Notes: The Exponential Model
advertisement

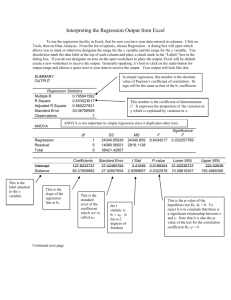
The Exponential Model The exponential model is a useful tool because in its most typical “first order” form it traces out the path of a variable that is growing at a constant rate. By generalizing the model, the assumption of constant growth can be dropped, allowing the model to better fit the path of a variable that is not growing at a constant rate. The First Order Exponential Model The “first order” exponential model generates a path with a constant growth rate. Letting r represent this constant rate and letting y denote the value of the variable that is growing, the value of the variable at a point in time t is given by (1) y t y 0 e rt , where y 0 is the initial value of the variable at point in time t 0 , and r is the constant rate at which the variable is growing. The continuous rate of growth of the variable y is represented by the quantity 1 dy . The y dt quantity yt in equation (1) represents the value of the variable y at time t , so we can also write yt as y (t ) . The representation y (t ) emphasizes that we are thinking that the value of the variable y is a function of the time t . If this function is differentiable, then it is common to write the derivative as y ' (t ) dy / dt . Since y(t ) yt , it follows that we obtain the derivate y ' (t ) for equation (1) by taking the derivative of the right side of the equation with respect to t. Given data on the variable y , the least squares regression technique can be used to obtain an estimate of the constant growth rate r. This estimate provides a characterization of the trend followed by the variable, in particular the best fit constant growth rate. Because least squares is a “linear regression” technique, we must “linearize” the model before we can apply least squares. This can be accomplished by taking the natural log of both sides of equation (1). Doing so, we obtain (2) ln( yt ) ln( y0 ) rt . Notice that this “logarithmic transformation” moved the variable r from a position of being an exponent on the number e in equation (1) to being a coefficient on the variable t in equation (2). In equation (2), the fact that r is an exponent implies that there is a non-linear relationship between r and yt ; i.e., you would not get a straight line if you plotted the relationship between yt and r. However, in equation (2), the fact that r is a coefficient implies 1 that there is a linear relationship between r and ln( yt ); i.e., you would get a straight line if you plotted the relationship between ln( yt ) and r. Because of this linear relationship, we can obtain a least squares estimate for r by regressing ln(yt ) on t. The Second Order Exponential Model The “second order” exponential model generates a path where the growth rate of the variable may change: (3) yt y0 e r1t r2t 2 Taking the natural log of (3) we have ln( yt ) ln( y0 ) r1t r2t 2 . Differentiating with respect to time t , we obtain 1 / yt dyt / dt r1 2r2t . Letting gt denote the growth rate of the variable y , letting a0 r1 , and letting a1 2r2 , we can rewrite the last equation as (4) g t a0 a1t . Equation (4) is a first degree polynomial model. Comparing equations (3) and (4), we find that a second degree exponential model for the level becomes a first degree polynomial model for the growth rate. In general, when differentiated with respect to time, an exponential model of degree k becomes a polynomial model of degree k-1. In particular, a fourth degree exponential model would be written (5) yt y0 e r1t r2t 2 r3t 3 r4t 4 Taking the natural log of (5) and differentiating with respect to time t , we obtain (6) g t a0 a1t a2t 2 a3t 3 , where gt is again the growth rate of y , a0 r1 , a1 2r2 , a2 3r3 , and a1 4r3 . Equation (6) is a relatively general model in that it allows the growth rate to vary in a flexible manner. Note that, if a1 a2 a3 0 , then the growth rate is constant and equal to g t a0 . If a2 a3 0 , but a1 0 , then the growth rate either increases over time (if a1 0 ) or decreases over time (if a1 0 ). If a3 0 , but a1 0 and a2 0 , then the growth rate can increase and then decrease, or vice versa. Finally, if a1 0 , a2 0 , and a3 0 , then the 2 growth rate can change directions twice, which is about as much flexibility as you would want for any model. By estimating the parameters in the exponential model, it is possible to create a model that fits the level of the variable that is growing, and this model can be used to forecast the level. To illustrate, consider the following figure, which presents an employment measure called FullTime Equivalent Employees. Clearly, the employment level has increased over time, though it is also evident that there are some years in which the employment level decreases. 200,000 Thousands Employed 150,000 U.S. Full Time Equivalent Employees 1948-2006 100,000 50,000 0 19451950195519601965197019751980198519901995200020052010 To obtain a model that fits this time series, we begin by using the general exponential model (5). Because it is nonlinear in the parameters, we must first take the natural log of model (5) to linerize it. Doing so, we obtain, (7) ln( yt ) ln( y0 ) r1t r2t 2 r3t 3 r4t 4 . Because there is a linear relationship between the ln( yt ) and the parameters r1 , r2 , r3 , and r4 , estimates for these four parameters and an estimate for the constant ln( y0 ) can be obtained by regressing the ln( yt ) on the variables t , t 2 , t 3 , and t 4 . The data plotted in the figure starts in 1948 and runs to the year 2006. The variable t runs from zero, which is associated with the year 1948, up to 58, which is associated with the last year 2006. The variables t 2 , t 3 , and t 4 are constructed by squaring, cubing, and quadrupling the variable t . The variable ln( yt ) is constructed by taking the natural log of the employment variable. The following graphic displays the output obtained from Excel from the regression. The R Square, which ranges between 0 and 1, measures the percentage of of the variance in the 3 dependent variable ln( yt ) that is explained by the regression. R 2 .9955 indicates that 99.55 percent of the variance is explained. This is a very high R square, but is typical for this type of regression where the model is fitting a trend. It is important to understand that, while it does provide information about how well the model fits the data, the R square should generally not be used to determine the quality of the model. SUMMARY OUTPUT Regression Statistics Multiple R 0.997743599 R Square 0.995492289 Adjusted R Square 0.995158385 Standard Error 2016.212786 Observations 59 ANOVA df Regression Residual Total Intercept t t2 t3 t4 4 54 58 SS MS F 48478406922 12119601731 2981.368 219516156 4065114 48697923078 Coefficients Standard Error t Stat 51863.38621 1189.562957 43.59868966 804.5338063 289.3534157 2.780453807 15.01072125 20.54046926 0.73078765 0.278632597 0.534288411 0.521502227 -0.005357015 0.004568738 -1.172537265 P-value 9E-44 0.007457 0.468068 0.604149 0.246128 The coefficient column presents the estimates of the parameters. The intercept, which is also referred to as the constant, is the estimate of ln( y0 ) in equation (7). The other four numbers in the column are the estimates of r1 , r2 , r3 , and r4 . The summary output presented in this graphic is not typically presented. More typically, the estimated equations is presented in something like the following manner: (8) ln( yt ) 51,863 805t 15.0t 2 (1,190)*** (289)*** (20.5) 0.28t 3 (0.53) 0.005t 4 , (0.005) R 2 0.9955 Underneath each estimate, the standard error associated with the estimate is presented in parenthesis. Some researchers would present the t-stat rather than the standard error. The two are interchangable in a sense because there is a relationship between them: The t-stat is equal to the coefficeint divided by the standard error. The t-stat is a test statistic associated with the null hypothesis that the coefficient is zero. The estimate for the coefficient will (almost surely) never actually be precisely zero. The question is how close the coefficient is to zero. The standard error is a measure of the lack of fit associated with the coefficient. The t-stat will be near zero when the coefficient itself is near zero, or when the standard error is large. When the t-stat is far from zero, we would tend to want to reject the hypothesis that the coefficient is zero. We say the coefficient is statistically insignificant if it is close enough to zero that we fail to reject the null hypothesis that the coefficient is zero. The p-value is the level of significance 4 at which we can reject the null hypothesis. For example, p-value of 0.246128 for the coefficient estimate -0.005 for r4 , the coefficient on t 4 , indicates we can reject the hypothesis that r4 0 at a 25% level of significance. This is the same as saying we can reject the hypothesis with 75 percent confidence. Typically, at least 90 percent confidence is desirable to reject. Thus, in this case the p-value of 0.246128 indicates we should fail to reject the hypothesis, meaning we conclude the r4 estimate is insignificant, which is the same as saying it is not significantly different than zero (even though it actually is -.005). The commonly used levels of significance are 10 percent, 5 percent, and 1 percent. Note that the p-value for the intercept estimate is 9E-44. This is a very small number, a decimal point followed by 43 zeros until you reach a 9. Thus, we are 99.99999…. percent confident that the intercept is not zero, so we confidently reject the null hypothesis that it is zero. One common way of indicating the level of confidence at which a null hypothesis can be rejected is by attaching asterisks to the standard errors as shown in (8). Three asterisks (***) indicates 99 percent confidence, or rejection at a p-value less than or equal to 0.01. Two asterisks (**) indicates 95 percent confidence, or rejection at a p-value less than or equal to 0.05 but greater than 0.01. One asterisk (*) indicates 90 percent confidence, or rejection at a p-value less than or equal to 0.10 but greater than 0.05. Applying this method to (8), the lack of asterisks on the last three standard errors indicates the estimates for r2 , r3 , and r4 are insignificant, while the three asterisks for the intercept and for r1 indicate that we are very confident these estimates are not zero. Because we find that our estimate for r4 is insignificant, the common practice is to drop the variable t 4 from the regression and re-estimate. Doing so, we obtain, (9) ln( yt ) 52,643 513t 38.1t 2 0.34t 3 , (990)*** (149)*** (6.00)*** (0.68)*** R 2 0.9954 In (9), the asterisks indicate that all of the estimates are significant at the 1 percent level of signficance, meaning we have at least 99 percent confidence that all of the estimates are signficantly different than zero. Notice the R square dropped, which will happen when you drop an explanatory variable. However, the R square typically will not drop much when you drop and insignificant variable because the variable had close to zero explanatory power. Here, indeed we see the R square did not drop much. The following figure plots the model (9) along with the actual data. 5 U.S. Full Time Equivalent Employees 1948-2006 200,000Thousands Employed 150,000 100,000 50,000 0 19451950195519601965 197019751980 198519901995200020052010 Actual Model Because the model (9) is based only upon the time variables, it can be used to forecast. This is accomplished by extending the time variables and then extending the model. The following figure does this for 10 additional years, so we obtain a forecast to the year 2016. From our model, we find that the estimated employment level for 2016 is 155,721,500. One can see cubic of the polynomial (9) at work. The third order of the polynomial is what allows the model to first increase at an increasing rate, but than increase at a decreasing rate. U.S. Full Time Equivalent Employees 1948-2006 200,000Thousands Employed 150,000 100,000 50,000 0 1940 1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 2005 2010 2015 2020 Actual Model 6