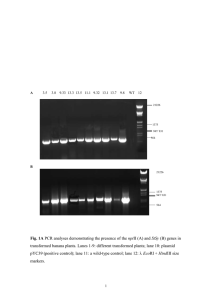
Peer-to-Peer in the Datacenter: Amazon Dynamo Aaron Blankstein COS 461: Computer Networks

Peer-to-Peer in the
Datacenter: Amazon Dynamo
Aaron Blankstein
COS 461: Computer Networks
Lectures: MW 10-10:50am in Architecture N101 http://www.cs.princeton.edu/courses/archive/spr13/cos461/
Last Lecture…
upload rate u s d
1 u
1
2 upload rates u i download rates d i
F bits d
4 u
4
Internet u
2 u
3 d
3 d
2
3
This Lecture…
4
Amazon’s “Big Data” Problem
• Too many (paying) users!
– Lots of data
• Performance matters
– Higher latency = lower “conversion rate”
• Scalability: retaining performance when large
Tiered Service Structure
Stateless
Stateless
Stateless
5
All of the
State
Figure 1: Service-oriented architecture of Amazon’s platform provide a response within 300ms for 99.9% of its requests for a peak client load of 500 requests per second.
In Amazon’s decentralized service oriented infrastructure, SLAs play an important role. For example a page request to one of the e-commerce sites typically requires the rendering engine to construct its response by sending requests to over 150 services.
These services often have multiple dependencies, which frequently are other services, and as such it is not uncommon for the call graph of an application to have more than one level. To ensure that the page rendering engine can maintain a clear bound on page delivery each service within the call chain must obey its performance contract.
Figure 1 shows an abstract view of the architecture of Amazon’s platform, where dynamic web content is generated by page rendering components which in turn query many other services. A service can use different data stores to manage its state and these data stores are only accessible within its service boundaries. Some services act as aggregators by using several other services to produce a composite response. Typically, the aggregator services are stateless, although they use extensive caching.
A common approach in the industry for forming a performance oriented SLA is to describe it using average, median and expected variance. At Amazon we have found that these metrics are not good enough if the goal is to build a system where all customers have a good experience, rather than just the majority. For example if extensive personalization techniques are used then customers with longer histories require more processing which impacts performance at the high-end of the distribution. An SLA stated in terms of mean or median response times will not address the performance of this important customer segment. To address this issue, at Amazon, SLAs are expressed and measured at the
99.9
th
percentile of the distribution. The choice for 99.9% over an even higher percentile has been made based on a cost-benefit analysis which demonstrated a significant increase in cost to improve performance that much. Experiences with Amazon’s production systems have shown that this approach provides a better overall experience compared to those systems that meet
SLAs defined based on the mean or median.
In this paper there are many references to this 99.9
th
percentile of distributions, which reflects Amazon engineers’ relentless focus on performance from the perspective of the customers’ experience. Many papers report on averages, so these are included where it makes sense for comparison purposes. Nevertheless,
Amazon’s engineering and optimization efforts are not focused on averages. Several techniques, such as the load balanced selection of write coordinators, are purely targeted at controlling performance at the 99.9
th
percentile.
Storage systems often play an important role in establishing a service’s SLA, especially if the business logic is relatively lightweight, as is the case for many Amazon services. State management then becomes the main component of a service’s
SLA. One of the main design considerations for Dynamo is to give services control over their system properties, such as durability and consistency, and to let services make their own tradeoffs between functionality, performance and costeffectiveness.
2.3 Design Considerations
Data replication algorithms used in commercial systems traditionally perform synchronous replica coordination in order to provide a strongly consistent data access interface. To achieve this level of consistency, these algorithms are forced to tradeoff the availability of the data under certain failure scenarios. For instance, rather than dealing with the uncertainty of the correctness of an answer, the data is made unavailable until it is absolutely certain that it is correct. From the very early replicated database works, it is well known that when dealing with the possibility of network failures, strong consistency and high data availability cannot be achieved simultaneously [2, 11]. As such systems and applications need to be aware which properties can be achieved under which conditions.
For systems prone to server and network failures, availability can be increased by using optimistic replication techniques, where changes are allowed to propagate to replicas in the background, and concurrent, disconnected work is tolerated. The challenge with this approach is that it can lead to conflicting changes which must be detected and resolved. This process of conflict resolution introduces two problems: when to resolve them and who resolves them. Dynamo is designed to be an eventually consistent data store; that is all updates reach all replicas eventually.
An important design consideration is to decide when to perform the process of resolving update conflicts, i.e., whether conflicts should be resolved during reads or writes. Many traditional data stores execute conflict resolution during writes and keep the read complexity simple [7]. In such systems, writes may be rejected if the data store cannot reach all (or a majority of) the replicas at a given time. On the other hand, Dynamo targets the design space of an “always writeable” data store (i.e., a data store that is highly available for writes). For a number of Amazon services, rejecting customer updates could result in a poor customer experience. For instance, the shopping cart service must allow customers to add and remove items from their shopping cart even amidst network and server failures. This requirement forces us to push the complexity of conflict resolution to the reads in order to ensure that writes are never rejected.
Horizontal or Vertical Scalability?
6
Vertical Scaling Horizontal Scaling
7
Horizontal Scaling Chaos
• Horizontal scaling is chaotic*
• Failure Rates:
– k = probability a machine fails in given period
– n = number of machines
– 1-(1-k) n = probability of any failure in given period
– For 50K machines, with online time of 99.99966%:
• 16% of the time, data center experiences failures
• For 100K machines, 30% of the time!
8
Dynamo Requirements
• High Availability
– Always respond quickly, even during failures
– Replication!
• Incremental Scalability
– Adding “nodes” should be seamless
• Comprehensible Conflict Resolution
– High availability in above sense implies conflicts
9
Dynamo Design
• Key-Value Store DHT over data nodes
– get(k) and put(k, v)
• Questions:
– Replication of Data
– Handling Requests in Replicated System
– Temporary and Permanent Failures
– Membership Changes
Data Partitioning and Data Replication
• Familiar?
• Nodes are virtual!
– Heterogeneity
• Replication:
– Coordinator Node
– N-1 successors also
– Nodes keep preference list
10
F
G
E
A
D
B
Key K
C
Nodes B, C and D store keys in range (A,B) including
K.
Figure 2: Partitioning and replication of keys in Dynamo ring.
Traditional replicated relational database systems focus on the problem of guaranteeing strong consistency to replicated data.
Although strong consistency provides the application writer a convenient programming model, these systems are limited in scalability and availability [7]. These systems are not capable of handling network partitions because they typically provide strong consistency guarantees.
3.3 Discussion
Dynamo differs from the aforementioned decentralized storage systems in terms of its target requirements. First, Dynamo is targeted mainly at applications that need an “always writeable” data store where no updates are rejected due to failures or concurrent writes. This is a crucial requirement for many Amazon applications. Second, as noted earlier, Dynamo is built for an infrastructure within a single administrative domain where all nodes are assumed to be trusted. Third, applications that use
Dynamo do not require support for hierarchical namespaces (a norm in many file systems) or complex relational schema
(supported by traditional databases). Fourth, Dynamo is built for latency sensitive applications that require at least 99.9% of read and write operations to be performed within a few hundred milliseconds. To meet these stringent latency requirements, it was imperative for us to avoid routing requests through multiple nodes
(which is the typical design adopted by several distributed hash table systems such as Chord and Pastry). This is because multihop routing increases variability in response times, thereby increasing the latency at higher percentiles. Dynamo can be characterized as a zero-hop DHT, where each node maintains enough routing information locally to route a request to the appropriate node directly.
4. SYSTEM ARCHI TECTURE
The architecture of a storage system that needs to operate in a production setting is complex. In addition to the actual data persistence component, the system needs to have scalable and robust solutions for load balancing, membership and failure detection, failure recovery, replica synchronization, overload handling, state transfer, concurrency and job scheduling, request marshalling, request routing, system monitoring and alarming, and configuration management. Describing the details of each of the solutions is not possible, so this paper focuses on the core distributed systems techniques used in Dynamo: partitioning, replication, versioning, membership, failure handling and scaling.
Table 1: Summary of techniques used in Dynamo and their advantages.
Problem
Partitioning
Technique
Consistent Hashing
Advantage
Incremental
Scalability
High Availability for writes
Handling temporary failures
Recovering from permanent failures
Membership and failure detection
Vector clocks with reconciliation during reads
Sloppy Quorum and hinted handoff
Anti-entropy using
Merkle trees
Gossip-based membership protocol and failure detection.
Version size is decoupled from update rates.
Provides high availability and durability guarantee when some of the replicas are not available.
Synchronizes divergent replicas in the background.
Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information.
Table 1 presents a summary of the list of techniques Dynamo uses and their respective advantages.
4.1 System I nterface
Dynamo stores objects associated with a key through a simple interface; it exposes two operations: get() and put(). The get( key ) operation locates the object replicas associated with the key in the storage system and returns a single object or a list of objects with conflicting versions along with a context . The put( key, context, object ) operation determines where the replicas of the object should be placed based on the associated key , and writes the replicas to disk. The context encodes system metadata about the object that is opaque to the caller and includes information such as the version of the object. The context information is stored along with the object so that the system can verify the validity of the context object supplied in the put request.
Dynamo treats both the key and the object supplied by the caller as an opaque array of bytes. It applies a MD5 hash on the key to generate a 128-bit identifier, which is used to determine the storage nodes that are responsible for serving the key.
4.2 Partitioning Algorithm
One of the key design requirements for Dynamo is that it must scale incrementally. This requires a mechanism to dynamically partition the data over the set of nodes (i.e., storage hosts) in the system. Dynamo’s partitioning scheme relies on consistent hashing to distribute the load across multiple storage hosts. In consistent hashing [10], the output range of a hash function is treated as a fixed circular space or “ring” (i.e. the largest hash value wraps around to the smallest hash value). Each node in the system is assigned a random value within this space which represents its “position” on the ring. Each data item identified by a key is assigned to a node by hashing the data item’s key to yield its position on the ring, and then walking the ring clockwise to find the first node with a position larger than the item’s position.
Handling Requests
• Requests handled by coordinator
– Consults replicas
• Forward request to N replicas from pref. list
– R or W responses form a quorum
F
G
A
B
Key K
C
Nodes B, C and D store keys in range (A,B)
• For load balancing/failures, any of the top N in the pref. list can handle request
E D including
K.
Figure 2: Partitioning and replication of keys in Dynamo ring.
11
Traditional replicated relational database systems focus on the problem of guaranteeing strong consistency to replicated data.
Although strong consistency provides the application writer a convenient programming model, these systems are limited in scalability and availability [7]. These systems are not capable of handling network partitions because they typically provide strong consistency guarantees.
3.3 Discussion
Dynamo differs from the aforementioned decentralized storage systems in terms of its target requirements. First, Dynamo is targeted mainly at applications that need an “always writeable” data store where no updates are rejected due to failures or concurrent writes. This is a crucial requirement for many Amazon applications. Second, as noted earlier, Dynamo is built for an infrastructure within a single administrative domain where all nodes are assumed to be trusted. Third, applications that use
Dynamo do not require support for hierarchical namespaces (a norm in many file systems) or complex relational schema
(supported by traditional databases). Fourth, Dynamo is built for latency sensitive applications that require at least 99.9% of read and write operations to be performed within a few hundred milliseconds. To meet these stringent latency requirements, it was imperative for us to avoid routing requests through multiple nodes
(which is the typical design adopted by several distributed hash table systems such as Chord and Pastry). This is because multihop routing increases variability in response times, thereby increasing the latency at higher percentiles. Dynamo can be characterized as a zero-hop DHT, where each node maintains enough routing information locally to route a request to the appropriate node directly.
4. SYSTEM ARCHI TECTURE
The architecture of a storage system that needs to operate in a production setting is complex. In addition to the actual data persistence component, the system needs to have scalable and robust solutions for load balancing, membership and failure detection, failure recovery, replica synchronization, overload handling, state transfer, concurrency and job scheduling, request marshalling, request routing, system monitoring and alarming, and configuration management. Describing the details of each of the solutions is not possible, so this paper focuses on the core distributed systems techniques used in Dynamo: partitioning, replication, versioning, membership, failure handling and scaling.
Table 1: Summary of techniques used in Dynamo and their advantages.
Problem
Partitioning
Technique
Consistent Hashing
Advantage
Incremental
Scalability
High Availability for writes
Handling temporary failures
Recovering from permanent failures
Membership and failure detection
Vector clocks with reconciliation during reads
Sloppy Quorum and hinted handoff
Anti-entropy using
Merkle trees
Gossip-based membership protocol and failure detection.
Version size is decoupled from update rates.
Provides high availability and durability guarantee when some of the replicas are not available.
Synchronizes divergent replicas in the background.
Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information.
Table 1 presents a summary of the list of techniques Dynamo uses and their respective advantages.
4.1 System I nterface
Dynamo stores objects associated with a key through a simple interface; it exposes two operations: get() and put(). The get( key ) operation locates the object replicas associated with the key in the storage system and returns a single object or a list of objects with conflicting versions along with a context . The put( key, context, object ) operation determines where the replicas of the object should be placed based on the associated key , and writes the replicas to disk. The context encodes system metadata about the object that is opaque to the caller and includes information such as the version of the object. The context information is stored along with the object so that the system can verify the validity of the context object supplied in the put request.
Dynamo treats both the key and the object supplied by the caller as an opaque array of bytes. It applies a MD5 hash on the key to generate a 128-bit identifier, which is used to determine the storage nodes that are responsible for serving the key.
4.2 Partitioning Algorithm
One of the key design requirements for Dynamo is that it must scale incrementally. This requires a mechanism to dynamically partition the data over the set of nodes (i.e., storage hosts) in the system. Dynamo’s partitioning scheme relies on consistent hashing to distribute the load across multiple storage hosts. In consistent hashing [10], the output range of a hash function is treated as a fixed circular space or “ring” (i.e. the largest hash value wraps around to the smallest hash value). Each node in the system is assigned a random value within this space which represents its “position” on the ring. Each data item identified by a key is assigned to a node by hashing the data item’s key to yield its position on the ring, and then walking the ring clockwise to find the first node with a position larger than the item’s position.
12
Detecting Failures
• Purely Local Decision
– Node A may decide independently that B has failed
– In response, requests go further in the pref. list
• A request hits an unsuspecting node
– “temporary failure” handling occur
Handling Temporary Failures
• E is in replica set
– Needs to receive the replica
– Hinted Handoff: replica contains
“original” node
• When C comes back
– E forwards the replica back to C ring.
F
13
G
E
A
D
B
Key K
Nodes B, C and D store keys in range (A,B) including
K.
Traditional replicated relational database systems focus on the problem of guaranteeing strong consistency to replicated data.
Although strong consistency provides the application writer a convenient programming model, these systems are limited in scalability and availability [7]. These systems are not capable of handling network partitions because they typically provide strong consistency guarantees.
3.3 Discussion
Dynamo differs from the aforementioned decentralized storage systems in terms of its target requirements. First, Dynamo is targeted mainly at applications that need an “always writeable” data store where no updates are rejected due to failures or concurrent writes. This is a crucial requirement for many Amazon applications. Second, as noted earlier, Dynamo is built for an infrastructure within a single administrative domain where all nodes are assumed to be trusted. Third, applications that use
Dynamo do not require support for hierarchical namespaces (a norm in many file systems) or complex relational schema
(supported by traditional databases). Fourth, Dynamo is built for latency sensitive applications that require at least 99.9% of read and write operations to be performed within a few hundred milliseconds. To meet these stringent latency requirements, it was imperative for us to avoid routing requests through multiple nodes
(which is the typical design adopted by several distributed hash table systems such as Chord and Pastry). This is because multihop routing increases variability in response times, thereby increasing the latency at higher percentiles. Dynamo can be characterized as a zero-hop DHT, where each node maintains enough routing information locally to route a request to the appropriate node directly.
4. SYSTEM ARCHI TECTURE
The architecture of a storage system that needs to operate in a production setting is complex. In addition to the actual data persistence component, the system needs to have scalable and robust solutions for load balancing, membership and failure detection, failure recovery, replica synchronization, overload handling, state transfer, concurrency and job scheduling, request marshalling, request routing, system monitoring and alarming, and configuration management. Describing the details of each of the solutions is not possible, so this paper focuses on the core distributed systems techniques used in Dynamo: partitioning, replication, versioning, membership, failure handling and scaling.
Table 1: Summary of techniques used in Dynamo and their advantages.
Problem
Partitioning
High Availability for writes
Handling temporary failures
Recovering from permanent failures
Membership and failure detection
Technique
Consistent Hashing
Vector clocks with reconciliation during reads
Sloppy Quorum and hinted handoff
Anti-entropy using
Merkle trees
Gossip-based membership protocol and failure detection.
Advantage
Incremental
Scalability
Version size is decoupled from update rates.
Provides high availability and durability guarantee when some of the replicas are not available.
Synchronizes divergent replicas in the background.
Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information.
Table 1 presents a summary of the list of techniques Dynamo uses and their respective advantages.
4.1 System I nterface
Dynamo stores objects associated with a key through a simple interface; it exposes two operations: get() and put(). The get( key ) operation locates the object replicas associated with the key in the storage system and returns a single object or a list of objects with conflicting versions along with a context . The put( key, context, object ) operation determines where the replicas of the object should be placed based on the associated key , and writes the replicas to disk. The context encodes system metadata about the object that is opaque to the caller and includes information such as the version of the object. The context information is stored along with the object so that the system can verify the validity of the context object supplied in the put request.
Dynamo treats both the key and the object supplied by the caller as an opaque array of bytes. It applies a MD5 hash on the key to generate a 128-bit identifier, which is used to determine the storage nodes that are responsible for serving the key.
4.2 Partitioning Algorithm
One of the key design requirements for Dynamo is that it must scale incrementally. This requires a mechanism to dynamically partition the data over the set of nodes (i.e., storage hosts) in the system. Dynamo’s partitioning scheme relies on consistent hashing to distribute the load across multiple storage hosts. In consistent hashing [10], the output range of a hash function is treated as a fixed circular space or “ring” (i.e. the largest hash value wraps around to the smallest hash value). Each node in the system is assigned a random value within this space which represents its “position” on the ring. Each data item identified by a key is assigned to a node by hashing the data item’s key to yield its position on the ring, and then walking the ring clockwise to find the first node with a position larger than the item’s position.
Managing Membership
• Peers randomly tell another their known membership history – “gossiping”
• Also called epidemic algorithm
– Knowledge spreads like a disease through system
– Great for ad hoc systems, selfconfiguration, etc.
– Does this make sense in Amazon’s environment?
14
15
Gossip could partition the ring
• Possible Logical Partitions
– A and B choose to join ring at about the same time: unaware of one another, may take long time to converge to one another
• Solution:
– Use seed nodes to reconcile membership views: well-known peers which are contacted more frequently
16
Why is Dynamo Different?
• So far, looks a lot like normal p2p
• Amazon wants to use this for application data!
• Lots of potential synchronization problems
• Dynamo uses versioning to provide eventual consistency.
Consistency Problems
• Shopping Cart Example:
– Object is a history of “adds” and “removes”
– All adds are important (trying to make money)
Client: Expected Data at Server:
Put(k, [+1 Banana])
Z = get(k)
Put(k, Z + [+1 Banana])
Z = get(k)
Put(k, Z + [-1 Banana])
17
[+1 Banana]
[+1 Banana, +1 Banana]
[+1 Banana, +1 Banana,
-1 Banana]
Client:
What if a failure occurs?
Data on Dynamo:
Put(k, [+1 Banana])
Z = get(k)
Put(k, Z + [+1 Banana])
Z = get(k)
Put(k, Z + [-1 Banana])
[+1 Banana]
A Crashes at A
B not in first Put’s quorum
[+1 Banana] at B
[+1 Banana, -1 Banana] at B
Node A Comes Online
At this point, Node A and B disagree about the current state of the object – how is that resolved?
Can we even tell that there is a conflict?
18
19
“Time” is largely a human construct
• What about time-stamping objects?
– We could authoritatively say whether an object is newer or older…
– all events are not necessarily witnessed
• If our system’s notion of time corresponds to
“real-time”…
– A new object always blasts away older versions, even though those versions may have important updates
(as in bananas example).
• Requires a new notion of time (causal in nature)
• Anyhow, real-time is impossible in any case
20
Causality
• Objects are causally related if the value of one object depends on (or witnessed) the previous
• Conflicts can be detected when replicas contain causally independent objects for a given key.
• Can we have a notion of time which captures causality?
21
Versioning
• Key Idea: every PUT includes a version, indicating the most recently witnessed version of the object being updated
• Problem: replicas may have diverged
– No single authoritative version number (or “clock” number)
– Notion of time must use a partial ordering of events
22
Vector Clocks
• Every replica has its own logical clock
– Incremented before it sends a message
• Every message attached with vector version
– Includes originator’s clock
– Highest seen logical clocks for each replica
• If M
1 is causally dependent on M
– Replica sending M
1
0
: will have seen M
0
– Replica will have seen clocks ≥ all clocks in M
0
Vector Clocks in Dynamo
• Vector clock per object
• Gets() return vector clock of object
• Puts() contain most recent vector clock
– Coordinator treated as
“originator”
• Serious conflicts are resolved by the application
/ client
Figure 3: Version evolution of an object over time.
23
Dynamo has access to multiple branches that cannot be syntactically reconciled, it will return all the objects at the leaves, with the corresponding version information in the context. An update using this context is considered to have reconciled the divergent versions and the branches are collapsed into a single new version.
To illustrate the use of vector clocks, let us consider the example shown in Figure 3. A client writes a new object. The node (say
Sx) that handles the write for this key increases its sequence number and uses it to create the data's vector clock. The system now has the object D1 and its associated clock [(Sx, 1)]. The client updates the object. Assume the same node handles this request as well. The system now also has object D2 and its associated clock [(Sx, 2)]. D2 descends from D1 and therefore over-writes D1, however there may be replicas of D1 lingering at nodes that have not yet seen D2. Let us assume that the same client updates the object again and a different server (say Sy) handles the request. The system now has data D3 and its associated clock [(Sx, 2), (Sy, 1)].
Next assume a different client reads D2 and then tries to update it, and another node (say Sz) does the write. The system now has D4
(descendant of D2) whose version clock is [(Sx, 2), (Sz, 1)]. A node that is aware of D1 or D2 could determine, upon receiving
D4 and its clock, that D1 and D2 are overwritten by the new data and can be garbage collected. A node that is aware of D3 and receives D4 will find that there is no causal relation between them. In other words, there are changes in D3 and D4 that are not reflected in each other. Both versions of the data must be kept and presented to a client (upon a read) for semantic reconciliation.
Now assume some client reads both D3 and D4 (the context will reflect that both values were found by the read). The read's context is a summary of the clocks of D3 and D4, namely [(Sx, 2),
(Sy, 1), (Sz, 1)]. If the client performs the reconciliation and node
Sx coordinates the write, Sx will update its sequence number in the clock. The new data D5 will have the following clock: [(Sx,
3), (Sy, 1), (Sz, 1)].
A possible issue with vector clocks is that the size of vector clocks may grow if many servers coordinate the writes to an object. In practice, this is not likely because the writes are usually handled by one of the top N nodes in the preference list. In case of network partitions or multiple server failures, write requests may be handled by nodes that are not in the top N nodes in the preference list causing the size of vector clock to grow. In these scenarios, it is desirable to limit the size of vector clock. To this end, Dynamo employs the following clock truncation scheme:
Along with each (node, counter) pair, Dynamo stores a timestamp that indicates the last time the node updated the data item. When the number of (node, counter) pairs in the vector clock reaches a threshold (say 10), the oldest pair is removed from the clock.
Clearly, this truncation scheme can lead to inefficiencies in reconciliation as the descendant relationships cannot be derived accurately. However, this problem has not surfaced in production and therefore this issue has not been thoroughly investigated.
4.5 Execution of get () and put () operations
Any storage node in Dynamo is eligible to receive client get and put operations for any key. In this section, for sake of simplicity, we describe how these operations are performed in a failure-free environment and in the subsequent section we describe how read and write operations are executed during failures.
Both get and put operations are invoked using Amazon’s infrastructure-specific request processing framework over HTTP.
There are two strategies that a client can use to select a node: (1) route its request through a generic load balancer that will select a node based on load information, or (2) use a partition-aware client library that routes requests directly to the appropriate coordinator nodes. The advantage of the first approach is that the client does not have to link any code specific to Dynamo in its application, whereas the second strategy can achieve lower latency because it skips a potential forwarding step.
A node handling a read or write operation is known as the coordinator . Typically, this is the first among the top N nodes in the preference list. If the requests are received through a load balancer, requests to access a key may be routed to any random node in the ring. In this scenario, the node that receives the request will not coordinate it if the node is not in the top N of the requested key’s preference list. Instead, that node will forward the request to the first among the top N nodes in the preference list.
Read and write operations involve the first N healthy nodes in the preference list, skipping over those that are down or inaccessible.
When all nodes are healthy, the top N nodes in a key’s preference list are accessed. When there are node failures or network partitions, nodes that are lower ranked in the preference list are accessed.
To maintain consistency among its replicas, Dynamo uses a consistency protocol similar to those used in quorum systems.
This protocol has two key configurable values: R and W. R is the minimum number of nodes that must participate in a successful read operation. W is the minimum number of nodes that must participate in a successful write operation. Setting R and W such that R + W > N yields a quorum-like system. In this model, the latency of a get (or put) operation is dictated by the slowest of the
R (or W) replicas. For this reason, R and W are usually configured to be less than N, to provide better latency.
Upon receiving a put() request for a key, the coordinator generates the vector clock for the new version and writes the new version locally. The coordinator then sends the new version (along with
24
Vector Clocks in Banana Example
Client: Data on Dynamo:
Put(k, [+1 Banana])
Z = get(k)
Put(k, Z + [+1 Banana])
Z = get(k)
Put(k, Z + [-1 Banana])
[+1]
A Crashes v=[(A,1)] at A
B not in first Put’s quorum
[+1] v=[(B,1)] at B
[+1,-1] v=[(B,2)] at B
Node A Comes Online
[(A,1)] and [(B,2)] are a conflict!
25
Eventual Consistency
• Versioning, by itself, does not guarantee consistency
– If you don’t require a majority quorum, you need to periodically check that peers aren’t in conflict
– How often do you check that events are not in conflict?
• In Dynamo
– Nodes consult with one another using a tree hashing
(Merkel tree) scheme
– Allows them to quickly identify whether they hold different versions of particular objects and enter conflict resolution mode
26
NoSQL
• Notice that Eventual Consistency, Partial
Ordering do not give you ACID!
• Rise of NoSQL (outside of academia)
– Memcache
– Cassandra
– Redis
– Big Table
– Neo4J
– MongoDB