Word
advertisement

Simple Linear Regression
Previously we’ve discussed the notion of inference – using sample statistics to find
out information about a population. This was done in the context of the mean of a
random variable. In addition we talked early on about correlation between two
variables. With the correlation coefficient and Chi-Square tests we were able to see if
there were relationships between random variables.
Here we want to take this a step further and formalize the relationship between two
variables, and then extend this to multivariate analysis. This is done through the
concept of regression analysis.
Suppose we are interested in the relationship between two variables: length of stay and
hospital costs. We think that LOS causes costs: a longer LOS results in higher costs.
Note that with correlation there are no claims made about what causes what – just that
they move together. Here we are taking it further by “modeling” the direction of the
relationship. How would we go about testing this? If we take a sample of individual
stays and measure their LOS and cost, we might get the following:
Stay
LOS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Cost
3
5
2
3
3
5
5
3
1
2
2
5
1
3
4
2
1
1
1
6
2614
4307
2449
2569
1936
7231
5343
4108
1597
4061
1762
4779
2078
4714
3947
2903
1439
820
3309
5476
1
Just looking at the data there looks to be a positive relationship, individuals with more
LOS seem to have a higher cost; but not always.
Another way of looking at the data would be with a scatter diagram:
Scatter Diagram: LOS vs Cost
8000
7000
$Cost
6000
5000
4000
3000
2000
1000
0
0
1
2
3
4
5
6
7
LOS
Ignore the trend line for now.
Cost is on the Y axis, LOS is on the X. It looks like there is a positive relationship
between cost and LOS. Simply eyeballing the data, it looks like the dots go up and to the
right.
The trendline basically connects the dots as best as possible. Note that the slope of this
line will tell you the marginal impact of LOS on charges: what happens to costs if LOS
increases by 1 unit? This line intersects the Y axis just above zero. This would be the
predicted cost if LOS was zero.
If the correlation coefficient between LOS and costs was 1 then all the dots would be on
this line. Note that for some observations the line is real close to the dot, while for
others it is pretty far away. Let the distance between any given dot and the line be the
error in the trend line. The trend line is drawn so that these errors are minimized. Since
errors above the line will be positive, while errors below the line will be negative we
have to be careful – positive errors will tend to wash out negative errors. Thus a strategy
in estimating this line would be to draw the line such that we minimize the sum of the
squared error term.
This is known as The Least Squares Method.
2
I.
The Logic
The idea of Least Squares is as follows:
In theory our relationship is:
Y = o + 1X +
Y is the dependent variable – the thing we are trying to explain.
X is the independent variable – what is doing the explaining.
o and 1 are population parameters that we are interested in knowing
In our case Y is the charge, X is LOS. o is the intercept (where the line crosses the Y
axis), and 1 is the slope of the line. This coefficient 1 is the marginal impact of X on Y.
These are population parameters that we do not know. From our sample we estimate the
following:
Y = bo + b1X + e
Note I’ve switched to non-Greek letters since we are now dealing with the sample. So bo
is an estimator for o and b1 is an estimator for 1. e is the error term reflecting the fact
that we will not always be exactly on our line. If we wanted to get a predicted value for
Y (costs) we would use:
^
Y i bo b1 Xi {the ^ means predicted value)
Note the error term is gone. So this is the equation for the estimated line. So suppose
that bo=3 and b1 = 2, then someone with a LOS of 5 days would be predicted to have
3+2*5=$13 in charges, etc.
Least squares finds bo and b1 by minimizing the sum of the squared difference between
the actual and predicted value for Y:
II.
Specifics
n
Sum of squared difference =
(Y Yˆ )
i
i
2
i 1
Substituting:
n
(Y Yˆ )
i
i 1
i
n
2
[Yi (bo b1 Xi )] 2
i 1
3
Thus least squares finds bo and b1 to minimize this expression. We are not going to go
into the details here of how this is done, but we will focus on the intuition of what is
going on.
The easiest way to think about it is to go back to the scatter diagram: least squares draws
the trend line to connect the dots the best way possible. We choose the parameters to
minimize the size of our mistakes or errors.
III.
How do we do this in Excel?
Excel can do both simple (one independent variable) and multiple (more than one)
regression.
You need the Data Analysis Toolpack to do it.
Load the Analysis ToolPak
1. Click the File tab, click Options, and then click the Add-Ins category.
2. In the Manage box, select Excel Add-ins and then click Go.
3. In the Add-Ins available box, select the Analysis ToolPak check box, and then click OK.
For the Mac you have to use a different add-in called Statplus:
http://www.analystsoft.com/en/products/statplusmacle/
4
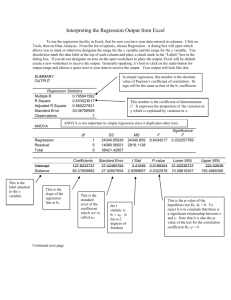
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.807337
R Square
0.651794
Adjusted R Square 0.632449
Standard Error
995.4983
Observations
20
ANOVA
df
Regression
Residual
Total
Intercept
LOS
1
18
19
SS
MS
F
Significance F
33390795 33390795 33.69347
1.69E-05
17838305 991016.9
51229100
CoefficientsStandard Error t Stat
P-value Lower 95% Upper 95%
997.4659
465.7353 2.141701 0.046147
18.99164 1975.94
818.8394
141.0671 5.804607 1.69E-05
522.4681 1115.211
What does all this mess mean?
Skip the first two sections for now and just look at the bottom part. The numbers under
Coefficients are our coefficient estimates:
Costi = 997.5 + 818.8*LOSi + ei
So we would predict that a patient starts with a cost of 997.5 and each day adds 818.8 to
the cost.
The least squares estimate of the effect of LOS on cost is $818.8 per day. So someone
with a LOS of 5 days is predicted to have: 997.5 + 818.8*5 = $5091.5 in costs.
The statistics behind all this get pretty complicated, but the interpretation is easy. And
note that we can now add as many variables as we want and the coefficient estimate for
each variable is calculated holding constant the other right-hand-side variables.
Science vs. Art in Regression
Causation
Omitted variable bias
IV.
Measures of Variation:
We now want to talk about how well the model predicted the dependent variable. Is it a
good model or not? This will then allow us to make inferences about our model.
5
The Sum of Squares
The total sum of squares (SST) is a measure of variation of the Y values around their
mean. This is a measure of how much variation there is in our dependent variable.
n
_
SST (Yi Y ) 2
i 1
[Note that if we divide by n-1 we would get the sample variance for Y]
The sum of squares can be divided into two components
Explained variation, or the Regression Sum of Squares (SSR) – that which is attributable
to the relationship between X and Y, and unexplained variation, or Error Sum of Squares
(SSE) – that which is attributable to factors other than the relationship between X and Y.
^
Y
Yi
(Yi Y i ) 2 ei
^
Y i bo b1 Xi
_
(Yi Y ) 2
^
(Y i Y ) 2
_
Y
Xi
X
The dot, represents one particular actual observation (Xi,Yi), the horizontal line
_
represents the mean of Y ( Y ), the upward sloping line represents the estimated
_
regression line. The distance between Yi and Y is the total variation (SST). This is
broken into two parts, that explained by X and that not explained. The distance between
6
the predicted value of Y and the mean of Y is that part of the variation that is explained
by X. This is SSR. The distance between the predicted value of Y and the actual value
of Y is the unexplained portion of the variation. This is SSE.
Suppose that X had no effect whatsoever on Y. Then the best regression line would
simply be the mean of Y. So the predicted value of Y would always be the Mean of Y no
matter what X is. So X is doing nothing in helping us to explain Y. Then all the
variation in Y will be unexplained.
Suppose, alternatively, that the predicted value was exactly correct – the dot is on the
regression line. Then notice that all the variation in Y is being explained by the variation
in X. In other words, if you know X you know Y exactly.
^
As shown above, some of the variation in Y is due to variation in X ( (Y i Y ) 2 ) and some
^
of the variation is not explained by variation in X ( (Yi Y i ) 2 ).
n
^
So to get the SSR we calculate SSR (Y i Y ) 2
i 1
n
And to get the SSE we calculate:
^
(Y Y
i
i
)2
i 1
Referring back to our first regression output notice the middle table looks as follows:
ANOVA
df
Regression
Residual
Total
SS
MS
F
Significance F
1 33390795 33390795 33.69347
1.69E-05
18 17838305 991016.9
19 51229100
The third column is labeled SS (or sum of squares), then the first row is regression So
SSR = 33390795. Residual is another word for error (or leftover) so SSE = 17838305,
and the SST = 51229100. Notice that: 51229100=33390795+17838305
How do we use this information? In general, the method of Least Squares chooses the
coefficients so to minimize SSE. So we want that to be as small as possible – or
equivalently, we want SSR to be as big as possible.
Notice that the closer SSR is to SST the better our regression is doing. In a perfect world
SSR = SST: or our model explains ALL the variation in Y. So if we look at the ratio of
SSR to SST, this will tell us how our model is doing. This is known as the Coefficient of
Determination or R2.
7
R2 = SSR/SST
for our example: R2= 33390795/51229100= .652
Is this good? It depends.
Thus, 65% of the variation in charges can be explained by variation in LOS. Note that
this is pretty low since there are many other things that determine charges.
Standard Error of the Estimate
Note that for just about any regression all the data points will not be exactly on the
regression line. We want to be able to measure the variability of the actual Y from the
predicted Y. This is similar to the standard deviation as a measure of variability around a
mean. This is called The Standard Error of the Estimate
n
SYX
SSE
n2
(Y Yˆ )
i
i
2
i 1
n2
Notice that this looks very much like the standard deviation for a random variable. But
here we’re looking at variation of actual values around a prediction.
For our example SYX =
17838305
=995.5
18
Note that the top table in the Excel output has the R-squared and the Standard Error
listed, among other things.
This is a measure of the variation around the fitted regression line – a loose interpretation
would be that on average the data points are about $995 off of the regression line. We
will use this in the next section to make inferences about our coefficients.
V.
Inference
We made our estimates above for the regression line based on our sample information.
These are estimates of the (unknown) population parameters. In this section we want to
make inferences about the population using our sample information.
t-test for the slope
Again, our estimate of is b. We can show that under certain assumptions (to come in a
bit) that b is an unbiased estimator for . But as discussed above there will still be some
sampling error associated with this estimate. So we can’t conclude that =b every time,
only on average. Thus we need to take this sampling variability into account.
Suppose we have the following null and alternative hypothesis:
8
Ho: 1=0 (there is no relationship between X and Y)
H1: 1 0 (there is a relationship)
This can also be one tailed if you have some prior information to make it so.
Our test statistic will be:
t = b1-1/Sb1, where Sb1 is the standard error of the coefficient.
Sb1 = SYX/SSX
Where SSX = (Xi-Xb)2
This follows a t-distribution with n-2 degrees of freedom.
[NOTE: in general this test has n-k-1 degrees of freedom, where k is the number of righthand-side variables. In this case k=1 so it is just n-2]
The Standard error of the coefficient is the standard error of the estimate divided by the
squared deviation in X.
Again note the bottom part of the Excel output:
Intercept
LOS
Coefficient Standard
Lower
Upper
s
Error
t Stat
P-value
95%
95%
997.4659 465.7353 2.141701 0.046147 18.99164 1975.94
818.8394 141.0671 5.804607 1.69E-05 522.4681 1115.211
So our LOS coefficient is 818.8. Is this statistically different from zero?
Our test statistic is: t=(818.8-0)/.141.1 = 5.8. We can use the reported p-value: .0000169
to conclude that we would reject the null hypothesis and say that there is evidence that 1
is not zero. That is, LOS has a significant effect on charges.
The t-test can be used to test each individual coefficient for significance in a multiple
regression framework. The logic is just the same.
One could also test other hypothesis: Suppose it used to be the case that each day in the
hospital resulted in $1000 charge, is there evidence that it has changed?
Ho: 1=1000
Ha: 11000
t=(818.8-1000)/141.06 = -1.28 the pvalue associated with this is .215 – so there is a
21.5% chance we could get a coefficient of 818 or further away from 1000 if the null is
true. Thus, we would fail to reject the null and conclude that there is no evidence that the
slope is different from 1000.
9
We could also estimate a confidence interval for the slope:
b1 tn-2Sb1
Where tn-2 is the appropriate critical value for t. You can get excel to spit this out for you
as well. Just click the confidence interval box and type in the level of confidence and it
will include the upper and lower limits in the output.
For my example we are 95% confident that the population parameter 1 is between 522
and 1115.
You can also predict confidence interval. Suppose a patient was going to stay 3 days in
the hospital, what do you predict costs to be?
Point estimate: cost = 997+3*818=$3,451
Or a 95% confidence interval of the expected cost would be:
18.99 + 3*(522)=1586
1975 +3*(1115)=5321
Or we are 95% confident that the cost would be between $1,586 and $5,321
10
Multiple Regression
VI.
Introduction
In the last section we looked at the simple linear regression model where we have only
one explanatory (or independent) variable. This can be easily expanded to a multivariate
setting. Our model can be written as:
Yi = o + 1X1i +2X2i + … + kXki + I
So we would have k explanatory variables. The interpretation of the ’s is the same as in
the simple regression framework. For example 1 is the marginal influence of X1 on the
dependent variable Y, holding all the other explanatory variables constant.
This is easy to do in Excel. It is similar to simple regression except that one needs to
have all the X variables side by side in the spreadsheet.
Inference about individual coefficients is exactly the same as in simple regression.
Suppose we have the following data for 10 hospitals:
Y
Cost
X1
Size
2750
2400
2920
1800
3520
2270
3100
1980
2680
2720
X2
CEO IQ
225
200
300
350
200
250
175
400
350
275
6
37
14
33
11
21
21
22
20
16
Cost is the cost per case for each hospital, Size is the size of the hospital in the number of
beds, and CEO IQ is a scale that measures how much the administrator knows about
competitor hospitals. In this case we might expect larger hospitals to have lower costs per
case, and when the administrator has more knowledge about his competition costs will be
lower as well.
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.834034
R Square
0.695612
Adjusted R Square 0.608644
Standard Error
323.9537
Observations
10
ANOVA
11
df
Regression
Residual
Total
Intercept
Size
CEO IQ
2
7
9
SS
1678818
734622
2413440
MS
F
Significance F
839409 7.998485
0.01556
104946
Coefficients Standard Error t Stat
P-value Lower 95% Upper 95%
4240.131
435.6084 9.733813 2.56E-05
3210.081 5270.181
-3.76232
1.442784 -2.60768 0.035032
-7.17395 -0.35068
-29.8955
11.66298 -2.56328 0.037372
-57.4741 -2.31699
So in this case we’d say that each bed lowers the per case cost of the hospital by $3.76,
and every one unit increase in the CEO IQ scale lowers costs by 29.90. Note that these
are not the same results we would get if we did two simple regressions:
If we only included Size:
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.640237
R Square
0.409904
Adjusted R Square 0.336142
Standard Error
421.9245
Observations
10
ANOVA
df
Regression
Residual
Total
Intercept
Size
1
8
9
SS
MS
F
Significance F
989277.9 989277.9 5.557108
0.046149
1424162 178020.3
2413440
Coefficients Standard Error t Stat P-value Lower 95% Upper 95% Lower 95.0% Upper 95.0%
3804.717
522.4326 7.282694 8.53E-05
2599.984 5009.449
2599.984
5009.44
-4.3696
1.853606 -2.35735 0.046149
-8.64403 -0.09518
-8.64403
-0.0951
While if we only included CEO IQ:
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.632394
R Square
0.399922
Adjusted R Square 0.324912
Standard Error
425.4781
Observations
10
12
ANOVA
df
SS
965187.2
1448253
2413440
MS
965187.2
181031.6
Coefficients Standard Error
3315.282
332.1822
-34.8896
15.11012
t Stat
9.980311
-2.30902
Regression
Residual
Total
1
8
9
Intercept
CEO IQ
F
Significance F
5.331595
0.049765
P-value
8.61E-06
0.049765
Why the changes in the coefficients?
Note the R-squared do not add up. The multiple Regression R2 is .695, and the two
simple R2’s are .40 and .41.
VII. Testing for the Significance of the Multiple Regression Model
F-test
Another general summary measure for the regression model is the F-test for overall
significance. This is testing whether or not any of our explanatory variables are
important determinants of the dependent variable. This is a type of ANOVA test.
Our null and alternative hypotheses are:
Ho: 1=2= … = k =0 (none of the variables are significant)
H1: At least one j 0
Here the F statistic is:
SSR
F=
SSE
k
n k 1
Notice that this statistic is the ratio of the regression sum of squares to the error sum of
squares. If our regression is doing a lot towards explaining the variation in Y then SSR
will be large relative to SSE and this will be a “big” number. Whereas if the variables are
not doing much to explain Y, then SSR will be small relative to SSE and this will be a
“small” number.
This ratio follows the F distribution with k and n-k-1 degrees of freedom.
The middle portion of the Excel output contains this information (this is the model with
school and experience, not shoe size):
13
ANOVA
df
Regression
Residual
Total
SS
2 1678818
7 734622
9 2413440
MS
F
Significance F
839409 7.998485
0.01556
104946
F = (1678818/2)/(734622/(10-2-1)) = 839409/104946 = 7.998
The “Significance F” is the p-value. So we’d reject Ho and conclude there is evidence
that at least one of the explanatory variables is contributing to the model. Note that this is
a pretty weak test: it could be only one of the variables or it could be all of them that
matter, or something in between. It just tells us that something in our model matters.
VIII. Dummy Variables in Regression
Up to this point we’ve assumed that all the explanatory variables are numerical. But
suppose we think that, say, earnings might differ between males and females. How
would we incorporate this into our regression?
The simplest way to do this is to assume that the only difference between men and
women is in the intercept (that is the coefficients on all the other variables are equal for
men and women).
Wage
Men
Women
male
female
Education
14
Assume for now the only other variable that matters is education. The idea is that we
think men make more than women independent of education. That is the male intercept
(male) is greater than the female intercept (female). We can incorporate this into our
regression by creating a dummy variable for gender. Suppose we let the variable Male
=1 if the individual is a male, and 0 otherwise. Then our equation becomes:
Wagei = o + 1Educationi + 2Malei + i
So if the individual is male the variable Male is “on” and if she is female Male is “off”.
The coefficient 3 indicates how much extra the wage of males is than female (this can be
positive or negative in theory). In terms of our graph, female = o, and male = o+3.
So the dummy variable indicates how much the intercept shifts up or down for that group.
This can be done for more than two categories. Suppose we think that earnings also
differ by race then we can write:
Wagei = o + 1Educationi + 2Malei +3Blacki + 4Asiani + 5Otheri + i
Where Black is a dummy variable equal to 1 if the individual is black, Asian =1 if the
individual is Asian, other =1 for other nonwhite race. Note that white is omitted from
this group. Just like female is omitted. Thus the coefficients 3, 4, and 5 indicate how
wages differ for blacks, Asian, and other, relative to whites:
Note that if there are x different categories, we include x-1 dummy variables in our
model. The omitted group is always the comparison.
Suppose we estimate this and get:
.^
Wage = -20 + 3.12*School + 4*Male –5*black –3*Asian –3*other.
So males make $4/hour more than females
Blacks make $5 less than whites
Asians make $3 less than whites
Other races make $3 less than whites.
Note that this is controlling for differences in other characteristics. That is, a male with
the same level of schooling, experience and race will earn $4 more than the identical
female. Similarly for race.
IX.
Interaction Effects
Suppose we’re interested in explaining total costs and we think LOS and gender are the
explanatory variables. We could estimate our model and get something like:
15
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.961293
R Square
0.924085
Adjusted R
Square
0.918011
Standard Error
619.0914
Observations
28
ANOVA
df
Regression
Residual
Total
Intercept
LOS
Female
2
25
27
Coefficients
638.4373
1113.62
-244.657
Significance
SS
MS
F
F
1.17E+08 58317790 152.1569
1.01E-14
9581854 383274.2
1.26E+08
Standard
Error
257.5843
65.47048
246.0593
t Stat
P-value
2.478557 0.020295
17.0095 2.97E-15
-0.9943 0.329603
Interpret this.
Now what if we think the effect of LOS on cost is different for males than females. How
might we deal with this? Note that the idea is that not only is there an intercept
difference, but there is a slope difference as well. To get at this we can interact LOS and
Female – that is create a new variable that multiplies the two together, then we would get
something like the following:
SUMMARY OUTPUT
Regression Statistics
Multiple R
0.998708
R Square
0.997417
Adjusted R
Square
0.997095
Standard Error
116.5416
Observations
28
16
ANOVA
df
Regression
Residual
Total
Intercept
LOS
Female
LOS*Female
3
24
27
Coefficients
2075.093
606.5649
-2472.39
711.2028
SS
MS
F
1.26E+08 41963822 3089.677
325966.7 13581.95
1.26E+08
Standard
Error
73.34754
23.00362
97.09693
27.24366
t Stat
28.29125
26.36823
-25.4631
26.10526
Significance
F
3.54E-31
P-value
6.06E-20
3.12E-19
7.01E-19
3.93E-19
Note the adjusted R2 increases which suggests that adding this new variable is “worth it”.
How do we interpret?
Females have costs that are $2,472 lower than males holding constant LOS. A one unit
increase in LOS increases costs for males by $606 for males, while the effect for females
is $711 LARGER. That is each day in the hospital increases costs for females by
606.5+711.2 = $1,317.7. So females start at a lower point, but increase faster with LOS
than do males.
17