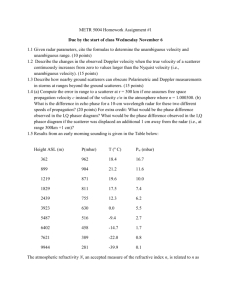
JOINTLY ESTIMATING 3D TARGET SHAPE AND MOTION FROM RADAR DATA
advertisement

JOINTLY ESTIMATING 3D TARGET SHAPE AND MOTION FROM RADAR DATA By Heather Palmeri A Thesis Submitted to the Graduate Faculty of Rensselaer Polytechnic Institute in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY Major Subject: MATHEMATICS Approved by the Examining Committee: Margaret Cheney, Thesis Adviser Joseph Mayhan, Member William Siegmann, Member David Isaacson, Member Rensselaer Polytechnic Institute Troy, New York November 2012 (For Graduation December 2012) c Copyright 2012 by Heather Palmeri All Rights Reserved ii CONTENTS LIST OF TABLES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vi LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vii ACKNOWLEDGMENT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xi ABSTRACT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiii 1. Introduction and Historical Review . . . . . . . . . . . . . . . . . . . . . . 1 1.1 Inverse Problems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 Radar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.3 Synthetic Aperture Radar (SAR) . . . . . . . . . . . . . . . . . . . . 2 1.3.1 . . . . . . . . . . . . . . . 2 1.4 Inverse Synthetic Aperture Radar (ISAR) . . . . . . . . . . . . . . . 3 1.5 Interferometric Synthetic Aperture Radar (IFSAR) . . . . . . . . . . 3 1.6 Scatterer Correlation . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 1.7 Scatterer Correlation Techniques for Image Processing . . . . . . . . 4 1.8 3D Image Processing Techniques for Target Characterization . . . . . 5 2. Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 Stripmap SAR and Spotlight SAR 2.1 Electromagnetic Wave Propagation . . . . . . . . . . . . . . . . . . . 8 2.2 Scatterers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 2.3 Radar Observables Background . . . . . . . . . . . . . . . . . . . . . 11 2.3.1 Obtaining Raw Data . . . . . . . . . . . . . . . . . . . . . . . 11 2.3.2 Sequential Block Processing . . . . . . . . . . . . . . . . . . . 13 2.4 Sample Target . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 2.5 Assumptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 2.6 Scatterer Correlation . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 2.7 The Shape and Motion Estimation Problem . . . . . . . . . . . . . . 22 2.8 Euler’s Dynamical Equations of Torque-Free Motion . . . . . . . . . . 23 2.8.1 2.9 Special Case: Turntable Geometry . . . . . . . . . . . . . . . 25 Simulating Truth Radar Data . . . . . . . . . . . . . . . . . . . . . . 26 2.10 Resolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 iii 2.11 Matrix Decompositions . . . . . . . . . . . . . . . . . . . . . . . . . . 27 2.11.1 The Singular Value Decomposition (SVD) . . . . . . . . . . . 27 2.11.2 The Reduced QR Factorization . . . . . . . . . . . . . . . . . 28 2.12 Basic Problem Formulation . . . . . . . . . . . . . . . . . . . . . . . 29 3. Phase-Enhanced 3D Snapshot Imaging Algorithm . . . . . . . . . . . . . . 31 3.1 2D Snapshot Imaging Equations . . . . . . . . . . . . . . . . . . . . . 32 3.2 3D Snapshot Imaging Equations . . . . . . . . . . . . . . . . . . . . . 32 3.3 Phase Equation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 3.3.1 Derivation from Snapshot Equations . . . . . . . . . . . . . . 33 3.3.2 Derivation From Range-Doppler Data Block . . . . . . . . . . 35 3.4 Phase-Enhanced 3D Snapshot Imaging Equations . . . . . . . . . . . 37 3.5 Augmenting Additional Roll Cuts . . . . . . . . . . . . . . . . . . . . 39 3.6 Phase-Enhanced 3D Snapshot Imaging Considerations . . . . . . . . . 40 3.6.1 Change in Roll . . . . . . . . . . . . . . . . . . . . . . . . . . 40 3.6.2 Coordinate System . . . . . . . . . . . . . . . . . . . . . . . . 41 3.6.3 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . 42 3.6.4 Resolving Phase Ambiguities . . . . . . . . . . . . . . . . . . . 43 3.7 Summing Target Space Images . . . . . . . . . . . . . . . . . . . . . . 45 3.8 Sector Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46 4. SVD Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 4.1 Derivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 4.2 Methodology Summary . . . . . . . . . . . . . . . . . . . . . . . . . . 56 4.3 Geometric Interpretation . . . . . . . . . . . . . . . . . . . . . . . . . 57 5. Phase-Enhanced SVD Method . . . . . . . . . . . . . . . . . . . . . . . . . 58 5.1 Scaling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 5.2 Sample Motion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 5.3 Imperfect Correlation . . . . . . . . . . . . . . . . . . . . . . . . . . . 62 5.4 5.3.1 Simulating Imperfect Correlation . . . . . . . . . . . . . . . . 62 5.3.2 Effect of Imperfect Correlation . . . . . . . . . . . . . . . . . . 65 Added Noise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68 5.4.1 Simulating Added Noise . . . . . . . . . . . . . . . . . . . . . 68 5.4.1.1 The Percentage Method. . . . . . . . . . . . . . . . . 68 iv 5.4.1.2 5.4.2 The Extraneous Points Method. . . . . . . . . . . . . 70 Effect of Added Noise . . . . . . . . . . . . . . . . . . . . . . 72 5.4.2.1 The Percentage Method. . . . . . . . . . . . . . . . . 72 5.4.2.2 The Extraneous Points Method. . . . . . . . . . . . . 73 6. Correlation Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 6.1 6.2 6.3 6.4 Iterative Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 6.1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 6.1.2 Large Number of Scatterers Without Noise . . . . . . . . . . . 77 6.1.3 Large Number of Scatterers With Noise . . . . . . . . . . . . . 85 6.1.4 Large Number of Scatterers With Phase Ambiguities Without Noise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88 6.1.5 Large Number of Scatterers With Phase Ambiguities, Noise, and Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . 91 Nearest Neighbor and Slope Algorithm . . . . . . . . . . . . . . . . . 94 6.2.1 Small Number of Scatterers Without Noise . . . . . . . . . . . 94 6.2.2 Small Number of Scatterers With Noise and Phase Ambiguities 97 Proof of Theorem Justifying Iterative Algorithm . . . . . . . . . . . . 106 6.3.1 Case Two Scatterers Switch . . . . . . . . . . . . . . . . . . . 109 6.3.2 Case More than Two Scatterers Switch . . . . . . . . . . . . . 124 6.3.3 Case Scatterers Switch at Multiple Aspects . . . . . . . . . . . 133 Comparison of Algorithms . . . . . . . . . . . . . . . . . . . . . . . . 135 7. Discussion and Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . 138 7.1 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138 7.2 Main Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140 7.3 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140 LITERATURE CITED . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142 v LIST OF TABLES 4.1 SVD Method Variables and Their Dimensions . . . . . . . . . . . . . . 56 5.1 3D Imaging Method Differences . . . . . . . . . . . . . . . . . . . . . . 58 vi LIST OF FIGURES 1.1 2D and 3D Target Shape and Motion Estimation Techniques Overview . 7 2.1 Transmitted and Received Pulses . . . . . . . . . . . . . . . . . . . . . 9 2.2 Coordinate System Diagram . . . . . . . . . . . . . . . . . . . . . . . . 11 2.3 Turntable Geometry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 2.4 RTI Plot for Simulated Data . . . . . . . . . . . . . . . . . . . . . . . . 14 2.5 Fixed Aspect Data Block . . . . . . . . . . . . . . . . . . . . . . . . . . 15 2.6 Extracted Ranges and Range-Rates . . . . . . . . . . . . . . . . . . . . 16 2.7 Sinusoidal Nature of Range and Range-Rate . . . . . . . . . . . . . . . 16 2.8 Sample RV Target Geometry . . . . . . . . . . . . . . . . . . . . . . . . 17 2.9 Simulated Sample RV Target Points . . . . . . . . . . . . . . . . . . . . 17 2.10 Scatterer Correlation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 2.11 Examples of Uncorrelated and Correlated Data Matrices . . . . . . . . . 21 2.12 Relationship Between Motion, Shape, and Radar Observables . . . . . . 22 2.13 Target Centered Coordinate System . . . . . . . . . . . . . . . . . . . . 24 2.14 Phase-Enhanced 3D Snapshot Imaging method . . . . . . . . . . . . . . 29 2.15 SVD Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.16 Phase-Enhanced SVD Method . . . . . . . . . . . . . . . . . . . . . . . 30 3.1 Localized Orthogonal Coordinate System for 3D Phase-Enhanced Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 3.2 Measurement Collection Method . . . . . . . . . . . . . . . . . . . . . . 40 3.3 Apparent Motion of Target Between Two Roll Cuts . . . . . . . . . . . 41 3.4 a) Reconstructed Positions, b) ±2π Phase Ambiguities c) Target Space Filtered Image . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 3.5 Phase Resolved Target Points, Three 2D Views . . . . . . . . . . . . . . 44 3.6 Target Space Reconstruction, 3D & Three 2D Views . . . . . . . . . . . 45 vii 3.7 Sector Processing, Pink Areas Correspond to Data Used . . . . . . . . . 47 3.8 Comparison: Sector Processing for Various Amounts of Data . . . . . . 48 3.9 Target Space Reconstruction Using Sector Processing . . . . . . . . . . 48 5.1 Shape and Motion Solutions . . . . . . . . . . . . . . . . . . . . . . . . 61 5.2 Varying Levels of Scatterer Correlation . . . . . . . . . . . . . . . . . . 62 5.3 Uncorrelated Extracted Radar Observables, p = 80 . . . . . . . . . . . 63 5.4 Uncorrelated Extracted Radar Observables . . . . . . . . . . . . . . . . 63 5.5 Uncorrelated Truth Radar Observables with Random Jumps . . . . . . 64 5.6 Shape and Motion Estimates for Varying Correlation Percentage Levels 5.7 Singular Value Distributions for Varying Correlation Percentage Levels . 66 5.8 Shape and Motion Estimates for Varying Correlation With Jumps . . . 67 5.9 Singular Value Distributions for Correlation With Varying Numbers of Jumps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 5.10 Truth Radar Observables with p = 15 . . . . . . . . . . . . . . . . . . . 69 5.11 Truth Radar Observables with Extraneous Points . . . . . . . . . . . . 71 5.12 Shape and Motion Estimates for Varying Percentage Levels of White Noise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72 5.13 Singular Value Distributions for Varying Noise Percentages . . . . . . . 73 5.14 Shape and Motion Estimates for Varying Levels of Extraneous Point Noise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 5.15 Singular Value Distributions for Varying Percentages of Extraneous Points 75 6.1 13 Scatterer Data Uncorrelated with Jumps . . . . . . . . . . . . . . . . 77 6.2 2 and 3 Jump Cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81 6.3 Matrix C of All Possible Correlations . . . . . . . . . . . . . . . . . . . 82 6.4 Singular Value Distributions from 13 Scatterer Data . . . . . . . . . . . 83 6.5 13 Scatterer Data Uncorrelated with Jumps then Correlated with Iterative Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84 6.6 13 Scatterer Data Uncorrelated with Jumps and Extraneous Points . . . 85 viii 65 6.7 Singular Value Distributions, Noisy Data . . . . . . . . . . . . . . . . . 86 6.8 Data Uncorrelated with Jumps and Noise then Correlated with Iterative Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87 6.9 Uncorrelated Data With Phase Ambiguities . . . . . . . . . . . . . . . . 88 6.10 Delta Phase after Phase Constraint . . . . . . . . . . . . . . . . . . . . 89 6.11 Singular Value Distributions from 13 Scatterer Data With Phase Ambiguities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90 6.12 Delta Phase after Iterative Algorithm Using Phase Constraint 6.13 Uncorrelated Data With Phase Ambiguities and Noise . . . . . . . . . . 91 6.14 Delta Phase With Noise after Phase Constraint . . . . . . . . . . . . . . 91 6.15 Singular Value Distributions from 13 Scatterer Data With Phase Ambiguities and Noise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92 6.16 Delta Phase with Noise after Iterative Algorithm Using Phase Constraint and Filtering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93 6.17 Radar Observables Correlated with Iterative Algorithm . . . . . . . . . 93 6.18 Uncorrelated Range Data . . . . . . . . . . . . . . . . . . . . . . . . . . 95 6.19 Range Data After Step 1 . . . . . . . . . . . . . . . . . . . . . . . . . . 96 6.20 Range Data After Step 2 . . . . . . . . . . . . . . . . . . . . . . . . . . 96 6.21 Uncorrelated Range Data with Extraneous Points . . . . . . . . . . . . 97 6.22 Range Data After Step 1 . . . . . . . . . . . . . . . . . . . . . . . . . . 98 6.23 Identifying an Intersection . . . . . . . . . . . . . . . . . . . . . . . . . 99 6.24 Analyzing an Intersection . . . . . . . . . . . . . . . . . . . . . . . . . . 100 6.25 Range Data After Step 3 . . . . . . . . . . . . . . . . . . . . . . . . . . 102 6.26 Range Data After Step 4 . . . . . . . . . . . . . . . . . . . . . . . . . . 103 6.27 Delta Phase Data Before Step 5 . . . . . . . . . . . . . . . . . . . . . . 104 6.28 Delta Phase Data After Step 5 . . . . . . . . . . . . . . . . . . . . . . . 104 6.29 Track Displaced Due to Phase Ambiguity . . . . . . . . . . . . . . . . . 105 6.30 Radar Observables Correlated Through Algorithm . . . . . . . . . . . . 105 ix . . . . . 90 6.31 Singular Value Distribution for 4 Scatterer Target . . . . . . . . . . . . 136 6.32 Singular Value Distribution for 5 Scatterer Target . . . . . . . . . . . . 137 x ACKNOWLEDGMENT First and foremost, I’d like to thank my advisor, Dr. Margaret Cheney, for all her help, and for getting me interested in the field of radar to begin with. Along those lines, I’d like to thank the RPI School of Science Accelerated B.S./Ph.D. Program. It was through this program that I was encouraged to start research during my sophomore year of college. I have Dr. Cheney and the program to thank for me being given the opportunity to dive in to research and summer internships in my field much earlier than many students are often able to. I’d like to thank Dr. William Siegmann, for recognizing my potential and accepting me in to this program to begin with. Dr. Cheney was wonderful in encouraging me to participate in summer internships and conferences. I’d like to thank Kevin Magde, my supervisor from my first summer internship at the Air Force Research Laboratory in Rome, NY. This was my first hands-on experience with radar, and was a great learning experience for someone starting out in the field. As a mathematics major, I often was asked ”What do you DO with math, teach?” and wasn’t quite sure how to answer that question. My first internship is what first gave me a real answer to that question. I was able to take radar measurements using a static range radar chamber at their facility and use mathematics to get information about targets out of this data. This was my first real-world experience in mathematics and inspired me to continue in the field. I’d like to thank the people I’ve worked with at MIT Lincoln Laboratory. I was able to spend three summer internships and two winter breaks working there. From where I started in group 34, I’d like to thank my supervisor, Allen Dors, and other members of the group, including Doug Koltenuk and Tim Bond. I’d also like to thank my officemates and fellow interns in the group, Andy O’Donnell and Kendra Kumley, for helping to make my experience at the lab an enjoyable one. I switched over to group 36 at MITLL in order to work with Dr. Joseph Mayhan on a project I thought would be interesting, which ended up leading in to my thesis topic. I’d like to thank Joe first of all for agreeing to take me on as an xi intern, then for his help and support throughout the rest of my internships, and then agreeing to be the external member of my doctoral committee. I’d like to thank Keh-Ping Dunn for his support and help in the group as well, and for taking time out of his busy schedule to meet with me and Joe often. Various other members in the group were very helpful in explaining concepts to me, including Noah Kubow, Shirin Kubat, and my officemates Elena Rossi and Su-May Hsu. My fellow interns in this group, specifically Jess Stigile and Adam Attarian, were great as well. As a graduate student at RPI, I was lucky enough to be a member of a great research group of students also working with Dr. Cheney. Through working with them, we formed some great friendships. A shout out is due to the original radar girls - Kaitlyn Voccola, Analee Miranda, and Tegan Webster. We were later joined by Tom Zugibe and Scott Altrichter, who weren’t exactly radar GIRLS, but we let that slide. Our radar group was lucky enough to join forces with some of the other students in RPI’s Inverse Problems Center (IPRPI) in sharing an office, so a shout out is due to them as well - Ashley Baer, Jessica Jones, and Joe Rosenthal. You guys are awesome! I’d like to thank my boyfriend, Ricky Grebe, for being there for me during pretty much my entire time in college. From the get-go with my research, he’s been supportive and even willing to listen to and critique my presentations. I’d like to thank my family for their love and support during my time in college. Even though I only moved about twenty-five minutes away from home to go to college, I was often still pretty unavailable since I was so busy with my schoolwork. They were always very understanding and supportive. My parents were always ready to help me move from apartment to apartment (eight moves in total during college) and didn’t get TOO annoyed with me for always leaving various assortments of furniture, boxes, and other belongings around the house when I couldn’t take them with me. Lastly, I’d like to thank my doctoral committee as a whole; Dr. Margaret Cheney, Dr. William Siegmann, Dr. David Isaacson, and Dr. Joseph Mayhan. They have always been very helpful and encouraging. I’ve been so lucky to have the support of all those listed above in my time as a student at RPI. Thanks to all of you. xii ABSTRACT A novel hybrid 3D radar imaging technique is presented that jointly estimates both target shape and motion using range, range-rate, and phase. This work expands on research done by the author as an intern at MIT Lincoln Laboratory. It builds on and combines the work of two papers: Phase-Enhanced 3D Snapshot ISAR Imaging and Interferometric SAR (Joseph Mayhan) and Shape and Motion Reconstruction from 3D-to-1D Orthographically Projected Data via Object-Image Relations (Matthew Ferrara). The second paper is a modification to work first presented in Derivation and Estimation of Euclidean Invariants of Far Field Range Data (Mark Stuff). The phase-enhanced 3D snapshot imaging algorithm solves for shape using known motion and uncorrelated range, range-rate, and phase data. The second method uses an SVD to jointly solve for shape and motion using correlated range data. Key features from each of these methods are incorporated in to the novel hybrid phase-enhanced 3D SVD method. Two algorithms are presented that eliminate the need for scatterer correlation so that the hybrid method can be used on uncorrelated radar data. One algorithm, applicable to targets with a small number of scatterers, methodically determines the optimal correlation for a set of data using continuity and slope conditions. This algorithm can be used in the presence of noise and phase ambiguities. The other algorithm, applicable to targets with a large number of scatterers, iterates on an optimally chosen set of possible correlations and chooses the “best” one based on a condition on the resulting singular values. This algorithm can also be used in the presence of noise and phase ambiguities. A mathematical proof is presented to show that a matrix of radar observables data is uncorrelated if and only if it has more than three nonzero singular values. This proof justifies the use of the iterative algorithm. xiii CHAPTER 1 Introduction and Historical Review 1.1 Inverse Problems Radar imaging a subset of a broader category of problems known as inverse problems. A forward problem can loosely be thought of as finding the solution to an equation. An inverse problem can be thought of as the “inverse” to this problem, i.e., given a solution, find the equation it resulted from. This process is in general not unique, as multiple equations can often yield the same solution [1]. Many problems in mathematics and science fall in to this category. Some examples are geophysics, medical imaging, and ocean acoustics. In general, these problems involve collecting data and using it to determine something about the source the data came from. 1.2 Radar The application of radar investigated here is the identification of flying objects. This is important in many areas. For example, the Federal Aviation Administration (FAA) uses radar for airport surveillance and air traffic control. Radar is of critical importance in missile defense applications. It isn’t enough to just know a target is there; oftentimes radar must be used to discriminate between actual missiles, decoys, and debris, all in real time. This is not a simple problem. There are many advantages to using radar over other imaging modalities. For one, radars can be used day or night, since they have their own form of illumination. They can image through scenes obscured by clouds and rain, since radio waves are only slightly attenuated by these conditions [2]. The term ‘radar’ is actually an acronym. It stands for ‘RAdio Detection And Ranging’, and dates back to 1940. In general, radar works by transmitting radio waves that travel to a target and reflect back. They are transmitted in a sequence of pulses at regularly spaced intervals in time. From the resulting time-delayed received pulses, certain properties of the target can be determined, such as range, 1 2 altitude, size, material properties, and more [3] [2]. A radar system includes a transmitter, a receiver, an antenna (with a pointing or steering mechanism), and a signal processing and display unit. Oftentimes the transmitter and receiver are at the same location, or “colocated”. The most easily determined property is the range of the target, since it is simply a scaled version of the time delay between the transmission of a pulse and its return after reflection off an object [2]. 1.3 Synthetic Aperture Radar (SAR) Synthetic Aperture Radar (SAR) was developed in 1951 by Carl Wiley of the Goodyear Aircraft Corporation. SAR systems involve a moving antenna and a stationary target. These systems are desirable because they form high-resolution images, and have been used to image terrain, including other planets and their moons. The movement of the antenna allows the synthetic aperture of the system to be greater than its actual aperture, which is how higher resolution is achieved. There are two main varieties of SAR, spotlight SAR and stripmap SAR [3] [2]. 1.3.1 Stripmap SAR and Spotlight SAR In stripmap SAR, the antenna is in a fixed position on the radar platform. This results in the radar viewing a strip of terrain parallel to the path of motion. In spotlight SAR, as the radar platform moves, the radar stares at one specific location. In this way, the same target is viewed from a different direction at each point in the flight path [2]. There are three main differences between stripmap SAR and spotlight SAR. • Spotlight SAR yields finer azimuth resolution than stripmap, using the same physical antenna. • Spotlight SAR allows a scene to be imaged at multiple viewing angles during a single pass. • Spotlight SAR efficiently images multiple smaller scenes, while stripmap SAR is more useful for a long strip of terrain. [2] 3 1.4 Inverse Synthetic Aperture Radar (ISAR) Inverse Synthetic Aperture Radar (ISAR) systems involve a stationary antenna and a moving target. The movement of the target, instead of the movement of the antenna, is then what creates the synthetic aperture for high-resolution imaging. Both SAR and ISAR use the similar underlying theory, since both involve the same relative motion between the radar and the target [4]. ISAR processing is very useful for identifying and classifying targets. The resulting images reveal the dominant scattering centers on the target. They are displayed in range-Doppler, or range and cross-range, coordinates. Range is the axis parallel to the direction of propagation from the radar toward the target, also known as slant range, and cross-range is the direction perpendicular to range [4]. Oftentimes, the radar observables range and range-rate are used for image processing. Range-rate is a scaled version of Doppler. It is interesting to note the similarity between ISAR and spotlight SAR. By focusing on one specific target from many aspects in spotlight SAR, a geometry very similar to ISAR results. 1.5 Interferometric Synthetic Aperture Radar (IFSAR) A SAR image inherently contains more information than an optical image. An optical image shows the amplitude of reflected light at each location. A SAR image shows the amplitude of reflected radio waves at each location, but additionally stores phase information at each location. Like optical images, SAR images are twodimensional. Oftentimes it is desirable to obtain a three-dimensional image in order to gain more information about the target [4]. Interferometric Synthetic Aperture Radar (IFSAR) compares images of a scene from different elevations and compares phase to extract information about the third dimension and hence form a three-dimensional image. This was first demonstrated by Graham in 1974. This method is widely used to make elevation maps of terrain. It can be done using two different setups; an airborne radar platform carrying a two-radar system, or a single antenna radar platform making repeat passes over the same area [4]. 4 1.6 Scatterer Correlation Scatterer correlation, or signal isolation, is the process of separating the signals that arise from each of the geometrically distinct locations, or scatterers, on the target. If a set of data is organized such that information from separate scatterers is distinguishable, we call it correlated. Otherwise, it is uncorrelated. Some imaging schemes require that the radar observables data be correlated, and some do not. In general, actual radar data will always be uncorrelated. For a more detailed explanation of scatterer correlation, see Section 2.6. 1.7 Scatterer Correlation Techniques for Image Processing The process of scatterer correlation is complicated. We discuss the history of various methods. • Prominent Point Methods: In the 1980s, W. Carrara, S. Werness, and others were able to successfully isolate a few of the strongest signals from localized regions of targets. This was done using interactive image editing tools and required an enormous amount of persistence to execute [2]. • Fully Automated Approach: In the 1990s, a fully automated approach to scatterer correlation was developed. The method assigned a likelihood ratio score to points in the range data and an optimization algorithm was then used to estimate the correlation. These estimates were then iteratively updated using least squares fits to a linearized model. This method worked well in all cases except when scatterers’ range tracks intersected [5]. • Three-Dimensional Dynamic Signal Analysis: In 1999, Mark Stuff published an approach that improves on the fully automated approach. The method exploits the fact that if scatterers intersect in range, they cannot simultaneously intersect in velocity, the derivative of range. The method uses a three-dimensional complex time-range-velocity (CTRV) distribution that “separates” the data so that no scatterers’ paths intersect in three-dimensional space. A dynamic programming algorithm is then used to extract the correctly correlated signals [5]. 5 1.8 3D Image Processing Techniques for Target Characterization Most conventional radar imaging schemes are two-dimensional. This is because radar data is generally taken in two dimensions, so much more work must be done to gain a third dimension. We review some of the general methods currently used to construct 3D images from wideband radar data: • Backprojection: At each aspect angle, backproject the data to all possible target locations that are the correct distance from the radar, where the distance is calculated using the recorded time delay. Coherently summing all contributions results in an image with the target appearing at the correct location. This is a commonly used method [3]. • Microlocal Analysis: The key idea is that singularities in the data lead to singularities in the resulting image. Microlocal analysis uses the concept of a wavefront set to help describe singularities and decipher which target characteristics they resulted from. This is a relatively new and unexplored area [6]. • 3D Snapshot Imaging: Extract radar observables (range, range-rate, amplitude, phase) for each observation, use known motion to solve general [Motion]x[Target]=[Radar Observables] equation for target scatterer locations. This method can solve for 2D target shape at one roll angle given one snapshot, or 3D target shape at one roll angle given two or more snapshots and scatterer correlation [7]. • Phase-Enhanced 3D Snapshot Imaging: This method is very similar to 3D snapshot imaging, but uses data from two snapshots taken at different roll angles. The phase difference between the snapshots is used as a third independent variable in order to solve for 3D target shape, given a priori motion information, without the need for scatterer correlation. This is a new method that is not yet widely used [8]. 6 • SVD of Correlated Observation Data: After performing centroid removal (essentially normalizing all target ranges), perform an SVD of the correlated range data matrix. This requires making the rigid-body assumption, that is, the assumption that nothing on the target itself is moving. After some manipulation, the matrices resulting from the SVD can be used to arrive at both shape and motion estimates. This method is not yet widely used. This was done using both range and range-rate by Tomasi and Kanade in 1991 [9]. It was done separately for only range by Stuff for his PhD thesis in 2002 [10]. Stuff’s method was modified by Ferrara in 2009 [11]. Of these methods, the two focused on here are the Phase-Enhanced 3D Snapshot Imaging Method and the SVD Method. It is important to notice some of the key differences between them. The SVD method requires scatterer correlation and solves for both shape and motion, while the phase-enhanced 3D snapshot imaging method does not require scatterer correlation, but solves for only shape. An overview of how these methods are related is shown in Figure 1.1. We next give much more detail on these methods, then explore their relation to each other and how they can be combined. 7 Figure 1.1: 2D and 3D Target Shape and Motion Estimation Techniques Overview CHAPTER 2 Background 2.1 Electromagnetic Wave Propagation We begin with Maxwell’s equations in the time domain. ∇·D=ρ (2.1) ∇·B=0 (2.2) ∇×E =− ∂B ∂t ∇×H=J+ (2.3) ∂D ∂t (2.4) Here D is the electric displacement field, B is the magnetic induction field, E is the electric field, H is the magnetic intensity or magnetic field, J is the current density, and ρ is the charge density. Radar waves are electromagnetic waves and can be assumed to propagate in free space. The following relations and simplifications can be made in free space. B = µ0 H D = 0 E ρ=0 J=0 By using the above relations, taking the curl of (2.3), and plugging the result in to (2.4), we arrive at ∇ × ∇ × E = −µ0 0 ∂ 2E . ∂t2 Then since ∇ × (∇ × E) = ∇(∇ · E) − ∇2 E and (2.1) in free space becomes ∇ · E = 0, we arrive at ∇2 E = µ0 0 8 ∂ 2E . ∂t2 9 So in free space, Maxwell’s equations reduce to the scalar wave equation for each component of the electric field vector E [3]. In a radar system, a pulse is transmitted at time t = 0. The pulse travels to the target, bounces off of it, then returns to the radar at time t = τ . The quantity τ is known as the time delay. An illustration of this is given in Figure 2.1. Figure 2.1: Transmitted and Received Pulses Assume that the target is a distance R from the transmitter. Then by time t = τ , the pulse has traveled a distance 2R. The pulse is estimated to travel at the speed of light, c, so the time delay τ can be calculated by τ = 2R/c. Here we assume the radar is stationary relative to the target, but in general, either the radar or the target can be moving, so we let R = R(s) to show this distance can change. If the transmitted signal is assumed to be a delta function, the received signal can be thought of as a time-delayed delta function. The equation of the received signal is then given by E(t, s) = Dδ(t − 2R(s)/c), where D measures the signal’s amplitude, and we have plugged in for the time delay τ . Notice that the received signal is given in two different time scales. The time variable t is on the order of the speed of light, describing the fast transmission of electromagnetic waves. This is known as fast time. The time variable s describes the relatively slow movement between the radar and target. This is known as slow time. Fourier transforming the received signal from time to frequency gives 10 Z E(ω, s) = Dδ(t − 2R(s)/c)e−iωt dω, which, using a well-known property of the delta function, simplifies to E(ω, s) = Dei2ωR(s)/c . (2.5) As can be seen, the received signal takes the form of a complex exponential in the frequency domain. 2.2 Scatterers A scatterer (or point scatterer or scattering center) is a distinct point on a target, such as a corner of a fin or the tip of a cone. A commonly used way to model targets to be imaged is the point scatterer model. Targets are modeled as a collection of discrete point scatterers. There are two main types of scatterers; fixed scatterers and slipping scatterers. Fixed scatterers are distinct points on the target that stay at fixed locations. As a radar views the target from different aspects, fixed scatterers appear to move since their distance from the radar is changing. On the other hand, slipping scatterers always appear to be at the same distance to the radar. A common example of a slipping scatterer is a sphere. When a sphere is viewed by a radar, the point on the sphere closest to the radar gives the biggest return. This is true no matter what aspect the sphere is viewed at. This scatterer located closest to the radar is known as a slipping scatterer. Its distance to the radar appears to remain constant, while its location on the target “slips”. Another example of a slipping scatterer a groove on a cone-shaped target. Slipping scatters are extremely difficult to image, and most imaging schemes that even attempt to take them in to account impose a filter on the data before processing to get rid of them. Due to this, the only scatterers considered here will be fixed scatterers. 11 2.3 2.3.1 Radar Observables Background Obtaining Raw Data We begin with a target centered coordinate system. The origin of the co- ordinate system is located at the center of gravity of the target. The unit look vector from the origin to the radar is denoted by k̂(s). The radar views the target at L different aspects. At the mth aspect, we have k̂(s) = k̂m . There are N distinct three-dimensional scatterers on the target, and the nth scatterer is denoted by rn = (xn , yn , zn ). The distance from the radar to each scatterer is given by R, where R is the sum of an overall range offset R0 and a normalized range Rmn such that k̂m · rn = Rmn . Figure 2.2: Coordinate System Diagram A typical way to collect radar data is in turntable geometry, as depicted in Figure 2.3. The target is located at a fixed origin and the radar moves in a counterclockwise fashion around the target. At each aspect, the radar sends and receives a sequence of electromagnetic pulses at increasing frequencies. A radar taking data at increasing but distinct frequencies, such as this, is often referred to as a stepped frequency system. The time it takes the radar to move around the target, stopping at each aspect, is on a different time scale than the time it takes for the radar to send and receive pulses at each aspect. These differing time scales are the same as the ones introduced in Section 2.1. The motion of the radar around the target is often described as slow 12 time, while fast time refers to the time taken to send and receive pulses. This results in radar data being taken in two variables, frequency and slow time. Figure 2.3: Turntable Geometry Another common way to think of ”turntable” geometry is to imagine that the target is mounted on a turntable in front of a stationary radar. Data taken in static ranges is often taken in this geometry, so it is also referred to as static range geometry. As mentioned in Section 2.1 (and is easily deduced from Figure 2.2), the radar receives the time-delayed pulse at time t = 2R(s)/c. Since the received signal includes a return from each discrete scatterer, the received signal is given by summing 2.5 over each scatterer, E(ω, s) = X Dn ei2ωRn (s)/c . n This expression gives the scattered field data E(ω, s) in frequency and slow time. Plugging in R(s) = k̂(s) · r gives E(ω, s) = X Dn ei2ωk̂(s)·rn /c , (2.6) n where the nth scatterer has complex amplitude Dn and is located at position rn on the target. Since aspect is a function of slow time, k̂(s) = k̂m denotes the radar line-of- 13 sight unit vector at the mth aspect. The frequency ω is given by ω = 2πc , λ where λ is the wavelength corresponding to frequency ω. Then the scattered field data can also be expressed as E(λ, m) = X 4π Dn ei λ k̂m rn . (2.7) n This expression gives the scattered field data E(λ, m) in wavelength and aspect. This is consistent with the Geometric Theory of Diffraction (GTD) applicable to high frequency regions. It is important to note that the target motion associated with this data is necessarily two-dimensional. This data is taken with the target at a fixed “roll” angle. A change in roll occurs when the target is rotated in the y − z plane. 2.3.2 Sequential Block Processing An image of the raw data E(ω, s) does not visually convey useful information. In order to extract useful information from this data, it can first be processed as follows. Some background for the following was found in [12]. Fourier transforming the received signal (2.6) from frequency ω to fast time t gives E(t, s) = X = X = X Z ei2ωk̂(s)·rn /c e−iωt dω Z e−iω(t−2k̂(s)·rn /c) dω Dn n Dn n Dn δ(t − 2k̂(s) · rn /c). (2.8) n This gives the received signal in the form of a time-delayed delta function, as is expected from the development in Section 2.1. We note that the introduction of the delta function assumes the signal model is valid for −∞ < ω < ∞, even though data is actually taken over only a selected frequency band. Two commonly known radar observables are range and range-rate. These are the observables that will be used here. Consequently, it will be useful to express the received signal above in terms of range, R, instead of time, t. We use the relation 14 t = 2R/c to obtain the expression E(R, s) = X n 2 Dn δ( (R − k̂(s) · rn )). c (2.9) Here we note the abuse of notation in again using E. The received signal is now given in range and slow time. Plotting E(R, s) for all R and s gives a Range-Time Intensity (RTI) plot, as shown in Figure 2.4. Figure 2.4: RTI Plot for Simulated Data Inverse Fourier transforming E(R, s) transforms slow time to Doppler frequency, ν. This is done for each fixed slow time value, s0 . Since it wouldn’t be useful to Fourier transform data at just one point, a “block” of data centered at each fixed slow time value, s0 , is used for each transform. The block is formed by multiplying the data by a“window”, W , that zeros out all the data not included in the block. The length of the window can be thought of as similar to the length of time the shutter is open on a camera. If it’s too long, the image will be blurred. The images here were made with a window length of 64 pulses. Inverse Fourier transforming the windowed data results in I(s0 , R, ν) = X n Z Dn 2 δ( (R − k̂(s) · rn ))Ws0 (s)eisν ds, c (2.10) so that the data are now in fast time and Doppler frequency. Again, it will be more useful to represent data in range-rate. Doppler frequency, ν, is related to range-rate, 15 Ṙ, by ν = 4π Ṙ, λ so we have I(s0 , R, Ṙ) = X n Z Dn 4π 2 δ( (R − k̂(s) · rn ))Ws0 (s)eis λ Ṙ ds. c (2.11) This is depicted for s0 = 45◦ in Figure 2.5. Figure 2.5: Fixed Aspect Data Block Since each (R, Ṙ) image is formed using a fixed aspect, we end up with L total images, often referred to as data blocks. Viewing these images in succession gives a “movie” of the target’s motion throughout the data acquisition period. The peaks of each image correspond to the radar observables to be extracted. Each peak has coordinates in the (R, Ṙ) plane, as well as a phase and amplitude at that location. These observables are recorded at each aspect and can be used for imaging. The process of extracting these observables from sequential images is known as sequential block processing. Figure 2.6 shows the extracted ranges and range-rates for each successive block. The radar begins viewing the target from the back end, as oriented in the first target image. As time (and aspect angle) increases, the target is viewed from all angles. The tumbling target in the figure displays how the target is oriented as time increases. 16 Figure 2.6: Extracted Ranges and Range-Rates Note the distinct sinusoidal nature of the ranges and range-rates. As the radar moves around the target in a circle, its coordinates, and therefore range to the target, can be described in terms of sines and cosines. Figure 2.7 illustrates this. Since range-rate is the time derivative of range, it follows that range-rate is also sinusoidal. Figure 2.7: Sinusoidal Nature of Range and Range-Rate 17 2.4 Sample Target Figure 2.8 shows the sample target geometry used for further simulations. The target has a cone body (grey) and three fins (blue). The fins are located 120◦ apart on the back end of the target. As mentioned previously, discrete points on targets are known as scatterers. Each of the red points in Figure 2.8 represents a scatterer on the sample target. The target has a total of thirteen fixed scatterers; four on each of the three fins and one on the cone nose. Figure 2.9 shows the three-dimensional simulated points used to model the target. Each point has a three-dimensional set of coordinates, (x, y, z). Figure 2.8: Sample RV Target Geometry Figure 2.9: Simulated Sample RV Target Points 18 2.5 Assumptions Many simplifications are made here. • Constant Amplitude For simplicity, each of the scatterers in Figure 2.9 were given equal constant amplitudes in the simulations. In reality, not all scatterers have the same amplitude, and their amplitude can vary depending on which direction they are viewed from. Variations in amplitude would show up in RTIs such as the one in Figure 2.4. • No Speculars Specular scattering occurs when a flat surface of a target is viewed at an angle exactly perpendicular to the surface, and a much higher return is generated. A useful real-life example is when some people’s foreheads show up as completely white in pictures when they are exactly perpendicular to the camera. A more realistic target model would include this effect, but this effect is ignored here. • Scatterer Resolution Notice in Figure 2.5 that the many scatterers on the back end of the target seem blurred together. This is also seen by how close together the range tracks are in Figure 2.4. This is due to the resolution of the Fourier transform. If there are many scatterers close together, they will not all be resolved, so the extracted ranges and range-rates will include some errors due to this. To help minimize that effect here, we use the simpler target shown in Figure 2.8. • No Shadowing Shadowing, or disappearing or occluded scatterers, occurs when some scatterers on a target cannot be seen because they are being blocked by other scatterers on the target. For example, when viewing the sample target looking directly at the back end of the cone, it would be impossible to see the nose of the cone. In Figure 2.4, the track on the top left for 0 < t < π 2 is the nose scatterer. It wouldn’t show up if shadowing was incorporated in to the target 19 model. Shadowing would also result in not every point in Figure 2.5 being visible. The effect of shadowing is not considered here. • Polarization Polarization refers to the geometry in which electromagnetic waves are transmitted and received. They can be transmitted and received either horizontally or vertically. Letting H denote horizontal and V denote vertical, this gives four transmit-receive combinations; HH, HV, VH, and VV. No specified polarization is included in the simulation, although it would be more realistic to include this. 20 2.6 Scatterer Correlation Scatterer correlation was briefly introduced in Section 1.6. Here we present a more detailed explanation of scatterer correlation. The range vs. range-rate images (data blocks) in Figure 2.10 display the aforementioned target at two aspect angles 30◦ apart. Scatterer correlation is the process of determining which scatterers in the second image correspond with which scatterers in the first image. For example, if we consider only scatterers A, B, and C in the first image, there are 3! = 6 possible ways these scatterers could be rearranged to get scatterers A, B, and C in the second image. From these images, it is fairly clear that A → A, B → B, and C → C. This problem gets very complicated very quickly, however. Including all thirteen scatterers on the target gives over six billion possible correlations. This problem is made much more difficult in the presence of noise and shadowing. Figure 2.10: Scatterer Correlation Figure 2.11 gives examples of uncorrelated and correlated data matrices. When data is correlated, data from specific scatterers is always entered in the same order in each row. This is not the case for uncorrelated data. Here, the letter in each matrix entry is used to indicate that the data located at that entry is from the scatterer corresponding to that letter, and has the form shown in (2.5). Unfortunately, radar data in general isn’t correlated. This is because as a radar interrogates a target and records data, it has no way of “knowing” which 21 Figure 2.11: Examples of Uncorrelated and Correlated Data Matrices data taken at a given aspect corresponds to data taken at a previous aspect. As the target is viewed at different orientations, its scatterers are viewed in different orientations as well. These ever-changing orientations dictate how the radar data is recorded. After the raw radar data is processed as discussed previously in this chapter, we arrive at Range vs. Range-Rate images. A peak-finding algorithm is used to identify all peaks in each of these images that are above a certain threshold. A peak is defined as a point in the image that is greater than all eight points surrounding it (right, left, top, bottom, top right, top left, bottom right, bottom left). In general, more points will be classified as peaks than there are scatterers on the target. Therefore, an input to the algorithm is the number of peaks to be extracted, p. In order to ensure that the p peaks chosen are most likely to be those resulting from scatterers on the target, the peaks are sorted by amplitude and the p points of highest amplitude are chosen. Their range, range-rate, and phase are recorded in the data matrices. Based on how the data is chosen to be recorded, it is easy to see that there is no guarantee the data will ever be recorded in the same order from one aspect to the next. Therefore, the data will in general be uncorrelated. However, data will remain correlated for a few aspects at a time. This is because data is recorded at every 0.25◦ . The images don’t change much over this small of a change in aspect. Therefore, data is recorded in the same order over at least a few aspects at a time, until a noticeable change occurs in the orientation of the target. 22 2.7 The Shape and Motion Estimation Problem Shape and motion estimation poses a nonlinear optimization problem which is a function of several variables including target geometry (size and shape), body center of rotation, and Euler dynamical variables, spin and precession, as explained in Section 2.8. Figure 2.12 displays the relationship between shape, motion, and radar observables. Many imaging algorithms assume either shape or motion is known in order to solve for the other. The joint estimation problem, which involves solving for both shape and motion, is a difficult and nontrivial problem. Figure 2.12: Relationship Between Motion, Shape, and Radar Observables Notice that the size of the shape matrix will never change. It will always have dimensions 3 × N , since each of the N scatterers has coordinates in three dimensions. However, the matrices of motion and radar observables will increase in size as the target is viewed at increasing numbers of aspects, since both have dimension 3L. Here, L is the number of aspects. Data taken at L aspects for all three radar observables results in a total of 3L rows of data in these matrices. 23 2.8 Euler’s Dynamical Equations of Torque-Free Motion The motion considered in this work will be torque-free motion. We give some background on what this means. The following can be found in [13]. The Euler equations are equations that describe the rotation of a rigid body. It is assumed that the reference frame is centered inside the body. The equations are Ix ω̇x + (Iz − Iy )ωy ωz = Nx Iy ω̇y + (Ix − Iz )ωz ωx = Ny Iz ω̇z + (Iy − Ix )ωx ωy = Nz . Here, the Ii are the three principal moments of inertia, ωi are the three components of the angular velocity, ω̇i are the three components of the angular acceleration, and Ni are the applied torques. Torque-free motion occurs when each Ni = 0. This yields Euler’s Dynamical Equations of Torque-Free Motion, Ix ω̇x = (Iy − Iz )ωy ωz Iy ω̇y = (Iz − Ix )ωz ωx (2.12) Iz ω̇z = (Ix − Iy )ωx ωy . The quantities ωx , ωy , and ωz depend on the Euler angles φ, ψ, and θ, ωx = ψ̇ sin θ sin φ + θ̇ cos φ ωy = ψ̇ sin θ cos φ − θ̇ sin φ ωz = φ̇ + ψ̇ cos θ. Here, ψ is the spin angle, θ is the precession cone angle, and φ is the precession rotation angle. The following is adapted from [8]. For our application, we use a target-centered coordinate system as shown in Figure 2.13. The origin is located at the center of the target. The vectors x, y, and z originate at the center of the target and are chosen to 24 Figure 2.13: Target Centered Coordinate System align with a dimension of the target. Standard spherical coordinates θ, φ characterize the look angle to the radar, which is determined by the unit vector k̂. Here, κ is the localized aspect angle from the radar to the target angular momentum vector, θp is the precession cone angle relative to the target angular momentum vector, φp is the precession rotation angle, and ψ is the spin angle. In general, for a target undergoing torque-free motion, θ(t) = θ(κ(t), θp , φp ) and φ(t) = φ(κ(t), θp , φp , ψ(t)) are complicated functions determined by Euler’s dynamical equations of motion. The aspect angle θ(t) is dependent on the precession variables, θ(t) = cos−1 (cos κ cos θp + sin κ sin θp sin φp ). (2.13) The roll angle φ(t) is dependent on the spin and precession variables, −1 φ(t) = ψ − tan cos κ sin θp − sin κ cos θp sin φp sin κ cos θp . (2.14) The target coordinates (and, hence, the image reference frame) are defined relative to the origin of the system shown in Figure 2.13. For a wideband radar operating in the higher frequency bands, the total scattering from the target can be decomposed into scattering from discrete scattering centers, rn , n = 1, . . . , N , as discussed in Section 2.3.1. Assume we can isolate a specific target scatterer. In a 25 target-centered coordinate system, this position is fixed, and the look angle to the radar, and its time derivative, are given by k̂ · rn ≡ Rn (2.15) ˙ k̂ · rn ≡ Ṙn (2.16) where (Rn , Ṙn ) are the range and range-rate radar observables corresponding to rn ˙ and k̂ and k̂ are functions of θ, θ̇, φ, φ̇ given by k̂ = sin θ cos φ x̂ + sin θ sin φ ŷ + cos θ ẑ (2.17) ˙ k̂ = θ̇θ̂ + φ̇ sin θ φ̂ (2.18) where θ̂ = cos θ cos φ x̂ + cos θ sin φ ŷ − sin θ ẑ φ̂ = − sin φ x̂ + cos φ ŷ. Equation (2.15) was previously shown geometrically in Figure 2.2. Equations (2.15) and (2.16) form a nonlinear set of equations characterizing the behavior of θ(t) and φ(t) and each scatterer rn . In [8], physical constraints are imposed on the motion θ(t) and φ(t) by constraining them to that body motion following from Euler’s dynamical equations of torque-free motion. 2.8.1 Special Case: Turntable Geometry In the turntable geometry/static range measurement case depicted in Figure 2.3, the radar is kept stationary while the target rotates a full 360◦ , which is computationally equivalent to the radar rotating as the target is kept stationary. The radar views the target in the plane θ = θ0 at a constant roll, while φ varies. For example, if θ0 = 90◦ , (2.17) and (2.18) are simplified to k̂ = cos φ x̂ + sin φ ŷ (2.19) ˙ k̂ = φ̇ (− sin φ x̂ + cos φ ŷ), (2.20) 26 where φ̇ is constant. This motion is purely two-dimensional. 2.9 Simulating Truth Radar Data In order to test the imaging algorithms developed in this work, we must simu- late data to test them on. At each aspect, the instantaneous motion is defined as in (2.17) and (2.18). For each of the L aspect angles and F frequency values, we use (2.7) to determine the exact value of the scattered field at that location. We end up with an L × F matrix of raw radar data. Note that in the case that we are simulating truth radar data resulting from turntable geometry, we use (2.19) and (2.20) instead of (2.17) and (2.18) to plug in to (2.7). The data used here was simulated to be X-band data, as is typical for radars imaging targets of this size. Specifically, F = 81 frequencies equally spaced between 8.2 and 12.2 GHz were used, making the center frequency 10.2 GHz. We assume that data is taken at 360◦ about the target, taken every 0.25◦ . This results in a total of N = 1441 aspects. The one extra aspect results from data being taken both at 0◦ and 360◦ . 2.10 Resolution The Fourier transforms here were computed using MATLAB’s Fast Fourier Transform (FFT). For computation speed, all Fourier processing here was computed using an FFT of size 28 = 256. A power of two was chosen because the FFT performs more efficiently when its size is a power of two. To calculate the wavelength resulting from using the given X-band frequencies, we plug in to the well-known equation relating wavelength and frequency, λ= c , ωc where ωc is the center frequency. This gives λ= 3 × 108 m/s = 0.0294m. 10.2 × 109 Hz 27 We expect that the wavelength, λ, will give a limit on the resolution that can reasonably be expected. The total range in each dimension of the images formed here is 3m, with a grid size of 256 × 256 resulting from the FFTs in both dimensions. This implies a resolution of 3 256 = 0.0117m per pixel in each dimension. This resolution, however, is unrealistic, given that it is less than half the wavelength. This resolution limit is what leads to the blurriness of the images, for example, how not all the scatterers are resolved in Figure 2.5. The limit on resolution that results from the FFT size is one of the reasons that target space image summation is used in Section 3.7. 2.11 Matrix Decompositions 2.11.1 The Singular Value Decomposition (SVD) We first present a brief review of the SVD, as it will be used frequently throughout this thesis. The following is adapted from [15]. The singular value decomposition (SVD) of a matrix A ∈ Cm×n is a factorization A = U Σ V ∗, where U ∈ Cm×m is unitary, V ∈ Cn×n is unitary, Σ ∈ Rm×n is diagonal. The diagonal entries σj of Σ are nonnegative and in non-increasing order, so σ1 ≥ σ2 ≥ . . . ≥ σp ≥ 0, where p = min(m, n). 28 2.11.2 The Reduced QR Factorization We now present a brief review of the reduced QR factorization. The following is adapted from [15]. The reduced QR factorization of a matrix A ∈ Cm×n is given by A = Q̂ R̂, where Q̂ is an m×n with orthonormal columns and R̂ is n×n and upper-triangular. The sequence of columns q1 , q2 , . . . has the property span(q1 , q2 , . . . , qj ) = span(a1 , a2 , . . . , aj ), j = 1, . . . , n. The columns a1 , . . . , ak can be expressed as linear combinations of q1 , . . . , qk , a1 = r11 q1 a2 = r12 q1 + r22 q2 a3 = r13 q1 + r23 q2 + r33 q3 .. . an = r1n q1 + r2n q2 + . . . + rnn qn . The full QR factorization of this same matrix A appends m−n more orthonormal columns to Q̂ so that it is an m × m unitary matrix, Q. Rows of zeros are added to R̂ to make the matrix R size m × n. This yields the relation A = Q R. 29 2.12 Basic Problem Formulation We present a brief overview of the basic problem formulation to motivate the subsequent sections. As discussed in Section 1.8, the two methods focused on here are the Phase-Enhanced 3D Snapshot Imaging method and the SVD method. Figures (2.14) and (2.15) give schematics highlighting the key ideas of each method. Figure 2.14: Phase-Enhanced 3D Snapshot Imaging method Figure (2.16) gives a schematic highlighting the goal of the dissertation; to develop a phase-enhanced 3D SVD method that uses range, range-rate, and phase in order to jointly estimate shape and motion while eliminating the need for scatterer correlation. 30 Figure 2.15: SVD Method Figure 2.16: Phase-Enhanced SVD Method CHAPTER 3 Phase-Enhanced 3D Snapshot Imaging Algorithm We present an overview of phase-enhanced interferometric processing. The following development is adapted from [8]. In 3D Inverse Synthetic Aperture Radar (ISAR) imaging, a target-centered coordinate system is employed, from which 2D range-Doppler image planar cuts through the target (as in Figure 2.5) are associated with points in the coordinate system (as in Figure 2.9) using the (assumed) known aspect angle to the target. These 2D images can be combined to form a 3D image of the main scattering centers, or scatterers, on the target. More recently, 3D snapshot imaging was developed. Conventional 2D snapshot imaging involves applying 2D ”snapshot” equations to two extracted radar observables, range and range-rate, to solve for 2D shape. To apply these to 3D, the 2D equations are applied to two different snapshots of data simultaneously and the resulting system of equations is solved in a least squares sense [7]. Another technique currently being explored is Interferometric Synthetic Aperture Radar (IF-SAR). This involves the “overlaying” of nearly identical 2D rangeDoppler images and uses phase differences between these images to estimate the “out-of-plane” height information, from which a 3D image is developed. The phase-enhanced 3D snapshot imaging algorithm combines 3D snapshot imaging and interferometric SAR. Localized microdynamic changes in look angles to the target characterized by Euler’s 6 Degrees-of-Freedom (6DOF) dynamical equations of motion (background given in Section 2.8) result in the nearly identical 2D range-Doppler images needed for interferometric SAR. The conventional 2D snapshot imaging equations are augmented to involve a third equation involving the resulting phase differences. The technique is particularly applicable for targets with smaller numbers (≤ 20) of dominant scatterers. In this section, we present an overview of 2D snapshot imaging, present two derivations of the phase equation, and then show how this equation is augmented 31 32 to the 2D snapshot imaging equations to yield the phase-enhanced 3D snapshot imaging equations. We show how additional data can be incorporated, and present many factors that need to be taken in to account when implementing the resulting equations. These include phase ambiguities, summing composite target space images, and sector processing. 3.1 2D Snapshot Imaging Equations As introduced in Section 2.3, 2D data blocks, or “snapshots”, can be pro- cessed sequentially to develop a sequence of range, range-rate pairs (Rn , Ṙn )m , t = t1 , . . . , tm . Equations (2.15) and (2.16) are applied sequentially to a number of snapshots to develop an image of the scatterers rn . This can be expressed in matrix form: T m · rn = Rn Ṙn , (3.1) m where T is a 2 × 3 transformation matrix given by k̂ T = ˙ . k̂ ˙ Here k̂ and k̂, as defined in (2.17) and (2.18), are expressed as row vectors, rn is a column vector, and (3.1) defines the mapping at time t = tm . Note that this applies to one specific scattering center rn . Applying these equations to each scatterer at each snapshot by direct matrix inversion results in two-dimensional estimates of the scatterers rn = (xn , yn ). This is adapted from [7]. Note that scatterer correlation is not required here since (3.1) is applied to individual scatterers separately at each time tj . Applying the two equations of (3.1) results in a two-dimensional estimate at time tj . 3.2 3D Snapshot Imaging Equations Now consider augmenting equations from another snapshot taken at t = tp to (3.1). Using three or more independent equations will result in a three-dimensional 33 shape estimate. Equation (3.2) gives the augmented equations, Tm Tp Rnm Ṙ nm · rn = Rnp Ṙnp . (3.2) Applying these equations to one scatterer at two snapshots will result in a threedimensional estimate of the scatterer rn = (xn , yn , zn ), as shown in [7]. Note that scatterer correlation is required here since the nth scatterer at t = tm must correspond to the nth scatterer at aspect t = tp . Also note that no restrictions are made on how “close” together the two snapshots must be. 3.3 Phase Equation Here we present two different derivations of the phase equation. The first derivation comes from comparing the equation of the received signal at two snapshots that are “close together” (what this means will be described in Section 3.4. This is adapted from [8]. The second derivation is a new derivation presented here to show that the same result can be obtained directly from the equations of two individual RangeDoppler data blocks. These Range-Doppler data blocks are also assumed to be “close” together. 3.3.1 Derivation from Snapshot Equations As shown in Section 2.3, the received signal from the target can be written in the form (2.7). Let k̂m = k̂1 at time t = t1 so that E1 = X 4π Dn ei λ k̂1 ·rn . (3.3) n Typically, the complex amplitude Dn is a relatively slowly varying function of frequency ω and angles θ(t) and φ(t) and characterizes the geometric theory of diffraction (GTD) diffraction coefficient of the nth scattering center. It is essentially 34 constant from one data block to the next when using sequential block processing, as long as the data blocks are “close” enough together so that no noticeable change occurs in range, range-rate, and amplitude. Consider viewing a target at two consecutive aspects. Let k̂m = k̂2 at t = t2 where t2 > t1 . If we assume k̂2 is “close” to k̂1 , then we say k̂2 = k̂1 + ∆k, (3.4) where ∆k is small. Using (3.4) in the general expression (3.3), the scattered field E2 at time t = t2 can be expressed in the form E2 = X 4π 4π [Dn1 ei λ ∆k·rn ]ei λ k̂1 ·rn (3.5) n Now assume that, since k̂2 is close to k̂1 , the 2D range-Doppler images extracted from each 2D data block centered at times t = t1 and t = t2 , respectively, are nearly identical, so that the individual scatterers in each image can readily be identified and correlated. It is assumed that range, range-rate, and amplitude remain constant; phase is the only quantity that changes. Hence, by extracting the phase of each scattering center from the range-Doppler image, (3.3) and (3.5) can be compared to obtain Phase(I2n ) − Phase(I1n ) = Phase(Dn1 ) − Phase(Dn2 ) + 4π (∆k) · rn λ (3.6) where I1n and I2n represent the complex value of the image pixel of the nth scattering center defined over each respective range-Doppler image plane. If k̂2 and k̂1 are close, then Dn1 ≈ Dn2 , so that (3.6) can be written in the form 4π (∆k) · rn = ∆n (Phase), λ (3.7) ∆n (Phase) = Phase(I2n ) − Phase(I1n ). (3.8) where we define: Equation (3.7) is the third equation that will be used to augment the standard set 35 of 3D snapshot imaging equations. It should be noted that (3.6) - (3.8) as derived are equivalent to the standard characterization of IF-SAR processing. They are repeated here only to emphasize their coupling to the 3D snapshot imaging equations. 3.3.2 Derivation From Range-Doppler Data Block Recall from Section 2.3 the equation of each Range-Doppler data block, I(s0 , R, Ṙ) = X n Z Dn 4π 2 δ( (R − k̂(s) · rn ))Ws0 (s)eis λ Ṙ ds. c (3.9) We Taylor expand k̂(s) about s = s0 , ˙ k̂(s) = k̂(s0 ) + k̂(s0 )(s − s0 ) + · · · , so that I(s0 , R, Ṙ) = X Z 4π 2 ˙ δ( (R − (k̂(s0 ) + k̂(s0 )(s − s0 ) + · · · ) · rn ))Ws0 (s)eis λ Ṙ ds. c (3.10) Dn n We let 2 ˙ s0 = (R − (k̂(s0 ) + k̂(s0 )(s − s0 ) · rn )). c The delta function in (3.10) makes a nonzero contribution approximately when s0 = 0. Using (2.15) and (2.16) at time s0 , setting s0 = 0 gives s = s0 + R − Rn (s0 ) . Ṙn (s0 ) Then denoting the Jacobian resulting from the change of variables from s to s0 by J, we find I(s0 , R, Ṙ) = J X n n (s0 ) R − Rn (s0 ) i(s0 + R−R )( 4π Ṙ) λ Ṙn (s0 ) Dn Ws0 s0 + e . Ṙn (s0 ) (3.11) 36 Isolating the phase of the nth scatterer gives 4π R − Rn (s0 ) Phase(In (s0 , R, Ṙ)) = s0 + Ṙ λ Ṙn (s0 ) 4π Ṙ(R − Rn (s0 ) + s0 Ṙn (s0 )) = . Ṙn (s0 )λ (3.12) The above equation gives the phase for fixed roll angle θ1 . Fixing φ and varying only θ allows us to consider changes in θ in particular instead of k. Now for θ = θ1 + ∆θ = θ2 , we assume that ∆θ is small enough that R(s0 ), Ṙ(s0 ), and Ṙ do not change noticeably. Then ∆n (Phase) = Phase(I2n ) − Phase(I1n ) = 4π Ṙ(Rθ2 − Rθ1 ) . Ṙ(s0 )λ (3.13) Assuming that at extracted peaks we have Ṙ = Ṙ(s0 ) and substituting Rθ2 − Rθ1 = k̂2 · rn − k̂1 · rn = ∆k · rn gives ∆n (Phase) = which is exactly (3.7). 4π (∆k) · rn , λ (3.14) 37 3.4 Phase-Enhanced 3D Snapshot Imaging Equations Note that increasing the number of equations used in (3.1), resulting in (3.2), caused the shape estimate to be three-dimensional instead of two-dimensional. In doing this, correlation between two snapshots is required. However, augmenting (3.1) with a different equation that doesn’t need to be correlated from the previous snapshot would be advantageous. The following methodology is adapted from [8]. We augment (3.1) with the phase equation given in (3.7). We consider the case where the target is rotating (spinning) with the radar stationary, so φ is monotonically increasing and θ is constant. Since Ṙ information is extracted from data along the direction of motion, then for spin-only motion, at constant roll θ0 and using (2.18) with θ̇ = 0, φ̇ sin θ0 φ̂ · rn = Ṙn , which shows that Ṙ is characterized solely by φ̇ for this case. Then since θ and φ change independently, augmenting (3.1) with data blocks associated with changes in θ as in (3.7) will provide additional independent information. In principle, augmenting (3.1) with (3.7) provides three independent equations that can be directly inverted to solve for the three unknowns (xn , yn , zn ). As previously shown, evaluating ∆k directly assuming θ = θ1 + ∆θ shows that (3.7) provides independent information. It can easily be shown that 4π 4π (∆k) · rn = ∆θθ̂ · rn . λ λ Recall that k̂ is a unit vector in the direction of the radar line of sight. Since k̂ is perpendicular to θ̂, φ̂, the three unit vectors (k̂, φ̂, θ̂) form a local (i.e., a function of θ, φ) orthogonal set of unit vectors, defining a local 3D axis set. The three independent equations are given by k̂ · rn = Rn Ṙn φ̂ · rn = φ̇ sin θ λ ∆n (Phase) θ̂ · rn = · , 4π ∆θ (3.15) 38 which clearly delineate the projections of the scattering center location vector rn onto the axes of this localized orthogonal frame. This is shown in Figure 3.1 [8]. Figure 3.1: Localized Orthogonal Coordinate System for 3D PhaseEnhanced Processing We can now rewrite (3.1) in the form T m · rn = Qmn , (3.16) where T is now a 3 × 3 motion matrix given by k̂ T = φ̇ sin θ φ̂ 4π ∆θθ̂ λ (3.17) and Qmn is given by Rn Qmn = Ṙ n , ∆n m where ∆n is shorthand for ∆n (Phase). (3.18) 39 3.5 Augmenting Additional Roll Cuts Although the phase-enhanced 3D snapshot imaging algorithm specifically ex- ploits phase differences between data sets with a very small change in roll between them, it is possible to also include data at other rolls. We can still extract R and Ṙ information for this data, however, we won’t acquire any phase information from it. Instead, we set up this data as in (3.1) and append it to (3.16). If we have u data sets corresponding to small changes in roll and v − u single data sets, the augmented equations become k̂1 φ̇ sin θ φ̂ 1 1 4π ∆θ1 θ̂ 1 λ .. . k̂u φ̇ sin θu φ̂u T · rn = 4π ∆θu θ̂ u λ k̂u+1 φ̇ sin θ u+1 φ̂u+1 .. . k̂v φ̇ sin θv φ̂v Rn1 Ṙ n1 ∆n 1 . . . Rnu Ṙnu · rn = ∆nu R nu+1 Ṙ nu+1 . .. Rnv Ṙnv = Qn . (3.19) This system can then be solved in a least squares sense for the scattering positions rn , rn = (T T T )−1 T T Qn . (3.20) 40 3.6 Phase-Enhanced 3D Snapshot Imaging Considerations We now focus on the implementation of the Phase-Enhanced 3D Snapshot Imaging equations, given in (3.16). We discuss how the change in roll is done in practice, then we discuss the considerations that have to be taken when employing the target centered coordinate system. 3.6.1 Change in Roll Recall that in turntable geometry, “snapshots” are taken at multiple consec- utive aspects at a fixed roll angle. Data can then be taken the same way but for a different fixed roll angle. If the two fixed roll angles are “close” enough together, this similar data can be exploited to gain information about the target in another dimension. Figure 3.2 shows how this data is taken. Figure 3.2: Measurement Collection Method The theory behind the phase-enhanced 3D snapshot imaging method is that the change in phase between data taken at two successive roll angles gives information that can be used as the third independent variable in the snapshot equations. Recall from Section 3.3.1 that k̂1 and k̂2 (corresponding to two consecutive roll angles) must be “close”, i.e., ∆k must be “small”, in order for the phase equation to be useful. This is because if ∆k changes so much that the resulting change in phase is greater than 2π, the result will be ambiguous. This is easily seen by the relation Phase(Aeiα ) = Phase(Aei(α+2π) ). Consequently, we aim to choose a sufficiently small value of ∆k. Now recall from Figure 2.13 that k̂ depends on both θ and φ. When looking at a change in roll, θ, 41 the aspect angle, φ, is kept constant. Therefore, a change in k̂ is equivalent to a change in only θ in this case. Since even 1◦ could be too large of a value for ∆θ, we will use ∆θ = 0.5◦ for simulations. Even smaller would be better, but we keep in mind that it is very difficult to physically rotate a target by even a half a degree, let alone less than half a degree. 3.6.2 Coordinate System It is important to pay attention to the coordinate system used here. The roll angle θ is always measured in the y − z plane from the z-axis down to the point on the target such that 0 ≤ θ ≤ π. To illustrate this, notice that θ = 120◦ for both lower fins in the diagram of the back end of the target in Figure 3.3. Figure 3.3: Apparent Motion of Target Between Two Roll Cuts As can be seen, the three fins are at 0◦ , 120◦ , and 120◦ at roll 0◦ . Note that roll 0◦ corresponds to θ = 90◦ , since θ is measured to the radar and the radar is always in the z = 0 plane for turntable geometry. When roll increases to ∆θ◦ , one would initially think that all points on the target move ∆θ◦ in θ. This diagram illustrates that for points on the right side of the target here, roll does indeed increase by ∆θ◦ , however, roll decreases by ∆θ◦ for points on the left. This is an important condition that must be included when implementing the equations. 42 3.6.3 Implementation As mentioned above, roll 0◦ corresponds to θ = 90◦ . Then with the parameters ∆θ = 0.5◦ , −π ≤φ ≤ π, 0 ≤t ≤ π, φ̇ = 1, (3.17) yields sin φ cos φ 0 , T = cos φ − sin φ 0 0 0 −1 so that Rn ˙n . rn = T −1 · R ∆n Thus we have solved for rn . Keep in mind, however, that the calculated rn will actually have the form rn + ∆r, where the added term represents the estimate error and variance that is inherently added to the truth rn positions. This is due to the limit on resolution imposed by the size of the FFT used to make the Range-Doppler images. Implementing these equations directly results in Figure 3.4a. The color of each point corresponds to its amplitude. Notice the extraneous points reconstructed much higher and lower than the target’s actual location. Even with ∆θ = 0.5◦ , some phase ambiguities are still induced. This will always be the case, however, since for two phases Θ1 ∈ [−π, π] and Θ2 ∈ [−π, π], we find that Θ2 − Θ1 ∈ [−2π, 2π]. In the following section, we find a way to visualize and correct for these induced phase ambiguities. 43 3.6.4 Resolving Phase Ambiguities A way to visualize the induced phase ambiguities is to add 2π to the phase of every reconstructed point and plot it in a different color, then do the same for −2π. This results in Figure 3.4b. It is clear that the extraneous points in the figure on the left indeed do come from these phase jumps. A simple fix, then, is to impose a geometric constraint on the reconstructed data points. The reason that this is possible is because the phase-enhanced 3D snapshot imaging method reconstructs shape in actual target coordinates, so it is known that the center of the target will be at the origin of the coordinate system. As will be seen in Section 4, not all imaging methods reconstruct targets in actual target coordinates, so this is not always possible. The target space filtering algorithm used here is that if a reconstructed height is at least 0.5m greater than the highest target point, then 2π is added to its phase. Similarly, if a reconstructed height is at least 0.5m lower than the lowest target point, 2π is subtracted from its phase. Obviously, 0.5m isn’t the correct height to use for all targets, so this would have to be determined independently for other targets. As a result of this target space filtering algorithm, all reconstructed points are mapped back to their correct locations in target space, as in Figure 3.4c. This is a novel method first presented here. Figure 3.4: a) Reconstructed Positions, b) ±2π Phase Ambiguities c) Target Space Filtered Image Figure 3.5 includes Figure 3.4c at different 2D views so that the main features 44 can be seen. Notice that many scatterers are reconstructed, but the number of scatterers, lack of shadowing, and limited resolution of the Fourier transform prohibit precise estimation. The fins on the target are apparent in the back view. However, the noise in the data due to the limited resolution of the Fourier transform results in some extraneous points being reconstructed above where the top fin should actually be. It also results in many points incorrectly being reconstructed in between scatterers. Figure 3.5: Phase Resolved Target Points, Three 2D Views 45 3.7 Summing Target Space Images The plots in Figure 3.5 are scatter plots of the points calculated directly by inverting the 3 × 3 system of phase-enhanced 3D snapshot imaging equations. As mentioned in Section 2.10, the resolution implied by the grid size resulting from a FFT of length 256 is unrealistic given the wavelength λ = 0.0294m. A more realistic resolution would be larger. For example, assuming resolution of 0.05m implies a grid size of 3 = 60. 0.05 We call each 3D grid point a bin, and sum up all points that fall within each bin. There are two ways of doing this. Amplitudes The first is to sum the amplitudes of all points that fall in to each bin. This allows higher amplitude scatterers to dominate, and has a risk of missing low amplitude scatterers. We call this method “amplitudes”. Counts The second option is to sum only the number of points that fall in to each bin. In this case, lower amplitude scatterers are more likely to be resolved. We call this method “counts”. In either of these cases, we can plot the total sum of each bin at its 3D location. The color of the point at that location will correspond to the total sum there. The images in Figure 3.6 are from the target space reconstruction using the amplitudes method. Using the counts method gives very similar results. Figure 3.6: Target Space Reconstruction, 3D & Three 2D Views As can be seen, not every point is reconstructed, but many main features are. 46 It should be noted that more features could be resolved if a bigger FFT size is used. However, this takes much longer computationally and often causes MATLAB to run out of memory. These images of the target are sometimes referred to as “target space” images, because they are reconstructed in actual target coordinates. This means that the origin corresponds to the center of the target, so the exact location of the target is known. As will be seen when the SVD method is introduced in Section 4, this is not always the case. 3.8 Sector Processing In the peak-finding algorithm, all peaks in the Range-Doppler images that are above a certain threshold are recorded as peaks, then the top N peaks are extracted, where N is the predicted number of scatterers on the target. The peak classification cutoff threshold is measured in decibels (dB) below the maximum intensity in the image. All the processing of the simulated data was performed with a threshold of 30 dB below max. This works well for simulated data of constant amplitude. However, when real radar data is used, amplitudes can vary greatly. In this case, some features can be reconstructed very well, while others are completely missed since their amplitudes are small in comparison to other features. The top fin of this target is a good example here. This inspired the idea of using a variable threshold on the data. This threshold should be low for the look angles that most directly view the top fin and higher in other areas. It is apparent from the reconstructed positions that many extraneous points are picked up. So, instead of using data at all look angles, one option is to perform sector processing. This involves using data from only a few choice look angle sectors, and optimally using a different threshold at each sector. This minimizes some of the unwanted error that has propagated through the system, some still due to the errors induced in the peak-finding algorithm. This is illustrated in Figure 3.7. Included in Figure 3.8 are side views of reconstructions performed using a) just one look angle, b) four look angles, c) the four sectors mentioned previously, and d) all look angles. It is important to note that a good deal of the target can be 47 Figure 3.7: Sector Processing, Pink Areas Correspond to Data Used picked up from just one look angle, since it is indeed a snapshot of the target. These reconstructions show that no features are lost by only using four sectors instead of all look angles, which is less than 10% of the original data. Many points are picked up just from a small number of look angles. Recall that in Section 3.6.3, it was pointed out that each calculated rn position is associated with estimate error and variance. Using more and more data when a relatively good image has already been reconstructed adds even more error. Therefore, if a reasonable image is made with a smaller amount of data, it is redundant to add in more points. Figure 3.9 includes the target space images formed from the simulated data using the sector processing shown in Figure 3.7. They look very similar to the images formed using all look angles, and they actually look a little cleaner (compare to Figure 3.6). This is especially apparent in the back end view. 48 Figure 3.8: Comparison: Sector Processing for Various Amounts of Data Figure 3.9: Target Space Reconstruction Using Sector Processing CHAPTER 4 SVD Method This chapter summarizes the work [11]. 4.1 Derivation In the SVD method, the rigid-body assumption is employed, that is, it is assumed that nothing on the target itself is moving. We start with an equation similar to (2.15), X d̂ = ρ. (4.1) Whereas (2.15) included data for one isolated scatterer, (4.1) includes all scatterers at a given aspect so that the shape matrix X is N × 3, the motion unit vector d̂ is 3 × 1, and the range vector ρ is N × 1. In the phase-enhanced 3D snapshot imaging algorithm, it was required that motion be known a priori. Here, neither shape nor motion is known a priori. The goal is to estimate both shape and motion from the initial data, ρ. Since many variables will be used, a table is included at the end of this section displaying all variables used and their dimensions. At each consecutive aspect, the target moves in a way that can be characterized by rotations and translations, i.e., at the mth aspect, T X Od̂m + d̂m · τ m 1N = ρm . Here, O is a rotation matrix, τ is a translation vector, and 1 is a N × 1 vector of ones. Recall that in the phase-enhanced 3D snapshot imaging algorithm, Rn in (2.15) included no translational information (R0 in Figure 2.2). This isn’t possible in the SVD method, since motion is not known a priori. The method is used on range-only data taken at unknown aspects to the target, and consequently, both X and ρm include translational information. The translational information is removed through centroid removal. To do this, the mean range is subtracted from each range and each target coordinate, 49 50 which allows the translational term to be removed. This yields the equation rk̂ = R, (4.2) where R is a vector consisting of centroid-removed ranges from the radar to each scatterer, r is a matrix whose rows contain the (x, y, z) coordinates of the centroidremoved scatterers, and k̂ = Od̂ is a unit vector view direction. We aim to arrive at an estimate for the shape, r, that doesn’t include the unknown motion, k̂. Solving (4.2) for k̂ yields k̂ = (rT r)−1 rT R. (4.3) Since k̂ is a unit vector, we can apply kk̂k = 1 to (4.3). This gives RT r(rT r)−2 rT R = 1. (4.4) This gives an expression involving just shape, r, and the known range data, R. However, we can’t directly solve this equation since it is a nonlinear equation for r. Notice that any rotated shape matrix, r̃ = r O, could be substituted into (4.4) and it would still hold. Consequently, the unchanging quantity Ω = r(rT r)−2 rT in (4.4) is a matrix characterizing the shape of the target whose relative coordinates remained unchanged through rotation and translation. Such quantities are known as invariants. Here, Ω represents the shape of both X and r. Another set of invariants also representing the shape of X and r is P = r(rT r)−1 rT , since r̃ = r O also does not affect P . 51 Notice that these invariants are overdetermined. There are more equations in the system than there are unknowns to solve for. We introduce a lemma that will be useful in the derivation. Lemma 1. [11] Define R1 (t1 ) R2 (t1 ) . . . RN (t1 ) R (t ) R (t ) . . . R (t ) 2 2 N 2 1 2 φ= .. .. .. . . . R1 (tL ) R2 (tL ) . . . RN (tL ) (4.5) and write the SVD of φ as φ = QAV T, (4.6) where φ has size L × N . If the column rank of the shape matrix r is three and the span of the columns of the motion matrix k̂ is also three, where φ = rk is the desired factorization, then φ has three nonzero singular values so that A is 3 × 3 and P = S(S T S)−1 S T = V V T . We now further examine the structure of Ω, starting by finding its pseudoinverse. The pseudoinverse of matrix M must satisfy the relation M M † = I, where M † denotes the pseudoinverse of M and I is the appropriately sized identity 52 matrix. Computing the pseudoinverse gives Ω Ω† = I r(rT r)−2 rT Ω† = I rT r(rT r)−2 rT Ω† = rT rT Ω† = rT r rT Ω† = r rT . So the pseudoinverse is given by Ω† = r rT . Now since Ω is symmetric, its SVD will also be symmetric. Taking the SVD gives Ω = U Σ UT , where U is an orthogonal matrix. This allows us to find another expression for Ω† , Ω Ω† = I U Σ U T Ω† = I ΣU T Ω† = U T U T Ω† = Σ−1 U T Ω† = U Σ−1 U T . So the pseudoinverse is also given by Ω† = U Σ−1 U T . Here we have used the property that for any orthogonal matrix M , both M T M = I and M M T = I. Now that we have two different expressions for Ω† , we can set them equal to each other, Ω† = r rT = U Σ−1 U T = (U Σ−1/2 )(Σ−1/2 U T ). So we have arrived at an expression for the shape estimate; r = U Σ−1/2 . (4.7) This shape estimate is valid only up to arbitrary rotations, as is shown by the fact 53 that Ω† = r r T = r O O−1 rT = (r O)(r O)T . Now that we have an expression for r, we can rewrite (4.2) as U Σ−1/2 k̂ = R. (4.8) We now further examine the structure of P = r (rT r)−1 rT using the new expression for r. P = r (rT r)−1 rT = U Σ−1/2 ((U Σ−1/2 )T (U Σ−1/2 ))−1 (U Σ−1/2 )T = U Σ−1/2 (Σ−1/2 U T U Σ−1/2 )−1 Σ−1/2 U T = U Σ−1/2 ΣΣ−1/2 U T = U UT . Since by Lemma 1 we have another expression for P in terms of the known quantity V taken from the initial SVD, P = V V T , we see that P = U UT = V V T . This leads to the conclusion that U = V O, so U is an arbitrarily rotated version of V . Then we can rewrite (4.8) as V O Σ−1/2 k̂ = R. (4.9) 54 Now V is already known from the initial SVD (4.6), R is the original data, O is an unknown rotation matrix, Σ−1/2 is a yet unknown matrix of singular values, and k̂ is the yet unknown motion unit vector. Multiplying both sides of (4.9) by V T gives O Σ−1/2 k̂ = V T R ≡ b, (4.10) where b is known. Similarly to what was done to arrive at (4.4), we can now impose the constraint kk̂k = 1. This gives bT O Σ O−1 b = 1. Let W = O Σ O−1 . Then W is a 3 × 3 symmetric matrix with only six nonzero variables. Let w be a column vector of the unknown elements of W , w = [w11 , w12 , w13 , w22 , w23 , w33 ]T . After some manipulation, expanding the system above gives ξw = 1, (4.11) where ξ = [b21 2b1 b2 2b1 b3 b22 2b2 b3 b23 ] is known. Now for each individual observation, recall from (4.10) that b = V T R. Since each column of φ is a transposed R vector from one observation, this gives the relation B = V T φT , where B is a matrix whose columns are the known b vectors from each observation. 55 Then from manipulating the initial SVD (4.6), we see that φ = QAV T φV = QA B = V T φT = A QT , where we have used the fact that AT = A since A is diagonal. Since B is 3 × L, we can denote the three rows of B as B1 , B2 , and B3 . Individual elements of these row vectors correspond to the bi , i = 1 . . . 3 variables in ξ. These can be used to expand the single observation equation (4.11) to a system including data from all observations. Let Ξ= B1 B1 T 2B1 B2 2B1 B3 . B2 B2 2B2 B3 B3 B3 The symbol denotes the Hadamard product, which involves element-wise multiplication of the vectors it acts on. Here Ξ is L × 6 and each of its rows is a ξ observation vector. Using this, (4.11) becomes Ξw = 1L , (4.12) where 1 is an L × 1 vector of ones. This can be directly solved for w, and hence W is found. Taking its SVD gives W = O Σ O−1 , so both O and Σ have been found, and hence so has the shape estimate, r = U Σ−1/2 = V O Σ−1/2 . 56 Table 4.1: SVD Method Variables and Their Dimensions We include Variable X d̂ ρ O τ 1N r k̂ R Ω P φ Q A V U b W w ξ B Bi Ξ 1L a table of each of the matrices involved along with their dimensions. Description Dimension shape matrix N ×3 motion unit vector at one aspect 3×1 range vector at one aspect N ×1 rotation matrix at one aspect 3×3 translation vector at one aspect 3×1 vector of ones N ×1 centroid-removed shape matrix N ×3 unit vector view direction 3×1 centroid-removed ranges N ×1 invariants characterizing shape N ×N invariants characterizing shape N ×N range data matrix at all aspects L×N left unitary matrix resulting from SVD of φ L×3 diagonal matrix resulting from SVD of φ 3×3 right unitary matrix resulting from SVD of φ N ×3 orthogonal matrix resulting from SVD of Ω N ×3 T V R, known 3×1 symmetric matrix, O Σ O−1 3×3 vector of the six unknown elements of W 6×1 2 2 2 [b1 2b1 b2 2b1 b3 b2 2b2 b3 b3 ] 1×6 matrix of b vectors from all aspects 3×L th i row of B 1×L matrix whose columns are Hadamard products of Bi L × 6 vector of ones L×1 This estimate can then be plugged back in to (4.2) to solve for the motion estimate, k̂. 4.2 Methodology Summary The SVD method implementation can be summarized in six steps. 1. Take the SVD of the L × N measurement matrix φ to obtain φ = Q A V T 2. Compute the 3 × L matrix B = A QT 3. Compute the L × 6 matrix Ξ from the rows of B 57 4. Solve the L × 6 system Ξw = 1 to find the 6 elements of the 3 × 3 symmetric matrix W 5. Take the SVD of W , W = O Σ O−1 , to find the shape estimate r = U Σ−1/2 = V O Σ−1/2 6. Plug back in to rk̂ = R to solve for the motion estimate, k̂ 4.3 Geometric Interpretation A key geometric interpretation can be realized here. Computing an SVD of r itself in (4.2), r = Y Φ Z T , gives Y Φ Z T k̂ = R. Multiplying each side by Y T yields Φ Z T k̂ = Y T R = b. Imposing kZ T k̂k = 1 gives bT Φ−2 b = b22 b23 b21 + + = 1, σ12 σ22 σ32 (4.13) where each σi is the ith diagonal entry of Σ, the singular values. So the ”images” lie on an ellipse embedded in RN . This ellipse gives all possible images resulting from the data. CHAPTER 5 Phase-Enhanced SVD Method There are many differences between the Phase-Enhanced 3D Snapshot Imaging algorithm and the 3DMAGI SVD method. A few of the key differences are highlighted in the table below. The attributes in bold are the attributes that the author would like an ideal 3D imaging algorithm to have. The goal of the Phase-Enhanced SVD (PESVD) method is to combine the SVD method and the Phase-Enhanced 3D Snapshot method in order to obtain an optimal hybrid method that has as many of these attributes as possible. In the 3DMAGI SVD method, range is used to jointly solve for shape and motion. An SVD is applied to range data with the goal of recovering its shape and motion components as in (2.15). When range-rate and phase data are available as well, an SVD can instead be applied to the full data matrix (3.18) with the goal of recovering its shape and motion components as in (3.16). Essentially the goal is to Table 5.1: 3D Imaging Method Differences Radar Observables Used Shape Estimate Motion Estimate Rigid Body Assumption Scatterer Correlation Code Run Time Estimate Characteristics Motion Dimension SVD Method Range Estimated up to arbitrary rotations and translations Estimated up to arbitrary rotations and translations Required Required Essentially instant One point for each scatterer 3D Euler Motion 58 Phase-Enhanced 3D Snapshot Range, rangerate, phase Estimated in target coordinates Not estimated; required a priori Not required Not required Iterative (aspect by aspect) Cumulative target space image 2D turntable geometry 59 again solve (3.16), but now without a priori motion knowledge. The system to be jointly solved is r 5.1 k̂ ˙ k̂ R = Ṙ . 4π ∆ ∆k λ (5.1) Scaling We now further examine (5.1). In (3.16), it didn’t matter whether the coefficients in the three equations were contained in the rows of (3.17) or the rows of (3.18), since there was only one unknown matrix to solve for, shape. However, in (5.1), both matrices on the left hand side are unknown. Therefore, if the scaling isn’t predetermined, a scaling factor from the shape matrix could end up in the motion estimate or a scaling factor from the motion matrix could end up in the shape estimate. If the scaling factors in the three equations of (5.1) are different, this will have the effect of scaling each of the three dimensions of r differently. For example, the target’s height, width, and length would each be multiplied by different constants, effectively skewing the shape estimate. Each entry of the motion matrix involves sines and cosines. It is essentially a rotation matrix. By definition, rotation matrices are orthogonal matrices with determinant 1. As of yet, the second and third rows of the motion matrix are arbitrarily scaled. By definition, each k̂ is a unit vector, so the first row is fine. However, the ˙ corresponding derivative, k̂, is not necessarily a unit vector, and neither is ∆k. We have ˙ ˙ ˙ k̂ = ||k̂||k̂0 , (5.2) ∆k = ||∆k||∆k0 , (5.3) and ˙ ˙ where ||k̂|| and ||∆k|| are scaling factors and k̂0 and ∆k0 are unit vectors. This 60 modifies (5.1) to r k̂ ˙ ˙0 ||k̂||k̂ R = Ṙ . 0 4π ∆ ||∆k||∆k λ (5.4) To ensure the scaling is consistent, we move the scaling factors to the right hand side of the equation. This modifies (5.1) to k̂ ˙ 0 r k̂ = ∆k0 R 1 ˙ Ṙ ||k̂|| λ 1 ∆ 4π ||∆k|| . (5.5) The issue is now that when solving (5.5) using R, Ṙ, and ∆ as inputs, the scaling factors are not known a priori. A simple fix for the first scaling factor is to first use just the given range-rate data, Ṙ, and perform the original SVD method on ˙ ˙ it beforehand to find Ṙ = rk̂. Then (5.2) can be solved for ||k̂||. Similarly, the scaling factor λ 1 4π ||∆k|| can be calculated. These scaling factors are then applied to the radar observables on the right hand side of (5.5). Jointly estimating shape and motion using the scaled data matrix will then yield correctly scaled shape and motion estimates. The Phase-Enhanced SVD Method estimates shape and motion only up to arbitrary translations and rotations. Figure 5.1 shows these solutions without the translations. The red corresponds to the truth solution while the blue corresponds to the calculated solution. As can be seen, the calculated solution is a rotated version of the truth solution. They align exactly when multiplied by a rotation matrix. 61 Figure 5.1: Shape and Motion Solutions 5.2 Sample Motion The same target illustrated in Figure 2.8 and Figure 2.9 is used for further simulations. In order for the Phase-Enhanced SVD method to work, the target must have three-dimensional motion. Therefore, turntable geometry can no longer be considered since it is two-dimensional. The target’s motion is given by (2.17) and (2.18), with θ(t) and φ(t) as in (2.13) and (2.14). For the examples throughout this chapter and the next, the specific threedimensional motion is characterized by the following parameters, in radians. κ=1 π θp = 18 π φp = 18 π ψ= 18 This yields the motion shown by the red solution on the right hand side of Figure 5.1. 62 5.3 5.3.1 Imperfect Correlation Simulating Imperfect Correlation Range, range-rate, and phase information taken from radar data will in general not be correlated. Without scatterer correlation, an ideal reconstruction such as the one in Figure 5.1 cannot be obtained. It is useful to examine the effects of imperfect scatterer correlation. We first simulate imperfect correlation as showin in Figure 5.2. Data that is 90% correlated has 10% of its rows randomly mixed up, data that is 80% correlated has 20% of its rows randomly mixed up, and so on. Figure 5.2: Varying Levels of Scatterer Correlation This is done as follows. For data that is p% correlated, (100 − p)% of its rows L) rows need to be rearranged. Since there are L rows, this means that round( 100−p 100 need to be rearranged. So for each n, n = 1 . . . round( 100−p L), row 100 round 100 n 100 − p is randomly rearranged. This is shown for p = 80 in Figure 5.3. For simplicity, only four scatterers are used here. This is a way to easily simulate varying levels of uncorrelation and will be useful in examining its effects. However, it is not a good representation of how data would realistically be uncorrelated. The radar observables range, range-rate, and delta phase are extracted from range vs. range-rate images such as Figure 2.5. They are extracted using peakfinding algorithms such as the one described in Section 2.6. The peak values found at each aspect are inserted into rows of the three data matrices. As the viewing 63 Figure 5.3: Uncorrelated Extracted Radar Observables, p = 80 aspect changes, the scatterers are viewed in different orders, which causes changes in the order of the peak scatterer values. This is shown in Figure 5.4. These are plots of the three radar observables extracted using the peak-finding algorithm. The random rearrangement of the order of scatterers is easily seen. For clarity, we will refer to the aspects at which these rearrangements occur as jump locations. Since all three radar observables are extracted simultaneously from each peak, all their jump locations are the same. Figure 5.4: Uncorrelated Extracted Radar Observables Notice that some outlying points now occur. When using the peak-finding algorithm, points are sometimes recorded in erroneous locations. Also notice that phase ambiguities still occur here. There is no way around this. The two extracted phase values at every aspect each lie within the interval [−π, π]. Because of this, taking their difference to arrive at the delta phase variable will inherently result in a value that lies within the interval [−2π, 2π]. This results 64 in phase jumps of size ±2π in the delta phase variable, in addition to the other jump locations already there from the peak-finding algorithm. Using this information, a much more realistic method of simulating uncorrelated data can be employed. I developed and implemented an algorithm to automatically uncorrelate data in this manner. The algorithm uses a set number of jumps to uncorrelate the data, which can be changed if desired. It picks two tracks at random to be switched. It picks a third track to be switched with probability 0.5 and a fourth track to be switched with probability 0.25. Once all tracks to be switched have been determined, it switches them in a random order. The probabilities and the number of tracks to be switched can easily be changed in the algorithm. Uncorrelated radar observables resulting from this algorithm are illustrated in Figure 5.5. Figure 5.5: Uncorrelated Truth Radar Observables with Random Jumps 65 5.3.2 Effect of Imperfect Correlation Figure 5.6 shows the effect of different levels of correlation where data was uncorrelated by varying percentages. The shape estimate for the 100% correlated case is the correct shape, while the other two are skewed. The motion estimate for the 100% correlated case is the correct motion, while the other two include random clouds of extraneous points from the points that aren’t correlated. All points here are direct outputs of the PESVD algorithm. The seemingly continuous lines in the motion estimate are the correctly calculated motion trajectory, while the points in the cloud around it are incorrect points resulting from extraneous points in the initial data. Figure 5.6: Shape and Motion Estimates for Varying Correlation Percentage Levels 66 Recall from the SVD method that the first three singular values of the matrix A obtained from the initial SVD of the data are ideally the only nonzero singular values of A. This is true when the data is correlated. In order to examine the ideally zero singular values, a target with more scatterers must be used to simulate data so that there are more singular values to look at. A 13-scatterer target was used here. Shown in Figure 5.7 are the distributions of the singular values for varying correlation levels of the initial data. As the data becomes less correlated, the ideally zero singular values steadily increase. The correct correlation is the only set of data that results in the fourth through last singular values being zero, as is desired. Figure 5.7: Singular Value Distributions for Varying Correlation Percentage Levels Figure 5.8 shows the effect of different levels of correlation where data is given with different numbers of jumps. As before, the data with no jumps gives the correct shape and motion estimates. As more jumps occur in the data, the shape estimate becomes worse and the motion estimate ends up with corresponding jumps. Figure 5.9 gives the singular value distributions when increasing numbers of jumps are added to the data. As can be seen, the ideal singular value structure occurs when there are no jumps (100% correlation), then the structure becomes worse as more jumps (more uncorrelation) occur. 67 Figure 5.8: Shape and Motion Estimates for Varying Correlation With Jumps Figure 5.9: Singular Value Distributions for Correlation With Varying Numbers of Jumps 68 5.4 Added Noise 5.4.1 Simulating Added Noise The author devised two different ways to add noise to the radar observables. It should be noted that the only type of noise considered here is noise induced during processing, not noise present pre-processing. This noise results from errors in extracting the radar observables from range vs. range-rate images such as 2.5. 5.4.1.1 The Percentage Method. We first simulate data with p% noise, where p% noise is interpreted as additive white noise where p ||Noise|| ≈ . ||Data|| 100 Each of the three radar observables data matrices are of size L × S, where L is the number of aspects and S is the number of scatterers. All three radar observables are real-valued. We seek to add noise by way of percentages. For example, to add 10% noise to a data matrix, we will multiply each value in the matrix by a random number within the interval [0.90, 1.10]. In this way, the noisy data value will be at least 10% smaller and at most 10% larger than its truth value. We calculate the formula that should be multiplied by each data matrix in in order to add p% noise. The desired formula must yield an interval, such as [0.90, 1.10], that is symmetric and centered about 1. We first find the formula that yields a symmetric interval centered about 0, scale it so that the desired percentage is achieved, then shift it to be centered about 1. In MATLAB, the quantity rand(L, N ) yields an L × N matrix whose elements are numbers randomly chosen from the standard uniform distribution on the open interval (0, 1). Then the quantity 2 rand(L, N ) − 1 (5.6) 69 gives numbers randomly chosen on the interval (−1, 1), which is symmetric about 0. Scaling this interval to achieve the desired percentage yields p (2 rand(L, N ) − 1), 100 which gives numbers randomly chosen on the interval − p p , . 100 100 To ensure the interval is centered about 1, we add 1, p (2 rand(L, N ) − 1) 100 100 − p p = + rand(L, N ). 100 50 1+ (5.7) This shifts the interval to p p 1− ,1 + . 100 100 Multiplying the truth data by (5.7) will add noise of size p. This yields the formula Noisy Data = p 100 − p + rand(L, N ) × Data, 100 50 (5.8) where the matrix multiplication is performed element-by-element. An example of truth radar observables data with 15% noise added is shown in Figure 5.10. Figure 5.10: Truth Radar Observables with p = 15 70 The author initially chose this method of adding noise because it works well for data that is on different scales. If noise was instead added by adding random values to the data, it would be difficult to ensure that noise of comparable magnitude was added to all three radar observables. For example, for the shown data, the delta phase variable varies on [−2π, 2π], while the range-rate variable varies on [−1, 1]. Adding random values on [−1, 1] to the range-rate data would add noise that is approximately equal in magnitude to the data itself, so around 100% noise. Adding random values on [−1, 1] to the delta phase data, however, would add noise that is about 32% of the magnitude of the data. One drawback to this method, however, is that for each individual radar observable, more noise is added to data values of greater magnitude than is added to data values of smaller magnitude. This is apparent in 5.10. The tracks become noisier the greater in magnitude they are. This is not a realistic effect. 5.4.1.2 The Extraneous Points Method. We now look at another method of adding noise to data. As is somewhat noticeable in Figure 5.4, sometimes noise appears in the form of data points randomly being recorded at the wrong location. This results in most of the data being at the correct locations, but random points being randomly offset. These points will be referred to as “extraneous” points. This implementation is very simple. Tracks are chosen at random and extraneous point locations are chosen at random. For each track at each chosen location, a number chosen randomly using (5.6) is added to its value. An input to the algorithm is the number of extraneous points to be added to the data. Figure 5.11 shows radar observables after noise is added using the extraneous points method. 71 Figure 5.11: Truth Radar Observables with Extraneous Points 72 5.4.2 Effect of Added Noise 5.4.2.1 The Percentage Method. Figure 5.12 shows the shape and motion estimates for data with varying percentage levels of noise. Reasonable quantities of added noise don’t seem to have much effect on the shape estimate, however, this blurs the motion estimate. Figure 5.12: Shape and Motion Estimates for Varying Percentage Levels of White Noise Figure 5.13 is a graph of the singular value distributions with increasing percentages of added noise. As predicted, the singular values become increasingly erroneous as increasing percentages of noise are added. 73 Figure 5.13: Singular Value Distributions for Varying Noise Percentages 5.4.2.2 The Extraneous Points Method. We now undergo the same analysis for our other method of adding noise, adding extraneous points to the data. Figure 5.14 shows the shape and motion estimates for data with increasing percentages of extraneous points. The motion estimates are simply rotated versions of each other; the change in scale is needed to accommodate the extraneous motion points. It is important to notice the distinction between the percentages here and the percentages used in Figures 5.12 and 5.13. Previously, data with n% noise was data with noise added of size n% of size of the data, so each noisy point is still a good rough estimate of its corresponding truth point. Here, n% noise means that n% of the points have been moved to be at completely erroneous locations, so each noisy point is in no way guaranteed to be a good estimate of its corresponding truth point. This is why the errors in Figure 5.15 appear to be larger than the errors in Figure 5.13. In reality, both methods of adding noise give similar results for how added noise affect estimates of shape and motion. 74 Figure 5.14: Shape and Motion Estimates for Varying Levels of Extraneous Point Noise 75 Figure 5.15: Singular Value Distributions for Varying Percentages of Extraneous Points CHAPTER 6 Correlation Algorithms We have demonstrated that the PESVD method works very well when given data that is correctly correlated. The goal here was to devise a method that would work on correlated data, but to also minimize the need for scatterer correlation. We do not consider the case of shadowing, also known as disappearing or occluded scatterers, in this work. Occluded scatterers are scatterers that can’t be seen at a given aspect because they are being blocked by other scatterers. This case is currently being pursued by other researchers. We only consider the case where all data is known, but it is uncorrelated in a realistic way and has noise. We devise two methods of correlating data so that uncorrelated data can be used in the PESVD method with much better results. We consider each method first without noise, then with the addition of reasonable amounts of noise. It should be noted that these algorithms can be used to correlate data that can then be used in any imaging algorithm, not just the PESVD method. 6.1 6.1.1 Iterative Algorithm Motivation Recall the effect of imperfect correlation as presented in Section 5.3.2. Figures 5.7 and figure 5.9 help to illustrate the effect of imperfect correlation. These figures both show that the correct correlation for a given set of radar data results in a simple, predictable singular value structure; all singular values after the first three are equal zero. This agrees with Lemma 1. The additional information obtained from these figures is that imperfect correlation affects this singular value structure in a predictable and easily recognizable way. In general, the less correlated a data set is, the greater its ideally nonzero singular values will be. Only one correlation, the correct one, will result in the ideal singular value structure. This observation was the author’s motivation to exploit this known singular 76 77 value structure in order to develop an iterative correlation algorithm that chooses the “best” correlation for a set of data. This section explains the development of the iterative algorithm based on the above observation. A theoretical justification is later provided in 6.3. 6.1.2 Large Number of Scatterers Without Noise We consider truth data uncorrelated as in Figure 5.5, but with a larger number of scatterers. Tracks can quickly become indistinguishable in this case, be it from overlapping, noise, or both. Since all three radar observables need to be correlated but correlating one correlates them all (besides phase jumps in delta phase), we will only include figures of the ranges to illustrate the algorithm. Figure 6.1 shows uncorrelated range data simulated from a target with 13 scatterers. Each black dot indicates where a track jumps. Figure 6.1: 13 Scatterer Data Uncorrelated with Jumps In the absence of a direct way of correlating the data, one method could be to examine every possible correlation that the data could have and choose the best one based on some criteria. Since this data has 13 tracks (corresponding to 13 78 scatterers) taken over 1441 aspects, the total number of possible ways the data could be arranged would be 131441 . It is clearly impossible to test every one of this enormous number of correlations. Since a brute force method is not feasible, we look for a way to cut down the number of possible correlations based on what we know about the data. What we know is • The peak-finding algorithm records scatterers in the same order across aspects until jumps occur, so the “chunks” of data in between jumps are already correlated. • At each aspect, it is fairly simple to identify which tracks have jumped based on range differences. If two tracks happen to switch while intersecting so that there is no noticeable difference in range, the jump can still be identified by range-rate differences at that same location. This means that even if the ranges intersect, they’ll have different slopes so a jump will easily be detected in range-rate. This fact was used by Mark Stuff in [5]. • At each jump location, the correct correlation is already known for the tracks that don’t have jumps; only the tracks with jumps will yield different correlation possibilities. • At each aspect where jumps occur (called a jump location), if n jumps occur, there are n! possible ways the data can be correlated after the jump. Using these known facts to our advantage will significantly reduce the number of possible correlations of the data. The algorithm will first explicitly list all possible correlations. For each possible correlation, it will reorder each jump in the data so that every jump is in the order specified by the given correlation. The PESVD method will then be applied to the reordered data matrix and the singular values recorded. After this has been done for each possible correlation, the correlation that yielded the closest to ideal singular value structure will be chosen as the best possible correlation. The algorithm is as follows. 79 1. The data is first stepped through in order of increasing aspect. If a jump occurs of a size over a given threshold in either range or range-rate, the location is marked as a jump location, k. The aspect at which the jump occurs is recorded, along with the indices of the tracks which had jumps. The total number of jumps at the k th jump location is referred to as mk . 2. The total number of possible correlations is calculated by multiplying the total possible number of permutations at each aspect. This is done through the formula N= K Y mk !. k=1 For example, for the data shown in Figure 6.1, we have N = 2! × 2! × 2! × 2! × 3! = 96. Clearly, this is a much more manageable number of correlations to examine than 131441 . The reason we consider permutations of every jump in the data simultaneously instead of examining one at a time is that the criterion used in the method is the singular values. The singular values come from the SVD of the data matrix resulting from permuting every jump in the data, so considering one jump location at a time would not be useful. 3. List out every possible correlation to be tested in to a matrix, C. The matrix will have N rows, so that each row gives one of the N possible correlations. The matrix will have K columns, so that each row gives one way in which the tracks can be permuted at each of the K jumps. Each element in the k th column will be chosen from the interval [1, mk !], since mk ! is the total possible number of correlations resulting from each jump. Note that we are only listing permutations resulting from the K jump loca- 80 tions, instead of K + 1 permutations resulting from the K + 1 “chunks” of data that K jump locations divide the data into. This is because we’ll take the order in which the data initially appears as being the correct correlation, then find the permutations of the subsequent data that returns it to the correct correlation. This is shown in (6.1), c11 . . . c1K c21 . . . c2K C= . .. .. . cN 1 . . . cN K , (6.1) where the nth column gives the nth possible correlation and where the entry representing the k th jump location of the nth correlation, cnk is contained in the interval cnk ∈ [1, mk !]. (6.2) For example, if only two tracks switch at jump k, then each element in the k th column can only be chosen from the interval [1, 2!], which makes sense because two tracks can only be arranged in two ways; they can stay in the same order or they can switch. If three tracks switch at jump k, then each element in the k th column will be chosen from the interval [1, 3!], so the three tracks can be rearranged in six ways. These cases are shown in Figure 6.2. The values Pk will be explained in the next step. As another example, for the data shown in Figure 6.1, the matrix C will be 96 × 5 and look like Figure 6.3. Here we have included the tracks below the matrix to clarify where the entries come from. Again, the matrices below the tracks will be explained in the next step. The matrix C is formed in MATLAB as follows. The algorithm randomly selects a number from each of the K intervals to form a sequence of K numbers. If this sequence is not already in C, it is appended to C as a new row. If this sequence is already in C, it is not appended to C and the algorithm continues to the next sequence. This continues until C has been completely filled to size N × K. 81 Figure 6.2: 2 and 3 Jump Cases Note that this method of populating C is not an explicit method. The problem of explicitly enumerating each individual correlation is not a simple one. The method of doing it randomly is fast, easy, and avoids this issue. For problems of a much larger magnitude, it could be possible that a method of explicitly enumerating them would be faster. That case is not explored here. 4. The algorithm tests each of the N possible correlations. For a given correlation, it loops through each jump location. At the k th jump location, it forms the matrix P of all the possible ways the jump can be permuted. If only two tracks switch at a jump location, the matrix is P2 = 2 1 1 2 . This means that for any two tracks (T1 , T2 ), their two possible new orders are (T2 , T1 ) and (T1 , T2 ), which is very straightforward. If three tracks switch at a jump location, the matrix becomes 82 Figure 6.3: Matrix C of All Possible Correlations P3 = 3 2 1 3 1 2 2 3 1 . 2 1 3 1 2 3 1 3 2 The rightmost column in Figure 6.2 shows these Pk matrices with their corresponding [1, mk !] intervals. The mk ! rows of each Pk give the mk ! possible 83 permutations of each jump location. Also, the Pk matrices under the tracks in Figure 6.3 are the matrices resulting from the data shown in Figure 6.1. At the nth correlation and k th jump location, the number cnk will give the row of P that should be chosen as the new way to order the tracks after the jump, i.e., the new order is given by P (cnk , :). The number cnk will be in the interval [1, mk !] and will determine which one of the mk ! rows of Pmk is to be used, i.e., we use the cnkth row of P . The tracks are then reordered. The matrix that stores the list of tracks that switch at each jump location then must be updated, as reordering tracks will switch how they are referenced at the next jump location. This is done for each of the K jump locations. Afterward, the Phase-Enhanced SVD algorithm is used on the reordered data. The singular values from the SVD are saved. The algorithm moves on to the next correlation and repeats the process. 5. The singular values were saved from each of the N possible correlations. Figure 6.4 shows what the singular value distributions look like for the data shown in Figure 6.1. The black dots represent the truth singular values. Figure 6.4: Singular Value Distributions from 13 Scatterer Data 84 We now choose the best correlation, where the best correlation is defined as the correlation that results in the best singular value distribution. The singular value distribution that gives the smallest sum of the ideally nonzero singular values is chosen and used to identify the correct correlation. The data is then reordered one last time, in the order given by the chosen correlation. The new correlation is shown for the data shown in Figure 6.1 in Figure 6.5. As can be seen, this method correctly correlates the data. Figure 6.5: 13 Scatterer Data Uncorrelated with Jumps then Correlated with Iterative Algorithm 85 6.1.3 Large Number of Scatterers With Noise We now demonstrate that the algorithm can be used on uncorrelated data with noise in the form of extraneous points as in Figure 6.6. This form of noise is more realistic than noise added by the percentage method, so we only explore this case here. Figure 6.6: 13 Scatterer Data Uncorrelated with Jumps and Extraneous Points A fairly simple addition to the algorithm is used to accommodate noise of this form. In step 1 of the algorithm, jump locations are only actually recorded if more than one jump occurs at them. This ensures that a reasonable number of jump locations are recorded. If only one jump occurs at a jump location, the location is easily identified as having an extraneous point instead of a track switch, so there is no need to record it. In the unlikely case that two extraneous points occur at one jump location, that jump location will then be saved and included in the correlation algorithm. This won’t adversely affect the algorithm, it will just make it take slightly longer. The algorithm then proceeds exactly as before. Figure 6.7 shows what the singular value distributions look like for the data shown in Figure 6.6. Due to the extraneous points, none of the singular value distributions will have the ideal structure. However, as before, selecting the singular value distribution 86 Figure 6.7: Singular Value Distributions, Noisy Data that gives the smallest sum of the ideally nonzero singular values still gives the best possible correlation. Selecting that correlation here and rearranging the data in the specified order results in Figure 6.8. As can be seen, the data has been given the correct correlation. The few extraneous points will affect the shape and motion estimate in the manner described in Section 5.4.2. This is a very reasonable number of extraneous points, though, so a very good shape and motion estimate will result from this. 87 Figure 6.8: Data Uncorrelated with Jumps and Noise then Correlated with Iterative Algorithm 88 6.1.4 Large Number of Scatterers With Phase Ambiguities Without Noise Suppose now that the uncorrelated data we are trying to correlate also has phase ambiguities, as is unavoidable in real data. An example of such data is shown in Figure 6.9. Figure 6.9: Uncorrelated Data With Phase Ambiguities Removing phase ambiguities here is not trivial. Proceeding as in the previous section and initially ignoring the phase jumps so that the data can be correctly correlated before resolving phase jumps is an option, but means that no singular value distribution will give the ideally zero structure, since all singular value distributions will have added errors due to the phase jumps. We instead proceed in a way that will seek to minimize the errors added to all the singular value distributions. After step 1 in the iterative algorithm, we will impose a simple constraint to get rid of the majority of the phase jumps. If a jump of greater than 1.75π occurs, the jump is assumed to be a 2π phase jump and ±2π is added to the value at the jump to map it back to the point closest to the previous point. This will resolve all phase ambiguities besides the ones arising after track switches. The delta phase variable after this constraint is shown in Figure 6.10. The rest of the algorithm is then executed as before. The singular value distributions resulting from it are shown in Figure 6.11. As can only barely be seen here, the small amount of error incurred by the phase ambiguities remaining in the delta phase variable barely affect the singular value distributions at all. The algorithm still picks the correct correlation. At the 89 Figure 6.10: Delta Phase after Phase Constraint end of the algorithm, the same phase constraint as before is applied. Now, the remaining ambiguities will not be affected by track switches. This correctly resolves the rest of the ambiguities and results in the correct delta phase variable, as seen in Figure 6.12. 90 Figure 6.11: Singular Value Distributions from 13 Scatterer Data With Phase Ambiguities Figure 6.12: Delta Phase after Iterative Algorithm Using Phase Constraint 91 6.1.5 Large Number of Scatterers With Phase Ambiguities, Noise, and Filtering We now demonstrate that the same algorithm can be used on data with both phase ambiguities and noise. The few extraneous points in the data after correlation can be smoothed out using median filtering. We use the data shown in Figure 6.13. Figure 6.13: Uncorrelated Data With Phase Ambiguities and Noise After imposing the phase constraint, delta phase improves as shown in Figure 6.14. Figure 6.14: Delta Phase With Noise after Phase Constraint The singular value distribution structure, shown in Figure 6.15, includes more 92 errors than before, as is shown by the ideally nonzero singular values being significantly farther from zero. However, the correct singular value distribution is still chosen as the one that minimizes these values. Figure 6.15: Singular Value Distributions from 13 Scatterer Data With Phase Ambiguities and Noise This results in the correct correlation being applied to the data. The phase ambiguities have been correctly resolved, as shown in Figure 6.16. The data was filtered using simple 1D median filtering in MATLAB that smooths out outlying points in all three radar observables. As can be seen, the iterative algorithm correctly correlates data that has phase ambiguities and reasonable levels of noise. The three correlated radar observables after applying the algorithm are shown in Figure 6.17. 93 Figure 6.16: Delta Phase with Noise after Iterative Algorithm Using Phase Constraint and Filtering Figure 6.17: Radar Observables Correlated with Iterative Algorithm 94 6.2 6.2.1 Nearest Neighbor and Slope Algorithm Small Number of Scatterers Without Noise When fewer scatterers are present, the iterative algorithm cannot be used. This is because there aren’t enough singular values after the first three to analyze, so examining the SVD structure is not useful. We develop a non-iterative algorithm that will perform faster than the iterative algorithm. With a smaller number of scatterers, it will be possible to go through the data sequentially and determine which tracks need to be switched where without testing every possible correlation. This method seems to be a natural way one would go about correlating data. We consider the case of four scatterers that are uncorrelated with random jumps via the algorithm discussed previously. We notice that, again, the data already has all three radar observables coupled so that finding the correct correlation of one radar observable will give the correct correlations for the others, besides phase ambiguities. Due to this we will again just show images of the ranges, until phase ambiguities are discussed. The algorithm is as follows. We begin with just correlating the ranges, then handle the delta phase variable separately to deal with the phase ambiguities. We start with the uncorrelated range data shown in Figure 6.20. This data has three jump locations. 1. We begin by identifying the jump locations. These are recorded whenever there is a jump over a given threshold size in either range or range-rate. For example, if two range tracks intersect and the track switch occurs right at the intersection, a jump location would not be detected in range, since the ranges would be approximately equal. However, their slopes would be different, so checking for a jump in range-rate at that same location would ensure that the jump is identified. Figure 6.19 shows correctly identified jump locations. Along with the jump locations, the track numbers that have jumps are recorded at each location and stored in a matrix for later reference. 2. At each jump location, a simple nearest neighbor algorithm is used to deter- 95 Figure 6.18: Uncorrelated Range Data mine which tracks go together. Each track before the intersection is matched with the track after the intersection that gives the smallest track jump between them. If the jump was detected in range-rate instead of range, the nearest neighbor algorithm is used on range-rate instead of range to correctly switch the tracks. After tracks are switched, the matrix identifying the tracks that jump at each jump location is updated to account for the newly ordered tracks. Applying this simple algorithm results in the data being correctly correlated, as shown in Figure 6.20. 96 Figure 6.19: Range Data After Step 1 Figure 6.20: Range Data After Step 2 97 6.2.2 Small Number of Scatterers With Noise and Phase Ambiguities We consider the case of uncorrelated data from four scatterers with extraneous points. This is a more realistic form of how data would look when extracted using the peak-finding algorithm, for example, as in the data shown in Figure 5.4. We begin with the uncorrelated data shown in Figure 6.21. This data has three jump locations and six extraneous points. Figure 6.21: Uncorrelated Range Data with Extraneous Points We notice that in this case, the previous algorithm is not practical. Each extraneous point would be wrongly recorded as a jump location and the nearest neighbor method would not work. In the case of noise in the form of extraneous points, the algorithm must be modified. The algorithm is as follows. We again begin with just correlating the ranges, as the data is coupled so all three radar observables can be correlated through this. 1. We begin by stepping through all aspects of the ranges. At each aspect, each point is matched up with the point from the previous aspect that is closest to it using a nearest neighbor algorithm. This is depicted in Figure 6.22. We do this because we know that in the presence of noise, it will be much harder to step through the data and handle each jump location individually 98 Figure 6.22: Range Data After Step 1 up front. Notice that if the extraneous points were not present, this step would correctly correlate the data besides track switches at intersections. The extraneous points result in the tracks not being correctly matched up. This step guarantees that all jumps are now either from intersections being incorrectly switched or from extraneous points. 2. The next step is to identify intersections. This is easy for the human eye, but tricker to automate. We start by again stepping through each aspect of the updated ranges. At each aspect, if any two tracks are less than a given threshold apart, a counter is started to measure at how many aspects the tracks remain close together. This window is used to prevent false intersections from being found due to noise. The intersection is found to have ended when the tracks are sufficiently apart. Let P denote the length of the intersection. This is illustrated in Figure 6.23. The center of the intersection is approximated to be at P k − round( ), 2 where k is the aspect at which the intersection ends. 99 Figure 6.23: Identifying an Intersection 3. We now must determine whether or not the tracks at each intersection should be switched. Range information alone is not enough to determine this, since these intersections occur where the ranges are approximately equal. Based on this, an easy way to determine an intersection needs to be switched would be just to search for a jump in range-rate. In the case of noise-free data, this would work. However, a condition depending on data from just one aspect is risky in the case of noisy data. Just one extraneous point could cause the algorithm to not resolve an intersection. Due to this, we examine the range-rates throughout a window about the intersection. We let S denote the length of data to be used on either side of the intersection, so that a total window of size 2S is used about the intersection. An intersection that needs its tracks switched and the corresponding rangerates are showed in Figure 6.24. No jump is seen in range, but a jump is seen in range-rate. The length 2S window about the intersection is seen in the figure. Let C and D be the length 2S vectors of range-rates corresponding to the 100 Figure 6.24: Analyzing an Intersection tracks intersecting in range centered at k − P2 as in Figure 6.24. Let C1 denote the first S elements of C and C2 denote the second S elements of C, and similarly for D. The basic criteria we want to use is that the intersection will be switched if C1 is closer to D2 than it is to C2 . Mathematically, if the condition ||C1 − D2 || < ||C1 − C2 || (6.3) is met, then the tracks at the intersection are switched. Note that using just this one condition is not foolproof. Just a few extraneous points in the range-rates could throw off the condition. Due to this, we seek to impose another condition in hopes that noise will not affect both. Theoretically, the range-rates are the exact derivative of the ranges. Another way to analyze the range-rates would be to actually compute the slope of the ranges. For each aspect j ∈ [2, 2S], we let E(j) = A(j) − A(j − 1) 101 and F (j) = B(j) − B(j − 1). So E and F are scaled versions of the derivative of range as computed by its definition. We seek to smooth any great discontinuities by assuming that the derivatives are linear about the intersection and thus fitting a first order polynomial to both E and F . This is done here using MATLAB’s “polyfit” function. Let Ê and F̂ denote the smoothed vectors formed from fitting first order polynomials to E and F , respectively. This gives the second slope condition. Let Ê1 denote the first S elements of Ê and Ê2 denote the second S elements of Ê, and similarly for F̂ . If the condition ||Ê1 − F̂2 || < ||Ê1 − Ê2 || (6.4) is met, then the tracks at the intersection are switched. Here this condition is exactly the same as (6.3), but it is a condition on the computed derivative instead of the recorded range-rates. Applying these two slope conditions is advantageous since either condition could be compromised by noise, but it is less likely that both will be compromised by noise at the same time. Applying these conditions correctly switches intersections, as shown in Figure 6.25. However, sometimes some are or are not correctly switched depending on how large S is chosen to be. 4. The track switches resulting from extraneous points have still not been corrected. We then impose a simple condition that if two tracks jump a significant amount at a given aspect, it most likely came from an extraneous point and the tracks are switched. This results in these switches being correctly resolved, as is shown in Figure 6.26. This process also simultaneously correctly correlates range-rate and delta phase. Figure 6.27 shows delta phase after this step. The jumps in correlation have been corrected, but the 2π phase ambiguities still remain. 102 Figure 6.25: Range Data After Step 3 5. We now focus on the 2π phase ambiguities in the delta phase variable. Now that correlation has been taken care of, the phase jumps should occur only for each individual track, instead of the tracks jumping in phase and also switching. This makes resolving the phase ambiguities much simpler. The delta phase variable at this point is given by Figure 6.27. Recall that in Section 3.6.4, phase ambiguities were easily resolved using a target space filtering approach. This was for the phase-enhanced 3D snapshot imaging algorithm, where targets were reconstructed in actual target coordinates. Here targets are reconstructed in arbitrary coordinates, so we don’t have any prior knowledge of where the target will be and how to filter accordingly. Because of this, another method must be employed. First, each track is stepped through individually. If a jump of greater than 1.75π occurs, the jump is assumed to be a 2π phase jump and ±2π is added to the value at the jump to map it back to the point closest to the previous point. Along with this, we apply simple 1D median filtering to the data to smooth it. This gets rid of sporadic extraneous points in all three radar observables. 103 Figure 6.26: Range Data After Step 4 The delta phase variable has been corrected, as shown in Figure 6.28. 6. One thing that sometimes occurs is that an entire track is mapped too high or too low due to phase ambiguities, as in Figure 6.29, taken from actual data extracted using the peak-finding algorithm. Because of this, we impose a check at this point. If any individual track has mean greater than 1.5π or less than −1.5π, then −2π or 2π is added to that track so that it gets mapped back to its correct location. After all steps of the algorithm, the data is correctly correlated. This is seen in Figure 6.30. 104 Figure 6.27: Delta Phase Data Before Step 5 Figure 6.28: Delta Phase Data After Step 5 105 Figure 6.29: Track Displaced Due to Phase Ambiguity Figure 6.30: Radar Observables Correlated Through Algorithm 106 6.3 Proof of Theorem Justifying Iterative Algorithm As is suggested in the previous section, it seems that uncorrelated data will always have more than three nonzero singular values. We now prove that this is true. We first state three important lemmas that will be useful in the proof. Lemma 1 [11]. Let A be a matrix of correlated radar range data and write the SVD of A as A = QΣV T. (6.5) If the column rank of the shape matrix r is three and the span of the columns of the motion matrix k̂ is also three (where A = r k is the desired factorization), then A has three nonzero singular values so that Σ is 3 × 3. These conditions on the shape and motion matrix mean that the target must be three-dimensional and is motion must also be three-dimensional. Lemma 2 [14]. Let A ∈ Rm×n be a matrix with rank(A) = r ≤ min(m, n) and Π a permutation matrix such that the first r columns in A Π are linearly independent. Then the QR factorization of A Π will have the form A Π = (Q1 Q2 ) R11 R22 0 0 (6.6) where R11 ∈ Rr×r is upper triangular with positive diagonal elements. Furthermore, the matrices Q and Q form orthogonal bases for the range of A and the null space 1 2 of AT , respectively. The rank of A is r and the null space of AT has rank m − r, so (Q1 Q2 ) has rank m. Lemma 3 [15]. The rank of a matrix A is r, the number of nonzero singular values. Lemma 4 [16]. Let A and B be p × n and p × q matrices, respectively, and [A, B] denote a row block matrix obtained by putting A and B side by side. Then, rank(A) + rank(B) − rank([A, B]) ≤ min(rank(A), rank(B)) (6.7) 107 We prove the following theorem. Theorem. A matrix of radar observables data is uncorrelated if and only if it has more than three nonzero singular values. Proof. Backward: We must show that more than three nonzero singular values implies uncorrelated data. This statement is the contrapositive of Lemma 1. Forward: Let A be an L × N matrix of correlated radar observables data, where L is the number of aspects and N is the number of scatterers. Then each entry aij is the range of the j th scatterer at slow time index i. The data is correlated as shown in Figure 2.11. Assume that the radar observables data results from a target with at least four scatterers, and that the scatterers do not all lie in the same plane so that the target is three-dimensional. Assume that there are more aspects than there are scatterers, so that N < L. By Lemma 1, we know that A has only three nonzero singular values. Then by Lemma 3, A has rank three. We first multiply A by a permutation matrix Π that reorders the columns of A so that the first three are linearly independent, say A Π = Ã. Since A has rank three, à also has rank three. Consequently, all columns of à can be written as a linear combination of the first three columns. Note that the permutation Π does not affect the correlation, since entire columns, not parts of columns, are switched. We take the reduced QR factorization of Ã, à = Q R, as shown below. ã11 . . . ã1N .. .. . ... . .. .. . ... . ãL1 . . . ãLN = q11 . . . q1N .. . . . . . .. .. . . . . . .. r11 r12 r13 . . . . . . r1N r22 r23 . . . . . . r2N r33 . . . . . . r3N (6.8) qL1 . . . qLN Here we have used Lemma 2 which shows that rij = 0 ∀ i > 3. The blank entries of R are equal to zero. Also by Lemma 2, the rank of Q resulting from the full QR factorization would be L. However, since this is a reduced QR factorization, Q has rank N . 108 The first three columns of Q form an orthonormal basis for the column space of Ã, and span(q1 , q2 , q3 ) = span(ã1 , ã2 , ã3 ), where ãj and qj denote the j th columns of à and Q, respectively. We know that it is necessarily the first three columns that this applies to because of the multiplication by the permutation matrix Π above. In other words, any column of à can be written as a linear combination of the first three columns of Q. The coefficients of these linear combinations are given by the corresponding entries of the matrix R. Consistently with Lemma 2, no nonzero entries are needed in R below the first three rows. If à had full rank, its QR factorization would be unique as long as we require that rjj > 0, 1 ≤ j ≤ n. Since à is rank-deficient, more than one QR factorization will be possible. By Lemma 2, the rank of R resulting from these QR factorizations will reveal the rank of Ã. For full rank matrices, “revealing rank” means that the R resulting from the QR factorization has all zero rows below some index, and that index is the rank. For rank-deficient matrices such as Ã, “revealing rank” means that the number of linearly independent rows of R will equal the rank of Ã. Recall how the elements of Q and R as arise from Gram-Schmidt orthogonalization [15]. The column vectors qj , 1 ≤ j ≤ N are given by ã1 r11 ã2 − r12 q1 q2 = r22 ã3 − r13 q1 − r23 q2 q3 = r33 .. . q1 = qn = ãn − Σn−1 i=1 rin qi . rnn (6.9) The coefficients rij are given by rij = q∗i ãj (i 6= j), (6.10) 109 and the coefficients rjj are given by |rjj | = ||ãj − Σj−1 i=1 rij qi ||2 . (6.11) Since the radar observables data results from a target with at least four scatterers, A has at least four distinct columns. It is not possible that any two columns of A will be equal. This is because if two columns were equal, they would have to have resulted from two scatterers that were at exactly the same range during the entire data collection period, in which case the radar would pick them up as one scatterer anyway. Individual values in separate columns will be equal when range tracks intersect, but no two columns will be identical. Consequently, we are guaranteed that any two columns, ãk and ãm , k < m, are not equal. Ensure that n has been chosen such that the nth entries of ãk and ãm are not equal. This means that the nth look aspect corresponds to a view at which the scatterers recorded in the k th and mth columns are not at equal range, so their range tracks are not intersecting. 6.3.1 Case Two Scatterers Switch We consider the case where two scatterers switch at a given aspect here. The case where more than two scatterers switch at a given aspect is discussed in the next section. Switch the nth element of ãk , ãnk , with the nth element of ãm , ãnm . We define the correct correlate to be the ordering in the first row, so we choose n such that 0 n > 1. The uncorrelated matrix resulting from this switch, à , is given by ã11 . . . ã1k . . . ã1m . . . ã1N .. .. ã21 . . ã2N .. .. . ãnm ãnk . .. .. .. .. . . . . ãL1 . . . ... ... 0 ... . (6.12) . . . ãLN Here we have kept the elements of à in terms of the original elements of Ã. We 110 examine how the switch of ãnk and ãnm affects the structure of the matrices Q0 and 0 R0 resulting from the QR decomposition of à . Case k > 3, m > 3 : 0 The first k − 1 columns of à and à are identical. By (6.9), we see that the definitions of qj , 1 ≤ j < k depend only on the first k − 1 columns of Ã. Therefore, the first k − 1 columns of Q0 are equal to the first k − 1 columns of Q. Explicitly, we have q0i = qi , 1 ≤ i < k. (6.13) 111 0 Using (6.13), we can write the QR factorization of à as ã11 . . . ã1k . . . ã1m . . . ã1N .. .. ã21 . . ã2N .. .. . ãnm ãnk . .. .. .. .. . . . . ãL1 . . . q11 q12 = q21 q22 q31 .. . q32 .. . × qn1 qn2 .. .. . . qL1 qL2 r11 r12 r22 ... ... ... . . . ãLN 0 0 0 . . . q1N . . . q1m q13 . . . q1k 0 0 0 . . . q2N . . . q2m q23 . . . q2k 0 0 0 q33 . . . q3k . . . q3m . . . q3N .. .. .. .. .. .. .. . . . . . . . 0 0 0 qn3 . . . qnk . . . qnm . . . qnN .. .. .. .. .. .. .. . . . . . . . 0 0 0 qL3 . . . qLk . . . qLm . . . qLN 0 0 r13 . . . r1k . . . r1m . . . r1N 0 0 r23 . . . r2k . . . r2m . . . r2N 0 0 r33 . . . r3k . . . r3m . . . r3N .. .. . . . . 0 .. rkk .. . 0 rmm (6.14) The unprimed elements in Q0 and R0 are the elements that are equal to the corresponding elements of Q and R. The k th column of Q0 , q0k , as seen in (6.9), depends on a0k . Since a0k 6= ak , q0k is not necessarily equal to qk . Since each successive column of Q0 depends on all previous columns of Q0 , none of the k th through N th columns of Q0 are necessarily equal to their corresponding columns in Q. Therefore, the k th through N th columns of Q0 are all primed. By (6.10), the first k − 1 rows of R0 depend on the first k − 1 columns of Q0 112 0 and all the columns of à . By (6.13), this means that the only elements within the first k − 1 rows of R0 that will be primed will be the ones depending on the columns 0 of à that are different than the corresponding columns of Ã, so the k th and mth columns. Therefore, within the first k − 1 rows of R0 , only the k th and mth columns are primed. Of the elements of R0 below the first k − 1 rows, all that are also below the diagonal are zero since by definition of the QR factorization, R0 must be upper triangular. Of the other elements of R0 below the first k − 1 rows, those that are not in the k th and mth columns must also be zero. This is because for any column a0p , 4 ≤ p ≤ N, p 6= k, p 6= m, we have that ã0p = ap and by matrix multiplication, ãp = r1p q1 + r2p q2 + r3p q3 , so it must be that ã0p = r1p q1 + r2p q2 + r3p q3 . Therefore, since no further columns of Q0 are needed to make ã0p , the coefficients of these columns can be set equal to zero, 0 rip = 0, 4 ≤ p ≤ N, p 6= k, p 6= m, k ≤ i ≤ p. Since we also know that rip = 0, i > 3, we have that 0 rip = rip , 4 ≤ p ≤ N, p 6= k, p 6= m, k ≤ i ≤ p. So we have shown that the first k − 1 columns of Q0 are unprimed, the k th 113 through N th columns of Q0 are primed, and the only primed columns of R0 are the k th and mth columns. We now look for explicit expressions for the primed elements of R0 in order to determine how the switch of ãnm and ãnk effects the rank of R0 , and thus the rank 0 of à . By (6.10), the original elements rik , 1 ≤ i < k are given by rik = q∗i ãk = [q1i q2i . . . qni . . . qLi ]T [ã1k ã2k . . . ãnk . . . ãLk ]. (6.15) 0 Similarly, the elements rik , 1 ≤ i < k are given by ∗ 0 rik = q0 i ã0k = q∗i ã0k = [q1i . . . qni . . . qLi ]T [ã1k . . . ãnm . . . ãLk ] = [q1i . . . qni . . . qLi ]T [ã1k . . . ãnk . . . ãLk ] − qni ãnk + qni ãnm = rik − qni ãnk + qni ãnm = rik + (ãnm − ãnk )qni , 1 ≤ i < k, (6.16) where in the first step we have used (6.13) and in the third step we have used (6.15). The same argument shows that 0 rim = rim + (ãnk − ãnm )qni , 1 ≤ i < k. (6.17) Since both rik = 0 and rim = 0 for 4 ≤ i < k, (6.16) and (6.17) tell us that 0 0 rim = −rik , 4 ≤ i < k. (6.18) Because of (6.13), simple relations between elements of R0 and R as in (6.16) and 114 (6.17) only hold for the first i rows of R0 , where i < k. Then (6.14) becomes ã11 . . . ã1k . . . ã1m . . . ã1N .. .. ã21 . . ã2N .. .. . ãnm ãnk . .. .. .. .. . . . . ãL1 . . . q11 q12 = q21 q22 q31 .. . q32 .. . qn1 qn2 .. .. . . qL1 qL2 ... ... ... . . . ãLN 0 0 0 q13 . . . q1k . . . q1m . . . q1N 0 0 0 q23 . . . q2k . . . q2m . . . q2N 0 0 0 q33 . . . q3k . . . q3m . . . q3N .. .. .. .. .. .. .. . . . . . . . 0 0 0 qn3 . . . qnk . . . qnm . . . qnN .. .. .. .. .. .. .. . . . . . . . 0 0 0 qL3 . . . qLk . . . qLm . . . qLN (6.19) r11 r12 r13 . . . 0 r1k ... 0 r1m . . . r1N × r22 r23 . . . 0 r2k ... 0 r2m r33 . . . 0 r3k ... 0 r3m . . . r2N . . . r3N . 0 r4k .. . 0 −r4k .. . 0 r(k−1)k 0 −r(k−1)k 0 rkk 0 rkm .. . 0 rmm Clearly, by (6.18), the 5th through (k − 1)th rows in R0 are all just scaled versions of the 4th row. Therefore, there is only one linearly independent row in the 4th through (k − 1)th rows of R0 . Consequently, R0 has more than three linearly independent rows instead of just three. Therefore R0 has rank greater than three. Since Q0 has full rank, this shows 0 that à has rank greater than three, so it has more than three nonzero singular 115 values. Any uncorrelated data set can be produced from a correlated one by a sequence of interchanges. As the data becomes more uncorrelated, more values of rij , i > 3 will be required to be nonzero, so the rank will increase each time, increasing the number of nonzero singular values accordingly. So we have shown that uncorrelated data implies that there are more than three nonzero singular values. This completes the proof for the case k > 3. Comparison to Numerical Simulations One may move on to the next case of the proof. However, it is interesting to examine the rest of the elements of R0 to see if any other knowledge can be gained about the structure. This is motivated by the fact that the structure (6.19) is not the structure seen in numerical simulations in MATLAB of the QR structure resulting from a switch of two elements as described in this proof. We know that the original element rkk is zero since k > 3. By (6.11), the equation for rkk is given by 0 = rkk = ||ãk − Σk−1 i=1 rik qi ||2 k−1 2 2 = (ã1k − Σk−1 i=1 rik q1i ) + . . . + (ãnk − Σi=1 rik qni ) + . . . + (ãLk − 2 Σk−1 i=1 rik qLi ) 1/2 . (6.20) Since each squared element in (6.20) cannot be negative, it follows that ãjk − Σk−1 1 ≤ k ≤ L. i=1 rik qji = 0, (6.21) Let χn denote an L × 1 vector that is all zeros besides a 1 in the nth location. The 116 0 element rkk is given by k−1 0 0 rkk = ||ã0k − Σi=1 rik qi ||2 = ||ã0k − Σk−1 i=1 (rik + (ãnm − ãnk )qni )qi ||2 k−1 rik qi − Σk−1 = ||ã0k − Σi=1 i=1 (ãnm − ãnk )qni qi ||2 k−1 = ||ã0k − ãk + ãk − Σk−1 i=1 rik qi − (ãnm − ãnk )Σi=1 qni qi ||2 k−1 = ||ã0k − ãk − (ãnm − ãnk )Σi=1 qni qi ||2 k−1 = ||(ãnm − ãnk )(χn − Σi=1 qni qi )||2 = (ãnm − ãnk ) ||(χn − Σk−1 i=1 qni qi )||2 k−1 k−1 = (ãnm − ãnk ) (Σi=1 qni q1i )2 + (Σi=1 qni q2i )2 + . . . + (1 − 2 2 Σk−1 i=1 qni ) + ... + 2 (Σk−1 i=1 qni qLi ) 1/2 , (6.22) where in the first step we have used (6.16), in the fourth step we have used (6.21), and in the fourth step we have used the fact that ã1k ã 2k . .. 0 ãk − ãk = ãnm . .. ãLk − ã1k 0 0 .. . = ãnk ãnm − ãnk .. .. . . 0 ãLk ã2k .. . = (ãnm − ãnk )χn , where, again, χn denotes an L × 1 vector that is all zeros besides a 1 in the nth location. In (6.22), we notice that the summation is over the first k − 1 columns of Q0 , which are equal to the first k − 1 columns of Q. These columns form an orthogonal basis for the range space of Ã. Therefore, no linear combination of these columns can yield a column entirely of zeros, so it is not possible for all the summation terms in (6.22) to be zero. Therefore, the normed term yields a nonzero contribution. 0 Since n was chosen such that ãnm 6= ãnk , (6.22) then shows that rkk 6= 0. 117 We now review which elements of (6.19) are known. The first k − 1 columns of Q0 are identical to the first k − 1 columns of Q. The k th through N th columns of Q0 are known by (6.9) as long as the corresponding elements of R0 are known. Every column of R0 besides the k th and mth columns is exactly equal to the corresponding column of R. Of the remaining columns, (6.16), (6.17), and (6.22) define every 0 0 . We seek expressions for these remaining elements. , . . . , rmm element besides rkm 0 0 The original two elements switched in à , defined in terms of elements of à , are given by 0 0 0 0 0 0 0 ãnm = qn1 r1k + qn2 r2k + qn3 r3k + qn4 r4k + . . . + qn(k−1) r(k−1)k + qnk rkk (6.23) and 0 0 0 0 0 0 0 ãnk = qn1 r1m + qn2 r2m + qn3 r3m + qn4 r4m + . . . + qn(k−1) r(k−1)m + qnk rkm 0 0 0 0 +qn(k+1) r(k+1)m + . . . + qnm rmm . (6.24) 0 We substitute the expression for rik in (6.16) in the first three elements of the right hand side of (6.23), 0 0 0 qn1 r1k + qn2 r2k + qn3 r3k = qn1 (r1k + (ãnm − ãnk )qn1 ) + qn2 (r2k + (ãnm − ãnk )qn2 ) + qn3 (r3k + (ãnm − ãnk )qn3 ) 2 2 2 = qn1 r1k + qn2 r2k + qn3 r3k + (ãnm − ãnk )(qn1 + qn2 + qn3 ) 2 2 2 + qn2 + qn3 ). = ãnk + (ãnm − ãnk )(qn1 (6.25) 0 Similarly, we substitute the expression for rim in (6.17) in the first three elements 118 of the right hand side of (6.24), 0 0 0 + qn3 r3m qn1 r1m + qn2 r2m = qn1 (r1m + (ãnk − ãnm )qn1 ) + qn2 (r2m + (ãnk − ãnm )qn2 ) + qn3 (r3m + (ãnk − ãnm )qn3 ) 2 2 2 ) + qn3 + qn2 = qn1 r1m + qn2 r2m + qn3 r3m + (ãnk − ãnm )(qn1 2 2 2 = ãnm + (ãnk − ãnm )(qn1 + qn2 + qn3 ). (6.26) 0 0 in (6.23) as + . . . + qn(k−1) r(k−1)m We use (6.18) to write the terms qn4 r4m 0 0 0 0 qn4 r4m + . . . + qn(k−1) r(k−1)m = −qn4 r4k − . . . − qn(k−1) r(k−1)k . (6.27) Adding together (6.23) and (6.24) and using the substitutions given in (6.25), (6.26), and (6.27) yields 0 0 0 0 0 0 0 0 ãnm + ãnk = ãnk + ãnm + qnk rkk + qnk rkm + qn(k+1) r(k+1)m + . . . + qnm rmm 0 0 0 0 0 0 0 0 0 = qnk rkk + qnk rkm + qn(k+1) r(k+1)m + . . . + qnm rmm . (6.28) The QR factorization is unique for full rank matrices, but not for rank-deficient matrices. Even though the QR factorization showed in (6.19) is correct, it is not the only possible QR factorization. Since R0 is rank-deficient and (6.28) is the only 0 0 0 0 that satisfy (6.28) will , . . . , rmm , any set of rkm , . . . , rmm constraint given for rkm provide a sufficient R0 , and therefore another valid QR factorization. A simple 0 0 choice is to set r(k+1)m = . . . = rmm = 0. Then (6.28) yields 0 0 rkm = −rkk . (6.29) The nonzero elements in the k th row of R0 are related to each other in the same way as (6.18). Then the 4th through k th rows of R0 are all linearly dependent, but linearly independent from the first three rows. All subsequent rows are all zeros. 119 With these substitutions, we can write (6.19) as ã11 . . . ã1k . . . ã1m . . . ã1N .. .. ã21 . . ã2N .. .. . ãnm ãnk . .. .. .. .. . . . . ãL1 . . . q11 q12 = q21 q22 q31 .. . q32 .. . qn1 qn2 .. .. . . qL1 qL2 r11 r12 × r22 ... q13 . . . ... 0 q1k ... ... . . . ãLN 0 q1m ... 0 q1N 0 0 0 q23 . . . q2k . . . q2m . . . q2N 0 0 0 q33 . . . q3k . . . q3m . . . q3N .. .. .. .. .. .. .. . . . . . . . 0 0 0 qn3 . . . qnk . . . qnm . . . qnN .. .. .. .. .. .. .. . . . . . . . 0 0 0 qL3 . . . qLk . . . qLm . . . qLN 0 0 r13 . . . r1k . . . r1m . . . r1N 0 0 . . . r2N r23 . . . r2k . . . r2m 0 0 . . . r3N r33 . . . r3k . . . r3m 0 0 . r4k −r4k .. .. . . 0 0 −rkk rkk (6.30) It is now apparent that the rank of the matrix R0 increases by exactly one in this case. It has been verified by the author using MATLAB that when QR factorizations of matrices such as (6.12) are done numerically, the resulting structure is exactly that shown in (6.30). Case k ≤ 3, m ≤ 3 : We now consider the case where both of the scatterers switched are within the first three columns of Ã. Recall that à was multiplied by a permutation matrix Π 0 so that the resulting matrix à ’s first three columns are then linearly independent. 120 We consider three arbitrary linearly independent vectors and show that switching corresponding elements in two of them results in another vector being required to make a full basis. Let the three arbitrary linearly independent vectors be w, x, and y. Let z be a vector in span(w, x, y), so z can be written as a linear combination of w, x, and y, i.e., z = aw + bx + cy, (6.31) for some constants a, b, and c. In the nth row of vectors w and x, switch the entries. Ensure that n is chosen such that w(n) 6= x(n), so that an actual switch in correlation occurs. Also assume that a 6= b, since a = b is the trivial case in which the change in correlation is not detectable. The case a = b corresponds to rij = rkj for some i, j, k. By (6.10), this can only happen if the column qi is identical to the column qk . Since by Lemma 2 Q0 is full rank, no two columns can be identical. Therefore, this trivial case is not possible here. In order for (6.31) to hold for the rows that weren’t switched, a, b, and c must remain the same. However, this results in the nth row yielding the equation ax(n) + bw(n) + cy(n) = z(n). (6.32) However, originally we had aw(n) + bx(n) + cy(n) = z(n). (6.33) In order for both (6.32) and (6.33) to hold, the system of equations a b b a w(n) x(n) = z(n) − cy(n) z(n) − cy(n) (6.34) 121 must hold. Since a 6= b, we find that w(n) x(n) 1 a b z(n) − cy(n) a2 − b 2 b a z(n) − cy(n) 1 (a + b)(z(n) − cy(n)) . = 2 a − b2 (a + b)(z(n) − cy(n)) = (6.35) Therefore, the only unique solution to (6.35) is w(n) = x(n), which makes (6.32) and (6.33) identical. However, n was chosen such that w(n) 6= x(n). This shows that there actually is no unique solution to (6.35), and (6.32) is false. Therefore, a correction term must be added in order for it to be true, ax(n) + bw(n) + cy(n) = z(n) − aw(n) − bx(n) + ax(n) + bw(n) = z(n) + (a − b)(x(n) − w(n)). (6.36) Notice that in the trivial case that a and b happen to be equal, the correction term is equal to zero, as is expected. So the vector z can no longer be expressed as a linear combination of just the three vectors w, x, and y. The switch of elements results in four linearly independent vectors required to span the space; w, x, y, and a vector that is all zeros besides (a − b)(x(n) − w(n)) in the nth entry. Returning to the problem at hand, we see that if at least one element is switched within the first three columns of Ã, one more column will then be required 0 to span the space of à . This means instead of the QR factorization of à having the form (6.8), at least one more entry below the first three rows of R0 will be required to be nonzero to accommodate the four columns of Q0 required to span the space. Consequently, R0 has four linearly independent rows instead of three. There0 fore R0 has rank four. Since Q0 has full rank, this means that à has rank four, so it has four nonzero singular values. As the data becomes more uncorrelated, more values of rij , i > 3 will be required to be nonzero, so the rank will increase each time, increasing the number of nonzero singular values accordingly. 122 So we have shown that uncorrelated data implies that there are more than three nonzero singular values. This completes the proof for the case k ≤ 3, m ≤ 3. Case k ≤ 3, m > 3 : We now consider the case where one of the scatterers switched is within the first three columns of à and one isn’t. We proceed similarly to the case where k ≤ 3 and m ≤ 3. We consider three arbitrary linearly independent vectors and one arbitrary linearly dependent vector. We show that switching an element in one of the linearly independent vectors with its corresponding element in the linearly dependent vector results in another vector being required to make a full basis. Let w, x, y, z again be defined as in (6.31). We ignore the trivial case where a 6= −1, since if a = −1, no noticeable change in correlation will occur since (6.31) will remain unchanged. The constants a, b, and c are chosen arbitrarily so that z is an arbitrary vector that is linearly dependent on the vectors w, x, and y. In the nth row of vectors w and z, switch the entries. Ensure that n is chosen such that w(n) 6= z(n), so that an actual switch in correlation occurs. In order for (6.31) to hold for the rows that weren’t switched, a, b, and c must remain the same after the switch. This results in the nth row yielding the equation az(n) + bx(n) + cy(n) = w(n). (6.37) However, originally we had (6.33). In order for both (6.37) and (6.33) to hold, the system of equations −a 1 1 −a w(n) z(n) = bx(n) + cy(n) bx(n) + cy(n) (6.38) 123 must hold. For a 6= −1, we find that w(n) z(n) 1 a2 − 1 1 = 2 a −1 = a 1 bx(n) + cy(n) bx(n) + cy(n) (a + 1)(bx(n) + cy(n)) . (a + 1)(bx(n) + cy(n)) 1 a (6.39) (6.40) Hence there is no unique solution to (6.40). Then a correction term must be added to (6.37) in order for it to hold, az(n) + bx(n) + cy(n) = z(n) − aw(n) + az(n) + w(n) − w(n) = w(n) + (a + 1)(z(n) − w(n)) (6.41) Notice that in the trivial case that a happens to be equal to −1, the correction term is equal to zero, as is expected. So the vector z can no longer be expressed as a linear combination of just the three vectors w, x, and y. The switch of elements results in four linearly independent vectors required to span the space; w, x, y, and a vector that is all zeros besides (a + 1)(z(n) − w(n)) in the nth entry. Returning to the problem at hand, we see that if at least one element is switched within the first three columns of Ã, one more column will then be required 0 to span the space of à . This means instead of the QR factorization of à having the form (6.8), at least one more entry below the first three rows of R0 will be required to be nonzero to accommodate the four columns of Q0 required to span the space. Consequently, R0 has four linearly independent rows instead of three. There0 fore R0 has rank four. Since Q0 has full rank, this means that à has rank four, so it has four nonzero singular values. As the data becomes more uncorrelated, more values of rij , i > 3 will be required to be nonzero, so the rank will increase each time, increasing the number of nonzero singular values accordingly. So we have shown that uncorrelated data implies that there are more than three nonzero singular values. 124 This completes the proof for the case k ≤ 3, m > 3. Notice that in all three cases, it was shown that switching two elements at the same aspect increases the rank by one. Therefore, we have shown that switching two elements at the same aspect increases the rank regardless of what the indices k and m are. This increase in rank yields an increase in the number of nonzero singular values. This completes the proof for when two scatterers switch. 6.3.2 Case More than Two Scatterers Switch We now examine the case where any number of scatterers are allowed to switch at a given aspect. The proof is very similar to the case where only two scatterers switch. Therefore, not every step is listed explicitly; rather, the proof follows along with the case where only two scatterers switch and the key differences are highlighted. We again begin with the matrix à shown in (6.8). In the nth row of Ã, we arbitrarily switch s elements. The s columns containing the elements that were switched will be referred to as the columns ξ1 , ξ2 , . . . , ξs , where ξ1 < ξ2 < . . . < ξs . We define the correct correlate to be the ordering in the first row, so we choose n such that n > 1. The uncorrelated matrix resulting from 0 this switch, à , is given by ã11 . . . ã1ξ1 . . . ã1ξt . . . ã1ξs . . . ã1N .. .. .. ã21 . . . ã2N .. .. . ãnξ2 . . . ãnξ( t+1) . . . ãnξ1 . .. .. .. .. .. . . . . . ãL1 . . . ... ... ... ... ... . (6.42) . . . ãLN For simplicity, we have replaced the nth element in column ξ1 with the nth element in column ξ2 , the nth element in column ξ2 with nth element in column ξ3 , and so on. The nth element in column ξs is replaced with the nth element in column ξ1 . However, any method of reordering s elements within a given row could be used. 0 Here we have kept the elements of à in terms of the original elements of Ã. 125 We examine how the switch of these elements affects the structure of the matrices 0 Q0 and R0 resulting from the QR factorization of à . Case ξ1 > 3 : The proof is very similar to the case where only two scatterers switch. Following along with the s = 2 case, the same argument that led to (6.13) shows that q0i = qi , 1 ≤ i < ξ1 . ã11 . . . ã1ξ1 . . . ã1ξt . . . ã1ξs . . . ã1N .. .. .. ã21 . . . ã2N .. .. . ãnξ2 . . . ãnξ( t+1) . . . ãnξ1 . .. .. .. .. .. . . . . . ãL1 . . . q11 q12 = q21 q22 q31 .. . q32 .. . × (6.43) qn1 qn2 .. .. . . qL1 qL2 r11 r12 r22 ... ... ... ... ... (6.44) . . . ãLN 0 0 0 0 . . . q1N . . . q1ξ q13 . . . q1ξ . . . q1ξ s t 1 0 0 0 0 . . . q . . . q q23 . . . q2ξ . . . q 2N 2ξs 2ξt 1 0 0 0 0 . . . q . . . q q33 . . . q3ξ . . . q 3N 3ξs 3ξt 1 .. .. .. .. .. .. .. .. .. . . . . . . . . . 0 0 0 0 qn3 . . . qnξ1 . . . qnξt . . . qnξs . . . qnN .. .. .. .. .. .. .. .. .. . . . . . . . . . 0 0 0 0 qL3 . . . qLξ1 . . . qlξt . . . qLξs . . . qLN 0 0 0 r13 . . . r1ξ1 . . . r1ξt . . . r1ξs . . . r1N 0 0 0 r23 . . . r2ξ . . . r . . . r . . . r 2N 2ξt 2ξs 1 0 0 0 r33 . . . r3ξ . . . r . . . r . . . r 3N 3ξt 3ξs 1 .. .. .. . . . . . . .. .. rξ0 1 ξ1 . .. rξ0 t ξt 0 rξs ξs 126 As in the case where only two scatterers switch, the unprimed elements in Q0 and R0 are the elements that are equal to the corresponding elements in Q and R. The same arguments used in that case hold, substituting the new column index ξ1 for k in all arguments. The first difference occurs in the equation analogous to (6.16). 0 , 1 ≤ i ≤ ξ1 are given by The elements riξ 1 0 0 riξ = qi∗ ã0ξ1 1 = q∗i ã0ξ1 = [q1i . . . qni . . . qLi ]T [ã1ξ1 . . . ãnξ2 . . . ãLξ1 ] = [q1i . . . qni . . . qLi ]T [ã1ξ1 . . . ãnξ1 . . . ãLξ1 ] − qni ãnξ1 + qni ãnξ2 = riξ1 − qni ãnξ1 + qni ãnξ2 = riξ1 + (ãnξ2 − ãnξ1 )qni , 1 ≤ i < ξ1 . (6.45) 0 , 1 ≤ i < ξ1 is given by Similarly, we find that any element riξ t 0 riξ = riξt + (ãnξt+1 − ãnξt )qni , 1 ≤ i < ξ1 . t (6.46) Since riξt = 0 for 4 ≤ i < ξ1 and 1 ≤ t ≤ s, (6.45) and (6.46) tell us that 0 0 0 = 0, 4 ≤ i < ξ1 . riξ + riξ + . . . + riξ s 1 2 (6.47) Equations (6.45), (6.46), and (6.47) show that the nonzero elements of the ith row of R0 , 4 ≤ i ≤ ξ1 , are given by qni [(ãnξ2 − ãnξ1 ), (ãnξ3 − ãnξ2 ), . . . , (ãnξ1 − ãnξs )]. (6.48) It is clear that the 4th through (ξ1 − 1)th rows of R0 are all scaled versions of each other. Then they are all linearly dependent, and they increase the rank of R0 . As in the case where only two scatterers switch, this proves the case for ξ1 > 3. Comparison to Numerical Simulations Again, one may move on to the next case of the proof. However, it is interesting to examine the rest of the elements of R0 127 to see if any other knowledge can be gained about the structure. This is motivated by the fact that the structure (6.45) is not the structure seen in numerical simulations in MATLAB of the QR structure resulting from a switch of more than two elements as described in this proof. The equations (6.20) and (6.21) still hold in this case, with k replaced by ξ1 . The same argument used to arrive at (6.22) shows that rξ0 1 ξ1 = (ãnξ2 k−1 2 2 − ãnξ1 ) (Σk−1 i=1 qni q1i ) + (Σi=1 qni q2i ) + . . . + (1 − 2 2 Σk−1 i=1 qni ) + ... + k−1 (Σi=1 qni qLi )2 1/2 . (6.49) The same argument as before shows that rξ0 1 ξ1 6= 0. We now review which elements of (6.30) are known. The first ξ1 − 1 columns of Q0 are identical to the first ξ1 − 1 columns of Q. The ξ1th through N th columns of Q0 are known by (6.9) as long as the corresponding elements of R0 are known. Every column of R0 besides the columns ξt , 1 ≤ t ≤ s, is exactly equal to the corresponding column of R. Of the remaining columns, (6.45), (6.46), and (6.49) define every element besides rξ0 1 ξt , . . . , rξ0 t ξt , 1 < t ≤ s. We seek expressions for these remaining elements. 0 0 The original s elements switched in à , defined in terms of elements of à , are 128 given by 0 0 0 0 0 0 r0 + qnξ + . . . + qn(ξ1 −1) r(ξ + qn4 r4ξ + qn3 r3ξ + qn2 r2ξ ãnξ1 = qn1 r1ξ s s s s 1 ξ1 ξs 1 −1)ξs 0 0 + qn(ξ r0 + . . . + qnξ r0 s ξs ξs 1 +1) (ξ1 +1)ξs (6.50) 0 0 0 0 0 0 ãnξ2 = qn1 r1ξ + qn2 r2ξ + qn3 r3ξ + qn4 r4ξ + . . . + qn(ξ1 −1) r(ξ + qnξ r0 1 1 1 1 1 −1)ξ1 1 ξ1 ξ1 (6.51) .. . 0 0 0 0 0 0 r0 + qnξ + . . . + qn(ξ1 −1) r(ξ + qn4 r4ξ + qn3 r3ξ ãnξ(t+1) = qn1 r1ξ + qn2 r2ξ t t t t 1 ξ1 ξt 1 −1)ξt 0 0 + qn(ξ r0 + . . . + qnξ r0 t ξt ξt 1 +1) (ξ1 +1)ξt .. . (6.52) 0 0 0 0 0 ãnξs = qn1 r1ξ + qn2 r2ξ + qn3 r3ξ + qn4 r4ξ + . . . + qn(ξ1 −1) r(ξ 1 −1)ξ(s−1) (s−1) (s−1) (s−1) (s−1) 0 0 0 + qnξ r0 + qn(ξ r0 + . . . + qnξ r0 . 1 ξ1 ξ(s−1) 1 +1) (ξ1 +1)ξ(s−1) (s−1) ξ(s−1) ξ(s−1) (6.53) 0 We substitute the expression for riξ in (6.45) in the first three elements on the right 1 hand side of (6.51), 0 0 0 qn1 r1ξ + qn2 r2ξ + qn3 r3ξ 1 1 1 = qn1 (r1ξ1 + (ãnξ2 − ãnξ1 )qn1 ) + qn2 (r2ξ1 + (ãnξ2 − ãnξ1 )qn2 ) + qn3 (r3ξ1 + (ãnξ2 − ãnξ1 )qn3 ) 2 2 2 = qn1 r1ξ1 + qn2 r2ξ1 + qn3 r3ξ1 + (ãnξ2 − ãnξ1 )(qn1 + qn2 + qn3 ) 2 2 2 = ãnξ1 + (ãnξ2 − ãnξ1 )(qn1 + qn2 + qn3 ). (6.54) 0 Similarly, we substitute the expression for riξ in (6.46) in the first three elements t 129 on the right hand side of (6.52), 0 0 0 qn1 r1ξ + qn2 r2ξ + qn3 r3ξ t t t = qn1 (r1ξt + (ãnξt+1 − ãnξt )qn1 ) + qn2 (r2ξt + (ãnξt+1 − ãnξt )qn2 ) + qn3 (r3ξt + (ãnξt+1 − ãnξt )qn3 ) 2 2 2 ) + qn3 + qn2 = qn1 r1ξt + qn2 r2ξt + qn3 r3ξt + (ãnξt+1 − ãnξt )(qn1 2 2 2 = ãnξt + (ãnξt+1 − ãnξt )(qn1 + qn2 + qn3 ). (6.55) Then adding together all equations (6.50) through (6.53) using the substitutions shown in (6.54) and (6.55) yields ãnξ1 + . . . + ãnξs = 2 2 2 ãnξ1 + . . . + ãnξs + (ãnξ2 − ãnξ1 )(qn1 + qn2 + qn3 ) 2 2 2 2 2 2 + (ãnξ3 − ãnξ2 )(qn1 + qn2 + qn3 ) + . . . + (ãnξs − ãnξs−1 )(qn1 + qn2 + qn3 ) 2 2 2 + . . . + (ãnξs − ãnξs−1 )(qn1 + qn2 + qn3 ) 0 0 0 0 0 0 + qn4 (r4ξ + r4ξ + . . . + r4ξ ) + qn5 (r5ξ + r5ξ + . . . + r5ξ )... s s 1 2 1 2 0 0 0 + qn(ξ1 −1) (r(ξ ) + r(ξ + . . . + r(ξ 1 −1)ξ1 1 −1)ξ2 1 −1)ξs 0 0 0 0 + qnξ r0 + . . . + qnξ r0 + qn(ξ r0 + . . . + qnξ r0 . s ξs ξs 1 ξ1 ξ1 1 ξ1 ξs 1 +1) (ξ1 +1)ξs (6.56) After cancellation of terms and substituting (6.47), (6.56) reduces to 0 0 0 0 0 = qnξ r0 + . . . + qnξ r0 + qn(ξ r0 + . . . + qnξ r0 . s ξs ξs 1 ξ1 ξ1 1 ξ1 ξs 1 +1) (ξ1 +1)ξs (6.57) This equation is analogous to (6.28). Again, the QR factorization is not unique for rank-deficient matrices and (6.57) is the only constraint given for rξ0 1 ξ1 , . . . , rξ0 1 ξs , . . . , rξ0 s ξs . Then a simple choice is to 0 set all riξ = 0 for i > ξ1 and let rξ0 1 ξj satisfy (6.47). This can be done while ensuring j that the ξith row is a scaled version of the 4th through (ξ1 − 1)th rows so that the 130 following structure is achieved, ã11 . . . ã1ξ1 . . . ã1ξt . . . ã1ξs . . . ã1N .. .. .. ã21 . . . ã2N .. .. . ãnξ2 . . . ãnξ( t+1) . . . ãnξ1 . .. .. .. .. .. . . . . . ãL1 . . . q11 q12 = q21 q22 q31 .. . q32 .. . qn1 qn2 .. .. . . qL1 qL2 r11 r12 × r22 ... ... q13 . . . 0 q1ξ 1 ... ... ... 0 q1ξ t ... ... . . . ãLN 0 q1ξ s ... 0 q1N 0 0 0 0 q23 . . . q2ξ . . . q . . . q . . . q 2N 2ξt 2ξs 1 0 0 0 0 q33 . . . q3ξ . . . q . . . q . . . q 3N 3ξt 3ξs 1 .. .. .. .. .. .. .. .. .. . . . . . . . . . 0 0 0 0 qn3 . . . qnξ1 . . . qnξt . . . qnξs . . . qnN .. .. .. .. .. .. .. .. .. . . . . . . . . . 0 0 0 0 qL3 . . . qLξ1 . . . qlξt . . . qLξs . . . qLN 0 0 0 r13 . . . r1ξ1 . . . r1ξt . . . r1ξs . . . r1N 0 0 0 r23 . . . r2ξ1 . . . r2ξt . . . r2ξs . . . r2N 0 0 0 r33 . . . r3ξ . . . r . . . r . . . r 3N 3ξ 3ξ t s 1 . .. .. .. . . . 0 0 0 rξ1 ξ1 rξ1 ξt rξ1 ξs (6.58) All of the 4th through ξ1th rows of R0 are linearly dependent, but linearly independent from the first three rows. This results in R0 having rank four. It has been verified by the author using MATLAB that when QR factorizations of matrices such as (6.42) are done numerically, the resulting structure is exactly that shown in (6.58). This completes the proof for the case ξ1 > 3. Case ξs ≤ 3 : We now consider the case where all the scatterers switched are within the first three columns of Ã. Clearly the only way this can happen is if only three scatterers switch. Again, recall that A was multiplied by a permutation matrix Π so that the 131 resulting matrix Ã’s first three columns are then linearly dependent. We consider three arbitrary linearly independent vectors and show that switching corresponding elements in all three of them results in another vector being required to make a full basis. Let the three arbitrary linearly independent vectors w, x, y, and z be defined as in (6.31). Instead of switching the nth entries of the three vectors all at once, we consider first the switch of just two elements as in (6.32), then make another switch of two elements so that afterward, all three have been switched. Ensure that n is chosen such that w(n) 6= x(n) 6= y(n), so that an actual switch in correlation occurs. Also assume that a 6= b 6= c, since a = b = c is the trivial case in which the change in correlation is not detectable. The case a = b = c corresponds to rij = rkj = rlj for some i, j, k, l. By (6.10), this can only happen if qi = qj = qk . Since by Lemma 2 Q0 is full rank, no three columns can be identical. Therefore, this trivial case is not possible here. Recall that after a switch of w(n) and x(n), (6.33) was modified to (6.36). To consider the case where three scatterers switch, we now switch w(n) and y(n) in (6.36). Proceeding as before, this results in ax(n) + by(n) + cw(n) = z(n) + (a − b)(w(n) − x(n)) − bw(n) − cy(n) + by(n) + cw(n) = z(n) + (a − b)(w(n) − x(n)) + (b − c)(y(n) − w(n)). (6.59) As before, this results in an additional vector being required to span the space. This vector is all zeros besides (b − c)(y(n) − w(n)) in the nth entry. Therefore, this additional vector is linearly dependent with the first additional vector that was needed to span the space, the vector that was all zeros besides (a − b)(w(n) − x(n)) in the nth entry. Returning to the problem at hand, we see that if all three elements are switched within the first three columns of Ã, one more column will then be required to span 0 the space of à . Again, as described in the proof of the case where only two scatterers 0 switch in the first three columns of Ã, this results in à having four nonzero singular 132 values. So switching three scatterers in the first three columns has the same effect on rank as switching just two scatterers in the first three columns. This completes the proof for the case ξs ≤ 3. Case ξ1 ≤ 3, ξs > 3 : We lastly consider the case where more than three scatterers switch, and the scatterers can be both within the first three columns and in the 4th through N th columns. A switch of more than three scatterers can be thought of as a sequence of two-scatterer switches. We break down the switches in to the order 1. A switch of any number of scatterers from the first three columns with scatterers from the 4th through N th columns, 2. A switch of scatterers within the first three columns, 3. A switch of scatterers within the 4th through N th columns. In the case where two scatterers switch and k ≤ 3, m > 3, we saw that this increased rank by one. A quick review of this proof easily shows that if another switch occurred in this same manner in the same row after the first switch, the result would be that another vector that is all zeros besides an entry in the nth location would be required to span the space. However, this vector is linearly dependent with the fourth vector that was already found to be required to span the space after the first switch. Clearly, no matter how many switches of this nature occur, each will require another vector to span the space, and each subsequent vector will be linearly dependent on the ones before it. So no matter how many switches of this nature occur, rank will increase only by one. In the case where only two scatterers switch for k > 3, m > 3, we saw that this increased rank by one. In the case where more than two scatterers switch for ξ1 > 3, we saw that despite this increase in the number of switches, rank still increased by only one. Similarly, in the case where only two scatterers switch for k ≤ 3, m ≤ 3, we saw that this increased rank by one. In the case where three scatterers switch for 133 ξ3 < 3, we saw that this additional switch in the first three columns did not increase the overall rank by more than initial switch; rank still increased by only one. Based on these previous conclusions, it follows that when more than three scatterers switch, and the scatterers can be both within the first three columns and in the 4th through N th columns, rank still increases by only one. This completes the proof for when ξ1 ≤ 3, ξs > 3. Notice that in all three cases, it was shown that switching any number of elements at the same aspect increases the rank by one. Therefore, we have shown that switching any number of elements at the same aspect increases the rank regardless of what the indices ξi are. This increase in rank yields an increase in the number of nonzero singular values. This completes the proof for the case where more than two scatterers switch at a single aspect. 6.3.3 Case Scatterers Switch at Multiple Aspects All the previous cases have shown that no matter how many scatterers are switched at a given aspect, the rank of the matrix will increase by one, increasing the number of nonzero singular values by one. We now show that no further changes in correlation at subsequent aspects will 0 ever decrease the rank. Consider partitioning the matrix à into two matrices, the first of which being the first n rows and the second of which being the (n + 1)th through Lth rows, 0 à = 0 0 . Ã1 Ã2 (6.60) 0 0 Since the only switch of scatterers in à occurs in its nth row, the matrix Ã2 is 0 correlated, and therefore by Lemma 1, it has rank 3. As shown in this proof, Ã1 has rank 4. Notice that Lemma 4 applies to matrices partitioned side by side, instead of 0 one above the other, as the matrix à is. 134 0 0 Rearranging (6.7) and substituting in Ã1 and Ã2 gives 0 0 0 0 0 0 rank([Ã1 , Ã2 ]) ≥ rank(Ã1 ) + rank(Ã2 ) − min(rank(Ã1 ), rank(Ã2 )). (6.61) By basic properties of matrices, 0T 0 0T 0 rank(Ã1 ) = rank(Ã1 ) (6.62) and rank(Ã2 ) = rank(Ã2 ). 0T (6.63) 0T We can plug Ã1 and Ã1 in to (6.61) to find that 0T 0T 0T 0T 0T 0T rank([Ã1 , Ã2 ]) ≥ rank(Ã1 ) + rank(Ã2 ) − min(rank(Ã1 ), rank(Ã2 )). (6.64) Plugging (6.62) and (6.63) in to (6.64) yields 0T 0T 0T 0T 0 0 0 0 rank([Ã1 , Ã2 ]) ≥ rank(Ã1 ) + rank(Ã2 ) − min(rank(Ã1 ), rank(Ã2 )). Since 0T 0T rank([Ã1 , Ã2 ]) = rank([Ã1 , Ã2 ]T ) = rank 0 0 = rank(Ã0 ), Ã1 Ã2 we find that 0 0 0 0 0 rank(à ) ≥ rank(Ã1 ) + rank(Ã2 ) − min(rank(Ã1 ), rank(Ã2 )). 0 0 (6.65) 0 Since rank(Ã1 ) = 4 and rank(Ã2 ) = 3, (6.65) shows that rank(à ) ≥ 4. This is the 0 for the case where we know that Ã2 is correlated. 0 If, however, Ã2 becomes uncorrelated at multiple aspects, its rank may change. 135 0 We let rank(Ã2 ) = r, where 1 ≤ r ≤ N . Then (6.65) becomes 4, 1 ≤ r ≤ 3 0 rank(à ) ≥ 4 + r − min(4, r) = 4, r = 4 r, 4 < r ≤ N. (6.66) 0 No matter what changes in correlation occur in Ã2 and regardless of if its rank 0 increases or decreases, (6.66) shows that rank(à ) cannot decrease. Therefore, no changes in correlation at any subsequent aspects can decrease the rank and we will always have that 0 rank(à ) ≥ 4. (6.67) The above cases and these observations together are sufficient to justify the use of the iterative algorithm in practice. It has been shown that uncorrelated data at just one aspect increases the rank from 3 to 4, and that this rank cannot then decrease at any subsequent aspects. As a result, uncorrelated data will always have at least four nonzero singular values (and more are possible resulting from changes in correlation at subsequent aspects). Therefore, this proves that a matrix of radar observables data is uncorrelated if and only if it has more than three nonzero singular values. 6.4 Comparison of Algorithms The two proposed methods are useful in different circumstances. If there are a small number of scatterers and not too much noise, then the nearest neighbor and slope algorithm can easily be employed. This runs very quickly and gives good results. When dealing with a large number of scatterers, finding the optimal correlation is not as straightforward as this. This is when the iterative algorithm can be used. It takes longer to run, but it is the most effective option in this case. When the number of scatterers is small, the iterative algorithm cannot be used anyway. This is because the algorithm depends on there being enough singular values after the first three that the algorithm can operate based on minimizing them. 136 If there are only four scatterers, this means the algorithm would be minimizing just the one last singular value, which would not be very effective. Figure 6.31 shows a singular value distribution from a target with four scatterers. Figure 6.31: Singular Value Distribution for 4 Scatterer Target As can be seen, all of the last singular values are zero. The iterative algorithm would be useless in this case, since it would be trying to find the minimum of a set of values that are all zero. Figure 6.32 shows a singular value distribution from a target with five scatterers. Here the algorithm correctly correlates uncorrelated data in the case of only five scatterers. Notice that the algorithm had to minimize only one value, since the last singular value seems to always be zero. From this, we can conclude that the iterative algorithm can be used whenever there are more than four scatterers. The nearest neighbor and slope algorithm quickly breaks down when more than a few scatterers are present, since many tracks can have similar slopes at the same aspect. The method seems to work well for up to five scatterers, but doesn’t do as well as more scatterers are added in. One thing to notice is that many ballistic targets will have a very small number of scatterers, since many of them are simple shapes such as cones. It is a very 137 Figure 6.32: Singular Value Distribution for 5 Scatterer Target reasonable assumption that a ballistic target could have four or five scatterers. Both of the correlation algorithms can be very useful for targets of this nature. A key attribute to notice is that the iterative algorithm uses all data at once, while the nearest neighbor and slope algorithm doesn’t necessarily have to. The number of scatterers is manageable enough in the nearest neighbor and slope algorithm that the data can be looked at sequentially. If needed, the PESVD method could be run periodically throughout the algorithm and the shape estimate modified as more data is acquired. This is a feature that the iterative algorithm does not have. The iterative algorithm is useful when there is so much data that a sequential method is impractical. The reason the iterative algorithm can’t correlate data sequentially is that the SVD needs to be applied to all the data as a whole in order to analyze its singular value structure. Due to this, it makes no sense to correlate the data aspect by aspect using an SVD. CHAPTER 7 Discussion and Conclusions 7.1 Summary An introduction is provided that gives a brief background of radar and explains the ideas of SAR, ISAR, and IFSAR, and scatterer correlation. An overview of previous work is given in order to explain where the work of this thesis fits in with other previous work. Background is given on key ideas required to understand the work of this thesis, including electromagnetic wave propagation and scatterers. Background is given on how radar data is collected and processed in order to arrive at the radar observables used for radar imaging: range, range-rate, and delta phase. This is done using Fourier processing in order to arrive at Range-Doppler data blocks from which the radar observables are extracted. Scatterer correlation is introduced, which is a key concept in this thesis. Background is given on the sample target used and how radar data was simulated from it for this thesis, and resolution constraints are discussed. A brief review of the Singular Value Decomposition (SVD) and QR factorization is given. An overview of the phase-enhanced 3D snapshot imaging method is given, along with an overview of how it fits in with the general 2D and 3D snapshot imaging equations. A derivation of the phase equation, as presented in [7], is provided, along with a new alternate derivation of the phase equation directly from the equation of the Range-Doppler data block. This is shown to verify that it agrees with the phase equation derived directly from the snapshot equations. The phase-enhanced 3D snapshot imaging method estimates shape given uncorrelated range, range-rate, and delta phase data and a priori motion. Considerations that must be taken in to account when implementing the phaseenhanced 3D snapshot imaging algorithm are presented. This includes specifics related to the coordinate system that is used. A new method of handling the phase ambiguities that inherently arise when using this method is presented. A summary 138 139 of the 3DMAGI SVD method is also presented. This method estimates both shape and motion given correlated range data. The hybrid phase-enhanced SVD (PESVD) method is then presented. This method combines the phase-enhanced 3D snapshot imaging algorithm and the 3DMAGI SVD method in to a hybrid method that uses range, range-rate, and delta phase data in order to estimate both shape and motion. In order to use this method, data must still be correlated (this motivates the next section). Scaling considerations are presented in order to ensure that the shape and motion estimates are reconstructed with accurate scaling. The effects of imperfect correlation and added noise are investigated. Two correlation algorithms are presented. The iterative correlation algorithm is applicable for targets with more than four scatterers. It can be used in the presence of noise and can resolve phase ambiguities. The method iterates on a set of possible correlations for radar data and chooses the optimal correlation based on a condition on the singular values resulting from the PESVD method. The second algorithm is applicable to targets with fewer scatterers. It uses the ideal continuity of the radar observables and the fact that range-rate data should ideally be the derivative of range data in order to methodically correlate radar observables data. Both methods can handle reasonable quantities of noise, but of the two, the iterative algorithm is better at handling noise. Lastly, a mathematical proof is provided of a theorem that justifies the use of the iterative algorithm. The proof is presented for the case when two scatters switch at a given aspect in order to make data uncorrelated, and for the case when more than two scatterers switch at a given aspect. These separate cases are included because the two-scatterer case is very straightforward and easy to follow. It is important to note the limitations of this work: • Can’t handle occluded scatterers • Effects of preprocessing noise haven’t been investigated • Can’t handle slipping scatterers • Can’t handle speculars 140 • Resolution is limited by FFT size 7.2 Main Contributions Previous work and the author’s new work are intermixed throughout the thesis. Therefore, a some of the author’s main contributions are listed below. • Developed a method to combine the Phase-Enhanced 3D Snapshot Imaging Algorithm and the 3DMAGI SVD Method in to a hybrid method that uses range, range-rate, and delta phase to estimate both shape and motion. • Developed an alternate derivation of the phase equation directly from the equation of the Range-Doppler data block and verified that it agrees with the phase equation derived from the snapshot equations. • Developed a method to resolve phase ambiguities in delta phase data taken when motion is known so that targets are reconstructed in target coordinates. • Developed a method to simulate realistically uncorrelated radar observables data with realistic noise and phase ambiguities. • Developed a methodical correlation algorithm that eliminates the need for scatterer correlation in the case of a small number of scatterers in the presence of noise and can resolve phase ambiguities. • Developed an iterative correlation algorithm that eliminates the need for scatterer correlation in the case of a large number of scatterers in the presence of noise and can resolve phase ambiguities. • Proved a theorem relating the number of nonzero singular values to whether or not a matrix of radar observables data is correlated. This theorem justifies the use of the iterative algorithm. 7.3 Future Work There are many possible future research topics that result from the work of this thesis. A few are listed below. 141 • Extend PESVD method to incorporate data from multiple sensors. The ability to extend this method to multistatics would be very useful. • Investigate the effect of preprocessing noise on the PESVD method. For example, varying Signal-to-Noise Ratios (SNRs) could be tested. It would be especially interesting to investigate what SNR results in noise so high that one of the three singular values used in the PESVD method results completely from noise, rendering the method is unusable. LITERATURE CITED [1] C. Groetsch, Inverse Problems. Washington, DC: The Mathematical Association of America, 1999. [2] W. Carrara et al., Spotlight Synthetic Aperture Radar: Signal Processing Algorithms. Norwood, MA: Artech Print on Demand, 1995. [3] M. Cheney and B. Borden, Fundamentals of Radar Imaging. Philadelphia, PA: SIAM, 2009. [4] C. Ozdemir, Inverse Synthetic Aperture Radar Imaging With MATLAB Algorithms. Hoboken, NJ: Wiley Series in Microwave and Optical Engineering, 2012. [5] M. Stuff, “Three-dimensional Analysis of Moving Target Radar Signals: Methods and Implications for ATR and Feature Aided Tracking”, in Proc. SPIE3721 Algorithms for Synthetic Aperture Radar Imagery VI, 1999, pp. 485-496. [6] A. Grigis and J. Sjostrand, Microlocal Analysis for Differential Operators, an Introduction (London Mathematical Society Lecture Note Series 196). Cambridge, UK: Cambridge University Press, 1994. [7] J. Mayhan et al., “High Resolution 3D ’Snapshot’ ISAR Imaging and Feature Extraction”. IEEE Trans. Aerosp. and Electron. Syst., vol. 37, no. 2, pp. 630-641, 2001. [8] J. Mayhan, “Phase-Enhanced 3D Snapshot ISAR Imaging and Interferometric SAR,” MIT Lincoln Laboratory, Lexington, MA, Tech. Rep. 1135, 2009. [9] C. Tomasi and T. Kanade, “Shape and Motion from Image Streams: A Factorization Method”. Carnegie Mellon University, Pittsburgh, PA, Tech. Rep. CMU-CS-91-105, 1991. 142 143 [10] M. Stuff, “Derivation and Estimation of Euclidean Invariants of Far Field Range Data,” Ph.D. Dissertation, Dept. Stats., Univ. of Michigan, Ann Arbor, 2002. [11] M. Ferrara et al., “Shape and Motion Reconstruction from 3D-to-1D Orthographically Projected Data via Object-Image Relations”. IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 10, pp. 1906-1912, 2009. [12] R. Sullivan, Radar Foundations for Imaging and Advanced Concepts. Herndon, VA: SciTech Publishing, 2004. [13] R. Becker, Introduction to Theoretical Mechanics. New York, NY: McGraw-Hill Book Company, Inc, 1954. [14] A. Bjorck and G. Dahlquist, Numerical Methods in Scientific Computing, Volume II. Philadelphia, PA: SIAM, 2008. [15] L. Trefethen and D. Bau, Numerical Linear Algebra. Philadelphia, PA: SIAM, 1997. [16] H. Yanai et al., Projection Matrices, Generalized Inverse Matrices, and Singular Value Decomposition. New York, NY: Springer, 2011.