WRD - EmbDev.net
advertisement

Image processing using FPGA
Mrs. Sarita chauhan(assist. Professor MLVTEC, Bhilwara); sarita.mlvtec@yahoo.co.in
Bharat Singh Tanwar(final year ECE MLVTEC, Bhilwara); bharat89singh@gmail.com
Pooja Pathak (final year ECE MLVTEC, Bhilwara); pooja1990pathak@gmail.com
Namita Surana(final year ECE MLVTEC, Bhilwara); namita.surana@gmail.com
Abstract— We present an FPGA accelerator for the Non-uniform
Fast Fourier Transform, which is a technique to reconstruct
images from arbitrarily sampled data. We accelerate the
compute-intensive interpolation step of the NUFFT Gridding
algorithm by implementing it on an FPGA. In order to ensure
efficient memory performance, we present a novel FPGA
implementation for Geometric Tiling based sorting of the
arbitrary samples. The convolution is then performed by a novel
Data Translation architecture which is composed of a multi-port
local memory, dynamic coordinate-generator and a plug-andplay kernel pipeline. Our implementation is in single-precision
floating point and has been ported onto the BEE3 platform.
flexibility and the opportunity to quickly develop a prototype
of a circuit. FPGAs have an advantage in low volume
prototyping and proof of concept applications.
Keywords: Gridding algorithm, Geometric Tiling, kernel, FPGA,
NUFFT
Introduction
Data processing involving complex algorithms is increasingly
commonly, whether it is video editing, speech recognition, or
analyzing experimental data, high volumes of data must be
processed as quickly as possible. Fast Fourier Transform
(FFT) is an efficient implementation of DFT and is used, apart
from other fields, in digital image processing. Fast Fourier
Transform is applied to convert an image from the image
(spatial) domain to the frequency domain. Once the image is
transformed into the frequency domain, filters can be applied
to the image by convolutions.
Challenge: Interpolation of the arbitrary samples onto a
Cartesian grid and supporting various kernel functions.
Goal: To provide a flexible system without sacrificing
performance
Features
Computers are not optimized for any single
calculation.
Application specific integrated circuits, or ASICs,
are much faster but unfortunately are expensive to
make and require flawless designs.
High Performance
Flexibility Provides Fast Time to Market and Easy
Upgradeability
Low Development Cost
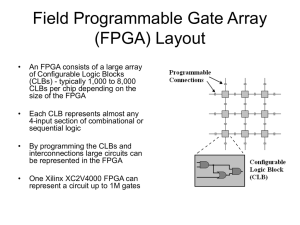
Field-programmable gate array (FPGA)
FPGAs are reconfigurable hardware chips that can be
reprogrammed to implement varied combinational and
sequential logic. Their reprogram-ability offers great
Block dia.of fpga integrated processing architecture
The FPGA integrated processing architecture shown in Figure
, consists of four units, namely,
1. Initialization unit(INU),
2. Data transfer unit (DTU),
3. Image processing unit(IPU)
4. Memory management unit (MMU).
Working: working could be understand in four steps.
1. Initialization unit
Initialization unit (INU) accesses the necessary settings stored
in the MMU for the system when system is started. When
system “start” signal is received by initialization unit,
addresses are generated to MMU , commands or parameters in
MMU are sent to Initialization unit. The commands are
The internal and external connections of 2-D convolver
3.
decoded to generate different signals to the related units for
necessary initial settings.
2.
Memory Management Unit (MMU)
MMU consists of two modules, namely,Parameter module and
image module.
Parameter module includes an internal memory for storing the
parameter initialization settings.Image module takes care of
the object image storing from IPU or the readout from
external memory to PC through DTU using IEEE 1284
standard .
Image processing unit
4. Data transfer unit
As its name suggest this unit is used to transfer the data from
one block to another.
Internal and external connections of image capturing area
Image processing unit (IPU) does the pipelined operations of
the image capturing, convolution and sorting.
IPU contains three parts, namely
image capturing,
2-D convolver, and
2-D sorters
Connections between inu, ipu, dtu & mmu
Gridding algorithm for NuFFT
The problem of handling data that falls on a nonequally
spaced grid occurs in numerous fields of science, ranging
from radio-astronomy to medical imaging. In MRI, this
condition arises when sampling under time-varying gradients
in sequences such as echo-planar imaging (EPI), spiral scans,
or radial scans. The technique currently being used to
interpolate the nonuniform samples onto a Cartesian grid is
called the gridding algorithm.
matrix expression, the computation in (1) can be described as
a matrix -vector multiplication:
G = Av;
with A = [α(t; s)]; g = [γ(t)]; v = [β(s)]
Problem Statement
Where,
T is the target array on the cartesian grid
S is the source array of arbitrary samples
G (i, j) is the kernel function
W is the convolution window
The Solution
Challenge: Memory bandwidth utilization is poor due to lack
of locality in the source array. There is a need to reorde the
arbitrary source array before convolution.
Geometric Tiling / Binning: Indexing and coarse sorting
procedure to reorder arbitrary samples into tiles / bins.
Simple tiling scheme to perform the indexing and sorting in 1
pass.
Data Translation:
Actual convolution computation on each { source, target }
tile-pair.
Computation –kernel function evaluation for each source
sample with its W x W target window
Source-centric computation for determining the target window
1. Geometric Tiling/Binning
Geometric tiling algorithm is transformation oriented towards
reducing power consumption without compromising the
numerical accuracy of the application. We shall describe the
class of matrix-vector multiplication we are concerned with.
Let T and S be two finite sets of sample points in R3. We refer
to t belongs to T as a target (point), to s belongs to S as a
source. We are provided with an interaction kernel function α
(t, s) defined on T×S and a function β(s) defined on the source
set S. We are interested in evaluating another function γ(t)
defined on the target set T as follows:
The function γ(t) describes the response at every single target
point to the function β(s) at all the source points in S. In
Geometric tiling on Cartesian grid
The matrix A has m rows and n columns, with m = T and n =
S While α(t; s) is the interaction between two points t and s, A
captures the interaction between the sets T and S. In the same
way, any sub-matrix of A is associated with a subset of T and
a subset of S and represents the
and represents the interaction between the two subsets. Such
geometric indexing can be mapped easily to the plain index
sets {1,..m} and{1,…n}.
Implementing geometric binning
It have two stream operators
Address Translator (AT)
Address Mapper (AM)
AT computes the Tile Index for each sample.To handle
arbitrary sampling, dynamic memory mapping scheme is
required.AM follows a linked-list scheme, where each node is
a source-point-group (SPG).AT and AM together map
arbitrary source samples into SPGs before doing a burst write
to DRAM.
A SPG consists of ‘p’ samples belonging to the same tile plus
a tail pointer.The local memory in the AM buffers up to ‘p’
samples per tile, appends the tail pointer and evicts the SPG .
At end of frame, Tail pointers are saved into an Address Map
table.Memory write bandwidth utilization is always
maximum.
Applications
This is used for various applications such as biomedical,
digital signal processing, image processing. In the field of
biomedical it is used in magnetic resonance imaging (MRI) in
various applications the computing models are designed by
this acceleration of nufft using FPGA.The most important
application of this is to reconstruct the images.
The FPGA-based non uniform FFT is used for numerous
applications including:
Motion detection
Optical Background Velocimetry
Target tracking
Magnetic Resonance Imagining
Conclusions
FPGAs are great fits for video and image processing
applications, such as broadcast infrastructure, medical
imaging, HD Video conferencing, video surveillance, and
Military imaging. These solutions can improve cost,
performance and productivity for many video and imaging
applications.
ACKNOWLEDGMENT:
We take immense pleasure in thanking Prof. Mr. G. K. Tyagi,
Principal , MLVTEC, Bhilwara for having full support us to
carry out this paper work.
I wish to express my deep sense of gratitude to my Internal
Guide, Mr. Neeraj Jain Lecturer, ICT Department for his
guidance and useful suggestions, which helped me in
completing the paper work, in time.
Needless to mention that Mrs. Harita Malani Assistant
Professor, MLVTEC, Bhilwara , who had been a source of
inspiration and for her timely guidance in the conduct of our
paper work. I would also like to thank Mr. Ritesh Saraswat
Assistant Professor, H.O.D , ICT Department MLVTEC,
Bhilwara for all their valuable guidance in the surfing work.
Finally, yet importantly, I would like to express my heartfelt
thanks to my beloved parents for their blessings, my
friends/classmates for their help and wishes for the successful
completion of this research.
Systems for comparasion
REFERENCES
Websites:
[1]. Betz, Vaughn. "FPGA Architecture." University of
Toronto.
<http://www.eecg.toronto.edu/~vaughn/challenge/fpga_arch.
html>.
[2]. Reda, Sherief. "RC Principles: Software." Brown
University,
Providence.
4
Oct.
2007.
4.
<http://ic.engin.brown.edu/classes/EN2911XF07/lecture08.pp5.
t>.
6.
1.
2.
3.
[5]. H. Choi and D. C. Munson, Analysis and design of
minimax-optimalinterpolators, IEEE Trans. Signal
Processing 46 (1998), 1571-1579
[3]. Fienberg, Bruce. "GiDEL Ships PROCSpark II
7. [6]. A.Dutt and V. Rokhlin, Fast Fourier tramsforms for
Development Board Featuring Altera’S Low-Cost
Non equispaced data, SIAM J. Sci. Comput. 14 (1993),
FPGAs." 25 May 2005. Altera. 18 Apr. 2008
1368{1383.
<http://www.altera.com/corporate/news_room/releases/releas
es_archive/2005/products/nr-cyclone2_procspark2.html>. 8. [7]. J. A. Fessler and B. P. Sutton, Nonuniform Fast Fourier
9.
transforms using min-max interpolation, IEEE Trans.
[4]. "PROCSpark II: Cyclone II - Based PCI Prototyping
10.
Signal Proc. 51 (2003), 560{574.
Board for Frame Grabbing, DSP, Imaging, Vision, Rapid
Prototyping."
GiDEL.
14
Apr.
2008
11. [8]. L. Greengard and J.-Y. Lee, Accelerating the Non
<http://gidel.com/procSpark%20II.htm>.
Uniform Fast Fourier Transform, SIAM Rev., 46