Type I error, Type II error, and Power
advertisement

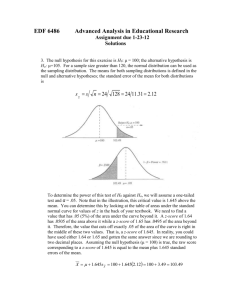
Type I error, Type II error, and Power A 5% significance test rejects H0 if z ≤ –1.645. This tells us that, if we keep drawing samples from a population, we will get x-bar more than 1.645 stdevs below the actual mean about 1 in 20 times. Power calculations help us see how large an effect the test for significance can be expected to detect. A cola company claims that each of their cans of soda has contents = 300 ml and = 3 ml. A critic claims that actually each can has an average of 295 ml. You want to test the hypothesis that the mean is indeed less than 300, so you grab a six pack from the store and calculate the mean ml per can. What Zcrit would you use for this test? What X crit does this correspond to? So we’re going to reject the null when Z < Zcrit or when X < X crit . 1. a) Let’s say the cola company was telling the truth. Simulate 1000 6-packs of “a popular cola drink” from a population of mu=300 and sigma=3. Imagine that each 6-pack is a sample. For each 6-pack, calculate its average content, get the z-score. You should have an Excel spreadsheet that looks more or less like this at the top: Average of Six Bottles Sample z Less than z-crit? 1 304.767 294.973 303.349 299.797 297.763 299.512 300.03 0.02 0 2 299.344 300.3 299.201 304.197 302.173 297.452 300.44 0.36 0 3 294.449 302.22 301.719 298.138 295.48 302.968 299.16 -0.68 0 (You should have 1000 samples of 6 cans in 1000 rows) If we set a one-sided alpha of .05, what is the z-critical? What is the z-critical converted back into ml? ml The last column is for you to check if the z-score is less than z-critical An easy way to do this is with the “IF” command, e.g. type =IF(i2 < –1.645, 1, 0) [if this doesn't work use semicolons instead of commas] into cell j2 (so You’ll get a 1 if it’s true, and a 0 if it’s false) and fill in the rest of the column, then sum over j2:j1001. In how many cases out of the 1000 does the z-score fall below the cut-off? /1000 = % So, we have a population that has a mean of 300, and the sample we randomly choose will lead us to RETAIN this null hypothesis most of the time; what is the probability of a randomly chosen sample leading us to falsely REJECT the null hypothesis? % What is this error called? 1. b) You can verify your result from part a) by back-calculating the critical value of x-bar: solve for x-bar from the z-statistics value of –1.645 x-bar= 300+ (z*)(sigma) = sqrt(n) and comparing each of Your x-bars with this critical x-bar. 2. a) Now let's say that the critic was just barely right. Repeat the simulation with a normal population of mu=299 (i.e. test the null hypothesis H0 : mu=300 against an alternative hypothesis Ha : mu=299). In how many cases out of these 1000 does the z-score fall below the cut-off? /1000 = % For what percent of these samples would you have correctly rejected the null hypothesis? For what percent of these samples would you have falsely accepted the null hypothesis? 2. b) You can check Your results against theoretical calculations based on this equation: P(x-bar ≤ [critical x-bar] when mu = 299 but mu-null = 300) = P(Z ≤ 297.98 – 300) = P(Z ≤ –.8285) = 3/sqrt(6) 3. a) Now let's say the cola company was making an egregious underfilling error. Try this again with a mu=295. What is the probability that H0 will be rejected when in fact mu=295? /1000 = % 3. b) What does this demonstrate to us about effect size? About the ease of rejecting H0? 4. Try a simulation of mu=299 with a larger variance (let’s say = 6 ml). How does this affect the power of the test? /1000 = % 5. Try the mu=299 simulation, but use N=50. What happens to the power of the test? /1000 = % 6. Try the mu=299 simulation with an alpha of 10% rather than 5% (You will have to check your simulated zscores against a different critical z-score; find it in Table E.10). What happens to the power of the test? /1000 = % 4 rules about power: 1. As effect size increases, power . 2. As variability increases, power . 3. As sample size increases, power . 4. As alpha increases, power .