Parallel Computing Using FPGA
advertisement

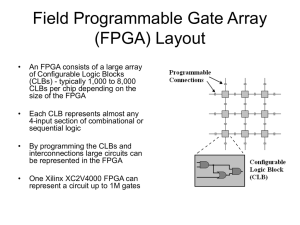
159.735 – Studies in parallel and distributed systems Parallel Computing Using FPGA Submitted to: Dr. Martin Johnson Submitted by: Sohaib Ahmed (07217579) Parallel Computing Using FPGA Introduction Field programmable gate arrays (FPGAs) are emerging in many areas of high performance computing, either as tailor made signal processor, embedded algorithm implementation, systolic array, software accelerator or application specific architecture. FPGAs are so flexible and reconfigurable that they are capable of massively parallel operations, explicitly tailored to the problem at hand. There are lot of paradigms to put FPGAs at work in a high performance computing environment There are number of limitations which restrict FPGAs to reach the performance of Application Specific Integrated Circuits (ASICs) but they provide the possibility of changing the hardware design easily while outpacing software implementations on general purpose processors. FPGA FPGA was first invented in the mid 1980s by one of the founder of Xilinx (www.xilinx.com ), Ross Freeman. It is a semiconductor device which is comprised of different number of logic elements, interconnects, IOBs (Input/Output blocks). All these components are user-configurable. It can help in implementing complex digital circuits. The IOBs form a ring around the outer-edge of the microchip while rectangular array of logic blocks lies inside the IOB ring. Each IOB provides a facility to access a selectable I/O to one of the pins found in exterior of the FPGA package as mentioned in figure 1 (Buell et al, 2007). Figure 1: FPGA internal structure based on the Xilinx architecture style (Buell et al., 2007) A typical FPGA logic block consists of a four-input lookup table (LUT) and flip-flop. Currently, FPGA consists of DSP blocks which have high-level functionality embedded into the silicon, high-speed IOBs, embedded memories and processors. It also contains Configurable logic blocks (CLBs) which comprised of multiple slices. A slice is a small set of building blocks. Moreover, modern FPGA consist of tens of thousands of CLBs and a programmable interconnected network in a rectangular grid (Buell et al, 2007). ASICs (Application specific integrated circuits) is typically performed a single function through out the lifetime of a chip while in FPGA, it can be reprogrammed in such a way that it can perform function in micro-seconds. Source code written in a hardware description language (HDL) such as Verilog and VHDL provides the functionality to perform tasks at run time. Synthesis process generates technologymapped netlist (figure 2). A map, place and route process then fits the netlist to the actual FPGA in architecture. The process produces a bitstream which is used to reconfigure FPGA. Timing, postsynthesis, functional simulations and verifications methodologies can validate map, place and route results (Buell et al., 2007) Figure 2: Typical design flow of FPGA (Buell et al, 2007) FPGA supports the notion of reconfigurable computing and provides a facility of onchip parallelism which can be mapped directly from the dataflow characteristics of an application’s parallel algorithm. A recent emergence in high performance can be achieved by a hybrid approach to make a complex-system on a programmable chip. Examples are Virtex II Pro, Virtex-4 and Xilinx Devices. The most recent success of FPGAs in high-performance computing came under Tsubame cluster in Tokyo when FPGAs increased performance by additional 25% (Wu-Feng & Manocha, 2007). Reconfigurable Computing High performance reconfigurable computing (HPRC) are parallel computing system that allows multiple microprocessors and multiple FPGAs embedded into it. FPGAs are inherently co-processors which are deployed to execute the small portion of the application that takes most of the time – under 10-90 rule, the 10 percent of the code that takes 90 percent of the execution time (Buell et al, 2007). Reconfigurable computing is also known as configurable computing or custom computing. It often has impressive performance and it is described in one of the example mentioned. For a key size of 270 bits, a point multiplication can be computed in 0.36 ms with a reconfigurable computing design implemented in an XC2V6000 FPGA at 66MHz while an optimized software implementation took 196.71 ms on a dual-xeon computer at 2.6 GHz. It shows that reconfigurable computing design is more that 540 times faster while its clock speeds is almost 40 times slower than the Xeon processors (Todman et al, 2005). Progress in hardware system and programming software With the emergence of technologies, many hardware systems have begun to resemble parallel computers. These systems are not designed for scalability because they consisted of a single board of one or more microprocessors connected to one or more FPGA devices. Recently, SRC-6 and SRC-7 have a parallel architecture in which used cross bar switch that can be piled for further scalability. Traditionally, highperformance computing vendors – specifically, Silicon Graphics Inc. (SGI), Cray and Linux Networx have incorporated FPGAs in their parallel architectures (Buell et al., 2007). From software perspective, developers can create the hardware kernel by using hardware description languages such as VHDL and Verilog. SRC Computers allow other hardware description languages including Carte C, Carte Fortran, Impulse Accelerated Technologies’ Impulse C, Mitrion C from Mitrionics, and Celoxica’s Handel-C. Annapolis Micro Systems’ CoreFire, Starbridge Systems’ Viva, Xilinx System Generator and DSPlogic’s reconfigurable computing toolbox are the highlevel graphical programming development tools (El-Ghazawi et al, 2008, Buell et al, 2007). Reconfigurable logic and traditional processing Reconfigurable logic consists of programmable computational matrix with a programmable interconnected network which is used within that computational matrix. There are the basic differences between reconfigurable logic and traditional processing which are described in figure 3 (Bondalapati & Prasanna, 2002). Spatial computation: the data is processed by spatially distributed the computations rather than temporally sequencing. Configurable data path: the functionality of the computational units and the interconnection network can be adapted at run-time. Distributed control: the computational units process data based on local configuration rather than an instruction broadcast to all the functional units. Distributed resources: the required resources for computation such as computational units and memory. Figure 3 Performance trends of FPGAs and microprocessors (Smith et al, 2007) Advantages of FPGAs There are number of advantages using FPGAs including speed, reduced energy power consumption. As in reconfigurable computing, hardware circuit is optimised with the application so that the power consumption will tend to be much lower than that for a general-purpose processor. FPGAs have other advantages which comprised of reduction in size, component count (and hence cost), improved time-to-market and improved flexibility and extendibility. These advantages are especially important for embedded applications (Todman et al, 2005). Limitations of FPGAs There are number of challenges in implementing reconfigurable computing. Todman et al. (2005) described three such challenges. 1. Structure of reconfigurable fabric 2. Interfaces between the fabric, processor(s) 3. Memory must be efficient There is another challenge regarding the development of computer-aided design and compilation tools that map an application to a reconfigurable computing. The problem is related to know about which part of the application is mapped to the fabric and which should be mapped to the processor (Todman et al., 2005). Few limitations of FPGAs in high performance computing should be addressed. These issues include the need of programming tools that address the overall architecture, profiling and debugging tools for parallel and reconfigurable performance. Furthermore, application-portability issues should be required to explore (Buell et al., 2007). FPGAs power applications performance FPGAs offer tremendous performance potential. They can support in number of different parallel computation applications and implemented in single clock execution time. If FPGAs are reprogrammable then they can provide on chip facility for a number of applications. Due to the presence of on-chip memory facilitate coprocessor logic’s memory access bandwidth is not restricted to the number of I/O pins present in the devices. Moreover, memory is also closely coupled to the algorithm logic so therefore, no external high-speed memory cache is needed. And due to that power-consuming cache access and coherency problems can be avoided. The use of internal memory also means that no additional I/O pins are required to increase its accessible memory size, simplifying design scaling (Altera, 2007). With the use of defined structures and the availability of resources in today’s high performance FPGAs ( i.e the Altera Stratix III family of FPGAs), they can serve as hardware for wide range of applications. As shown in Table 1 (Altera, 2007) , some of the practical examples of applications show that at least ten times improvement in execution time of algorithms as compare to single processor. Table 1 FPGA Algorithm Acceleration (Altera, 2007) FPGA application design techniques Herbordt (2007) described application design techniques to enable substantial FPGA acceleration. These methods are as follows: 1. Use an algorithm optimal for FPGAs 2. Use a computing mode appropriate for FPGAs 3. Use appropriate FPGA structures 4. Living with Amdahl’s law 5. Hide latency of independent functions 6. Use rate techniques to remove bottlenecks 7. Take advantage of FPGA-specific hardware 8. Use appropriate arithmetic precision 9. Use appropriate arithmetic mode 10. Minimize use of high-cost arithmetic operations 11. Create families of applications, not point solutions 12. Scale application for maximal use of FPGA hardware Need of highly parallel FPGAs There is a common approach in increasing performance of single unit is to build a cluster of low-cost off-the shelf machines. But there are few disadvantages like low communication bandwidth and costly. Most clusters are loosely coupled based on external peripherals and due to that it is much costly. Moreover, they are not able to solve specific problem in parallel. Another approach is related to use parallel computers and they share their resources which allow for very fast data throughput but require system design constraints to remain scalable. COPACOBANA (CostOptimized Parallel Code Breaker) utilizes up to 120 Xilinx Spartan-3 FPGAs connected through a parallel backplane and interfaces the outside world through a dedicated controller FPGA with an Ethernet interface and a Micro Blaze softprocessor core running uClinux. It uses for cryptanalysis and further work has been needed to use its architecture and framework for solving other scientific problems (Guneysu et al., 2007). COPACOBANA Architecture It consists of three basic blocks including one controller module, up to 20 FPGA modules and backbone which is used for providing interconnection between controller and FPGA modules (figure 4). Figure 4 Architecture of COPACOBANA (Guneysu et al., 2007) The FPGAs are directly connected to a common 64-bit data bus on board of the FPGA module which is interfaced to the backplane data bus via transceivers with 3state outputs. While disconnected from the bus, the FPGAs can communicate locally via the internal 64-bit bus on the DIMM module. The DIMM format allows for a very compact component layout, which is important to closely connect the modules by a bus. Every FPGA module is assigned a unique hardware address, which is accomplished by Generic Array Logic (GAL) attached to every DIMM socket. Hence, all FPGA cores can have the same configuration and all FPGA modules can have the same layout. They can easily be replaced in case of a defect. (Guneysu, 2007). Conclusion FPGAs offer a number of paradigms to speed up calculations in a hardware software co-design environment. They are relatively cost-effective as compare to ASICs and due to flexible in nature, hardware resources are utilized in an effective way. However, much work remains to be done for achieving high-performance parallel computing by using FPGAs. References Altera Cooperation White Paper (2007). Accerating high performance computing with FPGAs. October 2007 Bondalapti,K., & Prasanna,V. (2002). Reconfigurable computing systems. Proceedings of the IEEE, Vol. 90, No. 7, July, 2002. Buell, D., El-Ghazawi, T., Gaj,K.,& Kindratenko,V. (2007). High-Performance reconfigurable computing. IEEE Computer Society, March, 2007. El-Ghazawi, T., El-Araby,E., Miaoqing Huang, Gaj,K., Kindratenko, V.,& Buell, D. (2008).The promise of high-performance reconfigurable computing. IEEE computer society, February, 2008 pp. 69 -76. Guneysu,T., Paar,C., Pelzl,J., Pfieffer,G.,Schimmler,M., & Schlieffer,C. (2007). Parallel computing with low cost FPGAs A framework for COPACOBANA. Herbordt, M.C., VanCourt, T., Yongfeng, G., Shukhwani, B., Conti,A., Model,J. & Disabello,D. (2007). Achieving high performance with FPGA-Based computing Smith, M.C., Vetter,J.S., & Alam,S.R. (2005).Scientific computing beyond CPUs: FPGA implementations of common scientific kernels. MAPLD/187. Todman,T.J., Constantinides, G.A., Wilton,S.J.E, Luk,W. & Cheung, P.Y.K. (2005). Reconfigurable computing: architectures and design methods. IEEE Proceedings of Computer Digital Technologies, Vol. 152, No. 2, March, 2005. Wu-Feng, Manocha,D. (2007). High performance computing using accelerators, Parallel Computing, 33 (2007) pp. 645-647.