Unit 2 Notes - Teacher Pages
advertisement

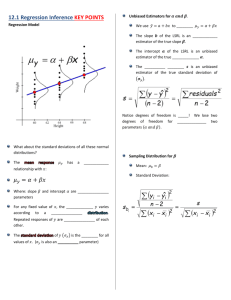
AP Stats – Unit 2 Notes(Ch. 5) : Exploring Bivariate Data Often times in statistics we want to examine the relationship between two or more variables. We will want to ask ourselves theses questions: What individuals do the data describe? What exactly are the variables? How are they measured? Are all the variables quantitative or is at least one a categorical variable? Response Variable(Dependent)– Measures an outcome of an experiment. Explanatory Variable(Independent) – Attempts to explain the observed outcomes in an experiment Scatterplots (pg 117-121)– The most effective way to display the relation between two quantitative variables. If there is a clear explanatory variable, plot it on the x-axis. The response variable is plotted on the y-axis. Each individual in the data appears as the point in the plot fixed by the values of both variables for that individual. X & Y axes should both be clearly labeled and scaled. Examining a Scatterplot Look for the overall pattern and for striking deviations from that pattern. You can describe the overall pattern in terms of form, direction, and strength. An outlier is an individual value that falls outside the overall pattern of the relationship. Form: The form describes the type of pattern that exists between the variables. The form could be linear, exponential, etc. Direction: Two variables are positively associated when above-average values of one tend to accompany above-average values of the other, and below-average values also tend to occur together (as x increases, so does y. When x decreases, so does y). Seen as a bottom left to upper right movement of points in scatterplot. Two variables are negatively associated when above-average values of one tend to accompany below-average values of the other, and vice-versa. (when x increases, y tends to decreases. When x decreases, y tends to increase). Seen as a top left to bottom right movement of points in scatterplot. Strength: Strength of a relationship is determined by how closely the points follow a clear pattern (ex. How close do the points follow a linear pattern?) *We can add categorical data to a scatterplot by using different colors or symbols to plot the points that represent different categorical data. Correlation: r (pg 200)– Measures the strength and direction of the linear relationship between the quantitative variables. r x i x y i y 1 n 1 s x s y zxz y n1 *If you notice in the formula, we are standardizing each x and y value, then multiplying those together. Facts about correlation: Correlation makes no distinction between explanatory and response variables. It makes no difference which variable you call x and which you call y. Correlation requires both variables be quantitative. Correlation uses standardized values of the observations, so it does not change when units of measurement change (from centimeters to inches, for example). Positive r values indicate positive association between the variables, negative r values indicate negative association between the variables. The correlation r is always a number between –1 and 1. The closer r is to the extremes, the stronger the relationship it. The closer it is to zero, the weaker the relationship. Correlation measures the strength of only a linear relationship between two variables. It doesn’t measure any other relationship even though it may be very strongly present. Correlation uses the mean and standard deviation in its calculation so it is also not resistant to outliers. Correlation in not a complete description of two-variable data, always give the means and standard deviations for your variables along with the correlation. Just because two variables are correlation, it doesn’t necessarily mean one CAUSES the other to change. Scatterplots and correlation See example 5.1-5.4, pg 202-206. Least-Squares Regression (pg 210) Correlation measures the strength and direction of a linear relationship. If a relationship exists, it makes sense to summarize it with a linear model. Regression Line ( ŷ ) – a straight line that describes how a response variable (y) changes as an explanatory variable (x) changes. How do we select what line will represent the relationship? The method of choice for this is known as the Least-Squares Regression Line (LSRL). The line that minimizes the sum of the squared deviations about the line is the LSRL. Properties of the LSRL The LSRL is defined as yˆ a bx The line always goes through the centroid (the point ( x, y ) ). Sy and the y-int is always a y b x The slope of the line is always b = r S x The line comes as close as possible to all the points by minimizing the sum of the squared vertical distances each point is away from the line. Ex. Say we have a set of data in which x 17.2 , y 161.1, s x 19.7, s y 33.5 , and r = .997 Sy 33.5 = .997 yˆ a bx , the slope, b = r = .9971.7 1.695 19.7 Sx the y-int, a y b x = 161.1 1.695(17.2) = 131.946 The LSRL is yˆ 131.946 1.695x See examples 5.5-5.6, pg 213-216 Interpreting the slope and y-intercept of the regression line: The slope of a line tells you how the y-values change when the x-values increase by 1 unit. The y-intercept tells you the value of the y when x = 0. When interpreting the slope and y-int for a LSRL, we must remember a couple things: o The regression line is predicting the y-values, therefore we must use terminology when interpreting the slope and y-int that indicate this. o The interpretation should always be done in context. Never use words like data, or x, or y. Also, include the units of measurement. Ex: Data was collect to study the relationship between the height(x) in inches and weight(y) in pounds of students. The LSRL was : yˆ 35 1.75 x . o Slope = 1.75 and this means as a person’s height increases by 1 inch, their weight tends to increase 1.75 lbs, on average. o Y-int = 35 and means a person who is 0 inches tall would have a predicted weight of 35 lbs (doesn’t make sense in this case because height cannot equal 0 inches) Assessing the Fit of a Line(pg 221) After fitting a regression line to a set of data, we want to ask: Is a line an appropriate way to summarize the relationship between the two variables? Are there any unusual aspects of the data set that we need to consider before proceeding to use the regression line to make predictions? How accurate can we expect predictions based on the regression line to be? Residuals – The difference between an observed value and the value predicted by the regression line. Residual = observed y – predicted y = y - ŷ See example 5.7, pg 223-224 Residual Plots – A scatterplot of the residuals against the explanatory variable (x). They help us assess the fit of a regression line. Assessing a Residual Plot If a regression line captures the overall relationship between x and y, there should be no systematic pattern in the residual plot. A curved pattern shows that the relationship is not linear. Increasing or decreasing spread about the line as x increases indicates that predictions of y will be less accurate for larger x. Individual points with large residuals are outliers in the vertical direction. Individual points that are extreme in the x direction, may not have large residuals, but they can be very important. See examples 5.8-5.9, pg 226-228 Coefficient of determination, r2 (pg 228) - The fraction (or percent) of the variation in the values of y that is explained by the least squares regression of y on x. See example 5.10, pg 229 Standard Deviation about the LSRL, se (pg 231) – The typical amount by which an observation deviates from the LSRL, and is calculated by: ( y ŷ) 2 se n2 See example 5.12, pg 231-233 Influential Observations – An outlier is an observation that lies outside the overall pattern of the other observations. An observation is influential if removing it would cause a marked charged in the correlation/regression equation. Extrapolation, (pg 214) – Using the LSRL to predict values much outside the range of x-values in the data set. Because we do not know if the pattern continues outside the given range, we should always be wary of making predictions that fall outside this range. Nonlinear Relationships and Transformations (pg 238) Not all bivariate data follows a linear pattern. When a scatterplot shows a curved pattern, or a residual plot reveals that a linear model is not appropriate, we must find a way to linearize, or “straighten” the data. We can do this by applying power or logarithmic transformations to the x and/or y data. See example 5.16, pg 245-248.