Regression revisited
advertisement

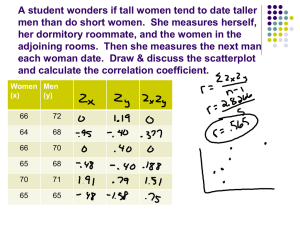
Regression revisited FPP 11 and 12 and a little more Statistical modeling Often researchers seek to explain or predict one variable from others. In most contexts, it is impossible to do this perfectly: too much we don’t know. Use mathematical models that describe relationships as best we can. Incorporate chance error into models so that we can incorporate uncertainty in our explanations/predictions Linear regression Linear regression is probably the most common statistical model Idea is like regression lines from Chapter 10. But, the slope and intercept from a regression line are estimates of that true line (just like a sample mean is an estimate of a population mean). Hence, we can make inference (confidence intervals and hypothesis tests) for the true slope and true intrecept Linear regression Often relationships are described reasonably well by a linear trend. Linear regression allows us to estimate these trends Plan of attack Pose regression model and investigate assumptions Estimate regression parameters from data Use hypothesis testing and confidence interval ideas to determine if the relationship between two variables has occurred by chance alone Regression with multiple predictors Regression terminology Typically, we label the outcome variable as Y and the predictor as X . Synonyms for outcome variables: response variable, dependent variables Synonyms for predictor variables explanatory variables, independent variables, covariates Some notation Recall the regression line or least squares line notation from earlier in the class y x α denotes the population intercept βdenotes the population slope Sample regression line If we collect a sample from some population and use sample values to calculate a regression line, then there is uncertainty associated with the sample slope and intercept estimates. The following notation is used to denote the sample regression line yˆ a bx Motivating example A forest service official needs to determine the total volume of lumber on a piece of forest land Any ideas on how she might do this? Motivating example A forest service official needs to determine the total volume of lumber on a piece of forest land Any ideas on how she might do this that doesn’t require cutting down lots of trees? She hopes predicting volume of wood from tree diameter for individual trees will help determine total volume for the piece of forest land. She investigates, “Can the volume of wood for a tree be predicted by its diameter?” Motivating example First she randomly samples 31 trees and measures the diameter of each tree and then its volume. Then she constructs a scatter plot of the data collected and checks for a linear pattern Is relationship linear? We know how to estimate the slope and intercept of the line that “best” fits the data But Motivating example What would happen if the forest service agent took another sample of 31 trees? Would the slope change? Would the intercept change? What about a third sample of 31 trees? a and b are statistics and are dependent on a sample We know how to compute them They are also estimates of a population intercept and slope Mathematics of regression model To accommodate the added uncertainty associated with the regression line we add one more term to the model y i x i i , where i comes from N(0, ) This model specification has three assumptions 1. the average value of Y for each X falls on line 2. the deviations don’t depend on X 3. the deviations from the straight line follow a normal curve 4. all units are independent The mechanics of regression Questions we aim to answer How do we perform statistical inference on the intercept and slope of the regression line? What is a typical deviation from the regression line? How do we know the regression line explains the data well? Estimating intercept and slope From early in the semester recall that the intercept and slope estimates for the line of “best” fit are 16.46 br 0.97 5.07 3.14 SDx SDy a y bx 30.14 5.08(13.25) 37.02 yˆ 37.02 5.07x Root mean square error (RMSE) What is the typical deviation from the regression line for a given x? The typical deviation is denoted by The root mean square error (RMSE) is a measure of the typical deviation from the regression line for a given x For the trees data this is 4.28 A tree with a diameter of 15 inches can be expected to have a volume of -37.02 + 5.07(15) = 39.03 cubic inches give or take about 4.28 cubic inches JMP output Residuals are used to compute RMSE The deviation of each yi from the line is called a residual that we will denote by di di y i yˆ i y i (a bx i ) An estimate of that is used in most software packages is denoted by n 1 2 s di n 2 i1 Significant tests and CIs Going back to the example of trees sampled from the plot of land. The sampled trees are one possible random sample from all trees in the plot of land Questions: What is a likely range for the population regression slope? Does the sample regression slope provide enough evidence to say with conviction that the population slope doesn’t equal zero? Why zero? CI for slope Est. ± multiplier*SE Same old friend in a new hat We will use the sample slope as an estimate The multiplier is found from a t-distribution with (n-2) degress of freedom The SE of the slope (not to be confused with RMSE) is SEb s n 2 (x x ) i i1 CI slope A 95% confidence interval for the population slope between diameter of tree and volume is b multiplier*SEb 5.07 multiplier*0.249567 Where does the multiplier value come from? We use the the t-table and find column with n-2 degrees of freedom and match with desired confidence level But with 31-2=29 d.f. we are not able to use t-table. So use normal 5.07 1.96*0.249567 (4.58, 5.56) CI of slope We found that a 95% confidence interval for is (4.58, 5.56). What is the interpretation of this interval? 95% confident that the population slope that describes the relationship between a tree’s diameter and its lumber volume is between 4.58 and 5.56 inches. What does the statement “95% Confidence” mean (this is the same thing as statistical confidence) We are confident that the method used will give correct results in 95% of all possible samples. That is, 95% of all samples will produce confidence intervals that contain the true population slope. Hypothesis test for existence of linear relationship What parameter (αorβ) should we test to determine whether X is useful in predicting Y? We want to test: H0: There is NO linear relationship between two numerical variables (X is NOT useful for predicting Y) Ha: There is a linear relationship between two numerical variables (X is useful for predicting Y) Draw the picture Hypothesis test for existence of linear relationship What parameter (αorβ) should we test to determine whether X is useful in predicting Y? We want to test: H0: There is NO linear relationship between two numerical variables (X is NOT useful for predicting Y) Ha: There is a linear relationship between two numerical variables (X is useful for predicting Y) Draw the picture The hypothesis can also be stated as Ho: = 0 vs. Ho: 0 Hypothesis test The test statistic is t est. hyp. 5.07 0 20.31 SE .2495 To find the p-value associated with this test statistic, we find the area under a t-curve with (n-2) degrees of freedom. According to JMP, this p-value equals smaller than 0.0001. According to the table it is smaller than 0.0005 Hence, there is strong evidence against the null. Conclude that the sample regression slope is not consistent with a population regression slope being equal to zero. There does appear to be a relationship between the diameter of a tree and its volume. JMP output How well does regression model fit data? Do determine this we need to check the assumptions made when using the model. Recall that the regression assumptions are 1. The average value of Y for each X falls on a line (i.e. the relationship between Y and X is linear) 2. The deviations (RMSE) are the same for all X 3. For any X, the distribution of Y around its mean is a normal curve. 4. All units are independent Check the regression fit to the data When the assumptions are true, values of the residuals should reflect chance error. That is, there should be only random patterns in the residuals. Check this by plotting the residuals versus the predictor If there is a non-random pattern in this plot, assumptions might be violated Diagnosing residual plots When pattern in residuals around the horizontal line at zero is: Curved (e.g. parabolic shape): Assumption 1 (slide 25) is violated Fan-shaped: Assumption 2 (slide 25) is violated Filled with many outliers: Assumption 2 (slide 25) is violated Possible patterns in Residual Plots Residual plot Do the residuals look randomly scattered? Or is there some pattern? Is there spread of the points similar at different values of diameter One number summary of regression fit R2 is the percentage of variation in Y’s explained by the regression line R2 lies between 0 and 1 Values near 1 indicate regression predicts y’s in data set very closely Values near 0 indicate regression does not predict the y’s in the data set very closely Interpretation in tree example We get a R2 = 0.93. Hence, the regression line between diameter and volume explains 93% of the variability volume Caution about R2 Don’t rely exclusively on R2 as a measure of the goodness of fit of the regression. It can be large even when assumptions are violated Always check the assumptions with residual plots before accepting any regression model Predictions from regression To predict an outcome for a unit with unobserved Y but known X, use the fitted regression model yˆ a bx Example from the tree data: Predict volume from a tree that has a 15 inch yˆ 37.02 5.07x 32.02 5.07(15) 44.03 in3 Recall warnings Predicting Y at values of X beyond the range of the X’s in the data is dangerous (extrapolation) Association doesn’t imply causation Influential points/outliers Fit model with and with out point to see if estimates change Often we aren’t interested in the intercept Ecological inference Regression fits for aggregated data tend to show stronger relationships With census data there is no sampling variability (we’ve exhausted the population) There is no standard error Sometimes census data are viewed as a random sample from a hypothetical “super-population”. In this case the census data provide inferences about the super-population When using time as the X variable care must be taken as the independent unit assumption is often not valid Most likely will need to use special models