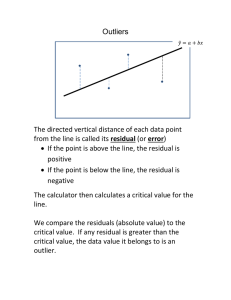
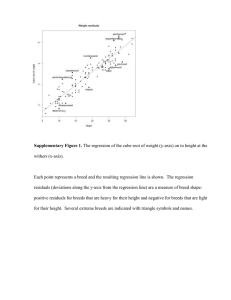
Question to ponder • As our ability to collect and store huge amounts of data increases, should we add more environmental covariates to our ecological models to make them more realistic? Data exploration and simple linear regression Todays goals • Describe steps to take in exploring data prior to analysis • Review linear regression – Most of the remainder of this course is based on the concepts underlying linear regression Steps in sta6s6cal analysis 1. 2. 3. 4. 5. Develop hypothesis Data exploration Model fitting Model selection Model diagnostics Data exploration • Reasons to explore data – Quality control – Check for outliers – Detect patterns in data – Ensure assumptions of analysis are met Histograms Dotplots Boxplots Colinearity Linear regression • Used to determine the extent to which there is a linear relationship between a dependent variable (response) and one, or more, ‘independent’ variables (predictor) Linear Models • Relationship between variables is a Linear Function Y-Intercept Random Error Slope 𝑌! = 𝛽" + 𝛽# 𝑋! + 𝜀! Dependent (Response) Variable Independent or Explanatory Variable (or Covariate) 11 Regression 𝑌! = 𝛽" + 𝛽# 𝑋! + 𝜀! 𝛽! = Slope (rise-over-run, ΔY/ ΔX) Y 𝛽" = y-intercept (where line crosses Y-axis) Quinn and Keough 2002 X 12 Regression 𝑌! = 𝛽" + 𝛽# 𝑋! + 𝜀! Y 𝜀! = unexpected error Residual = observed – expected 𝜀#̂ = 𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙 = 𝑌# − 𝑌/# Quinn and Keough 2002 X How do we fit this model? • Ordinary least squares – Method of fitting a model in which you minimize the residual sums of squares (RSS) 𝑟𝑒𝑠𝑖𝑑𝑢𝑎𝑙 = 𝜀# = 𝑌# − 𝑌/# % 𝑅𝑆𝑆 = 2(𝑌# − 𝑌/# )& #$! 14 • Khan academy video Maximum likelihood • Gaussian (normal distribution) • µ = mean • s2 = variance Simple example • Consider 3 data points – y1=1, y2=0.5, y3=1.5 • Likelihood is the product of the individual probabilities of each data point given a parameter estimate Maximum likelihood • Normal distribution likelihood equation • In practice, for numerical purposes, we minimize the negative log-likelihood Example data R code • lm(fishSize~fishDens, data=sim, weights=frequency) Call: lm(formula = fishSize ~ fishDens, data = sim) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 17.5375 0.3263 53.755 <2e-16 *** fishDens -1.3171 0.6462 -2.038 0.0418 * --Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 5.147 on 1259 degrees of freedom Multiple R-squared: 0.003288, Adjusted R-squared: 0.002497 F-statistic: 4.154 on 1 and 1259 DF, p-value: 0.04176 Assumptions 1. Normality 2. Homogeneity of variance (HOV) Y 3. Independence 4. Correct model specification 5. Fixed X X Zuur et al. 2009 22 1. Normality • The errors are assumed to be normally distributed with a mean of zero – Needed for parametric statistical tests 23 1. Normality • Diagnostics – Graphical evaluation (best) • histogram of residuals 24 2. Homogeneity of variance • Diagnostics – Graphical evaluation is best • Residual plots or conditional boxplots of residuals 25 2. Homogeneity of variance • Diagnostics – Graphical evaluation is best • Residual plots or conditional boxplots of residuals 26 3. Independence of errors • Collec\on of one sample is assumed to have NO effect, influence, or correla\on with another sample • Sta\s\cal methods rely on samples being random and independent 27 3. Independence of errors • Examples of non-independence: – Nested/hierarchical design; – repeated measures; – temporal correlation; – spatial correlation – “pseudoreplication” Data set 28 3. Independence of errors Diagnostics – Understanding of sampling design! – Graphical evaluation • Plot Y (or residuals) versus time/space (e.g., bubble plots) • Auto-correlation plots Spatial correlation of residuals Autocorrelation function acf() Residuals Y-coordinates • X-coordinates Time lag (years) 29