Central Limit Theorem
advertisement

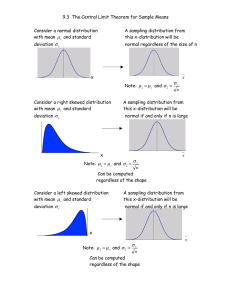
Central Limit Theorem This is a theorem that shows that as the size of a sample, n, increases, the sampling distribution of a statistic approximates a normal distribution even when the distribution of the values in the population are skewed or in other ways not normal. In addition, the spread of the sampling distribution becomes narrower as n increases; that is, the bell shape of the normal distribution becomes narrower. It is used in particular in relation to the sample mean: Thus, the sampling distribution of a sample mean approximates a normal distribution centred on the true population mean. With larger samples, that normal distribution will be more closely focused around the population mean and will have a smaller standard deviation. The theorem is critical for statistical inference as it means that population parameters can be estimated with varying degrees of confidence from sample statistics. For if the means of repeated samples from a population with population mean μ would form a normal distribution about μ, then for any given sample, the probability of the mean falling within a certain range of the population mean can be estimated. It does not require repeat sampling actually to be carried out. The knowledge that repeated sampling produces a normal and (for larger n) narrow distribution of sample averages concentrated around the population mean enables us to predict at varying levels of confidence just how close to the true mean our sample mean is. For large samples, the relationship will hold even if the population distribution is very skewed or discrete. This is important because in the social sciences, the distributions of many variables commonly investigated (e.g., income) are skewed. Large n can mean as little as 30 cases for estimation of a mean but might need to be more than 500 for other statistics. To illustrate, Figure 1 shows an example of a skewed distribution. It is a truncated British income distribution from a national survey of the late 1990s. The means of around 60 repeat random samples of sample size n = 10 were taken from this distribution and result in the distribution shown in Figure 2. This distribution is less skewed than that in Figure 1, though not exactly normal. If a further 60 repeat random samples—this time, of n = 100—are taken from the distribution illustrated in Figure 1, the means of these samples form the distribution in Figure 3, which clearly begins to approximate a normal distribution. Figure 1. An Example Skewed Distribution Figure 2. The Distribution of Sample Means From the Distribution Shown in Figure 1, in Which Sample Size = 10 Figure 3. The Distribution of Sample Means From the Distribution Shown in Figure 1, in Which Sample Size = 100 Example As a result of this theorem, we can, for example, estimate the population mean of, say, the earnings of female part-time British employees. A random sample of 179 such women in the late 1980s provided a sample mean of earnings of £2.57 per hour with a sample standard deviation, s of 1.24, for the particular population under consideration. We can take the sample standard deviation to estimate the population standard deviation, which gives us a standard error of 1.24 / 179 0.093 . On the basis of the calculated probabilities of a normal distribution, we know that the population mean will fall within the range 2.57 ± (1 • 0.093), that is, between £2.48 and £2.66 with 68% probability; that it falls within the range 2.57 ± (1.96 • 0.093), that is, between £2.39 and £2.75 with 95% probability; and that it falls within the range 2.57 ± (2.58 • 0.093), that is, between £2.33 and £2.81 with 99% probability. We can be virtually certain that the range covered by the sample mean, plus or minus 3 standard errors, will contain the value of the population mean. But as is clear, there is a trade-off between precision and confidence. Thus, we might be content being 95% confident that the true mean falls between £2.39 and £2.75 while acknowledging that there is a 1 in 20 chance that our sample mean does not bear this relationship to the true mean. That is, it may be one of the samples whose mean falls into one of the tails of the bell-shaped distribution. The central limit theorem remains critical to statistical inference and estimation in that it enables us, with large samples, to make inferences based on assumptions of normality. The theorem can also be proved for multivariate variables under similar conditions as those that apply to the univariate case.