Contingency Tables With Ordinal Variables
David Howell presents a nice example of how to modify the usual Pearson 2 analysis if you
wish to take into account the fact that one (or both) of your classification variables can reasonably be
considered to be ordinal (Statistical Methods for Psychology, 8th ed., 2013, pages 317-319). Here I
present another example.
The data are from the article "Stairs, Escalators, and Obesity," by Meyers et al. (Behavior
Modification 4: 355-359). The researchers observed people using stairs and escalators. For each
person observed, the following data were recorded: Whether the person was obese, overweight, or
neither; whether the person was going up or going down; and whether the person used the stairs or
the escalator. The weight classification can reasonably be considered ordinal.
Before testing any hypotheses, let me present the results graphically:
Percentage Use of Staircase Rather than Escalator Among Three Weight Groups
30
25
20
Ascending
15
Descending
10
5
0
Obese
Overweight
Normal
Initially I am going to ignore whether the shoppers were going up or going down and test to
see if there is a relationship between weight and choice of device. Here is the SPSS output:
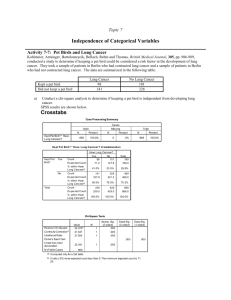
de vice * w eight Crosstabulati on
device
1 Stairs
2 Esc alator
Count
% within weight
Count
% within weight
1 Obese
24
7.7%
286
92.3%
weight
2 Overweight
165
15.3%
910
84.7%
3 Normal
256
14.0%
1576
86.0%
Total
445
13.8%
2772
86.2%
Contingency-Ordinal.doc
2
Chi-Square Te sts
Pearson Chi-Square
Lik elihood Ratio
Linear-by-Linear
As soc iation
N of Valid Cases
Value
11.752 a
13.252
2
2
As ymp. Sig.
(2-sided)
.003
.001
1
.099
df
2.718
3217
a. 0 c ells (.0% ) have expected count less than 5. The
minimum expected count is 42. 88.
Notice that the Person Chi-Square is significant. Now we ask “is there a linear relationship
between our weight categories and choice of device?” The easy way to do this is just to use a linear
regression to predict device from weight category.
ANOVAb
Model
1
Regres sion
Residual
Total
Sum of
Squares
.324
383.120
383.444
df
1
3215
3216
Mean Square
.324
.119
F
2.719
Sig.
.099a
a. Predic tors: (Constant), weight
b. Dependent Variable: device
As you can see, the linear relationship is not significant. If you look back at the contingency
table you will see that the relationship is not even monotonic. As you move from obese to overweight
the percentage use of the stairs rises dramatically but then as you move from overweight to normal
weight it drops a bit.
A chi-square for the linear effect can be computed as
2 = (N – 1)r2 = 3215(.324) / 383.444 = 2.717, within rounding error of the “Linear by Linear
Association” reported by SPSS.
We could also test the deviation from linearity by subtracting from the overall 2 the linear 2:
11.752 – 2.717 = 9.035. The df are also obtained by subtraction, overall less linear = 2 – 1 = 1. P(2
> 9.035 | df = 1) = .0026. There is a significant deviation from linearity.
Now let us split the file by the direction of travel. If we consider only those going down, there is
a significant overall effect of weight category but not a significant linear effect:
3
Chi-Square Te stsb
Pearson Chi-Square
Lik elihood Ratio
Linear-by-Linear
As soc iation
N of Valid Cases
Value
8.639a
9.091
2
2
As ymp. Sig.
(2-sided)
.013
.011
1
.973
df
.001
1362
a. 0 c ells (.0% ) have expected count less t han 5. The
minimum expected count is 23. 09.
b. direct = 2 Des cending
If we consider only those going up, there is a significant linear effect, and the deviation from
linearity is not significant 2(1, N = 1362) = 2.626, p = .105
Chi-Square Te stsb
Pearson Chi-Square
Lik elihood Ratio
Linear-by-Linear
As soc iation
N of Valid Cases
Value
9.525a
10.001
6.899
2
2
As ymp. Sig.
(2-sided)
.009
.007
1
.009
df
1855
a. 0 c ells (.0% ) have expected count less t han 5. The
minimum expected count is 13. 21.
b. direct = 1 Asc ending
Equivalence of the Linear-by-Linear Chi-Square and the N-1 Chi-Square for 2×2 Tables
Return to Wuensch’s Stats Lessons Page
Karl L. Wuensch, East Carolina University, September, 2013.
 0
0