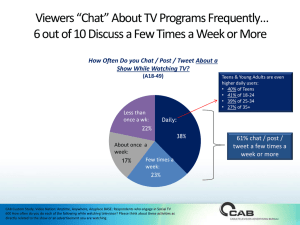
Slides - David Uthus
advertisement

“Cheap” Tricks for NLP: An “Invited” Talk Craig Martell Associate Professor Naval Postgraduate School Director, NLP Lab Overview • We’ve been doing work on microtext since before it was “microtext”. • About NPS • NPS Chat Corpus (v1 and v2?) – Overview – Goal (Jane Lin, NSA) – Age Detection Task (MAJ Jenny Tam, USA) • POS and Dialogue Act tagging: using Treebank to bootstrap (Lt. Col. Eric Forsyth, USAF) • But do we really even need to POS-tag? (CAPT James Hitt, USN) – Getting by “on the cheap” • Authorship detection in Twitter (LT Sarah Boutwell, USN) • Good scientific goals for the community (??) NPS NLP Lab • NPS is both a university and part of the DoD • As a university, we work on the same types of sponsored research as civilian universities – – – – DARPA*, IARPA, MURIs, NSF, etc. Standard competitive process Standard academia/industry expectations for results Same tenure and promotion process • As a part of the DoD, we do work more directly for sponsors: – DoD, DARPA*, NRO, NSA, etc. – Depending on the type of money, results need to be more operationally applicable – We have had some cool results using “cheap” tricks that could point to more “normal” academic research Some Recent and Current Work • IARPA SCIL – – – – Persuasion Detection Sub-group Detection In forums, chat, etc. (“microtext”) With UMD, UCSC, and Temple • DoD, etc. – Topic Detection in IRC Chat (Adams 2008) – Authorship “signal boosting” with large author sets • Any boost is remarkably useful to analysts – Project away topic signal from documents for cleaner authorship signal (topic does most of the work) – L1 detection from English-L2 documents. – “On-phone” NLP (above and more) • Accuracy vs Computational Power The NPS Chat Corpus, V1 • Gather 495,000 posts in age-based rooms – According to the terms of service of the chat service • To abide by the privacy act, we hand anonymized 10,000 posts, tagged them for dialogue act and part of speech – Go to Web Page The NPS Chat Corpus, V2? • We have also gathered data to aid in doing conversational thread extraction: – Essentially, we want to cluster posts according to what conversation they’re in – Not necessarily mutually exclusive clusters • We gathered data similar to that gathered by Elsner and Charniak at Brown – They gathered IRC data from Linux tech help – We added iPhone and Python tech help, and Physics Q&A – It has all been hand “clustered” for conversations – Working with UCSC CS (Lyn Walker) and Linguistics (Pranav Anand) to augment the annotation to include dialogue act and “attachment” instead of clusters. First Use: Age Detection • Second Youth Internet Safety Survey (2005) (YISS-2) – Decrease in youths receiving solicitations – Number of dangerous sexual overtures/aggressive solicitations has not declined – In 35% of the aggressive episodes, youths did not think the solicitations were serious enough to tell anyone – Only 7% of the aggressive solicitations were reported to law enforcement, ISP, or other authority • Need for an automated system that can recognize adults conversing with teens to alert parents of possible inappropriate conversations Tam – Chat Classification • NPS Chat Corpus (Talk City Chat Data) – Teens, 20s, 30s, 40s, 50+ • Perverted Justice (IM chat logs) – Pseudo Victims (adults posing as minors) – Convicted criminals (solicitation of minors) • Binary Classification – teens vs. adults – teens vs. specific age group – teens vs. pseudo victims (similarity between actual teens to adults pretending to be teens) – criminals vs. teens (looking for minors soliciting minors) – criminals vs. pseudo victims • Classification Tool – Linear Support Vector Machine with different slack variables • Result: 80-90% success at detecting Teens from Adults. But the most important is detecting Teens from 20s. >90% • Current state of the art in the field! Forsyth – Dialogue Act/POS Tagging • An experiment in cross-domain NLP • We wanted to POS tag chat (Lt Col Eric Forsyth, USAF) • Lex. Bigrams → Bigrams → Lex. Unigrams → Unigrams → MLE from training data • WSJ train, chat test: 57.4% accuracy – Not surprising. Chat is not like WSJ • Treebank train, chat test: 65.8% accuracy – Includes ATIS, Switchboard; chat is somewhat speech like • Boot strapped/hand corrected POS tags for 10,000 posts • Chat train, chat test: 73.7% • But, add 10,000 chat posts to Treebank: 87.1% – Using HMM tagger trained on combo: 90.8% • Using these parts of speeches tags as part of the input, we can dialogue act tag at 83.2% accuracy. Hitt – Dialogue Act/POS Tagging • But does POS tagging matter for dialogue act tagging (our actual goal in chat, sms, etc). • Sure, but it doesn’t have to be that good Instead of using chat at all, we (CAPT James Hitt, USN) simply generated the MLE for each word string (no wsd) from pre-existing resources (Treebank and Brown combined). • Just using these “cheap” parts of speech we get: 83.23% L1 Language Identification • Using International Corpus of Lerner English • For each author L2 = English (except for native speaker control group) • Texts in English • Task: Guess L1 • Using character 3-grams, we (LT Charles Ahn, USN) got: 81.3% L1 Language Identification CPOS and L1 Identification • Interestingly CPOS n-grams works very well here too: • Cells contain average counts of documents over 26 trials • ML: Multi-class Logistic Regression Boutwell – Authorship Detection in Twitter • • • • Hot off the presses Built a “social network” from the Twitter garden hose Use it to simulate SMS messages within the group If my phone is stolen, can it tell that it isn’t me writing SMS? • So, what do we need to do authorship detection over “SMS” – Doesn’t seem to be a lot of authorship signal in SMS • Well, not in one, but in 23 there is – If we have a stream of 23 messages, we got 90% accuracy over 10 authors. – Authors are consistent in how they deal with the constraints? – More error/success analysis needed Research to be explored • Can we build a better scientific understanding of different domains of text and develop a theory of what will be useful from pre-existing domains? What will be needed from the new domain? • How much can we actually do with as little as possible? – Do we need to parse? • Should we expand (e.g., ur), or generate new grammars • I argue we build new models sooner rather than later – How do we get parallel corpora? – How do we get best practices for mechanical turk?