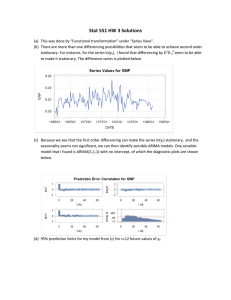
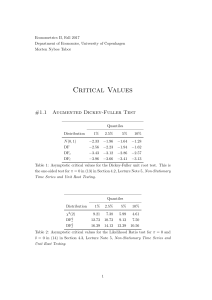
UNIT IV: TIME SERIES ANALYSIS BASICS OF TIME SERIES A time series consists of a set of observations measured at specified, usually equal, time interval. Time series analysis attempts to identify those factors that exert influence on the values in the series. Time series analysis is a basic tool for forecasting. Industry and government must forecast future activity to make decisions and plans to meet projected changes. An analysis of the trend of the observations is needed to acquire an understanding of the progress of events leading to prevailing conditions. The trend is defined as the long term underlying growth movement in a time series Accurate trend spotting can only be determined if the data are available for a sufficient length of time Forecasting does not produce definitive results Forecasters can and do get things wrong from election results and football scores to the weather Time series examples • Sales data • • Gross national product • • Share prices • • $A Exchange rate • Time series components Time series data can be broken into these four components: 1. Secular trend 2. Seasonal variation Unemployment rates Population Foreign debt Interest rates 3. Cyclical variation 4. Irregular variation All Ords 10000 0 All Ords This is the long term growth or decline of the series. In economic terms, long term may mean >10 years Describes the history of the time series Uses past trends to make prediction about the future Where the analyst can isolate the effect of a secular trend, changes due to other causes become clearer Page 1 of 14 The seasonal variation of a time series is a pattern of change that recurs regularly over time. Seasonal variations are usually due to the differences between seasons and to festive occasions such as Easter and Christmas. Examples include: • Air conditioner sales in Summer • Heater sales in Winter • Flu cases in Winter • Airline tickets for flights during school vacations Cyclical variations also have recurring patterns but with a longer and more erratic time scale compared to Seasonal variations. The name is quite misleading because these cycles can be far from regular and it is usually impossible to predict just how long periods of expansion or contraction will be. There is no guarantee of a regularly returning pattern. Example includes: • Floods • Economic depressions or recessions • Wars • Changes in consumer spending • Changes in interest rates This chart represents an economic cycle, but we know it doesn’t always go like this. The timing and length of each phase is not predictable. Page 2 of 14 1. An Irregular (or random) variation in a time series occurs over varying (usually short) periods. 2. It follows no pattern and is by nature unpredictable. 3. It usually occurs randomly and may be linked to events that also occur randomly. 4. Irregular variation cannot be explained mathematically. 5. If the variation cannot be accounted for by secular trend, season or cyclical variation, then it is usually attributed to irregular variation. Example include: – Sudden changes in interest rates – Collapse of companies – Natural disasters – Sudden shift s in government policy Monthly Value of Building Approvals ACT) – Dramatic changes to the stock market – Effect of Middle East unrest on petrol prices ARIMA MODEL • Autoregressive Integrated Moving Average models (ARIMA models) were popularized by George Box and Gwilym Jenkins in the early 1970s. • ARIMA models are a class of linear models that is capable of representing stationary as well as non-stationary time series. • ARIMA models do not involve independent variables in their construction. They make use of the information in the series itself to generate forecasts. • ARIMA models rely heavily on autocorrelation patterns in the data. • ARIMA methodology of forecasting is different from most methods because it does not assume any particular pattern in the historical data of the series to be forecast. • It uses an interactive approach of identifying a possible model from a general class of models. • The chosen model is then checked against the historical data to see if it accurately describes the series. In time series analysis, the Box-Jenkins Model is a mathematical model designed to forecast data within a time series. Time-Series is of two types: Page 3 of 14 If the ACF (autocorrelation factor) of the time series values either cuts off or dies down fairly quickly, then the time series values should be considered STATIONARY. If the ACF (auto correlation factor) of the time series values either cuts off or dies down extremely slowly, then it should be considered NON-STATIONARY. • • • • • • A stationary process is one whose statistical properties do not change over time. A non-stationary process/time-series have properties which change over time. The Box-Jenkins model alters the non-stationary time series to make it stationary by using the differences between data points. All stationary time series can be modeled as Auto Regressive (AR) or Moving Average (MA) or ARMA models. The BOX-JENKINS method applies Autoregressive Moving Average ARMA or ARIMA models to find the best fit of a time-series model to past values of a time series. This allows the model to pick out trends, typically using autoregresssion, moving averages and seasonal differencing in the calculations. DEFINITION of Autoregressive Integrated Moving Average – ARIMA • A statistical analysis model that uses time series data to predict future trends. • Box-Jenkins (ARIMA) is an important forecasting method that can yield highly accurate forecasts for certain types of data. • It is a form of regression analysis that seeks to predict future movements. • It considers the random variations. • It examining the differences between values in the series instead of using the actual data values. • Lags of the differenced series are referred to as “autoregressive" and lags within forecasted data are referred to as “moving average”. • This model type is generally referred to as ARIMA (p, d, q), model. • p represents autoregressive, d represents integrated, and q represents the moving average parts of the data set. • ARIMA modeling can take into account trends, seasonality, cycles, errors and non- stationary aspects of a data set when making forecasts. • A seasonal Box-Jenkins model is symbolized as ARIMA(p,d,q)*(P,D,Q), where the p,d,q indicates the model orders for the short-term components of the model and P,D,Q indicate the model orders for the seasonal components of the model. • Box-Jenkins is an important forecasting method that can generate more accurate forecasts than other time series methods for certain types of data. Page 4 of 14 • • • • • • As originally formulated, model identification relied upon a difficult, time consuming and highly subjective procedure. Today, software packages such as Forecast Pro use automatic algorithms to both decide when to use Box-Jenkins models and to automatically identify the proper form of the model. Box-Jenkins models are similar to exponential smoothing models. Box-Jenkins models are adaptive, can model trends and seasonal patterns, and can be automated. Box-Jenkins models are based on autocorrelations (patterns in time) rather than a structural view of level, trend and seasonality. Box-Jenkins tends to succeed better than exponential smoothing for longer, more stable data sets and not as well for noisier, more volatile data. BOX-JENKINS METHOD The Box-Jenkins method was proposed by George Box and Gwilym Jenkins The approach starts with the assumption that the process that generated the time series can be approximated using an ARMA model if it is stationary or an ARIMA model if it is non-stationary. It refers to the process as a stochastic model building and that it is an iterative approach that consists of the following 3 steps: 1. Identification. Use the data and all related information to help select a sub-class of model that may best summarize the data. 2. Estimation. Use the data to train the parameters of the model (i.e. the coefficients). 3. Diagnostic Checking. Evaluate the fitted model in the context of the available data and check for areas where the model may be improved. 1. Identification The identification step is further broken down into: 1. Assess whether the time series is stationary, and if not, how many differences are required to make it stationary. 2. Identify the parameters of an ARMA model for the data. 1.1 Differencing Page 5 of 14 Below are some tips during identification. Unit Root Tests. Use unit root statistical tests on the time series to determine whether or not it is stationary. Repeat after each round of differencing. Avoid over differencing. Differencing the time series more than is required can result in the addition of extra serial correlation and additional complexity. 1.2 Configuring AR and MA Two diagnostic plots can be used to help choose the p and q parameters of the ARMA or ARIMA. They are: Autocorrelation Function (ACF). The plot summarizes the correlation of an observation with lag values. The x-axis shows the lag and the y-axis shows the correlation coefficient between -1 and 1 for negative and positive correlation. Partial Autocorrelation Function (PACF). The plot summarizes the correlations for an observation with lag values that is not accounted for by prior lagged observations. Both plots are drawn as bar charts showing the 95% and 99% confidence intervals as horizontal lines. Bars that cross these confidence intervals are therefore more significant and worth noting. Some useful patterns you may observe on these plots are: The model is AR if the ACF trails off after a lag and has a hard cut-off in the PACF after a lag. This lag is taken as the value for p. The model is MA if the PACF trails off after a lag and has a hard cut-off in the ACF after the lag. This lag value is taken as the value for q. The model is a mix of AR and MA if both the ACF and PACF trail off. 2. Estimation Estimation involves using numerical methods to minimize a loss or error term. We will not go into the details of estimating model parameters as these details are handled by the chosen library or tool. 3. Diagnostic Checking The idea of diagnostic checking is to look for evidence that the model is not a good fit for the data. Two useful areas to investigate diagnostics are: 1. Over fitting 2. Residual Errors. 3.1 Over fitting The first check is to check whether the model over fits the data. Generally, this means that the model is more complex than it needs to be and captures random noise in the training data. This is a problem for time series forecasting because it negatively impacts the ability of the model to generalize, resulting in poor forecast performance on out of sample data. Careful attention must be paid to both in-sample and out-of-sample performance and this requires the careful design of a robust test harness for evaluating models. 3.2 Residual Errors Forecast residuals provide a great opportunity for diagnostics. A review of the distribution of errors can help tease out bias in the model. The errors from an ideal model would resemble white noise, which is a Gaussian distribution with a mean of zero and a symmetrical variance. For this, you may use density plots, histograms, and Q-Q plots that compare the distribution of errors to the expected distribution. A non-Gaussian distribution may suggest an opportunity for Page 6 of 14 data pre-processing. A skew in the distribution or a non-zero mean may suggest a bias in forecasts that may be correct. Additionally, an ideal model would leave no temporal structure in the time series of forecast residuals. These can be checked by creating ACF and PACF plots of the residual error time series. The presence of serial correlation in the residual errors suggests further opportunity for using this information in the model. 4. Forecasting • One of the most important tests of how well a model performs is how well it forecasts. • One of the most useful models for forecasting is the ARIMA model. • To produce dynamic forecasts the model needs to include lags of either the variables or error terms. AR, MA, ARMA, and ARIMA MODELS AR, MA, ARMA, and ARIMA models are used to forecast the observation at (t+1) based on the historical data of previous time spots recorded for the same observation. However, it is necessary to make sure that the time series is stationary over the historical data of observation overtime period. If the time series is not stationary then we could apply the differencing factor on the records and see if the graph of the time series is a stationary overtime period. ACF (Auto Correlation Function) Auto Correlation function takes into consideration of all the past observations irrespective of its effect on the future or present time period. It calculates the correlation between the t and (t-k) time period. It includes all the lags or intervals between t and (t-k) time periods. Correlation is always calculated using the Pearson Correlation formula. PACF (Partial Correlation Function) The PACF determines the partial correlation between time period t and t-k. It doesn’t take into consideration all the time lags between t and t-k. For e.g. let's assume that today's stock price may be dependent on 3 days prior stock price but it might not take into consideration yesterday's stock price closure. Hence we consider only the time lags having a direct impact on future time period by neglecting the insignificant time lags in between the two-time slots t and t-k. How to differentiate when to use ACF and PACF? Let's take an example of sweets sale and income generated in a village over a year. Under the assumption that every 2 months there is a festival in the village, we take out the historical data of sweets sale and income generated for 12 months. If we plot the time as month then we can observe that when it comes to calculating the sweets sale we are interested in only alternate months as the sale of sweets increases every two months. But if we are to consider the income generated next month then we have to take into consideration all the 12 months of last year. So in the above situation, we will use ACF to find out the income generated in the future but we will be using PACF to find out the sweets sold in the next month. AR (Auto-Regressive) Model The time period at t is impacted by the observation at various slots t-1, t-2, t-3…., t-k. The impact of previous time spots is decided by the coefficient factor at that particular period of time. Page 7 of 14 The price of a share of any particular company X may depend on all the previous share prices in the time series. This kind of model calculates the regression of past time series and calculates the present or future values in the series in know as Auto Regression (AR) model. Consider an example of a milk distribution company that produces milk every month in the country. We want to calculate the amount of milk to be produced current month considering the milk generated in the last year. We begin by calculating the PACF values of all the 12 lags with respect to the current month. If the value of the PACF of any particular month is more than a significant value only those values will be considered for the model analysis. For e.g in the above figure the values 1,2, 3 up to 12 displays the direct effect(PACF) of the milk production in the current month w.r.t the given the lag t. If we consider two significant values above the threshold then the model will be termed as AR(2). MA (Moving Average) Model The time period at t is impacted by the unexpected external factors at various slots t-1, t-2, t-3, ….., t-k. These unexpected impacts are known as Errors or Residuals. The impact of previous time spots is decided by the coefficient factor α at that particular period of time. The price of a share of any particular company X may depend on some company merger that happened overnight or maybe the company resulted in shutdown due to bankruptcy. This kind of model calculates the residuals or errors of past time series and calculates the present or future values in the series in know as Moving Average (MA) model. Consider an example of Cake distribution during my birthday. Let's assume that your mom asks you to bring pastries to the party. Every year you miss judging the no of invites to the party and end upbringing more or less no of cakes as per requirement. The difference in the actual and expected results in the error. So you want to avoid the error for this year hence we apply the moving average model on the time series and calculate the no of pastries needed this year based on past collective errors. Next, calculate the ACF values of all the lags in the time series. If the value of the ACF of any particular month is more than a significant value only those values will be considered for the model analysis. For e.g in the above figure the values 1,2, 3 up to 12 displays the total error(ACF) of count in pastries current month w.r.t the given the lag t by considering all the in-between lags between time t and current month. If we consider two significant values above the threshold then the model will be termed as MA (2). Page 8 of 14 ARMA (Auto Regressive Moving Average) Model This is a model that is combined from the AR and MA models. In this model, the impact of previous lags along with the residuals is considered for forecasting the future values of the time series. Here β represents the coefficients of the AR model and α represents the coefficients of the MA model. Consider the above graphs where the MA and AR values are plotted with their respective significant values. Let's assume that we consider only 1 significant value from the AR model and likewise 1 significant value from the MA model. So the ARMA model will be obtained from the combined values of the other two models will be of the order of ARMA (1, 1). ARIMA (Auto-Regressive Integrated Moving Average) Model We know that in order to apply the various models we must in the beginning convert the series into Stationary Time Series. In order to achieve the same, we apply the differencing or integrated method where we subtract the t-1 value from t values of time series. After applying the first differencing if we are still unable to get the Stationary time series then we again apply the second-order differencing. The ARIMA model is quite similar to the ARMA model other than the fact that it includes one more factor known as Integrated( I ) i.e. differencing which stands for I in the ARIMA model. So in short ARIMA model is a combination of a number of differences already applied on the model in order to make it stationary, the number of previous lags along with residuals errors in order to forecast future values. Consider the above graphs where the MA and AR values are plotted with their respective significant values. Let's assume that we consider only 1 significant value from the AR model and likewise 1 significant value from the MA model. Also, the graph was initially non-stationary and we had to perform differencing operation once in order to convert into a stationary set. Hence the ARIMA model which will be obtained from the combined values of the other two models along with the Integral operator can be displayed as ARIMA (1,1,1). Page 9 of 14 ERROR MEASUREMENTS Measurement error is the difference between the observed value of a Variable and the true, but unobserved, value of that Variable. Measurement error refers to a circumstance in which the true empirical value of a variable cannot be observed or measured precisely. The error is thus the difference between the actual value of that variable and what can be observed or measured. For instance, household consumption/expenditures over some interval are often of great empirical interest (in many applications because of the theoretical role they play under the forwardlooking theories of consumption). These are usually observed or measured via household surveys in which respondents are asked to catalog their consumption/expenditures over some recall window. However, these respondents often cannot recall precisely how much they spent on the various items over that window. Their reported consumption/expenditures are thus unlikely to reflect precisely what they or their households actually spent over the recall interval. Unfortunately measurement error is not without consequence in many empirical applications. Perhaps the most widely recognized difficulty associated with measurement error is bias to estimates of regression parameters. Measurement error causes the recorded values of Variables to be different from the true ones. In general the Measurement error is defined as the sum of Sampling error and Non-sampling error. Measurement errors can be systematic or random, and they may generate both Bias and extra variability in statistical outputs. Usually the term measurement refers to measuring the values of a Variable at the unit level, for example, measuring a Household’s consumption or measuring the wages paid by a business. The term Measurement error is also applicable for aggregates at the population level. UNIVARIATE TIME SERIES MODELLING The term "univariate time series" refers to a time series that consists of single (scalar) observations recorded sequentially over equal time increments. Although a univariate time series data set is usually given as a single column of numbers, time is in fact an implicit variable in the time series. If the data are equi-spaced, the time variable, or index, does not need to be explicitly given. The time variable may sometimes be explicitly used for plotting the series. However, it is not used in the time series model itself. UNIT ROOT Stationarity: A stationary time series is one whose statistical properties such as mean, variance, autocorrelation, etc. are all constant over time’. The consistency of these variables makes predictions easier to do. On average, a stationary time series occurs less frequently than one with a stochastic trend. Seasonality: Seasonality is a pretty straight forward concept. It suggests that factors outside of the control of the business model are going to still have a strong pull on how the company is performing financially. With a Broadway show we can see the dips happen around September due to people returning to school and summer vacations being over. The large spikes happen at times like Page 10 of 14 Christmas and New Years when wallets are open and people are gift giving. An important thing to keep in mind with seasonality is that it can exist even with an unpredictable outcome. In those situations, the time series is even harder to follow and seasonality must be removed from it in order to gain a better perspective of the trends. Stochastic: Stochasticity (Also a Random Walk with a Drift) can be defined as a variable or process that has uncertainty in it. The features lack dependence between one another. Stochasticity would be used over the word randomness when the probability of a feature is important. Whereas a term such as ‘random sampling’ just refers to having a lack of bias but does not inference an outcome. A unit root test tests whether a time series variable is non-stationary and possesses a unit root. The null hypothesis is generally defined as the presence of a unit root and the alternative hypothesis is either stationarity, trend stationarity or explosive root depending on the test used. In general, the approach to unit root testing implicitly assumes that the time series to be tested can be written as, Yt= Dt+Zt+€t Where, Dt is the deterministic component (trend, seasonal component, etc.) Zt is the stochastic component. €t is the stationary error process. The task of the test is to determine whether the stochastic component contains a unit root or is stationary. Unit root (also called a unit root process or a difference stationary process) is a stochastic trend in a time series, sometimes called a “random walk with drift”. If a time series has a unit root, it shows a systematic pattern that is unpredictable. A possible unit root. The red line shows the drop in output and path of recovery. Blue shows the recovery if there is no unit root and the series is trend-stationary.These are tests for stationarity in a time series. A time series has stationarity if a shift in time doesn’t cause a change in the shape of the distribution; unit roots are one cause for non-stationarity. Methods of Unit Root Test The Dickey Fuller Test (sometimes called a Dickey Pantula test), which is based on linear regression. Serial correlation can be an issue, in which case the Augmented Dickey-Fuller (ADF) test can be used. The ADF handles bigger, more complex models. It does have the downside of a fairly high Type I error rate. The Elliott–Rothenberg–Stock Test, which has two subtypes: o The P-test takes the error term’s serial correlation into account, o The DF-GLS test can be applied to detrended data without intercept. The Schmidt–Phillips Test includes the coefficients of the deterministic variables in the null and alternate hypotheses. Subtypes are the rho-test and the tau-test. The Phillips–Perron (PP) Test is a modification of the Dickey Fuller test, and corrects for autocorrelation and heteroscedasticity in the errors. The Zivot-Andrews test allows a break at an unknown point in the intercept or linear trend. Page 11 of 14 COINTEGRATION TEST Cointegration is a statistical method used to test the correlation between two or more nonstationary time series in the long run or for a specified period. The method helps identify long-run parameters or equilibrium for two or more variables. In addition, it helps determine the scenarios wherein two or more stationary time series are cointegrated so that they cannot depart much from the equilibrium in the long run.The method determines the sensitivity of two or more variables to the same set of conditions or parameters. Let us understand the method with the help of a graph. The prices of two commodities, A and B, are shown on the graph. We can infer that these are perfectly cointegrated commodities in terms of price, as the difference between the prices of both commodities has remained the same for decades. Though this is a hypothetical example, it perfectly explains the cointegration of two non-stationary time series. Examples of Cointegration Cointegration as correlation does not measure whether two or more time-series data or variables move together in the long run. In contrast, it measures whether the difference between their means remains constant or not. So, that means that two random variables completely different from each other can have one common trend that combines them in the long run. If this happens, variables are said to be cointegrated. Now let’s take the example of Cointegration in pair trading. In pair trading, a trader purchases two cointegrated stocks, stock A at the long position and stock B in the short. The trader was unsure about the price direction for both the stocks but was sure that stock A’s position would be better than that of stock B. Now, let us say that if the prices of both the stocks go down, the trader will still make a profit as long as stock A’s position is better than stock B’s if both stocks weigh equally at the purchase time. Condition of Cointegration The cointegration test is based on the logic that more than two-time series variables have similar deterministic trends that one can combine over time. Therefore, it is necessary for all cointegration testing for non-stationary time series variables. One should integrate them in the same order, or they should have a similar identifiable trend that can define a correlation between them. So, they should not deviate much from the average parameter in the short run. In the long run, they should be reverting to the trend. Page 12 of 14 Methods for testing cointegration You can test for cointegration using four different methods. These methods have some similarities, but each one has a particular strength and may give you different results. You can use the four methods below to test for cointegration: Engle-Granger test The Engle-Granger test was the first method to test for cointegration during its early development. You can use the Engle-Granger test to errors based on doing a regression of two variables. It uses the two hypotheses below: H0: No cointegration exists between the two variables H1: Cointegration exists between the two variables Where: H0 is the null hypothesis for the test H1 is the alternative hypothesis for the test While this form of cointegration testing is quicker than the others, it has two drawbacks. The first is that it can only work with two time-related series. The second is that if one of the two timerelated series depends on the other, then the test can sometimes output an incorrect conclusion that the two variables have no cointegration. You can address both of these by using the other methods to test for cointegration. Phillips-Ouliaris test The Phillips-Ouliaris test is an improvement on the original Engle-Granger test. Its major benefit is that it handles the issue related to independent variables because it can recognize if one of the time-related series depends on the other and factors this into the outcome it presents, meaning that if one series depends on the other, it still considers them cointegrated. Like the Engle-Granger test, the two hypotheses for this test are: H0: No cointegration exists between the two variables H1: Cointegration exists between the two variables Also like the Engle-Granger test, this method cannot work with over two variables, which is an issue that you can resolve by using the Gregory and Hansen test of cointegration. Johansen test The Johansen test is an improvement on both the Engle-Granger test and the Phillips-Ouliaris test. You can use this test to work with time-related series in which one series depends on the other, such as supply and demand, and eliminates errors from the previous two methods, which allows this method to work with two or more variables. There are also two subtests to the Johansen test. You can use the subtests below to help find if two or more time-related series are cointegrated: CAUSALITY TEST Prof. Clive W.J. Granger, recipient of the 2003 Nobel Prize in Economics developed the concept of causality to improve the performance of forecasting. It is basically an econometric hypothetical test for verifying the usage of one variable in forecasting another in multivariate time series data with a particular lag. A prerequisite for performing the Granger Causality test is that the data need to be stationary i.e it should have a constant mean, constant variance, and no seasonal component. Transform the nonstationary data to stationary data by differencing it, either first-order or second-order differencing. Do Page 13 of 14 not proceed with the Granger causality test if the data is not stationary after second-order differencing. Let us consider three variables Xt , Yt , and Wt preset in time series data. Case 1: Forecast Xt+1 based on past values Xt . Case 2: Forecast Xt+1 based on past values Xt and Yt. Case3 : Forecast Xt+1 based on past values Xt , Yt , and Wt, where variable Yt has direct dependency on variable Wt. Here Case 1 is univariate time series also known as the autoregressive model in which there is a single variable and forecasting is done based on the same variable lagged by say order p. The equation for the Auto-regressive model of order p (RESTRICTED MODEL, RM) Xt = α + 𝛾1 X𝑡−1 + 𝛾2X𝑡−2 + ⋯ + 𝛾𝑝X𝑡−𝑝 where p parameters (degrees of freedom) to be estimated. In Case 2 the past values of Y contain information for forecasting Xt+1. Yt is said to “Granger cause” Xt+1 provided Yt occurs before Xt+1 and it contains data for forecasting Xt+1. Equation using a predictor Yt (UNRESTRICTED MODEL, UM) Xt = α + 𝛾1 X𝑡−1 + 𝛾2X𝑡−2 + ⋯ + 𝛾𝑝X𝑡−𝑝 + α1Yt-1+ ⋯ + α𝑝 Yt-p 2p parameters (degrees of freedom) to be estimated. If Yt causes Xt, then Y must precede X which implies: Lagged values of Y should be significantly related to X. Lagged values of X should not be significantly related to Y. Case 3 cannot be used to find Granger causality since variable Yt is influenced by variable Wt. Hypothesis test Null Hypothesis (H0): Yt does not “Granger cause” Xt+1 i.e., 𝛼1 = 𝛼2 = ⋯ = 𝛼𝑝 = 0 Alternate Hypothesis (HA): Yt does “Granger cause” Xt+1, i.e., at least one of the lags of Y is significant. Calculate the f-statistic Fp,n-2𝑝−1 = (𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑒 𝑜𝑓 𝐸𝑥𝑝𝑙𝑎𝑖𝑛𝑒𝑑 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒) / (𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑒 𝑜𝑓 𝑈𝑛𝑒𝑥𝑝𝑙𝑎𝑖𝑛𝑒𝑑 𝑉𝑎𝑟𝑖𝑎𝑛𝑐𝑒) Fp,n-2𝑝−1 = ( (𝑆𝑆𝐸𝑅𝑀−𝑆𝑆𝐸𝑈𝑀) /𝑝) /(𝑆𝑆𝐸𝑈𝑀 /𝑛−2𝑝−1) Where n is the number of observations and SSE is Sum of Squared Errors. If the p-values are less than a significance level (0.05) for at least one of the lags then reject the null hypothesis. Perform test for both the direction Xt->Yt and Yt->Xt. Try different lags (p). The optimal lag can be determined using AIC. Limitation Granger causality does not provide any insight on the relationship between the variable hence it is not true causality unlike ’cause and effect’ analysis. Granger causality fails to forecast when there is an interdependency between two or more variables (as stated in Case 3). Granger causality test can’t be performed on non-stationary data. Page 14 of 14