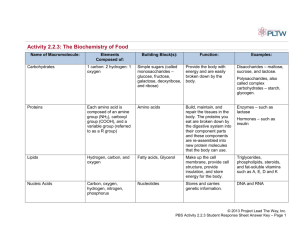
Module 2: Protein structure Learning Outcomes • Associate Professor Terry Mulhern 1 Learning Outcomes 1. 2. 3. 4. 5. 6. 7. 8. 9. 11. 12. 13. Describe where you would expect to find polar and nonpolar amino acids in a folded globular protein. Describe were you would expect to find Gly and Pro in a folded protein. List the overall features of folded proteins. Explain why protein folding is said to be cooperative. Explain how Christian Anfinsen’s experiments showed that under appropriate conditions protein folding is reversible. Describe the role of disulfide bonds in protein folding. Describe how cellular conditions are not ‘ideal’ for protein folding. Explain the role of protein folding chaperones in ‘protecting’ unfolded proteins from ‘misfolding’. List the forces drive protein folding and which chemical groups and amino acid type are involved in each interaction. Explain the thermodynamic basis of the hydrophobic interaction. List the different regions of a Ramachandran plot. Draw a labelled Ramachandran plot. Interpret structural information from a Ramachandran plot. Learning Outcomes 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. Describe how hydrogen bonding helps make proteins compact. Identify different hydrogen bonding interactions in a protein List the structural properties of alpha-helices. Explain why alpha-helices are often ‘amphipathic’. Draw a simplified helical wheel diagram. Read amino acid sequences to identify heptad repeat patterns. Explain the difference between a beta-strand and a beta-sheet. List the structural properties of beta-sheets. Explain how a beta-sheet can have hydrophilic and hydrophobic face. Read amino acid sequences to identify alternating sequence patterns. Draw a diagrams illustrating hydrogen bonding in antiparallel and parallel betasheets. 26. List the structural properties of reverse turns. 27. Explain the difference between type-I and type-II turns. 28. Read amino acid sequences to identify where turns are likely. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. Learning Outcomes Define regular and irregular structures. Identify regular and irregular structures from structural information. List the structural properties of proteins. Describe the three common supersecondary structures. Identify supersecondary structure in images of proteins. Explain the difference between primary, secondary, tertiary and quaternary protein structure. From images of proteins, identify secondary, tertiary and quaternary protein structures. Explain the difference between the terms domain fold and module. Define domain in terms of structure and evolution. Describe the genetic processes that create proteins with different functional properties using existing domain structures. Explain what is meant by the statement that protein sequences can be optimally aligned. Explain the link between sequence identity, ancestry, and structural similarity. Define homologue, orthologue and paralogue. Module 2: Protein structure Video 1: Locations of amino acids in proteins • Associate Professor Terry Mulhern 5 What is Expected of You? Learning Outcomes:(1) (2) Describe where you would expect to find polar and nonpolar amino acids in a folded globular protein. Describe were you would expect to find Gly and Pro in a folded protein. Location of residue types Where are different residues found? Example: Lysozyme All heavy atoms • There is no empty space inside a protein (proteins are compact) • Water is excluded from inside proteins. ribbon heavy side chain atoms Heavy atoms: C,O,N,S Carbon: Black Oxygen: Red Nitrogen: Blue Sulfur: Yellow Location of residue types Where are different residues found? Example: Lysozyme Polar side chains Exposed on the surface Nonpolar side chains Buried in the core Location of residue types Where are different residues found? Example: Lysozyme Gly Backbone shown (no side chain) In turns Pro In turns Module 2: Protein structure Video 2: Protein folding, unfolding and re-folding • Associate Professor Terry Mulhern 10 What is Expected of You? Learning Outcomes:- (1) List the overall features of folded proteins. (2) Understand why protein folding is said to be cooperative. (3) Explain how Christian Anfinsen’s experiments showed that under appropriate conditions protein folding is reversible. (4) Describe the role of disulfide bonds in protein folding What forces drive protein folding? General features of folded protein structures •Proteins are compact: there tends to be no empty space inside proteins because of close packing of backbone and side chain atoms •Water is generally excluded from the interior of proteins •Nonpolar (hydrophobic) side chains are usually located inside the protein •Polar (hydrophilic) side chains are usually located on the outside of the protein •How does a regular structure like the backbone pack closely? •How do irregular structures like side chains packing closely? •Why do proteins fold? i.e Why is the folded state more stable than unfolded states? What forces drive protein folding? •electrostatic forces •van der Waals interactions •hydrogen bonds •hydrophobic interactions These interactions combine to stabilise the folded state making it favoured over the unfolded state Folded state is called the ‘native’ state Unfolded state is said to be ‘denatured’ In solution, an unfolded polypeptide with spontaneously fold up. e.g. rapidly dilute a protein from denaturant (e.g. concentrated urea) to buffer. Figure 3-5 Molecular Biology of the Cell (© Garland Science 2008) Protein unfolding Urea To unfold a protein: ‘denature’ the native state To refold a protein: ‘renature’ Figure 3-6a Molecular Biology of the Cell (© Garland Science 2008) Protein folding/unfolding pH, Temperature, Denaturants Protein folding is co-operative (all or none) Transition between two states: folded and unfolded Folded and unfolded states are in equilibrium Protein folding is reversible % Unfolded 100% Unfolded 50% Folded 0% 6 8 10 pH 12 35 45 55 ºC 65 0 4 6 [GdnHCl] 8 Protein folding is cooperative Generally, if any part of a protein fold is disrupted interactions with the rest of the protein structure are disrupted and the remainder of the structure will be lost. Conditions that disrupt any part of the structure will lead to the whole protein unraveling. Folded state is only marginally more stable than the unfolded state Protein folding/unfolding is reversible (Under the appropriate conditions) https://en.wikipedia.org/wiki/Christian_B._Anfinsen Protein unfolding Protein re-folding SH HS SH HS SH HS Remove β-mercaptoethanol SH SH Remove 8 M urea Protein re-folding Remove 8 M urea Remove β-mercaptoethanol Protein re-folding Oxidation in the presence of urea gave ‘mixed’ disulfides (scrambled). Only a small fraction would have the pairings correct (105 different ways to arrange 8 cysteines). Only the correct pairing can stabilize the native structure. Adding a trace of βME reduces scrambled disulfides and then the protein can refold correctly. Under appropriate conditions Protein folding/unfolding is reversible Protein re-folding remove β-mercaptoethanol HS Air Oxidation SH HS SH HS SH HS SH SH Remove 8 M urea SH HS SH HS SH HS SH Add a little β-mercaptoethanol Protein folding is reversible (all the ‘information’ is in the sequence) Disulfide bonds don’t ‘direct’ folding Folding directs disulphide bond formation Disulfide bonds increase the relative stability of the folded state over the unfolded state(s) (lock on the correct folded state) Module 2: Protein structure Video 3: Chaperones • Associate Professor Terry Mulhern 24 What is Expected of You? Learning Outcomes:(1) (2) Describe how cellular conditions are not ‘ideal’ for protein folding Explain the role of protein folding chaperones in ‘protecting’ unfolded proteins from ‘misfolding’ Protein folding in vivo: Chaperones Although a polypeptide ‘should’ be able to fold unassisted under ‘ideal’ solution conditions. Conditions in the cell can make folding slow or impossible. Molecular crowding: cells are highly concentrated solutions of proteins/nucleic acids/sugars/lipids etc. ‘Inappropriate’ interactions may occur with other molecules before the protein can fold. Protein folding in vivo: Chaperones https://mgl.scripps.edu/people/goodsell/illustration/public/ Protein folding in vivo: Chaperones Although a polypeptide ‘should’ be able to fold unassisted, conditions in the cell can make folding slow or impossible Molecular crowding: cells are highly concentrated solutions ‘Inappropriate’ interactions may occur with other proteins/sugars/lipids etc. before the protein can fold Nascent polypeptide may misfold as they comes off the ribosome. The polypeptide chain grows by sequential addition of amino acid residues to the C-terminal end of the chain. Misfolding may occur because the sequence is not complete. Chaperones don’t fold the protein –they help avoid misfolding. Chaperones assist folding by binding to unfolded/partially folded polypeptides and protecting them from misfolding. Chaperones bind to temporarily exposed hydrophobic regions preventing them from interacting with the wrong partners: ‘inappropriate’ interactions. Protein folding in vivo: Chaperones https://mgl.scripps.edu/people/goodsell/illustration/public/ Module 2: Protein structure Video 4: Forces that drive protein folding • Associate Professor Terry Mulhern 31 What is Expected of You? Learning Outcomes:(1) (2) List the forces drive protein folding and which chemical groups and amino acid type are involved in each interaction. Be able to explain the thermodynamic basis of the hydrophobic interaction. Favorable Interactions in Proteins • Electrostatic interactions – long-range strong interactions between permanently charged groups – Salt bridges, especially those buried in the hydrophobic environment, strongly stabilize the protein. • London dispersion (van der Waals interactions) – Medium-range weak attraction between all atoms contributes significantly to the stability in the interior of the protein. • Hydrogen bonds – Interaction of N−H and C=O of the peptide bond leads to local regular structures such as α helices and β sheets. • Hydrophobic effect – The release of water molecules from the structured solvation layer around the molecule as protein folds increases the net entropy. Electrostatic forces: point charges Ionic interactions between oppositely charged groups in proteins are called “Salt bridges” Charges tend to be distributed over several atoms Component due to electrostatic interaction Component due to hydrogen bonding H N H C N CH2 CH2 H - + N O H C CH2 O H CH2 Arg Glu CH2 Electrostatic forces: dipoles Molecules do not need net charge to form electrostatic interactions Electron density can be localised due to electronegativity (electronegativity O>N>C>S>H) O O C Cα :N H - C Cα Cα -0.42 O Example of dipole: Peptide bond The peptide bond has partial double-bond character due to resonance Cα +0.42 N H+ Cα C Cα N Double bonded species is populated 40% H Giving rise to partial charges on the atoms Separation of charges gives a “dipole moment” (distance×charge) Dipoles can interact with each other and point charges (see α-helix) -0.20 +0.20 Van der Waals interaction Lennard-Jones C12 C 6 E r = − ( ) 6,12 potential r 12 r 6 C12, C6 constants 0.2 Interaction Energy (kcal/mol) Zero point at combined VDW radii (Same interaction energy as when separate) Repulsion Steeper 1/r12 0 ∆E: Energy Difference -0.2 Optimal VDW Er - E∞ interaction 0 2 Attraction Shallower 1/r6 4 6 Distance r (Å) 8 +ve inter. energy Less favourable than When ∞ separated -ve inter. energy More favourable than When ∞ separated Most favourable distance -almost touching Hydrogen bonds A hydrogen bond occurs when two electronegative atoms compete for The same hydrogen atom: Hydrogen bond Acceptor D H A Hydrogen bond Donor δ− δ+ δ− D H A The main component of the hydrogen bond is electrostatic Dipole of D-H interacting with the partial negative charge on A In strong hydrogen bonds there is also a covalent component based on transfer of electrons from A to H Result: the most favourable (and common) geometry has D-H..A collinear Hydrophobic interactions The electrostatic, hydrogen bond, and van der Waals interactions between two polar groups in aqueous environment not particularly favourable -because comparable competing interactions are possible with water Why then do proteins fold? Proteins also contain nonpolar groups. Water is a poor solvent for nonpolar groups compared with organic solvents Nonpolar groups cannot form hydrogen bond networks Nonpolar groups prefer to interact with other nonpolar groups The process is driven by entropy ∆G = ∆H − T∆S Free energy Enthalpy (heat) Entropy (disorder) Favourable ∆G (negative) given by negative ∆H + positive ∆S i.e. increase the disorder somehow (but how?) BUT Polypeptide chain is more ordered when it folds?? Hydrophobic interactions Removal of hydrophobic side chains from water. Releases ordered water from hydrophobic side chains (favorable entropy) E.g. oil droplets, organic solvents in water etc. The hydrophobic effect Hydrophobic interactions Removal of hydrophobic side chains from water releases ordered water from hydrophobic side chains Folded protein: Burial of nonpolar side chians, many ‘ordered’ water molecules released -disordered Lower entropy Unfolded Exposed nonpolar side chains Many ‘ordered’ water molecules Higher entropy Module 2: Protein structure Video 5: Ramachandran plots • Associate Professor Terry Mulhern 41 What is Expected of You? Learning Outcomes:- (1) List the different regions of a Ramachandran plot. (2) Draw a labelled Ramachandran plot. (3) Interpret structural information from a Ramachandran plot. Dihedral/torsion angles: φ and ψ Why are phi (φ) and psi (ψ) so important? Because: assuming all peptide bonds are trans All the conformational freedom in the backbone of a polypeptide is due to these two rotations. Everything else in this diagram is fixed H R H O φ C Cα N H C N ψ C Cα O The backbone conformation of a protein can be completely described In terms of a pair of angles (φ,ψ) Ramachandran plot Named after the Indian Biophysicist G.N. Ramachandran 1968 Figure 3-3b Molecular Biology of the Cell (© Garland Science 2008) The Polypeptide Is Made Up of a Series of Planes Linked at α Carbons Distribution of φ and ψ Dihedral Angles • Some φ and ψ combinations are very unfavorable because of steric crowding of backbone atoms with other atoms in the backbone or side chains. • Some φ and ψ combinations are more favorable because of chance to form favorable H-bonding interactions along the backbone. • A Ramachandran plot shows the distribution of φ and ψ dihedral angles that are found in a protein: • shows the common secondary structure elements • reveals the presence unusual backbone structure Ramachandran Plot Ramachandran Plot Ramachandran plot for the enzyme pyruvate kinase (isolated from rabbit) are overlaid on the plot of theoretically allowed conformations Ramachandran Plot • Not all residues in the ‘β’ region are in beta-strands Regions of ‘Ramachandran space’ α β L D β L alpha beta left-handed turn disallowed • Not all residues in the ‘α’ region are in beta-strands • ‘Disallowed’ really means unfavourable or uncommon, but not impossible α D (all the white) • All residues are subject to steric hindrance that favours the α, β or L regions –even if they are in irregular structures like ‘random coil’ Secondary Structures • Secondary structure refers to a local spatial arrangement of the polypeptide backbone. • Two regular arrangements are common: • the α helix – Multiple consecutive residues in α region – stabilized by hydrogen bonds between residues nearby in the sequence • the β sheet – Multiple consecutive residues in β region – stabilized by hydrogen bonds between adjacent segments that may not be nearby in the sequence • Irregular arrangement of the polypeptide chain is called the random coil. Module 2: Protein structure Video 6: Alpha-helices • Associate Professor Terry Mulhern 51 What is Expected of You? Learning Outcomes:- (1) Describe how hydrogen bonding helps make proteins compact (2) Identify different hydrogen bonding interactions in a protein (3) List the structural properties of alpha-helices (4) Explain why alpha-helices are often ‘amphipathic’ (5) Draw a simplified helical wheel diagram (6) Read amino acid sequences to identify heptad repeat patterns Hydrogen bonds in proteins • Any polar group buried in the protein must form a hydrogen bond. This will include charged groups, but these are rarely buried. • There is a +ve partial charge on the donor (H) and –ve partial charge on the acceptor (O). −δ +δ +δ −δ • The atoms of a hydrogen bond can approach much closer than a VDW interaction (2.7 Å compared to 1.9 Å) due to covalent character of the hydrogen bond • This increases the compactness and stability of a protein. Hydrogen bonds: backbone and side chain Can be: Backbone-backbone Backbone-side chain Side chain-side chain Hydrogen bonds: secondary structure Close packing of the polypeptide backbone Is achieved by several hydrogen bonding patterns Beta-sheet (NH residue i to C=O residue j) Alpha-helix (NH residue i to C=O residue i-4) Reverse turns (NH residue i+3 to C=O residue i) L/R-handed β L α Hydrogen bonds should Always be described Donor to acceptor NH to C=O Hydrogen bonds: alpha-helix N C 3.6 residues per turn (100 ° per res.) 5.4 Å per turn (1.5 Å axial rise per res) Side chains project outwards from helix axis Hydrogen bonds: alpha-helix N RH i-4 i-3 • The helix is right-handed • Abundant i-2 • φ,ψ -57º, -47º • NH (residue i) to C=O (residue i-4) • All NH and C=O within the helix (except four at each end) form favourable internal hydrogen bonds. i-1 i C • Peptide bond dipoles add together giving a macrodipole N O || C i-4 H | N i-3 i-2 i-1 i i+1 i+2 i+3 i+4 C Secondary structure: alpha-helices Ways of forming a hydrophobic ‘core’ All α Bundles Mixed αβ Coiled coils The α Helix: Top View • The inner diameter of the helix (no side chains) is about 4–5 Å. • too small for anything to fit “inside” (not even water) • The outer diameter of the helix (with side chains) is 10–12 Å. • happens to fit well into the major groove of dsDNA • Amino acids #1 and #8 align nicely on top of each other. • What kind of sequence gives an α helix with one hydrophobic face? Secondary structure: alpha-helices 8 4 1 a d e 7 g 5 b 2 c 3 f 6 Heptad repeat: abcdefg One heptad (7 x 100°) ~ 2 x 360° Two times around abcdefgabcdefgabcdefgabcdefg abcdefgabcdefgabcdefg | | | | | | HxxHxxxHxxHxxxHxxHxxx Sequence Affects Helix Stability • Not all polypeptide sequences adopt α-helical structures. • Small hydrophobic residues such as Ala and Leu are strong helix formers. • Pro acts as a helix breaker because it lacks the NH hydrogen bond donor • Gly acts as a helix breaker because the tiny R group doesn’t contribute to stability of helix • Attractive or repulsive interactions between side chains 3 to 4 amino acids apart will affect formation (e.g. stabilized by oppositely charged residues 3-4 away in sequence) Module 2: Protein structure Video 7: Beta-sheets • Associate Professor Terry Mulhern 63 What is Expected of You? Learning Outcomes:- (1) Explain the difference between a beta-strand and a beta-sheet (2) List the structural properties of beta-sheets (3) Explain how a beta-sheet can have hydrophilic and hydrophobic face (4) Read amino acid sequences to identify alternating sequence patterns (5) Draw a diagrams illustrating hydrogen bonding in antiparallel and parallel beta-sheets Beta-Sheets • The planarity of the peptide bond and tetrahedral geometry of the α carbon create a pleated sheet-like structure. • Sheet-like arrangement of the backbone is held together by hydrogen bonds between the backbone amides in different strands. • Side chains protrude from the sheet, alternating in an up-and-down direction. https://www.marksandspencer.com/au/pure-cotton-regular-fit-dinnershirt/p/P60116615.html?carousel=dwRec https://www.bestandless.com.au/School-Uniforms-%26-Accessories/GirlsSchoolwear/Girls-School-Skirts-Skorts-%26-Dresses/Girls-SchoolSkirts/Girls-Netball-Skirt Hydrogen bonds: beta-sheet Hydrogen bonds: beta-sheet • A β-sheet consists of two or more β-strands. The strand is the element. • Strands are either parallel or antiparallel to neighbouring strands. Sheets can be pure or mixed. • φ,ψ -130º, +130º (approx.) • Twisted sheets are abundant Parallel: H-bond connect each residue to two different residues on opposite strand Antiparallel: H-bond connect each residue to a single residue on opposite strand • Hydrogen bonds between NH and C=O of neighbouring strands: antiparallel more stable; outer NH and C=O of a sheet are not hydrogen bonded. In parallel β sheets, the H-bonded strands run in the same direction. • Hydrogen bonds between strands are bent (weaker). In antiparallel β sheets, the H-bonded strands run in opposite directions. • Hydrogen bonds between strands are linear (stronger). Secondary structure: beta-sheet e.g. β-barrel Hydrophobic side chains are packed into the core of the barrel Hydrophilic side chains project outwards into the solvent Alternate residues hydrophobic/hydrophilic Module 2: Protein structure Video 8: Reverse turns • Associate Professor Terry Mulhern 72 What is Expected of You? Learning Outcomes:- (1) List the structural properties of reverse turns (2) Explain the difference between type-I and type-II turns (3) Read amino acid sequences to identify where turns are likely (4) Define regular and irregular structures (5) Identify regular and irregular structures from structural information Secondary structure: beta-sheet e.g. β-barrel Hydrophobic side chains are packed into the core of the barrel Hydrophilic side chains project outwards into the solvent Alternate residues hydrophobic/hydrophilic Reverse Turns (β Turns) • Turns occur frequently whenever strands in β sheets change the direction. • The 180° turn is accomplished over four amino acids. • The turn is stabilized by a hydrogen bond from a carbonyl oxygen of position 1 to amide hydrogen of position 4 in the turn (i and i+3). • Proline in position 2 (i+1) or glycine in position 3 (i+2) are common in β turns. Hydrogen bonds: beta-turns Called β-turns or reverse turns β-turns reverse the direction of the main chain Abundant, mostly on surface, redirect backbone (particularly for β-sheets). Consist of four residues Residues i+1 and i+2 have different φ,ψ angles A hydrogen bond between NH of the fourth (i+3) the carbonyl of the first (i) and the stabilizes the turn. Proline often in position i+1 (φ=-60 matches requirement of most β-turns) Type II turns often have Gly in position i+2, R Gly fav. because lack of side chain lessens “steric hindrance” [C=O clash with R group]. Positive φ at position i+2 Type I and II differ by the direction i+1 carbonyl Regular (and irregular) elements of protein structure • β-sheets and α-helices are abundant elements of regular secondary structure. • Regular structure is defined as residues that have repeating φ,ψ angles (consecutive residues). • Regular structures are stabilized by a repeating pattern of hydrogen bonds. They present side chains in a predictable fashion and pack together in limited ways. • β-turns are a simple way of reversing the main chain. They are also stabilized by a hydrogen bond. Each residue in the turn performs a different structural role and has different φ,ψ angles (irregular) • Irregular structure often links regular elements and is termed ‘loop’ or ‘random coil’ structure Why are we alive? Various interactions stabilise the structure of proteins Electrostatics: salt bridges dipole interactions Van der Waals: close packing of atoms Hydrogen bonds: side chain to side chain side chain to backbone backbone to backbone Several backbone-backbone hydrogen bonding patterns facilitate close packing of the polypeptide These intra-protein effects in the folded state are almost balanced by protein-solvent effects in the unfolded state; i.e. these forces alone are not sufficient to make folded proteins stable BUT The burial of nonpolar groups in the hydrophobic core of proteins can only occur in the folded state Burial is entropically favourable (release of ordered water) and drives protein folding Because we are wet Module 2: Protein structure Video 9: Supersecondary structure • Associate Professor Terry Mulhern 80 What is Expected of You? Learning Outcomes:- (1) List the structural properties of proteins (2) Describe the three common supersecondary structures (3) Identify supersecondary structure in images of proteins Principles of Protein Structure • The peptide bond is usually trans, planar and fairly rigid. • There are limitations on the dihedral angles that the main chain of the protein can adopt (Ramachandran Plot). • Repeating preferred φ,ψ angles are characteristic of the commonly observed α-helices and β-strands. • All buried polar groups to form hydrogen bonds. • Proteins are compact because of favourable VDW contacts and hydrogen bonds. • There are a small group of supersecondary structure elements that pack together to make up folded proteins • There is an entropic requirement to bury hydrophobic residues Most folds consist of a high content of three small repeating supersecondary structural elements. αα-hairpin ββ-hairpin β-trefoil Jelly Roll Immunoglobulin-like TIM barrel Ferredoxin-like 4-helix Updown OB fold UB-roll Globin-like Doubly wound All folds βαβ Supersecondary Structure (%) 83 47 67 82 38 90 77 55 88 68 62 αα-hairpin ββ-hairpin βαβ Module 2: Protein structure Video 10: Hierarchy of protein structure • Associate Professor Terry Mulhern 85 What is Expected of You? Learning Outcomes:- (1) Explain the difference between primary, secondary, tertiary and quaternary protein structure. (2) From images of proteins, identify secondary, tertiary and quaternary protein structures. Four Levels of Protein Structure αα-hairpin ββ-hairpin βαβ Hierarchy of Protein Structure subunit = polypeptide chain 1. Primary structure: amino acid sequence 2. Secondary structure: elements, α-helix, β-sheet, turns (simple motifs α−α, β−β, β−α−β –supersecondary structure) 3. Tertiary structure (domains, folds, modules) Primary structure Nter-EEWYFGKITRRESERLLLNAENPRGTFLVRES -Cter Secondary structure Supersecondary structure β1 β2 α β−α−β β1 α β2 SH2 Tertiary structure Protein Tertiary Structure • Tertiary structure refers to the overall spatial arrangement of atoms in a protein. • Stabilized by numerous weak interactions between amino acid side chains − largely hydrophobic and polar interactions − can be stabilized by disulfide bonds • Interacting amino acids are not necessarily next to each other in the primary sequence. • Tertiary structure refers to domains/folds/modules and arrangement of domains (in a single subunit) Hierarchy of Protein Structure 1. Primary structure: amino acid sequence 2. Secondary structure: elements, α-helix, β-sheet, turns (simple motifs α−α, β−β, β−α−β –supersecondary structure) 3. Tertiary structure: folds, modules, domains, arrangement. Nter-EEWYFGKITRRESERLLLNAENPRGTFLVRES -Cter 3 β−α−β β1 α β2 2 SH2 3 Quaternary Structure A quaternary structure is formed by the assembly of individual polypeptides into a larger functional cluster. Hierarchy of protein structure • Special Case: multiple chains • Tertiary: describes the fold of a protein chain/subunit • Quaternary: the arrangement of two or more protein subunits Ribbon diagram of a homodimer of two protein chains N C Tertiary structure describes the fold of each domain in a subunit and their arrangement (single chain) Two domains Two chains N C Quaternary structure describes the subunit arrangement (multiple chains) Hierarchy of protein structure Four domains One chain Four domains Four chains Src kinase: composed of four domains Example of tertiary structure neuraminidase: composed of four domains Example of quaternary structure Figure 3-10 Molecular Biology of the Cell (© Garland Science 2008) Figure 3-21 Molecular Biology of the Cell (© Garland Science 2008) Hierarchy of protein structure N C Four domains One chain Four domains Four chains Src kinase: composed of four domains Example of tertiary structure neuraminidase: composed of four domains Example of quaternary structure Figure 3-10 Molecular Biology of the Cell (© Garland Science 2008) Figure 3-21 Molecular Biology of the Cell (© Garland Science 2008) Module 2: Protein structure Video 11: Domains, folds and modules • Associate Professor Terry Mulhern 96 What is Expected of You? Learning Outcomes:- (1) Explain the difference between the terms domain fold and module. What is a Domain? Primary structure: Secondary structure: Tertiary structure: amino acid sequence arrangement of sequence into elements (α and β) arrangement of elements into one or more domain A single protein chain can consist of one or more domains. • Although many proteins consist of a single polypeptide chain they can be divided into separate domains. • A domain is a region within the native tertiary structure for which evidence can be provided of an existence independent of the rest of the protein (fold independently) One chain Two domains Hierarchy of Protein Structure 1. Primary structure: amino acid sequence 2. Secondary structure: elements, α-helix, β-sheet, turns (simple motifs α−α, β−β, β−α−β –supersecondary structure) 3. Tertiary structure: folds, modules, domains, arrangement. Nter-EEWYFGKITRRESERLLLNAENPRGTFLVRES -Cter 3 β−α−β β1 α β2 2 SH2 3 What is a Fold? G6E G6 G6E XT Src SH2 XR6 ute A protein fold is defined by the arrangement of secondary structure elements relative to each other in space. https://www.goauto.com.au/futuremodels/ford/falcon/range/ford-previews-2012-falconfacelift/2011-09-15/12513.html Phosphotyrosine recognition domains: the typical, the atypical and the versatile. Kaneko T1, Joshi R, Feller SM, Li SS. Cell Commun Signal. 2012 Nov 7;10(1):32. doi: 10.1186/1478811X-10-32. What is a Module? New proteins have evolved by Gene duplication and domain shuffling EGF Protease Kringle Ca2+ binding • Can attribute a function to individual folds: catalytic, lipid-binding, peptidebinding, DNA-binding, fibronectin-binding, transmembrane, etc. • Many proteins are modular: have one or more repeating fold within their overall structure – many transcription factors have three or more zinc fingers. Hierarchy of protein structure • Tertiary structure: the fold of a single protein subunit. • Protein subunits can consist of more than one domain: considered to be a discrete unit of protein folding, and can be viewed independent of the rest of the protein subunit. • Over half of domain structures can be broken down into three repeating supersecondary structural elements: ααhairpin, ββ-hairpin, βαβ-element. • There are 30,000 proteins (genes) →100,000 domains but only 3,000 folds (prediction). ~2,500 different folds are known so far. • Soon, we should be able to predict the fold or identify the domains of most proteins… https://www.heraldsun.com.au/news/victoria/worst-traffic-times-melbourne-uber-driver-study-shows-tullamarine-freeway-the-most-frustrating/newsstory/f8fc66cb75efbe87f6c238d482c026fb https://en.wikipedia.org/wiki/Road_train https://www.youtube.com/watch?v=0iFkKRh5kcM Module 2: Protein structure Video 12: Protein evolution • Associate Professor Terry Mulhern 105 What is Expected of You? Learning Outcomes:1. 2. 3. 4. 5. Define domain in terms of structure and evolution. Describe the genetic processes that create proteins with different functional properties using existing domain structures. Explain what is meant by the statement that protein sequences can be optimally aligned. Explain the link between sequence identity, ancestry, and structural similarity. Define homologue, orthologue and paralogue. New proteins with new functions are been made by mixing domains and mutating existing domains New proteins with new properties and functions can be generated by: 1. Intragenic mutation: point mutations, insertions and deletions 2. Gene duplication: whole or part of a genome is duplicated 3. DNA segment shuffle: two or more existing genes can be broken (*) and recombined 4. Gene lateral transfer: one organism acquires parts of the genome of another. * Think of the broken “fragment” as a domain or string of domains A Domain can be defined as an evolutionary unit rather than a structural unit: a brief introduction to bioinformatics. • New proteins have evolved by gene duplication and domain shuffling. This implies domains can have a common protein ancestor. • The individual domains are further subjected to point mutations, insertions and deletions (change, gain and loss of function). • No new domains (folds) are being created – only modified and readjusted – (we think nature has finished exploring protein fold space). Original gene maintains phenotype and function Original gene: • Mutations that do not effect function retained. New gene gives redundancy Time Gene duplication. New gene: • Mutations may change/lose/gain function; • environmental pressure selects if advantageous. Mutagenesis allows sequence to drift Sequences may now differ substantially……how different and what has happened to the structure? Sequences of protein domains can be aligned on the basis of sequence residue identity or similarity • Protein sequences can be aligned based on identical and similar residues. • Identity means exactly the same residue (invariant) • Similar means a change to a residue that is observed frequently or with similar physical-chemical properties eg Ser to Thr, Val to Leu (conservative) • Alignments can be improved by introducing gaps that account for residue insertions and deletions. Similar residues Identical residues Better alignment by introducing gap Aligning two sequences of EF-Tu (Elongation Factors) from two bacteria based on sequence identity and introducing a single gap. (see Figs 3-33 and 3-34 Lehninger 6ed) How do the structures of proteins that are related by such evolutionary events such as gene duplication, but have different sequences, compare? Identical residue, 31% identity • Each sequence “change” results in a small change to structure. • Structure, however, changes much more slowly than sequence. This means that for two proteins whose sequences show >25% identity they will have a similar structure. • In general they will have similar secondary and tertiary structures. Gaps between two sequences will result in a loop insertion within the general structural fold. Primary amino acid sequence of domains can be aligned. A general observation is – if the two sequences show > 25% identity the protein domains are considered to be homologues. To say two protein domains are homologues has special meaning – it implies they arose from an event such as gene duplication (so they share a common protein domain ancestor) *and* that means “they have the same fold”. Homologues can be divided into two groups: • Orthologue: homologous proteins that perform the same function in different species eg horse and tuna trypsin • Paralogue: homologous proteins that perform different but related functions within one organism eg human trypsin, compared with human thrombin If sequence identity is low <<25%, and proteins are functionally different, it is hard to draw conclusions. If we find the fold to be similar then they are likely to be homologues. An example of probable gene duplication: chymotrypsin and thrombin, two homologous (paralogues) serine proteases • Sequences show 38% sequence identity • The structures are strikingly similar – small differences –loop size (*), extra helical turn (#), but same β-structure and same overall fold. Common Ancestor Gene duplication, mutagenesis • Each has the same functionally essential residues that are involved in catalysis # * * * • Differ in substrate specificity, and so binding pockets have modified for specific function. * • structure changes more slowly than sequence • Different parts of the protein mutate at different rates (conservation of functional residues) Chymotrypsin, digestion Thrombin, blood clotting 8gch 1abi H57 S195 D102 Overlay of functional residues; same three dimensional structure.