Linear discriminant functions
advertisement

Introduction to Pattern Recognition for Human ICT
Linear discriminant functions
2014. 11. 7
Hyunki Hong
Contents
•
Perceptron learning
•
Minimum squared error (MSE) solution
•
Least-mean squares (LMS) rule
•
Ho-Kashyap procedure
Linear discriminant functions
• The objective of this lecture is to present methods for
learning linear discriminant functions of the form.
where 𝑤 is the weight vector and 𝑤0 is the threshold weight or
bias.
- The discriminant functions will be derived in a nonparametric fashion, that is, no assumptions will be made
about the underlying densities.
– For convenience, we will focus on the binary classification
problem.
– Extension to the multi-category case can be easily achieved
by
1. Using 𝜔𝑖/┌𝜔𝑖 dichotomies
2. Using 𝜔𝑖/𝜔𝑗 dichotomies
Dichotomy: splitting a whole into exactly two nonoverlapping parts. a procedure in which a whole is
divided into two parts.
Gradient descent
• general method for function minimization
– Recall that the minimum of a function 𝐽(𝑥) is defined by the
zeros of the gradient.
1. Only in special cases this minimization function has a closed
form solution.
2. In some other cases, a closed form solution may exist, but is
numerically ill-posed or impractical (e.g., memory
requirements).
– Gradient descent finds the minimum in
an iterative fashion by moving in the
direction of steepest descent.
where 𝜂 is a learning rate.
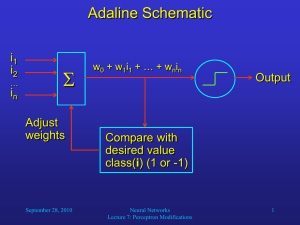
Perceptron learning
• Let’s now consider the problem of learning a binary
classification problem with a linear discriminant function.
– As usual, assume we have a dataset 𝑥 = {𝑥(1, 𝑥(2, …, 𝑥(𝑁 }
containing examples from the two classes.
– For convenience, we will absorb the intercept 𝑤0 by
augmenting the feature vector 𝑥 with an additional constant
dimension.
- Keep in mind that our objective is to find a vector a such that
– To simplify the derivation, we will “normalize” the training set
by replacing all examples from class 𝜔2 by their negative
- This allows us to ignore class labels and look for vector 𝑎
such that
• To find a solution we must first define an objective
function 𝐽(𝑎)
– A good choice is what is known as the Perceptron criterion
function
, where 𝑌𝑀 is the set of examples misclassified by 𝑎.
Note that 𝐽𝑃(𝑎) is non-negative since 𝑎𝑇𝑦 < 0 for all misclassified
samples.
• To find the minimum of this function, we use gradient
descent
– The gradient is defined by
- And the gradient descent update rule becomes
- This is known as the perceptron batch update rule.
1. The weight vector may also be updated in an “on-line” fashion,
this is, after the presentation of each individual example
𝑎(𝑘+1) = 𝑎(𝑘) + 𝜂𝑦 (𝑖
where 𝑦(𝑖 is an example that has been misclassified by 𝑎(𝑘).
Perceptron learning
• If classes are linearly separable, the perceptron rule is
guaranteed to converge to a valid solution.
– Some version of the perceptron rule use a variable learning
rate 𝜂(𝑘).
– In this case, convergence is guaranteed only under certain
conditions.
• However, if the two classes are not linearly separable, the
perceptron rule will not converge
– Since no weight vector a can correctly classify every sample
in a non-separable dataset, the corrections in the perceptron
rule will never cease.
– One ad-hoc solution to this problem is to enforce convergence
by using variable learning rates 𝜂(𝑘) that approach zero as 𝑘
→∞.
Minimum Squared Error (MSE) solution
• The classical MSE criterion provides an alternative to
the perceptron rule.
– The perceptron rule seeks a weight vector 𝑎𝑇 such that
𝑎𝑇𝑦(𝑖 > 0
The perceptron rule only considers misclassified samples,
since these are the only ones that violate the above
inequality.
– Instead, the MSE criterion looks for a solution to the
equality 𝑎𝑇𝑦 (𝑖 = 𝑏(𝑖 , where 𝑏(𝑖 are some pre-specified target
values (e.g., class labels).
As a result, the MSE solution uses ALL of the samples in
the training set.
• The system of equations solved by MSE is
– where 𝑎 is the weight vector, each row in 𝑌 is a training
example, and each row in b is the corresponding class label.
1. For consistency, we will continue assuming that examples
from class 𝜔2 have been replaced by their negative vector,
although this is not a requirement for the MSE solution.
• An exact solution to 𝑌𝑎 = 𝑏 can sometimes be found.
– If the number of (independent) equations (𝑁) is equal to the
number of unknowns (𝐷+1), the exact solution is defined by
𝑎 = 𝑌−1𝑏
– In practice, however, 𝑌 will be singular so its inverse does
not exist.
𝑌 will commonly have more rows (examples) than columns
(unknowns), which yields an over-determined system, for
which an exact solution cannot be found.
• The solution in this case is to minimizes some function of
the error between the model (𝑎𝑌) and the desired output
(𝑏).
– In particular, MSE seeks to Minimize the sum Squared Error
which, as usual, can be found by setting its gradient to zero.
The pseudo-inverse solution
• The gradient of the objective function is
– with zeros defined by 𝑌𝑇𝑌𝑎 = 𝑌𝑇𝑏
– Notice that 𝑌𝑇𝑌 is now a square matrix!.
• If 𝑌𝑇𝑌 is nonsingular, the MSE solution becomes
– where 𝑌† = (𝑌𝑇𝑌)−1𝑌𝑇 is known as the pseudo-inverse of 𝑌
since 𝑌†𝑌 = 𝐼.
Note that, in general, 𝑌𝑌† ≠ 𝐼.
Least-mean-squares solution
• The objective function 𝐽𝑀𝑆𝐸(𝑎) can also be minimize using a
gradient descent procedure.
– This avoids the problems that arise when 𝑌𝑇𝑌 is singular.
– In addition, it also avoids the need for working with large
matrices.
• Looking at the expression of the gradient, the obvious
update rule is
𝑎(𝑘+1) = 𝑎(𝑘) + 𝜂(𝑘)𝑌𝑇(𝑏− 𝑌𝑎(𝑘))
– It can be shown that if 𝜂(𝑘) = 𝜂(1)/𝑘, where 𝜂(1) is any positive
constant, this rule generates a sequence of vectors that
converge to a solution to 𝑌𝑇(𝑌𝑎−𝑏) = 0.
– The storage requirements of this algorithm can be reduced by
considering each sample sequentially.
𝑎(𝑘+1) = 𝑎(𝑘) + 𝜂(𝑘)(𝑏(𝑖 − 𝑦(𝑖 𝑎(𝑘))𝑦(𝑖
– This is known as the Widrow-Hoff, least-mean-squares (LMS)
or delta rule.
Numerical example
Summary: perceptron vs. MSE
• Perceptron rule
– The perceptron rule always finds a solution if the classes are
linearly separable, but does not converge if the classes are
non-separable
• MSE criterion
– The MSE solution has guaranteed convergence, but it may not
find a separating hyperplane if classes are linearly separable.
Notice that MSE tries to minimize the sum of the squares of the
distances of the training data to the separating hyperplane, as
opposed to finding this hyperplane.
학습 내용
선형 판별함수
판별함수와 패턴인식
판별함수의 형태
판별함수와 결정영역
판별함수의 학습
최소제곱법
퍼셉트론 학습
매트랩을 이용한 선형 판별함수 실험
1) 판별함수
이(binary) 분류 문제
하나의 판별함수 g(x)
다중 클래스 분류 문제
클래스별 판별함수 gi(x)
2) 판별함수의 형태
1. 직선 형태의 선형 판별함수 (고차원 공간의 경우 초평면)
n차원 입력 특징벡터 x = [x1, x2, …, xn]T
클래스 Ci의 선형 판별함수
wi 초평면의 기울기를 결정하는 벡터 (초평면의 법선 벡터)
wi0 x = 0인 원점에서 직선까지의 거리를 결정하는 바이어스
wi , wi0 : 결정경계의 위치를 결정하는 파라미터 (2차원: 직선 방정식)
3) 판별함수의 형태
2. 다항식 형태의 판별함수 (보다 일반적인 형태)
클래스 Ci에 대한 이차 다항식 형태의 판별함수
Wi : 벡터 x의 두 원소들로 구성된 2차항 들의 계수의 행렬.
n차원은 n(n+1)/2개 원소
n차원 입력 데이터의 경우 추정해야 할 파라미터의 개수 : n(n+1)/2+n+1개
p차 다항식 O(np)
계산량의 증가, 추정의 정확도 저하
4) 판별함수의 형태
→ 선형 분류기 제약점 +다항식 분류기의 파라미터 수의 문제 해결
3. 비선형 기저(basis) 함수의 선형합을 이용한 판별함수
판별함수의 형태 결정:
삼각함수
가우시안 함수
하이퍼탄젠트 함수
시그모이드 함수
…
5) 판별함수의 형태
판별함수와 그에 따른 결정경계
(b)
(a
)
선형함수
(c
)
2차 다항식
삼각함수
6) 판별함수와 결정영역
결정영역
(a)
(b)
2
1
C1
C2
1
2
C2
C1
7) 판별함수와 결정영역
입력특징이 각 클래스에 속하는 여부를 결정: 일대다 방식 (one-to-all method)
g1 ( x) 0
g1 0
3
g1 0
?
g1 or g3 ?
?
1
?
g2 0
g 0
g 2 ( x) 0 2
?
2
g3 0
g3 ( x) 0
g3 0
미결정영역: 모든 판별함수에
음수
모호한 영역: 두 판별함수에
양수
g1 or g2 ?
8) 판별함수와 결정영역
임의의 (가능한) 두 클래스 쌍에 대한 판별함수
클래스 수가 m개
: 판별식 m(m -1)/2개 필요
g12 ( x) 0
C1
C2
일대일 방식
(one-to-one method)
1
C1
?
C3
2
C2
g 23 ( x) 0
C3
3
g13 ( x) 0
미결정영역: 모든 판별함수에
음수
9) 판별함수와 결정영역
클래스별 판별함수
결정규칙
판별함수의 동시 학습이 필요
g 2 ( x) 0
g 2 g3 0
3
g1 g3 0
g3 ( x) 0
1
2
g1 ( x) 0
g1 g2 0
판별함수의 학습
1) 최소제곱법
판별함수
학습 데이터 집합
파라미터 벡터
판별함수 gi의 목표출력값
ξj가 클래스 Ci에 속하면, 목표출력값 tji = 1
판별함수 gi의 목적함수(“오차함수”)
판별함수 출력값과 목표출력값 차이의 제곱
“최소제곱법”
2) 최소제곱법
큰 입력 차원, 많은 데이터
행렬 계산에 많은 시간 소요
“순차적 반복 알고리즘”
한 번에 하나의 데이터 에 대해 제곱오차를 감소시키는
방향으로 파라미터를 반복적으로 수정
→ 오차함수의 기울기를 따라서 오차값이 줄어드는 방향으로
3) 최소제곱법
파라미터의 변화량
파라미터 수정식 (τ+1번째 파라미터)
학습률
learning rate
“최소평균제곱(Least Mean Square) 알고리즘”
: 입력과 원하는 출력과의 입출력 매핑을 가장 잘 근사하는 선형함수 찾기
기저함수의 선형합에 의한 판별함수의 경우
: 입력 벡터 x 대신, 기저 함수를 이용한 매핑값인 ф(x) 사용
4) 퍼셉트론(perceptron) 학습
Rosenblatt
인간 뇌의 정보처리 방식을 모방하여 만든 인공신경회로망의 기초
적인 모델
입력 x에 대한 i번째 출력 yi 결정
동일
선형 판별함수를 이용한 결정규칙
5) 퍼셉트론 학습
M개의 패턴 분류 문제
• 각 클래스별로 하나의 출력을 정의하여 모두 M개의 퍼셉트론
판별함수를 정의
• 학습 데이터를 이용하여 원하는 출력을 내도록 파라미터 조정
: i 번째 클래스에 속하는 입력 들어오면, 이에 해당하는 출력 yi만 1, 나머지는 모두 0되도록
목표출력값 ti 정의
파라미터 수정식
6) 퍼셉트론 학습
퍼셉트론 학습에 의한 결정경계의 변화
원래 “·”는 클래스 C1에 속하고 목표값은 1, “o”는 클래스 C2 속하고 목표값은 0
(a)
(b)
x (1)
(c)
w (1) x (1)
w
w (1)
( 0)
w
( 2)
x
( 2)
w ( 2)
x ( 2)
1 2
1 2
(a)
x(1)의 목표출력값 t가 0이지만,
현재 출력값은 1.
→ w(1) = w(0) + η(ti - yi) x(1) = - η x(1)
(b)
이 경우는 반대.
→ w(2) = w(1) + η(ti - yi) x(2) = η x(2)
1 2
7) 퍼셉트론 학습
매트랩을 이용한 퍼셉트론 분류기 실험
1) 데이터 생성 및 학습 결과
NumD=10;
학습 데이터의 생성
train_c1 = randn(NumD,2);
train_c2 = randn(NumD,2)+repmat([2.5,2.5],NumD,1);
train=[train_c1; train_c2];
train_out(1:NumD,1)=zeros(NumD,1);
train_out(1+NumD:2*NumD,1)=zeros(NumD,1)+1;
plot(train(1:NumD,1), train(1:NumD,2),'r*'); hold on
plot(train(1+NumD:2*NumD,1), train(1+NumD:NumD*2,2),'o');
학습 데이터
2) 퍼셉트론 학습 프로그램
퍼셉트론 학습
Mstep=5;
% 최대 반복횟수 설정
INP=2; OUT=1;
% 입출력 차원 설정
w=rand(INP,1)*0.4-0.2; wo=rand(1)*0.4-0.2; % 파라미터 초기화
a=[-3:0.1:6];
% 결정경계의 출력
plot(a, (-w(1,1)*a-wo)/w(2,1));
eta=0.5;
% 학습률 설정
for j = 2:Mstep
% 모든 학습 데이터에 대해 반복횟수만큼 학습 반복
for i=1:NumD*2
x=train(i,:); ry=train_out(i,1);
학습에
따른 출력
결정경계의
y=stepf(x*w+wo);
% 퍼셉트론
계산 변화
e=ry-y;
% 오차 계산
E(i,1)=e;
dw= eta*e*x';
% 파라미터 수정량 계산
dwo= eta*e*1;
w=w+dw;
% 파라미터 수정
wo=wo+dwo;
end
plot(a, (-w(1,1)*a-wo)/w(2,1),'r');
% 변화된 결정경계 출력
end