World Data HANDLING DATA COURSEWORK
advertisement

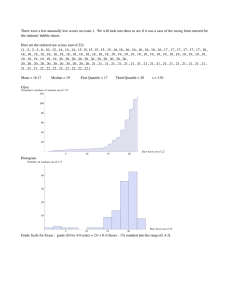
HANDLING DATA COURSEWORK World Data Main Menu What is Coursework??? Specify and Plan Collect, Process & Represent Interpret and Discuss What You Should Do? Planning the Investigation Sample Mean, Median, Mode and Range Pie Charts Bar Charts Histograms and Freq Polygons Scatter Plots Stem and Leaf Plots Cumulative Frequency Box and Whisker Plots Your Task Is given in detail on the task sheet. Basically your task is to: “investigate what influences the amount a student drinks.” The database has been selected for you from Rondam Secondary school. What Will Happen A MIX OF THE FOLLOWING: •Direct Teaching – statistics skills, ICT, investigation cycle •Group Work – planning, discussing, •Individual Time – writing up, working Hypothesis Specify and Plan How could you make it better? Interpret and discuss Investigation cycle Collect, process and represent Specify and plan What to do in this section? Examine the Writing Frame and what decisions you must make to fill it in. Decide on the hypothesis you are going to test. Make sure it is well explained. Write a clear and detailed description of the task and your plan to test the hypothesis. Do a draft first. Your final write up will come later. Hypothesis Collect,Specify Process and Plan Represent How could youand make it better? Interpret and discuss Investigation cycle Collect, process and represent Specify and plan What to do in this section? Collect the data – fully explain your sampling technique and sample size. Tabulate the data. Only include the information relevant to your hypothesis. Using statistical and graphical methods to process and examine the data. Hypothesis Interpret Specify and and Plan How could you make itDiscuss better? Interpret and discuss Investigation cycle Collect, process and represent Specify and plan What to do in this section? This is the big crunch section. Draw conclusions from all of your calculations and relate these to your initial hypothesis. Make sure you: Compare results to show differences/similarities. Use facts and statistics taken directly from your calculations. Evaluate your approach and explain any changes you would make if you were doing it again. Consider bias in your results. And Now ……. Challenge What will a good piece of maths investigative work look like ??? You should consider: • What will it contain? • How will it be presented? • How will it be marked? • What will it look like? 15 mins in groups of 5 or 6 Formulating a hypothesis The first step in planning a statistical enquiry is to decide what problem you want to explore. This can be done by asking questions that you want your data to answer and by stating a hypothesis. A hypothesis is a statement that you believe to be true but that you have not yet tested. The plural of hypothesis is hypotheses. For example, Year Eleven pupils with paid jobs don’t do as well in their exams. Forming a hypothesis “Year Eleven pupils with paid jobs don’t do as well in their exams.” How could you find out if this statement is true? Think about: What data (information) would you need to collect? How will you collect it? Which Year Elevens does this statement cover? How could you ensure the data you collect represents all of these Year Elevens? What would you do with the data? What would you expect to find? Key vocabulary hypothesis – a statement that can be tested population – the group (often of people) referred to in the hypothesis sample – a selection from the population biased sample – an unfair selection representative sample – a fair selection cross section – a selection that reflects all the subgroups within the population objective data – information that is not affected by people’s opinions Key vocabulary subjective data – information that is affected by people’s opinions primary data – information you collect yourself, by asking people, measuring, carrying out experiments, and so on secondary data – information that has been collected already, that you get from books, the internet, and so on ethical issues – problems to do with confidentiality and personal questions reliable results – results that will be repeated if the experiment or survey is carried out again with a new sample Extending a hypothesis Once you have collected data and drawn conclusions about your hypothesis, you could ask further questions and pursue other lines of enquiry. You will need to plan what these might be beforehand if you are carrying out a survey. For example, “People feel stressed when they have exams.” “You get less work done when it is noisy.” “Sleep deprivation affects concentration.” “Coffee can help you revise better.” “The more revision you do, the better your exam results.” How could you extend these hypotheses? What extra information might it be worth collecting? Sampling – Soap Wars Westenders 12 Carnation Street 10 Millions 8 6 4 2 JAN FEB MAR APR MAY AUG VIEWING FIGURES How are TV viewing figures compiled? Television viewing figures When compiling television viewing figures, it is impractical to find out what everyone in the country is watching at a particular time. Instead, the viewing habits of a sample of households is carefully monitored and the data collected is used to compile the figures. To avoid bias, it is important that the sample is representative of all television viewing households across the country. This is done by dividing households into categories and taking samples in proportion to the size of each category. This is an example of a stratified sample. Different sampling methods Random sampling People are chosen at random e.g. names picked from a hat or using a random number generator on a calculator. Every member of the population has an equal chance of being chosen. Systematic sampling Members of the population are chosen at regular intervals, such as every 100th person from a telephone directory. Quota sampling You keep asking until you have enough people from each category. An example would be a survey in the street where you stop when you have enough people from each age category. Evaluating different sampling methods Random sampling Every member of the population has an equal chance of being chosen, which makes it fair. It can be very time consuming and usually impractical. Systematic sampling You are unlikely to get a biased sample. It is not strictly random: some members of the population cannot be chosen once you have decided where to start on the list. Evaluating different sampling methods Quota sampling This is easier to manage. It could be biased. For example, if you are only asking people on the street or in a shop, the sample might not represent people at work all day. Stratified sampling It is the best way to reflect the population accurately. It is time consuming and you have to limit the number of relevant variables to make it practical. The three averages and range There are three different types of average: MODE MEAN MEDIAN most common sum of values number of values middle value The range is not an average, but tells you how the data is spread out: RANGE largest value – smallest value Comparing sets of data Here is a summary of Chris and Rob’s performance in the 200 metres over a season. They each ran 10 races. Mean Range Chris Rob 24.8 seconds 1.4 seconds 25.0 seconds 0.9 seconds Which of these conclusions are correct? Robert is more reliable. Robert is better because his mean is higher. Chris is better because his range is higher. Chris must have run a better time for his quickest race. On average, Chris is faster but he is less consistent. Pie charts A pie chart is a circle divided up into sectors which are representative of the data. In a pie chart, each category is shown as a fraction of the circle. Methods of travel to work For example, in a survey half the people asked drove to work, a quarter walked and a quarter went by bus. Car Walk Bus Pie charts To convert raw data into angles for n data items: 360 ÷ n represents the number of degrees per data item. For example, 40 people take part in a survey. What angle represents one person? 360° ÷ 40 = 9° two people? 9° × 2 = 18° eight people? 9° × 8 = 72° How many people are represented by an angle of 36°? There are 9° per person. 36° ÷ 9° = 4 people. Drawing pie charts There are 30 people in the survey and 360º in a full pie chart. Each person is therefore represented by 360º ÷ 30 = 12º We can now calculate the angle for each category: Newspaper No of people Working Angle The Guardian 8 8 × 12º 96º Daily Mirror 7 7 × 12º 84º The Times 3 3 × 12º 36º The Sun 6 6 × 12º 72º Daily Express 6 6 × 12º 72º Total 30 360º Drawing pie charts Once the angles have been calculated you can draw the pie chart. Start by drawing a circle using a compass. The Daily The Express Draw a radius. Guardian 72º 96º Measure an angle of 96º from 72º the radius using a protractor 84º The Sun 36º The Daily and label the sector. Mirror The Measure an angle of 84º from Times the the last line you drew and label the sector. Repeat for each sector until the pie chart is complete. Drawing bar charts When drawing bar chart remember: Give the bar chart a title. Use equal intervals on the axes. Label both the axes. Leave a gap between each bar. Drawing bar charts Use the data in the frequency table to complete a bar chart showing the the number of children absent from school from each year group on a particular day. Year Number of absences 7 74 8 53 9 32 10 11 11 10 Bar charts for two sets of data Two or more sets of data can be shown on a bar chart. For example, this bar chart shows favourite subjects for a group of boys and girls. Girls' and boys' favourite subjects 8 Number of pupils 7 6 5 Girls 4 Boys 3 2 1 0 Maths Science English Favourite subject History PE Frequency diagrams Frequency diagrams can be used to display grouped continuous data. For example, this frequency diagram shows the distribution of heights for a group students: Heights of students Frequency 35 30 25 20 15 10 5 0 150 155 160 165 170 175 180 185 Height (cm) This type of frequency diagram is often called a histogram. Drawing frequency diagrams Use the data in the frequency table to complete the frequency diagram showing the time pupils spent watching TV on a particular evening: Time spent (hours) Number of people 0≤h<1 4 1≤h<2 2≤h<3 3≤h<4 4≤h<5 6 8 5 3 h≤5 1 Histograms and Frequency Polygons We can show the trend of these graphs more clearly using a FREQUENCY POLYGON. Using a previous example, you first need to draw a histogram Then joint the midpoints of each column. Heights of Year 8 pupils 35 Frequency 30 25 20 15 10 5 0 140 145 150 155 160 Height (cm) 165 170 175 Scatter Graphs Scatter graphs What does this scatter graph show? Life expectancy 85 80 75 70 65 60 55 50 0 20 40 60 80 100 Number of cigarettes smoked in a week 120 It shows that life expectancy decreases as the number of cigarettes smoked increases. This is called a negative correlation. Interpreting scatter graphs Scatter graphs can show a relationship between two variables. This relationship is called correlation. Correlation is a general trend. Some data items will not fit this trend, as there are often exceptions to a rule. They are called outliers. Scatter graphs can show: positive correlation: as one variable increases, so does the other variable negative correlation: as one variable increases, the other variable decreases zero correlation: no linear relationship between the variables. Correlation can be weak or strong. The line of best fit The line of best fit is drawn by eye so that there are roughly an equal number of points below and above the line. Look at these examples, 25 25 25 25 20 20 20 20 15 15 15 15 10 10 10 10 5 0 0 0 5 10 15 20 25 Strong positive correlation 5 5 5 0 0 0 5 10 15 20 Weak positive correlation 25 0 5 10 15 20 25 Strong negative correlation 0 5 10 15 20 25 Weak negative correlation Notice that the stronger the correlation, the closer the points are to the line. If the gradient is positive, the correlation is positive and if the gradient is negative, then the correlation is also negative. Line of best fit When drawing the line of best fit remember the following points, The line does not have to pass through the origin. For an accurate line of best fit, find the mean for each variable. This forms a coordinate, which can be plotted. The line of best fit should pass through this point. The line of best fit can be used to predict one variable from another. It should not be used for predictions outside the range of data used. The equation of the line of best fit can be found using the gradient and intercept. Constructing stem-and-leaf diagrams The data below represents the numbers of cigarettes smoked in a week by regular smokers in Year 11. 7 15 5 38 13 10 41 23 30 22 45 20 20 7 7 11 5 17 24 30 17 19 Put this data into a stem-and-leaf diagram. The stem should represent ____ tens and the leaf should units represent _____. Work out the mode, mean, median and range. Calculations with stem-and-leaf diagrams Stem (tens) Leaf (units) 0 5 5 7 7 7 1 0 1 3 5 7 7 9 Mode The mode is __ 7 . Mean There are ___ 22 people in the survey and they smoke a total 427 cigarettes a week. of ____ 427 ÷ 22 =___ 19 2 0 0 2 3 4 3 0 0 8 4 1 5 Median The median is halfway between 17 and ___. 19 This is ___. 18 ___ Range ___ 45 – ___ 5 = ___ 40 Solving problems with stem-and-leaf diagrams Stem (tens) Leaf (units) 0 5 5 7 7 7 1 0 1 3 5 7 7 9 2 0 0 2 3 4 3 0 0 8 4 1 5 What fraction of the group smoke more than 20 cigarettes a week? What is this as a percentage? The mean number smoked is 19. How many smoke less than the mean? What is this as a percentage? What percentage smoke less than 10 cigarettes? A packet of 20 cigarettes costs about £4. Work out the average amount spent on cigarettes using the median. Cumulative Freq - Choosing class intervals You are going to record how long each member of your class can keep their eyes open without blinking. How could this information be recorded? What practical issues might arise? Time is an example of continuous data. You will have to decide how accurately to measure the times, to the nearest tenth of a second? to the nearest second? to the nearest five seconds? Holding Your Breath You will also have to decide what size class intervals to use. When continuous data is grouped into class intervals it is important that no values are missed out and that there are no overlaps. For example, you may decide to use class intervals with a width of 5 seconds. If everyone holds their breath for more than 30 seconds the first class interval would be more than 30 seconds, up to and including 35 seconds. This is usually written as 30 < t ≤ 35, where t is the time in seconds. < t ≤ 40 The next class interval would be 35 _________. Cumulative frequency Cumulative frequency is a running total. It is calculated by adding up the frequencies up to that point. Here are the results of 100 people holding their breath: Time in seconds 30 < t ≤ 35 35 < t ≤ 40 40 < t ≤ 45 45 < t ≤ 50 50 < t ≤ 55 55 < t ≤ 60 Frequency 9 12 24 28 16 11 Cumulative frequency 9 9 + 12 = 21 21 + 24 = 45 45 + 28 = 73 73 + 16 = 89 89 + 11 = 100 Time in seconds 0 < t ≤ 35 0 < t ≤ 40 0 < t ≤ 45 0 < t ≤ 50 0 < t ≤ 55 0 < t ≤ 60 Plotting a cumulative frequency graph 100 The upper boundary for each class interval is plotted against its cumulative frequency. 90 Cumulative frequency 80 70 A smooth curve is then drawn through the points. 60 50 We can use the graph to estimate the median by finding the time for the 50th person. 40 30 This gives us a median time of 47 seconds. 20 10 0 30 35 40 45 50 55 Time in seconds 60 The interquartile range Remember, the range is a measure of spread. It is the difference between the highest value and the lowest value. When the range is affected by outliers it is often more appropriate to use the interquartile range. The interquartile range is the range of the middle 50% of the data. The lower quartile is the data item ¼ of the way along the list. The upper quartile is the data item ¾ of the way along the list. interquartile range = upper quartile – lower quartile Finding the interquartile range 100 The cumulative frequency graph can be used to locate the upper and lower quartiles and so find the interquartile range. 90 Cumulative frequency 80 70 The lower quartile is the time of the 25th person. 42 seconds 60 50 The upper quartile is the time of the 75th person. 51 seconds 40 30 20 10 0 30 35 40 45 50 55 Time in seconds 60 The interquartile range is the difference between these two values. 51 – 42 = 9 seconds A box-and-whisker diagram A box-and-whisker diagram, or boxplot, can be used to illustrate the spread of the data in a given distribution using the median, the lower quartile and the upper quartile. These values can be found from a cumulative frequency graph. 100 For example, for this cumulative frequency graph showing the results of 100 people holding their breath, Cumulative frequency 90 80 70 Minimum value = 30 60 50 Lower quartile = 42 40 30 Median = 47 20 Upper quartile = 51 10 0 30 35 40 45 50 55 60 Time in seconds Maximum value = 60 A box-and-whisker diagram The corresponding box-and-whisker diagram is as follows: Minimum value Median Lower quartile 30 42 Maximum value Upper quartile 47 51 60 Lap times James takes part in karting competitions and his Dad records his lap times on a spreadsheet. One of the karting tracks is at Shenington. In 2004, 378 of James’ lap times were recorded. The track is 1108 metres long. James’ fastest time in a race was 51.8 seconds. In which position in the list would the median lap time be? There are 378 lap times and so the median lap time will be the 378 + 1 th value ≈ 190th value 2 Lap times In which position in the list would the lower quartile be? There are 378 lap times and so the lower quartile will be the 378 + 1 th value ≈ 95th value 4 In which position in the list would the upper quartile be? There are 378 lap times and so the upper quartile will be the 378 + 1 th 3× value ≈ 284th value 4 Lap times at Shenington karting circuit James’ lap times are displayed in the following cumulative frequency graph. 400 Cumulative frequency 350 300 250 200 150 100 50 0 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 Lap times in seconds Box and whisker plot for James’ race times Minimum value Maximum value Lower quartile Median Upper quartile 52 54 53 58 What conclusions can you draw about James’ performance? 91