Class Slides
advertisement

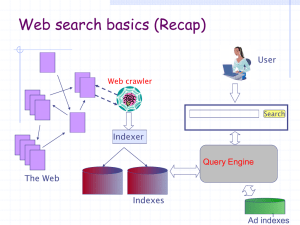
CS246 Basic Information Retrieval Today’s Topic Basic Information Retrieval (IR) Bag of words assumption Boolean Model Vector-space model Inverted index Document-term matrix TF-IDF vector and cosine similarity Phrase queries Spell correction Information-Retrieval System Information source: Existing text documents Keyword-based/natural-language query The system returns best-matching documents given the query Challenge Both queries and data are “fuzzy” Unstructured text and “natural language” query What documents are good matches for a query? Computers do not “understand” the documents or the queries Developing a computerizable “model” is essential to implement this approach Bag of Words: Major Simplification Consider each document as a “bag of words” Consider queries as bag of words as well Great oversimplification, but works adequately in many cases “bag” vs “set” Ignore word ordering, but keep word count “John loves only Jane” vs “Only John loves Jane” The limitation still shows up on current search engines Still how do we match documents and queries? Boolean Model Return all documents that contain the words in the query No notion of “ranking” Simplest model for information retrieval A document is either a match or non-match Q: How to find and return matching documents? Basic algorithm? Useful data structure? Inverted Index Allows quick lookup of document ids with a particular word Postings list lexicon/dictionary DIC 3 8 10 13 16 20 PL(Stanford) 1 2 3 9 PL(UCLA) 4 5 8 10 13 19 20 22 Stanford UCLA MIT … 16 18 PL(MIT) Q: How can we use this to answer “UCLA Physics”? Inverted Index Allows quick lookup of document ids with a particular word Postings list lexicon/dictionary DIC 3 8 10 13 16 20 PL(Stanford) 1 2 3 9 PL(UCLA) 4 5 8 10 13 19 20 22 Stanford UCLA MIT … 16 18 PL(MIT) Size of Inverted Index (1) 100M docs, 10KB/doc, 1000 unique words/doc, 10B/word, 4B/docid Q: Document collection size? Q: Inverted index size? Heap’s Law:Vocabulary size = k nb with 30 < k < 100 and 0.4 < b<1 k = 50 and b = 0.5 are good rule of thumb Size of Inverted Index (2) Q: Between dictionary and postings lists, which one is larger? Q: Lengths of postings lists? Zipf’s law: collection term frequency 1/frequency rank Q: How do we construct an inverted index? Inverted Index Construction C: set of all documents (corpus) DIC: dictionary of inverted index PL(w): postings list of word w 1: For each document d C: 2: Extract all words in content(d) into W 3: For each w W: 4: If w DIC, then add w to DIC 5: Append id(d) to PL(w) Q: What if the index is larger than main memory? Inverted-Index Construction For large text corpus Block-sorted based construction Partition and merge Evaluation: Precision and Recall Q: Are all matching documents what users want? Basic idea: a model is good if it returns document if and only if it is “relevant”. R: set of “relevant” document D: set of documents returned by a model | DR| Precision |D| | DR| Recall |R| Vector-Space Model Main problem of Boolean model Matrix interpretation of Boolean model Too many matching documents when the corpus is large Any way to “rank” documents? Document – Term matrix Boolean 0 or 1 value for each entry Basic idea Assign real-valued weight to the matrix entries depending on the importance of the term “the” vs “UCLA” Q: How should we assign the weights? TF-IDF Vector A term t is important for document d TF: term frequency # documents containing t TF-IDF weighting # occurrence of t in d IDF: inverse document frequency If t appears many times in d or If t is a “rare” term TF X Log(N/IDF) Q: How to use it to compute query-document relevance? Cosine Similarity Represent both query and document as a TF-IDF vector Take the inner product of the two normalized vectors to compute their similarity QD Q Dfor document ranking. Note: |Q| does not matter Division by |D| penalizes longer document. Cosine Similarity: Example idf(UCLA)=10, idf(good)=0.1, idf(university) = idf(car) = idf(racing) = 1 Q = (UCLA, university), D = (car, racing) Q = (UCLA, university), D = (UCLA, good) Q = (UCLA, university), D = (university, good) Finding High Cosine-Similarity Documents Q: Under vector-space model, does precision/recall make sense? Q: How to find the documents with highest cosine similarity from corpus? Q: Any way to avoid complete scan of corpus? Inverted Index for TF-IDF Q · di = 0 if di has no query words Consider only the documents with query words Inverted Index: Word Document Word Lexicon IDF docid TF Stanford 1/3530 D1 2 UCLA 1/9860 D14 30 MIT 1/937 D376 8 … Posting list (TF may be normalized 18 by document size) Phrase Queries “Havard University Boston” exactly as a phrase Q: How can we support this query? Two approaches Biword index Positional index Q: Pros and cons of each approach? Rule of thumb: x2 – x4 size increase for positional index compared to docid only Spell correction Q: What is the user’s intention for the query “Britnie Spears”? How can we find the correct spelling? Given a user-typed word w, find its correct spelling c. Bayes’ rule: P(c|w) = P(w|c)P(c)/P(w) Probabilistic approach: Find c with the highest probability P(c|w). Q: How to estimate it? Q: What are these probabilities and how can we estimate them? Rule of thumb: 75% misspells are within edit distance 1. 98% are within edit distance 2. Summary Boolean model Vector-space model Inverted index TF-IDF weight, cosine similarity Boolean model TF-IDF model Phrase queries Spell correction