ppt
advertisement

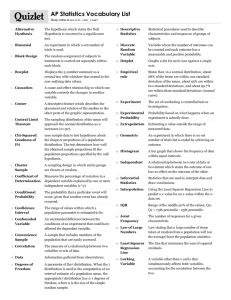
Introduction to Inferential Statistics Statistical analyses are initially divided into: Descriptive Statistics or Inferential Statistics. Descriptive Statistics are used to organize and/or summarize the parameters associated with data collection (e.g., mean, median, mode, variance, standard deviation) Inferential Statistics are used to infer information about the relationship between multiple samples or between a sample and a population (e.g., t-test, ANOVA, Chi Square). The Scientific Method uses Inferential Statistics to determine if the independent variable has caused a significant change in the dependent variable and if that change can be generalizable to the larger population. If a dependent variable within the population is normally distributed and we can calculate or estimate the mean and standard deviation of the population, then we can use probabilities to determine significance of these relationships. To begin we must collect a representative sample of our much larger population. Sampling A Representative Sample means that all significant subgroups of the population are represented in the sample. Random Sampling is used to increase the chances of obtaining a representative sample. It assures that everyone in the population of interest is equally likely to be chosen as a subject. Random Number Generators or Tables are used to select random samples. Each number must have the same probability of occurring as any other number. The larger the random sample, the more likely it will be representative of the population. Sampling Distribution Generalization refers to the degree to which the mean of a representative sample is similar to or deviates from the mean of the larger population. This generalization is based on a distribution of sample means for all possible random samples. This distribution is called a Sampling Distribution. It describes the variability of sample means that could occur just by chance and thereby serves as a frame of reference for generalizing from a single sample mean to a population mean. It allows us to determine whether, given the variability among all possible sample means, the one observed sample mean can be viewed as a common outcome (not statistically significant) or as a rare outcome (statistically significant). All possible random samples of even a modest size population would consist of a very large number of possibilities and would be virtually impossible to calculate by hand. Therefore we use statistical theory to estimate the parameters. Sampling Distribution The Central Limit Theorem states that the distribution of sample means approaches a normal distribution when n is large. In such a distribution of unlimited number of sample means, the mean of the sample means will equal the population mean. Standard Error of the Mean The standard deviation of the distribution of sample means is called the Standard Error of the Mean or Standard Error for short. It is represented by the following formula: Since the standard deviation of the population is often unavailable, a good estimate of the standard error uses the standard deviation of the sample (s). This newly modified formula of the Standard Error is shown below: Statistical Significance Now that we have the parameters of the Sampling Distribution we can see how to use this distribution to determine if the mean difference between two samples or between a sample and a population are significantly different from each other. The Research Hypothesis (H1) states that the sample means of the groups are significantly different from one another. The Null Hypothesis (H0) states that there is no real difference between the sample means. Anytime you observe a difference in behavior between groups, it may exist for two reasons: 1.) there is a real difference between the groups, or 2.) there is no real difference between the groups, the results are due to error involved in sampling. This error can be described in two ways: Type I error is when you reject the null hypothesis when shouldn't have Type II error is when you fail to reject the null hypothesis when you should have Statistical Significance The probability of committing a Type I error is designated by alpha. An alpha level of 0.05 is reasonable and widely accepted by all scientists. The null hypothesis can be rejected if there is less than 0.05 probability of committing a Type I error ( p < .05 ). Two-Tailed Hypothesis If the research hypothesis does not predict a direction of the results, we say it is a Two-Tailed Hypothesis because it is predicting that alpha will be split between both tails of the distribution. If the sample mean falls in either of these areas we can reject the null hypothesis. This is shown below: One-Tailed Hypothesis If the scientific hypothesis predicts a direction of the results, we say it is a OneTailed Hypothesis because it is predicting that alpha will fall only in one specific directional tail. If the sample mean falls in this area we can reject the null hypothesis. This is shown below: