RNA-seq
advertisement

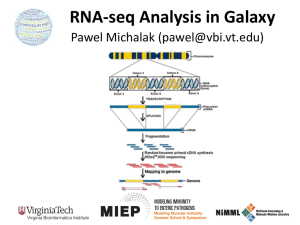
RNA-seq: Quantifying the Transcriptome Alisha Holloway, PhD Gladstone Bioinformatics Core Director What is RNA-seq? Use of high-throughput sequencing technologies to assess the RNA content of a sample. Why do an RNA-seq experiment? • Detect differential expression • Assess allele-specific expression • Quantify alternative transcript usage • Discover novel genes/transcripts, gene fusions • Profile transcriptome • Ribosome profiling to measure translation Why do an RNA-seq experiment? • Detect differential expression • Assess allele-specific expression • Quantify alternative transcript usage • Discover novel genes/transcripts, gene fusions • Profile transcriptome • Ribosome profiling to measure translation Skelly et al. 2011 Why do an RNA-seq experiment? • Detect differential expression • Assess allele-specific expression • Quantify alternative transcript usage • Discover novel genes/transcripts, gene fusions • Profile transcriptome • Ribosome profiling to measure translation Why do an RNA-seq experiment? • Detect differential expression • Assess allele-specific expression • Quantify alternative transcript usage • Discover novel genes/transcripts, gene fusions • Profile transcriptome • Ribosome profiling to measure translation Why do an RNA-seq experiment? • Detect differential expression • Assess allele-specific expression • Quantify alternative transcript usage • Discover novel genes/transcripts, gene fusions • Profile transcriptome • Ribosome profiling to measure translation Pluripotent Stem Cell Cardiogenic Cardiac Cardiomyocytes Mesoderm Precursors Why do an RNA-seq experiment? • Detect differential expression • Assess allele-specific expression • Quantify alternative transcript usage • Discover novel genes/transcripts, gene fusions • Profile transcriptome • Ribosome profiling to measure translation More later! Ingolia et al. 2009, Weissman Lab Choose the right technology RNA-seq Microarray ID novel genes, transcripts, & exons Well vetted QC and analysis methods Greater dynamic range Less bias due to genetic variation Repeatable Well characterized biases Quick turnaround from established core facilities Currently less expensive No species-specific primer/probe design More accurate relative to qPCR Many more applications RNA-seq dynamic range and accuracy RNA-seq vs. Affy Marioni et al. 2008 RNA-seq vs. Taqman qPCR © 2010 NuGen Which sequencing technology to use? Illumina Pac-Bio Read length 100 bp paired end 2500 bp avg Throughput 200 million read pairs/lane <1% 1 million reads/ SMRT cell 15% total, most are indels, 4% SNP $7-8k/sample Error rate Cost Accessibility Uses $900/sample USCF, UC-Davis, BGI; UC-Davis; no many kits available kits/protocols available DE, ASE, Alternative Characterize splicing transcriptome When to use Pac-Bio The wet lab side…briefly New methods to keep info on strand of template too. Plan it well. • Experimental design – Biological replicates – Reference genome? – Good gene annotation? • • • • Read depth Barcoding Read length Paired vs. single-end Biological variation Technical variation Plan it well. • Experimental design – Biological replicates – Reference genome? – Good gene annotation? • • • • Read depth Barcode/Index Read length Paired vs. single-end Plan it well. • Experimental design – Biological replicates – Reference genome? – Good gene annotation? • • • • Read depth Barcode/Index Read length Paired vs. single-end How much data do we need? • ~15-20K genes expressed in a tissue | cell line. • Genes are on average 3KB • For 1x coverage using 100 bp reads, would need 600K sequence reads • In reality, we need MUCH higher coverage to accurately estimate gene expression levels. • 30-50 million reads Plan it well. • Experimental design – Biological replicates – Reference genome? – Good gene annotation? • • • • Read depth Barcode/Index Read length Paired vs. single-end 180-200 million reads / lane Run 3-4 samples / lane Plan it well. • Experimental design – Biological replicates – Reference genome? – Good gene annotation? • • • • Read depth Barcoding Read length Paired vs. single-end Uniq seq = 4read length Read length Unique seq 25 1.1x1015 50 1.3x1030 100 1.6x1060 ~60 million coding bases in vertebrate genome Plan it well. • Experimental design – Biological replicates – Reference genome? – Good gene annotation? • • • • Read depth Barcoding Read length Paired vs. single-end Power of paired-end reads • Huge impact on read mapping – Pairs give two locations to determine whether read is unique • Critical for estimating transcript-level abundance – Increases number of splice junction spanning reads Distribution of cDNA fragment sizes 200 bp 100 bp • Size select 200-300 bp cDNA fragments • Reads are usually 50 bp • Inner mate distance would be 100-200 bp on average. Ends map to different locations Paired end sequencing allows you to reliably call and remove duplicates. How do you make sense of this pile of data? • QC • Alignment • Analysis – Stats – Hypothesis tests – Combine with other data • Visualization QC • FastQC – Before alignment – http://www.bioinformatics.babraham.ac.uk/projects/fastqc/ • RNA-SeQC – After alignment – https://confluence.broadinstitute.org/display/CGATools/RNA-SeQC • Proportion of reads that mapped uniquely – Remove duplicates; likely due to PCR amp. • Assess ribosomal RNA and possible contaminant content – human RNA (if not human samples) – Mycoplasma (if cell lines) Base quality over reads High quality Red: high density Blue: low density Low quality Position along read Mapped reads summary Sample Name Total Records Optical duplicates PCR duplicates % duplication Unmapped reads Uniquely mapping reads Read-1 uniquely mapping Read-2 uniquely mapping Concordant reads pairs mapped Reads map to “+” Reads map to “-” Non-splice reads Splice reads Annotation of reads Distribution of reads over gene body Normalized by gene length Then what? • Align reads to the genome – Easy(ish) for genomic sequence – Difficult for transcripts with splice junctions Alignment Algorithms • Bowtie (Langmead et al 2009) – BWT, multiseed heuristic alignment • BWA (Li and Durbin 2009) – BWT, Smith-Waterman alignment • SOAP2 (Li et al. 2009) – BWT, proprietary alignment algorithm • BFAST (Homer at al. 2009, based on BLAT) – multiple indexes, finds candidate alignment locations using seed and extend, followed by a gapped Smith-Waterman local alignment for each candidate http://en.wikipedia.org/wiki/List_of_sequence_alignment_software Burrows-Wheeler Transform (compression to reduce memory footprint) Alignment tools for splice junction mapping • • • • Tophat MapSplice SpliceMap HMMsplicer Tophat • Map reads to transcriptome using Bowtie • Map to genome to discover novel exons – or start here if no annotation available • Split reads to smaller segments; map to genome to discover novel splice junctions • Report best alignment for each read Trapnell et al. Bioinformatics 2009; Trapnell et al. Nature Protocols 2012 MapSplice & SpliceMap • Tag alignment (user chooses aligner) – Break reads into segments – Map reads – Unmapped segments considered for splice junction mapping based on location of partner segment – Merge segments from read for final alignment • Assess splice junction quality Wang et al. NAR 2010, Au et al. NAR 2010 HMMsplicer Local Source! Dimon et al. PLoS One 2010 Compare tools for splice junction mapping Splice Junction Mapper Junction s Prop. Junctions Bowtie map to known transcriptome (control) SpliceMap Tophat – no annotation Tophat – annotation, no novel junctions Tophat – annotation, novel junctions 23,037 21,990 20,196 22,544 22,599 0.955 0.877 0.979 0.981 Difficult to get a false positive rate because you don’t know what your annotation is missing. Transcript Assignment Aligned contiguous and spliced reads Build graph to connect neighboring concordant alignments Traverse graph to assemble variants Assembled isoforms Martin & Wang, Nature Reviews Genetics 2011 Transcript Assignment &|Abundance Tools • Assembly uses annotation – Cufflinks – MISO • De novo assembly – Cufflinks – Trans-ABySS – Trinity – Maker Cufflinks • Constructs the parsimonious set of transcripts that explain the reads observed. Basically, finds a minimum path cover on the DAG. • Derives a likelihood for the abundances of a set of transcripts given a set of fragments. • FPKM – fragments per kb of exon per million fragments mapped. Trapnell, Pachter MISO • Mixture of Isoforms • Bayesian – treats expression level of set of isoforms as random variable and estimates a distribution over the values of this variable. • Gives confidence intervals for expression estimates and measures of DE as Bayes factors Burge Lab @ MIT Bias Correction and Normalization • Random hexamer bias (Hansen et al. 2010) – From PCR or RT primers – Re-estimate read counts to account for bias • Resources for normalization – Bullard et al. 2010 – http://www.rnaseqblog.com/dataanalysis/which-methodshould-you-use-fornormalization-of-rna-seqdata/ Differential Expression • Goal: determine whether observed difference in read counts is greater than would be expected due to random variation. • If reads independently sampled from population, reads would follow multinomial distribution appx by Poisson Pr(X = k) = le k -l k! Differential Expression • BUT! We know that the count data show more variance than expected • Overdispersion problem mitigated by using the negative binomial distribution, which is determined by mean and variance Kij @ NB(mij , s ) 2 ij Sample j, gene i Differential Expression • Binomial test – Old Cuffdiff or if no replicates • Negative binomial – DESeq – estimate variance using all genes with similar expression levels – Cuffdiff – sim to DESeq, but incorp fragment assignment uncertainty simultaneously – EdgeR - moderate variance over all genes • T-test Use replicates to capture biological variation KO KO1 KO2 KO3 WT1 WT2 WT3 Pool gene RPM RPM RPM RPM RPM RPM RPM Hk2 65 299 211 0.633 9.29E-03 Col1a1 171 162 178 326 160 324 511 810 0.301 1.23E-13 1095 655 0.011 5.16E-23 Slc2a1 162 78 59 59 87 WT Pool Replicate Pool RPM adj Pval adj Pval 569 286 240 160 278 217 • Counts per sample have overlapping distribution • Pooled counts show difference between KO and WT • Biological variance is ignored in pooled analysis. Differential Expression Old cuffdiff Some biology, finally? • How have gene expression patterns have changed during the course of differentiation? • Which genes are specific to certain cell types? • What can we learn about what those coexpressed genes do? Clusters of co-expressed genes • Use unsupervised clustering to group genes by expression pattern • Use gene ontology information to determine which kinds of genes are in each group • Reveal novel associations and gene types Clusters of co-expressed genes Pluripotency/stem cell: Nanog, Oct4 Mesoderm/cell fate commitment: Mesp1, Eomes Cardiac precursors: Isl1, Mef2c, Wnt2 Cardiac structure/function: Actc1, Ryr2, Tnni3 Thanks for listening! Alisha Holloway Gladstone Institutes Bioinformatics Core alisha.holloway@gladstone.ucsf.edu