures designs: The number of observations principle. Canadian Journal of Experimental Psychology, 63, 124–138. doi: 10.1037/a0014164 Masson, M. E. J. (2011). A tutorial on a practical Bayesian alternative to nullhypothesis significance testing. Behavioral Research Methods. doi: 10.3758/s13428-010-0049-5 Sprott, J. C. (1996). Numerical recipes and routines in BASIC. Cambridge University Press: Cambridge, UK. REFERENCES Campbell, J. I. D., & Thompson, V. A. (2002). More power to you: Simple power calculations for treatment effects with one degree of freedom. Behavior Research Methods, Instrumentation, and Computers, 34, 332-337. doi: 10.3758/BF03195460 Campbell, J. I. D., & Thompson, V. A. (2012). MorePower 6.0 for ANOVA with Bayesian Analysis and Graphical Confidence Intervals. Behavioral Research Methods. Advance online publication. doi: 10.3758/s13428-012-0186-0 5