ISE 390 Introduction Chapter 1 Spring 2005
advertisement

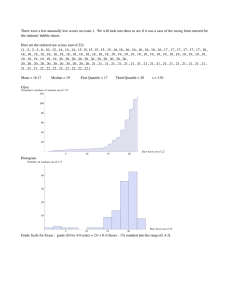
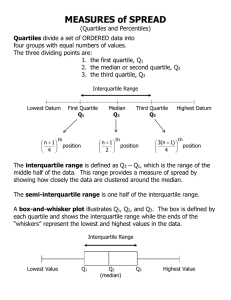
ISE 390 Chapter 1 Introduction Spring 2005 Probability and Statistics for Modern Engineering , Second Edition, Lawrence L. Lapin Class Objectives • Develop an understanding of the terms used in the study of Statistics. • Understand the difference in populations and samples. • Demonstrate capability to collect, organize, present, analyze, and interpret numerical data. • Understand Statistical Measures used to describe populations and samples including: Location Variability • Central Tendency • Range • Mean • Variance • Median • Standard Deviation • Mode • Coefficient of Variation • Position • Percentiles, Fractiles, and Quartiles Definitions • Statistic (Singular) – A data point (Boeing closed at $45.00.) • Statistics (Plural) – The Dow was down 25 points today. (Aggregate of 30 stock prices) • Statistics (Discipline) - The collection, organization, presenting, analyzing, and interpreting of numerical data for the purpose of providing information with which to reach a decision or communicate information in the face of uncertainty. • Statistical Population – The collection of ALL possible members of a specific group of interest. • Sample – A subset of the statistical population used to represent the population from which information is inferred regarding the population. • Quantitative Population – Observations are numerical values. • Qualitative Population – Observations are attributes described in terms of color, shape, sex, etc. Types of Quantitative Data • Ratio Data – Operations of addition, subtraction, multiplication, and division are applicable, Examples include time or physical data such as minutes, height, weight, etc. • Interval Data – Only addition or subtraction is applicable. Temperature scales are examples. • Ordinal Data – No arithmetic operations apply. Some relative value is associated with the scale. This includes scales such as hurricane or tornado ratings or the Beaufort wind scale. • Nominal Data – Numbers that represent arbitrary code. No relative meaning. Codes for offices or colors are examples. Analysis of Data Sample Times to Inspect Test Devices for Calibration Frequency Distribution Number of Inspections 30 20 10 0 10 15 Histogram 20 Frequency Polygon Frequency Curve Stem and Leaf Plot Frequency 2 16 29 27 11 6 4 2 2 1 100 Stem 11 12 13 14 15 16 17 18 19 20 Leaf (Decimal) 7 3 8 9 6 7 6 7 0 1 0 5 5 2 7 3 8 0 6 2 5 7 9 1 8 8 7 9 0 0 3 9 5 0 1 1 3 6 4 3 0 9 3 2 7 5 0 3 2 2 3 5 6 9 9 6 5 7 8 0 9 8 9 0 0 1 2 1 6 7 0 2 3 0 1 9 8 2 3 2 2 7 8 6 2 0 3 4 7 7 7 2 2 2 2 0 2 7 3 4 Advantage Over Other Displays of Data: No data is lost. Relative and Cumulative Frequency Distributions Music preferences in 200 young adults 14 to 19 Rap Alternative Rock and Roll Country Classical 100 50 26 20 4 The pie chart quickly tells you that • the majority of students like rap best (50%), and • the remaining students prefer alternative (25%), rock and roll (13%), country (10%) and classical (2%). Tip! When drawing a pie chart, ensure that the segments are ordered by size (largest to smallest) and in a clockwise direction. Source (or "Adapted from", if appropriate): Statistics Canada's Internet Site, full URL of source pages, and date of extraction. Statistics Canada information is used with the permission of Statistics Canada. Users are forbidden to copy the data and redisseminate them, in an original or modified form, for commercial purposes, without the expressed permission of Statistics Canada. Information on the availability of the wide range of data from Statistics Canada can be obtained from Statistics Canada's Regional Offices, its World Wide Web site at http://www.statcan.ca, and its toll-free access number 1-800-263-1136. Ogive for Cumulative Frequency Distribution Normal Probability Distributions x Probability Density Function a b Cumulative Probability Density Function SPSS Scatter Diagram for Concrete Strength vs. Pulse Velocity Scatter Diagram Scatter Diagrams Statistical Measures Population descriptors are called Parameters Sample descriptors are called Sample Statistics Location Variability • Central Tendency • Range • Mean • Variance • Median • Standard Deviation • Mode • Coefficient of Variation • Position • Percentiles, Fractiles, and Quartiles Central Tendency – Mean Population Mean N = number of members in population N m x i i 1 Sample Mean Approximated from Grouped Data N Sample Mean - X n = number of members in sample n X m (lower case Greek letter Mu) x i 1 n i Central Tendency – Median and Mode Median – That value above and below which an equal number of observations lie. Denoted by m 584 633 693 663 755 In the case where there is an even number of samples or observations, the Median is the average of the middle two samples. 584 633 640 680 693 755 The Median is (680 + 640)/2 = 660. Mode – The most frequently occurring value 0 0 3 7 1 0 2 10 27 15 0 is the Mode 0 0 1 2 Where the data is taken from a continuum, the Mode is taken to be the midpoint of the class interval with the highest frequency. Frequency Distribution Forms and Summary Measures Positional Comparisons of the Three Measures of Central Tendency for Symmetrical and Skewed distributions Bimodal Frequency Distributions Using Stem and Leaf Plot to Find Median and Mode Frequency 2 16 29 27 11 6 4 2 2 1 100 Stem 11 12 13 14 15 16 17 18 19 20 Leaf (Decimal) 3 7 0 2 3 5 6 0 0 0 0 0 0 0 2 2 2 0 2 2 3 4 0 1 7 8 8 0 0 3 9 5 9 0 1 1 6 0 2 5 9 7 0 2 5 7 1 2 6 8 1 2 6 8 1 2 7 8 9 9 9 9 9 1 2 2 2 2 2 3 3 3 3 5 6 6 7 7 7 8 9 9 3 3 3 3 4 4 5 5 6 6 7 7 7 7 7 8 8 7 Median – The median will be between the 50th and 51st observation. Adding 2 + 16 + 29 = 47, we know that the Median will be on the stem for 14. Counting in on the 14 stem, we find that the 50th and 51st observations are both 14.2. The Median is (14.2 + 14.2)/2 = 14.2. Mode – Look for the fraction that occurs most frequently on one stem. In this data, that is the 2 in the 14 stem. The Mode is 14.2. Finding Percentiles from Ungrouped Data 1. Sort the data in ascending order. 2. Establish the decimal allowable range. 1 n 1 d n n 1 10 9 d 10 10 .1 < d < .9 (d = decimal equivalent of desired percentile; n = sample size) 3. Find the relative position of the desired percentile. ( n + 1) d (10 + 1) .1 Let k be the largest integer such that: k < ( n + 1) d 1 < (1.11) k = 1 The desired percentile will lie between Xk and Xk + 1 or X1 and X2 4. Compute the percentile value. Qd = Xk + [( n + 1) d - k](Xk + 1 – Xk) = 5.3 + [(10 + 1) .1 – 1] (5.4 – 5.3) Q.1 = 5.3 + [(11).1 – 1](.1) = 5.3 + (.1)(.1) = 5.31 k < (11) .25 = 2.75 k = 2 Q.25 = 5.4 + [(11).25 – 2](5.7 - 5.4) = 5.4 + (0.75)(.3) = 5.4 + .225 = 5.63 k < (11) .5 = 5.5 k = 5 Q..50 = 6.10 + [(11).5 – 5](6.1 – 6.1) = 6.10 + (0.5)(0) = 6.10 + 0 = 6.10 k < (11) .75 =8. 25 k = 8 Q.75 = 6.4 + [(11).75 – 8](6.5 - 6.4) = 6.4 + (0. 25)(.1) = 6.4 + .025 = 6.43 1 2 3 4 5 6 7 8 9 10 5.3 5.4 5.7 6.0 6.1 6.1 6.2 6.4 6.5 6.6 Percentiles, Fractiles, and Quartiles Percentile – The point below which the stated percentage lies. Example: 17 of 20 observations fall below 23. What percentile is 23? 17/20 = .85. 23 is the 85th percentile. Fractile - The point below which the stated fraction lies. Example: 17 of 20 observations fall below 23. What fractile is 23? 17/20 = .85. 23 is the .85-fractile. Quartile – Divides data into four groups of equal frequency First Quartile – Same as the 25th percentile (.25-fractile) Second Quartile - Same as the 50th percentile (.50-fractile) and also the Median. Third Quartile - Same as the 75th percentile (.75-fractile) Finding Percentiles from Ungrouped Data Frequency 2 16 29 27 11 6 4 2 2 1 100 Stem 11 12 13 14 15 16 17 18 19 20 Leaf (Decimal) 3 7 0 2 3 5 6 0 0 0 0 0 0 0 2 2 2 0 2 2 3 4 0 1 7 8 8 0 0 3 9 5 9 0 1 1 6 0 2 5 9 7 0 2 5 7 1 2 6 8 1 2 6 8 1 2 7 8 9 9 9 9 9 1 2 2 2 2 2 3 3 3 3 5 6 6 7 7 7 8 9 9 3 3 3 3 4 4 5 5 6 6 7 7 7 7 7 8 8 7 First Quartile (100 + 1) .25 = 25.25 Q.25 = 13.0 + (25.25 – 25.0)(13.1 – 13.0) = 13.025 Second Quartile (100 + 1) .5 = 50.5 Q.5 = 14.2 + (50.5 – 50.0)(14.2 – 14.2) = 14.2 Third Quartile (100 + 1) .75 = 75.75 Q.75 = 15.0 + (75.75 – 75.0)(15.2 – 15.0) = 15.15 Fourth Quartile Finding Percentiles Graphically 14.2 Q.50 Finding Percentiles from Grouped Data (Raw data unavailable, but grouped into frequency distribution) Qd = Xk + [( n + 1) d - k] ( Xk + 1 – Xk h-k ) (73 + 1)(.25) = 18.5 The greatest cumulative frequency not exceeding 18.5 is 7 for the first interval , so k = 7. Q.25 will fall in the second interval, and its cumulative frequency is 30. 105.0 – 100.0 Q.25 = 100.0 + [( 18.5 - 7] = 102.5 30 - 7 ( ) Variability* *The term “Dispersion” is also used. Variability – Interquartile Range (Difference in the third quartile, Q.75 and the first quartile, Q.25) Boxplot Range Interquartile Range Interquartile Range = 6.43 – 5.63 = 0.80 From Slide 16; Q.25 = 5.63, Q.50 = 6.10, Q.75 = 6.43 1 2 3 4 5 6 7 8 9 10 5.3 5.4 5.7 6.0 6.1 6.1 6.2 6.4 6.5 6.6 Variance and Standard Deviation (Measures deviation of individual observations around the mean.) Variance Standard Deviation N Population – Lower case Greek letter Sigma 2 (x m 2 i i 1 N (x X 2 n Sample s2 i i 1 Approximated from Grouped Data s2 s 2 s s2 n 1 n Calculation by Hand 2 x 2 nX 2 s s2 i 1 f n 1 k x nX 2 k n 1 2 s s2 The sum of the deviations of the samples about the sample mean = 0. Composite Summary Measures Kurtosis – Measures the “peakedness”of a distribution Coefficient of Variation v Population – m s Sample - v X Coefficient of Skewness – Provides direction and degree of skewness of frequency distribution ( 3 Xm SK s A. Which has the greatest Coefficient of Variation? B. Mesokurtic – Meso means intermediate. C. Leptokurtic – Lepto means slender. D. Platykurtic – Platy means flat. m = Median SK > 0, Positively Skewed SK < 0, Negatively Skewed SK = 0, No Skew Proportion Population Proportion Number of Observatio ns in Category Population Size Sample Proportion P Number of Observatio ns in Category Sample Size