Models of Learning Hebbian ~ coincidence Recruitment ~ one trial
advertisement

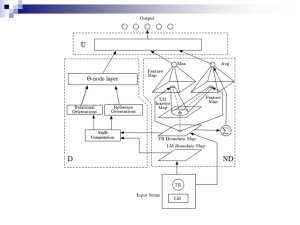
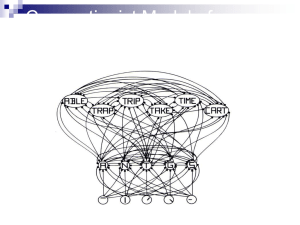
Models of Learning Hebbian ~ coincidence Recruitment ~ one trial Supervised ~ correction (backprop) Reinforcement ~ delayed reward Unsupervised ~ similarity Hebb’s Rule The key idea underlying theories of neural learning go back to the Canadian psychologist Donald Hebb and is called Hebb’s rule. From an information processing perspective, the goal of the system is to increase the strength of the neural connections that are effective. Hebb (1949) “When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased” From: The organization of behavior. Hebb’s rule Each time that a particular synaptic connection is active, see if the receiving cell also becomes active. If so, the connection contributed to the success (firing) of the receiving cell and should be strengthened. If the receiving cell was not active in this time period, our synapse did not contribute to the success the trend and should be weakened. LTP and Hebb’s Rule Hebb’s Rule: neurons that fire together wire together strengthen weaken Long Term Potentiation (LTP) is the biological basis of Hebb’s Rule Calcium channels are the key mechanism Chemical realization of Hebb’s rule It turns out that there are elegant chemical processes that realize Hebbian learning at two distinct time scales Early Long Term Potentiation (LTP) Late LTP These provide the temporal and structural bridge from short term electrical activity, through intermediate memory, to long term structural changes. Calcium Channels Facilitate Learning In addition to the synaptic channels responsible for neural signaling, there are also Calciumbased channels that facilitate learning. As Hebb suggested, when a receiving neuron fires, chemical changes take place at each synapse that was active shortly before the event. Long Term Potentiation (LTP) These changes make each of the winning synapses more potent for an intermediate period, lasting from hours to days (LTP). In addition, repetition of a pattern of successful firing triggers additional chemical changes that lead, in time, to an increase in the number of receptor channels associated with successful synapses - the requisite structural change for long term memory. There are also related processes for weakening synapses and also for strengthening pairs of synapses that are active at about the same time. The Hebb rule is found with long term potentiation (LTP) in the hippocampus Schafer collateral pathway Pyramidal cells 1 sec. stimuli At 100 hz During normal low-frequency trans-mission, glutamate interacts with NMDA and nonNMDA (AMPA) and metabotropic receptors. With highfrequency stimulation, Calcium comes in Enhanced Transmitter Release AMPA Early and late LTP (Kandel, ER, JH Schwartz and TM Jessell (2000) Principles of Neural Science. New York: McGraw-Hill.) A. Experimental setup for demonstrating LTP in the hippocampus. The Schaffer collateral pathway is stimulated to cause a response in pyramidal cells of CA1. B. Comparison of EPSP size in early and late LTP with the early phase evoked by a single train and the late phase by 4 trains of pulses. Computational Models based on Hebb’s rule The activity-dependent tuning of the developing nervous system, as well as post-natal learning and development, do well by following Hebb’s rule. Explicit Memory in mammals appears to involve LTP in the Hippocampus. Many computational systems for modeling incorporate versions of Hebb’s rule. Winner-Take-All: Recruitment Learning Units compete to learn, or update their weights. The processing element with the largest output is declared the winner Lateral inhibition of its competitors. Learning Triangle Nodes LTP in Episodic Memory Formation WTA: Stimulus ‘at’ is presented 1 a 2 t o Competition starts at category level 1 a 2 t o Competition resolves 1 a 2 t o Hebbian learning takes place 1 a 2 t o Category node 2 now represents ‘at’ Presenting ‘to’ leads to activation of category node 1 1 a 2 t o Presenting ‘to’ leads to activation of category node 1 1 a 2 t o Presenting ‘to’ leads to activation of category node 1 1 a 2 t o Presenting ‘to’ leads to activation of category node 1 1 a 2 t o Category 1 is established through Hebbian learning as well 1 a 2 t o Category node 1 now represents ‘to’ Hebb’s rule is not sufficient What happens if the neural circuit fires perfectly, but the result is very bad for the animal, like eating something sickening? A pure invocation of Hebb’s rule would strengthen all participating connections, which can’t be good. On the other hand, it isn’t right to weaken all the active connections involved; much of the activity was just recognizing the situation – we would like to change only those connections that led to the wrong decision. No one knows how to specify a learning rule that will change exactly the offending connections when an error occurs. Computer systems, and presumably nature as well, rely upon statistical learning rules that tend to make the right changes over time. More in later lectures. Hebb’s rule is insufficient tastebud tastes rotten eats food gets sick drinks water should you “punish” all the connections? Models of Learning Hebbian ~ coincidence Recruitment ~ one trial Supervised ~ correction (backprop) Reinforcement ~ delayed reward Unsupervised ~ similarity Recruiting connections Given that LTP involves synaptic strength changes and Hebb’s rule involves coincident-activation based strengthening of connections How can connections between two nodes be recruited using Hebbs’s rule? The Idea of Recruitment LearningK Y X N B F = B/N Pno link (1 F ) BK Suppose we want to link up node X to node Y The idea is to pick the two nodes in the middle to link them up Can we be sure that we can find a path to get from X to Y? the point is, with a fan-out of 1000, if we allow 2 intermediate layers, we can almost always find a path X Y X Y Finding a Connection P = (1-F) **B**K P = Probability of NO link between X and Y N = Number of units in a “layer” B = Number of randomly outgoing units per unit F = B/N , the branching factor K = Number of Intermediate layers, 2 in the example K= N= 106 107 108 0 .999 .9999 .99999 1 .367 .905 .989 2 10-440 10-44 10-5 # Paths = (1-P k-1)*(N/F) = (1-P k-1)*B Finding a Connection in Random Networks For Networks with N nodes and N branching factor, there is a high probability of finding good links. (Valiant 1995) Recruiting a Connection in Random Networks Informal Algorithm 1. Activate the two nodes to be linked 2. Have nodes with double activation strengthen their active synapses (Hebb) 3. There is evidence for a “now print” signal based on LTP (episodic memory) Triangle nodes and feature structures A B C A B C Representing concepts using triangle nodes Recruiting triangle nodes Let’s say we are trying to remember a green circle currently weak connections between concepts (dotted lines) has-color blue has-shape green round oval Strengthen these connections and you end up with this picture has-color has-shape Green circle blue green round oval Has-color Green Has-shape Round Has-color GREEN Has-shape ROUND Back Propagation Jerome Feldman CS182/CogSci110/Ling109 Spring 2007 Types of Activation functions Linearly separable patterns Linearly Separable Patterns An architecture for a Perceptron which can solve this type of decision boundary problem. An "on" response in the output node represents one class, and an "off" response represents the other. Multi-layer Feed-forward Network Boolean XOR XOR o 0.5 input x1 input x2 output 0 0 1 1 0 1 0 1 0 1 1 0 1 1 OR AND 0.5 h1 h1 1.5 1 1 1 1 x1 x1 Pattern Separation and NN architecture Supervised Learning - Backprop How do we train the weights of the network Basic Concepts Use a continuous, differentiable activation function (Sigmoid) Use the idea of gradient descent on the error surface Extend to multiple layers Backpropagation Algorithm “activations” “errors” Backprop To learn on data which is not linearly separable: Build multiple layer networks (hidden layer) Use a sigmoid squashing function instead of a step function. Tasks Unconstrained pattern classification Credit assessment Digit Classification Function approximation Learning control Stock prediction Sigmoid Squashing Function output y 1 1 e net n net wiyi i 0 w0 y0=1 w1 y1 w2 y2 wn ... input yn The Sigmoid Function y=a x=neti Nice Property of Sigmoids Gradient Descent Gradient Descent on an error Learning Rule – Gradient Descent on an Root Mean Square (RMS) Learn wi’s that minimize squared error 1 2 E[ w] (tk o k ) 2kO O = output layer Gradient Descent E[ w] Gradient: Training rule: E E E E[ w] , ,..., w w w 1 n 0 w E[w] E wi wi 1 2 ( t o ) k k 2kO Backpropagation Algorithm Generalization to multiple layers and multiple output units An informal account of BackProp For each pattern in the training set: Compute the error at the output nodes Compute w for each wt in 2nd layer Compute delta (generalized error expression) for hidden units Compute w for each wt in 1st layer After amassing w for all weights and, change each wt a little bit, as determined by the learning rate wij ipo jp Backprop Details Here we go… Also refer to web notes for derivation The output layer wjk k wij j yi ti: target i E = Error = ½ ∑i (ti – yi)2 The derivative of the sigmoid is just learning rate E Wij E Wij Wij Wij Wij E E yi xi ti yi f ' ( xi ) y j Wij yi xi Wij yi 1 yi Wij ti yi yi 1 yi y j Wij y j i i ti yi yi 1 yi The hidden layer wjk wij yi ti: target W jk E W jk E E y j x j W jk y j x j W jk k j i E = Error = ½ ∑i (ti – yi)2 E E yi xi (ti yi ) f ' ( xi ) Wij y j i yi xi y j i E (ti yi ) f ' ( xi ) Wij f ' ( x j ) yk W jk i W jk (ti yi ) yi 1 yi Wij y j 1 y j yk i W jk yk j j (ti yi ) yi 1 yi Wij y j 1 y j i j Wij i y j 1 y j i Let’s just do an example 0 i 1 0 i 2 b=1 w01 0.8 w02 0.6 w0b 1/(1+e^-0.5) 0.5 x0 f y0 0.6224 i1 i2 y0 0 0 0 0 1 1 1 0 1 1 1 1 E = Error = ½ ∑i (ti – yi)2 E = ½ (t0 – y0)2 0.5 0.4268 E = ½ (0 – 0.6224)2 = 0.1937 Wij y j i i ti yi yi 1 yi W01 y1 0 i1 0 0 0 t0 y0 y0 1 y0 0 W02 y2 0 i2 0 W0b yb 0 b 0 0.1463 learning rate 0 0 0.6224 0.62241 0.6224 0 0.1463 suppose = 0.5 W0b 0.5 0.1463 0.0731 Momentum term The speed of learning is governed by the learning rate. If the rate is low, convergence is slow If the rate is too high, error oscillates without reaching minimum. w ( n) w ( n 1) i ( n)y j ( n) ij ij 0 1 Momentum tends to smooth small weight error fluctuations. the momentum accelerates the descent in steady downhill directions. the momentum has a stabilizing effect in directions that oscillate in time. Convergence May get stuck in local minima Weights may diverge …but works well in practice Representation power: 2 layer networks : any continuous function 3 layer networks : any function Local Minimum USE A RANDOM COMPONENT SIMULATED ANNEALING Overfitting and generalization TOO MANY HIDDEN NODES TENDS TO OVERFIT Overfitting in ANNs Early Stopping (Important!!!) Stop training when error goes up on validation set Stopping criteria Sensible stopping criteria: total mean squared error change: Back-prop is considered to have converged when the absolute rate of change in the average squared error per epoch is sufficiently small (in the range [0.01, 0.1]). generalization based criterion: After each epoch the NN is tested for generalization. If the generalization performance is adequate then stop. If this stopping criterion is used then the part of the training set used for testing the network generalization will not be used for updating the weights. Architectural Considerations What is the right size network for a given job? How many hidden units? Too many: no generalization Too few: no solution Possible answer: Constructive algorithm, e.g. Cascade Correlation (Fahlman, & Lebiere 1990) etc Network Topology The number of layers and of neurons depend on the specific task. In practice this issue is solved by trial and error. Two types of adaptive algorithms can be used: start from a large network and successively remove some nodes and links until network performance degrades. begin with a small network and introduce new neurons until performance is satisfactory. Supervised vs Unsupervised Learning •Backprop requires a 'target' •how realistic is that? •Hebbian learning is unsupervised, but limited in power •How can we combine the power of backprop (and friends) with the ideal of unsupervised learning? Autoassociative Networks •Network trained to reproduce the input at the output layer copy of input as target •Non-trivial if number of hidden units is smaller than inputs/outputs •Forced to develop compressed representations of the patterns •Hidden unit representations may reveal natural kinds (e.g. Vowels vs Consonants) •Problem of explicit teacher is circumvented input Problems and Networks •Some problems have natural "good" solutions •Solving a problem may be possible by providing the right armory of general-purpose tools, and recruiting them as needed •Networks are general purpose tools. •Choice of network type, training, architecture, etc greatly influences the chances of successfully solving a problem •Tension: Tailoring tools for a specific job Vs Exploiting general purpose learning mechanism Summary Multiple layer feed-forward networks Replace Step with Sigmoid (differentiable) function Learn weights by gradient descent on error function Backpropagation algorithm for learning Avoid overfitting by early stopping ALVINN drives 70mph on highways Use MLP Neural Networks when … (vectored) Real inputs, (vectored) real outputs You’re not interested in understanding how it works Long training times acceptable Short execution (prediction) times required Robust to noise in the dataset Applications of FFNN Classification, pattern recognition: FFNN can be applied to tackle non-linearly separable learning problems. Recognizing printed or handwritten characters, Face recognition Classification of loan applications into credit-worthy and non-credit-worthy groups Analysis of sonar radar to determine the nature of the source of a signal Regression and forecasting: FFNN can be applied to learn non-linear functions (regression) and in particular functions whose inputs is a sequence of measurements over time (time series). Extensions of Backprop Nets Recurrent Architectures Backprop through time Elman Nets & Jordan Nets Output 1 Output 1 Hidden Context Input α Hidden Context Input Updating the context as we receive input • In Jordan nets we model “forgetting” as well • The recurrent connections have fixed weights • You can train these networks using good ol’ backprop Recurrent Backprop w2 a w4 b w1 c w3 unrolling 3 iterations a b c a b c a b c w1 a w2 w3 b w4 c • we’ll pretend to step through the network one iteration at a time • backprop as usual, but average equivalent weights (e.g. all 3 highlighted edges on the right are equivalent)