hw_05n
advertisement

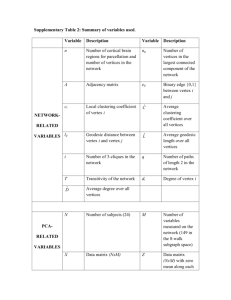
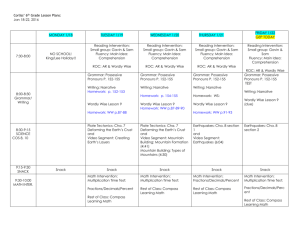
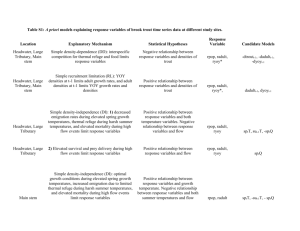
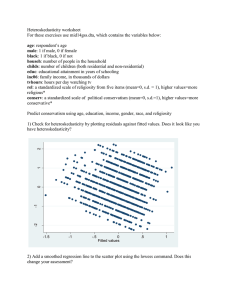
Homework 5 - 11 Questions Covers mainly Chapter 9 but also Categorical Coding (8) and VIF, Cook's Distance (10) Use the Project Talent data set. 1. A lack-of-fit test regressing Math on Gender, SES, Sociability, Reading, and Mechanical Reasoning indicates that a possible curvature exists for the variables Reading and Mechanical Reasoning. Without centering, create new, second-order variables for Reading and for Mechanical Reasoning. Repeat the multiple regression analysis including these second order terms (will result in a model with seven (7) predictors). Select Options and select Variance Inflation Factor AND Lack-of-Fit > Data Subsetting and answer the following questions. a. What are the VIF values for all of the predictors? b. Does this indicate the presence of Multicollinearity? Why or why not? c. What is the p-value of the lack-of-fit tests and what does this indicate about model fit? 2. Create new second order terms for Reading and Mechanical Reasoning after centering both the first order terms. Repeat the multiple regression analysis including these centered first and second order terms. Select Options and select Variance Inflation Factor AND Lack-of-Fit > Data Subsetting and answer the following questions. a. What are the VIF values for all of the predictors? b. Does this indicate the presence of Multicollinearity and support your answer? c. What is the p-value of the lack-of-fit test and what does this indicate about model fit? 3. The variable School Size is interpreted as follows: 1 = number of students is less than 100 (call this "small") 2 = number of students is from 100 to 399 (call this "medium") 3 = number of students is 400 or more (call this "large") The data set includes dummy coding, effect coding (large school as reference group for both), and orthogonal coding for Small - Medium, and Small/Medium - Large. Regressing Math on just these coded variables (i.e. regress Math separately on the two DV, then the two effect variables, then the two orthogonal variables) and answer the following questions: 1 a: Provide an interpretation of the t-tests for regressing Math on the DV. b: Provide an interpretation of the t-tests for regressing Math on the effect variables. c: Provide an interpretation of the t-tests for regressing Math on the orthogonal variables. 4. Regress Math on each orthogonal coded variable separately (i.e. conduct two simple linear regressions) and answer the following: a. What is the R-squared value for regressing Math on Small-Med? b. What is the R-squared value for regressing Math on SM-Large? c. What is the R-squared value for the multiple regression model when regressing Math on both orthogonal variables (i.e. from the model in 3c)? d. Did the sum of the R-squared values in parts a and b equal the R-squared value in c? Use the High School and Beyond (HSB) data set. The data is explained in the HSB Read Me file. USE MATH AS RESPONSE 1. With Math as the response and the remaining variables as predictors (excluding ID as that serves only as an identifier), how many models are possible (assume an intercept for all models)? 2. Using Math as response, analyze the data using Minitab Backward, Forward, and Stepwise Regression (keep default settings). Specify the “best” regression equation identified by these three methods. How many steps did it take for each method? Do they agree? Backward: Steps: Forward: Steps: Stepwise: Steps: 2 Agree? 3. In the Backward Elimination analysis, which variable was removed first and why? 4. In the Forward and Stepwise analyses which variable entered first and why? 5. In the Backward Elimination analysis how much of a change in R2 is there between the model in Step 4 and the final model? 6. Now regress Math on all of the predictors and use the Best Subsets in Minitab to determine the variables that comprise the best model using R-squared, adjusted Rsquared, and lowest Cp. What are the variables, criterion values, and are the models the same? [Remember that goal is reduce number of variables from full model.] Lowest Cp: Value: R-squared: Value: Adj. R-Squared: Value: All models the same? 7. Regress Math on Reading, Writing and Science. Click Storage and select Cook’s Distance (Di). Determine if any of these Di value(s) indicate if any observation(s) as influential by seeing if any of these Di values exceed 0.5 of the F-distribution with p and n-p degrees of freedom. That is, find the cumulative F probability for this column of Di values. If any cumulative probabilities exceed 0.5 then that observation would be considered and outlier. Also, in the output under Unusual Observations any observation marked with an “X” indicates and influential outlier. Do any exist in this regression analysis? DF: Number of Di values greater than 0.5: Observations that are considered influential outliers: 3