Su2010
advertisement

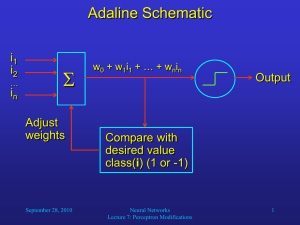
Quadratic Perceptron Learning with Applications Tonghua Su National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences Beijing, PR China Dec 2, 2010 Outline • Introduction • Motivations • Quadratic Perceptron Algorithm – – – – Previous works Theory perspective Practical perspective Open issues • Conclusions 1 Introduction Notation, binary classification, multi-class classification, large scale learning vs large category learning Introduction • • • • Domain Set Label Set Training Data Binary Classification – e.g. linear model Introduction • Multi-class Classification – Learning strategy • One vs one • One vs all • Single machine – e.g. Linear model – Large-category classification • Chinese character recognition (3,755 classes) • More confusions between classes Introduction • Large Scale Learning – large numbers of data points – high dimensions – Challenge in computation resource • Large Category vs Large Scale – Almost certainly: large category large scale – Tradeoffs: efficiency vs accuracy 2 Motivations MQDF HMMs Modified Quadratic Discriminant Function (MQDF) • QDF – MQDF [Kimura et al ‘1987] • Using SVD, • Truncate small eigenvalues Modified Quadratic Discriminant Function (MQDF) • MQDF+MCE+Synthetic samples [Chen et al ‘2010] – Building block: discriminative learning of MQDF 63.5 63.0 RCR (%) 62.5 62.0 61.5 HCL+HITtv HCL+HITtv+Syn1 HCL+HITtv+Syn4 HCL+HITtv+Syn8 HCL+HITtv+Syn16 61.0 60.5 60.0 0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 Sweeps Hidden Markov Models (HMMs) • Markovian transition + state specific generator 0.95 0.05 F 0.95 S F F F L L F F E L 0.05 • Continuous density HMMs: each state emits a GMM – e.g. Usable in handwritten Chinese text recognition [Su ‘2007] Hidden Markov Models (HMMs) • Perceptron training of HMMs [Cheng et al ’2009] – Joint distribution – Discriminant function log p(s,x) – Perceptron training • Nonnegative-definite constraint – Lack of theoretical foundation 3 Quadratic Perceptron Algorithm Related works Theoretical considerations Practical considerations Open issues Previous Works • Rosenblatt’s Perceptron [Rosenblatt ’58] – Updating rule: Previous Works • Rosenblatt’s Perceptron w0 wTx4y4=0 _+ wTx3y3=0 w2 _+ x2y2 x3y3 w1 w2 wTx2y2=0 _ Solution Region + x2y2 x3y3 w3 w4 wTx1y1=0 +_ w1 Previous Works • Rosenblatt’s Perceptron [Rosenblatt ’58] – View from batch loss where • Using stochastic gradient decent (SGD) Previous Works • Convergence Theorem [Block ’62,Novikoff ’62] – Linearly separate data – Stop at most (R/)2 steps Previous Works • Voted Perceptron [Freund ’99] – Training algorithm Prediction: Previous Works • Voted Perceptron – Generalization bound Previous Works • Perceptron with Margin [Krauth ’87, Li ’2002] Previous Works • Ballseptron [Shalev-Shwartz ’2005] Previous Works • Perceptron with Unlearning [Panagiotakopoulos ’2010] Learning Unlearning Theoretical Perspective • Prediction rule • Learning Theoretical Perspective • Algorithm online version Theoretical Perspective • Convergence Theorem of Quadratic Perceptron (quadratic separable) Theoretical Perspective • Convergence Theorem of Quadratic Perceptron with Magin (quadratic separable) Theoretical Perspective • Bounds for quadratic inseparable case Theoretical Perspective • Generalization Bound Theoretical Perspective • Nonnegative-definite constraints – Projection to the valid space – Restriction on updating • Convergence holds Theoretical Perspective • Toy problem: Lithuanian Dataset – 4000 training instances – 2000 test instances Theoretical Perspective • Perceptron learning (toy problem) 50 Fit Err Test Err 40 Err (%) 30 20 10 0 0 10 20 30 Sweeps 40 50 Theoretical Perspective • Extension to Multi-class QDF Theoretical Perspective • Extension to Multi-class QDF – Theoretical property holds as binary QDF – Proof can be completed using Kesler’s construction Practical Perspective • Practical Perspective – Perceptron batch loss where – SGD Practical Perspective • Practical Perspective – Constant margin – Dynamic margin Practical Perspective • Experiments – Benchmark on digit databases Practical Perspective • Experiments – Benchmark on digit databases 1.2 Fit Err Test Err 1.0 Err (%) 0.8 0.6 grg on MNIST 0.4 0.2 0.0 0 10 20 Sweeps 30 40 Practical Perspective • Experiments – Benchmark on digit databases 3.0 Fit Err Test Err Err (%) 2.5 2.0 grg on USPS 0.5 0.0 0 10 20 Sweeps 30 40 Practical Perspective • Experiments – Effects of training size (grg on MNIST) 1.6 MQDF PTMQDF 1.4 1.2 Err (%) 1.0 0.8 0.6 0.4 0.2 0.0 2k 4k 8k 10k 20k 30k # of training instances 40k 50k 60k Practical Perspective • Experiments – Benchmark on CASIA-HWDB1.1 Practical Perspective • Experiments – Benchmark on CASIA-HWDB1.1 11 Fit Err Test Err Err (%) 10 9 0.6 0.5 0.4 0.3 0.2 0.1 0.0 0 10 20 Sweeps 30 40 Open Issues • Convergence on GMM/MQDF? • Error reduction on CASIA-DB1.1 is small – How about adding more data ? – Can label permutation help? • Speedup the training process • Evaluate on more datasets 4 Conclusions Conclusions • Theoretical foundation for QDF – Convergence Theorem – Generalization Bound • Perceptron learning of MQDF – Margin is need for good generalization – More data may help Thank you! References • • • • • • [Chen et al ‘2010] Xia Chen, Tong-Hua Su,Tian-Wen Zhang. Discriminative Training of MQDF Classifier on Synthetic Chinese String Samples, CCPR,2010 [Cheng et al ‘2009] C. Cheng, F. Sha, L. Saul. Matrix updates for perceptron training of continuous density hidden markov models, ICML, 2009. [Kimura ‘87] F. Kimura, K. Takashina, S. Tsuruoka, Y. Miyake. Modified quadratic discriminant functions and the application to Chinese character recognition, IEEE TPAMI, 9(1): 149-153, 1987. [Panagiotakopoulos ‘2010] C. Panagiotakopoulos, P. Tsampouka. The Margin Perceptron with Unlearning, ICML, 2010. [Krauth ‘87] W. Krauth and M. Mezard. Learning algorithms with optimal stability in neural networks. Journal of Physics A, 20, 745-752, 1987. [Li ‘2002] Yaoyong Li, Hugo Zaragoza, Ralf Herbrich, John Shawe-Taylor, Jaz Kandola. The Perceptron Algorithm with Uneven Margins, ICML, 2002. References • • • • • [Freund ‘99] Y. Freund and R. E. Schapire. Large margin classification using the perceptron algorithm. Machine Learning, 37(3): 277-296, 1999. [Shalev-Shwartz ’2005] Shai Shalev-Shwartz, Yoram Singer. A New Perspective on an Old Perceptron Algorithm, COLT, 2005. [Novikoff ‘62] A. B. J. Novikoff. On convergence proofs on perceptrons. In Proc. Symp. Math. Theory Automata, Vol.12, pp. 615–622, 1962. [Rosenblatt ‘58] Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65 (6):386–408, 1958. [Block ‘62] H.D. Block. The perceptron: A model for brain functioning, Reviews of Modern Phsics, 1962, 34:123-135.