Notes Wednesday, September 7
advertisement

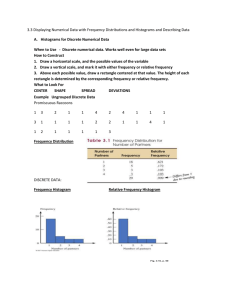
Drawing Histograms To draw a histogram, 1. Collect data 2. Organize data into class intervals: Most of the times, the class intervals are given. If we have to decide class intervals, we try to pick the class intervals so that most of them contain similar number of data points. 3. Calculate the relative frequencies or absolute frequencies: Absolute frequencies mean the total number of data points in each class interval, whereas relative frequencies mean the percentage of data points in each class interval. Depending on what histogram we will draw, we can make different tables. If we need to draw an absolute frequency histogram we list the total number of data points of each class interval, if we need to draw a relative frequency histogram we will write out the percentage of data points of each class interval. 4. Calculate the density scale: On each one of the class intervals, there will be a rectangle over it with the area equal to the percentage of data in that interval if we consider relative frequency histogram, or with the area equal to the total number of data in that interval if we consider absolute frequency histogram. Now we know the area of the rectangles over each class interval and we know the width of each rectangle, how do we find the height of those rectangles? We simply divide the area by the width. In the absolute frequency case, divide the total number of data points in a class interval by the width of the class interval. In the relative frequency case, divide the percentage of data points in each of the class interval by the width of the corresponding class interval. 5. Draw rectangles: First mark the horizontal axis with class intervals and mark the vertical axis with the density scale, then on each class interval draw a rectangle with the height we just calculated before. NOTE: In case of relative frequency histograms, areas of rectangles represent percentages. Be careful in choosing the horizontal and vertical units!! 2. In a college statistics class, the final exam scores were distributed as follows: Score Abolute Relative Density (height) 0-10 5 5/81=6.17% 0.617 10-50 8 9.88 .25 50-60 0 0 0 60-70 7 8.64 .86 70-80 15 18.52 1.85 80-90 24 29.63 2.96 90-100 22 27.16 2.72 Assume that for each class interval, the left end point falls in that class interval. a) Draw a relative frequency histogram for the data. b) If it took an 80% to make a B on the final, what percentage of the class made B’s or better? 57% c) Give a possible explanation for the small rise at the far left of the histogram. Standard Normal Distribution Three characterizations: Bell Shaped: All the histograms of normal distributions are bell shaped curves. The standard normal distribution is a special case of normal distributions with mean 0 and standard deviation 1. This is the histogram of the standard normal distribution. Symmetry: The curve is symmetric about the vertical line through 0 Approaching to 0: The curve is approaching the horizontal axis both to the right and left infinitely, but it never meets the horizontal axis. Four percentages: 50%: Remember that in a histogram, the area under the curve represents the percentage of the data. We know the curve of standard normal distribution is symmetric about the vertical line through 0, can you tell me what percentage of the data lies to the left of the vertical line through 0? 50%. 68%: When we talked about the standard deviation of a data set, we said that about 2/3 or 68% of data is within one SD of mean. Since the standard deviation for the histogram of standard normal distribution is 1, so there is 68% of the data lies between -1 and 1. 95%: In general, about 95% of a data is within 2 SD of mean. So here about 95% of the data is between -2 and 2. 99.7%: 99.7% of the data is between -3 and 3, so most of the data are between -3 and 3. Distribution table: If you look at the first page of your workbook, there is a distribution table. How do we use this table? First, there is a name for the numbers on the horizontal axis, we call them standard scores. Given a standard score, the percentage on the table represents the area of under the curve to the left of the standard score. For example, what is the percentile of 1.46 on the table? 92.79% of the data are below 1.46. What is the percentage of the data that are greater than 1.46? What is the percentage of the data that are between 1.41 and 1.46? Standardization The formula: Most of the data sets do not have a mean of 0 and a standard deviation of 1. To use the distribution table, we have to convert the data sets such that the mean is 0 and the standard deviation 1. Given a data set X with mean x and SD S_x, the z-score of x is You can see we are doing a change of scale to the original data set. What is the new mean and SD? Normal Approximation Find percentage between two z-scores Find percentage above a z-score Given percentile, find z-scores Percentile Ranks