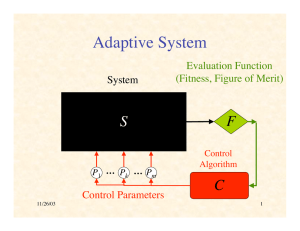
Gradient Ascent Process Lecture 28 General Ascent on Fitness Surface
advertisement

Part 7: Neural Networks & Learning
12/3/07
Gradient Ascent Process
P˙ = "#F (P)
Change in fitness :
m "F d P
m
dF
k
F˙ =
=#
= # ($F ) k P˙k
k=1 "P d t
k=1
!d t
k
˙
˙
F = $F % P
Lecture 28
2
F˙ = "F # $"F = $ "F % 0
!
12/3/07
!
1
Therefore gradient ascent increases fitness
(until reaches 0 gradient)
12/3/07
2
General Ascent
on Fitness Surface
General Ascent in Fitness
Note that any adaptive process P( t ) will increase
fitness provided :
0 < F˙ = "F # P˙ = "F P˙ cos$
∇F
+
where $ is angle between "F and P˙
–
Hence we need cos " > 0
!
or " < 90 o
12/3/07
3
12/3/07
4
!
Gradient of Fitness
Fitness as Minimum Error
%
(
"F = "'' #$ E q ** = #$ "E q
& q
)
q
Suppose for Q different inputs we have target outputs t1,K,t Q
Suppose for parameters P the corresponding actual outputs
!
are y1,K,y Q
Suppose D(t,y ) " [0,#) measures difference between
!
!
target & actual outputs
Q
!
Q
!
Let F (P) = "# E q (P) = "# D[t q ,y q (P)]
!
!
q=1
12/3/07
d D(t q ,y q ) #y q
"
d yq
#Pk
q
q
q
= " D t ,y # $y
=
Let E q = D(t q ,y q ) be error on qth sample
!
"D(t q ,y q ) "y qj
"E q
"
=
D(t q ,y q ) = #
"Pk "Pk
"y qj
"Pk
j
yq
q=1
5
12/3/07
!
(
)
$Pk
6
!
1
Part 7: Neural Networks & Learning
12/3/07
Derivative of Squared Euclidean
Distance
Suppose D(t,y ) = t " y = # ( t " y )
Jacobian Matrix
#"y1q
&
"y1q
%
"P1 L
"Pm (
%
Define Jacobian matrix J =
M
O
M (
q
%"y q
(
"
y
n
n
%
"P1 L
"Pm ('
$
2
q
q
Note J " #
!
n$m
and %D(t ,y
Since ("E q ) k =
!
q
q
)"#
!
q
q
#y #D(t ,y )
#E
=$
,
q
#Pk
#y j
j #Pk
=
!
T
"#E q = ( J q ) #D(t q ,y q )
!
i
i
"D(t # y ) "
" (t # y )
=
$ (t i # y i )2 = $ i"y i
"y j
"y j i
j
i
n$1
q
j
q
2
i
d( t j " y j )
dyj
2
2
= "2( t j " y j )
d D(t,y )
= 2( y # t )
dy
12/3/07
!
"
12/3/07
7
!
8
!
Recap
Gradient of Error on qth Input
"E q d D(t ,y
=
"Pk
d yq
q
q
) # "y
T
P˙ = "$ ( J q ) (t q # y q )
q
q
"Pk
To know how to decrease the differences between
actual & desired outputs,
"y q
= 2( y $ t ) #
"Pk
q
q
!
we need to know elements of Jacobian,
"y qj
"Pk ,
which says how jth output varies with kth parameter
(given the qth input)
"y q
= 2% ( y qj $ t qj ) j
j
"Pk
T
"E q = 2( J q ) ( y q # t q )
The Jacobian depends on the specific form of the system,
in this case, a feedforward neural network
!
12/3/07
9
!
12/3/07
10
!
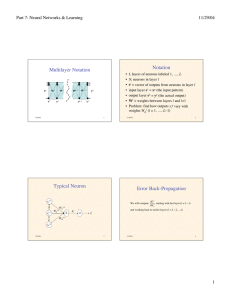
Notation
Multilayer Notation
xq
W1
s1
12/3/07
W2
s2
WL–2 WL–1
sL–1
•
•
•
•
•
•
•
yq
sL
11
L layers of neurons labeled 1, …, L
Nl neurons in layer l
sl = vector of outputs from neurons in layer l
input layer s1 = xq (the input pattern)
output layer sL = yq (the actual output)
Wl = weights between layers l and l+1
Problem: find how outputs yiq vary with
weights Wjkl (l = 1, …, L–1)
12/3/07
12
2
Part 7: Neural Networks & Learning
12/3/07
Typical Neuron
Error Back-Propagation
s1l–1
sjl–1
We will compute
Wi1 l–1
Wijl–1
hil
Σ
"E q
starting with last layer (l = L #1)
"W ijl
and working back to earlier layers (l = L # 2,K,1)
sil
σ
WiNl–1
!
sNl–1
12/3/07
13
12/3/07
14
Output-Layer Neuron
Delta Values
Convenient to break derivatives by chain rule :
s1L–1
"E q
"E q "hil
=
"W ijl#1 "hil "W ijl#1
"E q
Let $ = l
"h i
sjL–1
l
i
So
!
15
dh
2
= 2( siL $ t iq )
!
16
"hiL
"
=
$W ikL#1skL#1 = sL#1
j
"W ijL#1 "W ijL#1 k
d siL
d hiL
!
= 2( siL $ t iq )' &( hiL )
12/3/07
Eq
Output-Layer Derivatives (2)
2
#E q
#
=
% (skL $ tkq )
#hiL #hiL k
L
i
tiq
siL = yiq
12/3/07
Output-Layer Derivatives (1)
d( siL $ t iq )
σ
sNL–1
12/3/07
=
hiL
WiNL–1
"E q
"hil
= $il
"W ijl#1
"W ijl#1
"iL =
Wi1 L–1
WijL–1
Σ
"
#E q
= %iL sL$1
j
#W ijL$1
where %iL = 2( siL $ t iq )' &( hiL )
17
12/3/07
18
!
3
Part 7: Neural Networks & Learning
12/3/07
Hidden-Layer Neuron
Hidden-Layer Derivatives (1)
"E q
"hil
= $il
"W ijl#1
"W ijl#1
Recall
s1l
s1l–1
sjl–1
W1il
Wi1
Wijl–1
s1l+1
"il =
l–1
Σ
hil
sil
σ
Wkil
skl+1
Eq
WiNl–1
l l
d $ ( hil )
"hkl +1 " #m W km sm "W kil sil
=
=
= W kil
= W kil$ %( hil )
l
l
l
"h i
"h i
"h i
d hil
!
WNil
sNl–1
!
sNl+1
sNl
" #il = &#kl +1W kil% $( hil ) = % $( hil )&#kl +1W kil
!
12/3/07
19
#E q
#E q #h l +1
#h l +1
= $ l +1 k l = $"kl +1 k l
#hil
#h i
#h i
k #h k
k
k
k
12/3/07
20
!
Derivative of Sigmoid
Hidden-Layer Derivatives (2)
Suppose s = " ( h ) =
l#1 l#1
dW s
"hil
"
=
$W ikl#1skl#1 = dWij l#1j = sl#1j
"W ijl#1 "W ijl#1 k
ij
"
!
"1
"2
Dh s = Dh [1+ exp("#h )] = "[1+ exp("#h )] Dh (1+ e"#h )
!
#E q
= %il sl$1
j
#W ijl$1
= "(1+ e"#h )
=#
where %il = ' &( hil )(%kl +1W kil
k
"2
("#e ) = #
e"#h
"#h
"#h 2
(1+ e )
$ 1+ e"#h
1
e"#h
1 '
= #s&
"
)
"#h
1+ e"#h 1+ e"#h
1+ e"#h (
% 1+ e
= #s(1" s)
12/3/07
21
12/3/07
22
!
!
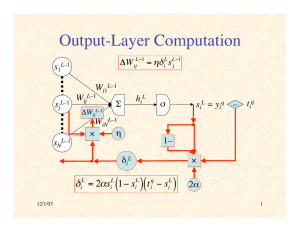
Summary of Back-Propagation
Algorithm
Output-Layer Computation
sjL–1
%E q
= "iL sL$1
j
%W ijL$1
sNL–1
Hidden layers : "il = #sil (1$ sil )%"kl +1W kil
k
!
&E q
= "il sl$1
j
&W ijl$1
12/3/07
"W ijL#1 = $%iL sL#1
j
s1L–1
Output layer : "iL = 2#siL (1$ siL )( siL $ t iq )
!
1
(logistic sigmoid)
1+ exp(#$h )
23
12/3/07
Wi1 L–1
WijL–1
!
Σ
hiL
ΔW ijL–1
WiNL–1
η
×
σ
siL = yiq –
tiq
1–
δiL
×
"iL = 2#siL (1$ siL )( t iq $ siL )
2α
24
!
4
Part 7: Neural Networks & Learning
12/3/07
Hidden-Layer Computation
l#1
ij
"W
s1l–1
l l#1
i j
= $% s
W1il
Wi1 l–1
W l–1
sjl–1 ! ij
ΔW ijl–1
hil
Σ
" = #s (1$ s
12/3/07
l
i
WNil
1–
δil
l
i
Wkil
l
i
×
)%"
l +1
k
W
l
ki
• Batch Learning
s1l+1
δ1l+1
Eq
skl+1
×
WiNl–1
×
η
sNl–1
sil
σ
Training Procedures
δk
l+1
on each epoch (pass through all the training pairs),
weight changes for all patterns accumulated
weight matrices updated at end of epoch
accurate computation of gradient
• Online Learning
– weight are updated after back-prop of each training pair
– usually randomize order for each epoch
– approximation of gradient
sNl+1
Σ
–
–
–
–
δNl+1
• Doesn’t make much difference
α
k
25
12/3/07
26
!
Gradient Computation
in Batch Learning
Summation of Error Surfaces
E
E
E1
E1
E2
12/3/07
E2
27
Gradient Computation
in Online Learning
12/3/07
28
The Golden Rule of Neural Nets
E
Neural Networks are the
second-best way
to do everything!
E1
E2
12/3/07
29
12/3/07
30
5
Part 7: Neural Networks & Learning
12/3/07
Complex Systems
•
•
•
•
•
•
VIII. Review of Key Concepts
12/3/07
31
Many interacting elements
Local vs. global order: entropy
Scale (space, time)
Phase space
Difficult to understand
Open systems
12/3/07
Many Interacting Elements
Complementary Interactions
• Massively parallel
• Distributed information storage &
processing
• Diversity
•
•
•
•
•
– avoids premature convergence
– avoids inflexibility
12/3/07
33
Positive feedback / negative feedback
Amplification / stabilization
Activation / inhibition
Cooperation / competition
Positive / negative correlation
12/3/07
Emergence & Self-Organization
34
Pattern Formation
• Microdecisions lead to macrobehavior
• Circular causality (macro / micro feedback)
• Coevolution
– predator/prey, Red Queen effect
– gene/culture, niche construction, Baldwin effect
12/3/07
32
35
•
•
•
•
•
Excitable media
Amplification of random fluctuations
Symmetry breaking
Specific difference vs. generic identity
Automatically adaptive
12/3/07
36
6
Part 7: Neural Networks & Learning
12/3/07
Stigmergy
Emergent Control
• Stigmergy
• Entrainment (distributed synchronization)
• Coordinated movement
• Continuous (quantitative)
• Discrete (qualitative)
• Coordinated algorithm
– through attraction, repulsion, local alignment
– in concrete or abstract space
– non-conflicting
– sequentially linked
• Cooperative strategies
– nice & forgiving, but reciprocal
– evolutionarily stable strategy
12/3/07
37
12/3/07
Wolfram’s Classes
Attractors
•
•
•
•
• Classes
– point attractor
– cyclic attractor
– chaotic attractor
Class I: point
Class II: cyclic
Class III: chaotic
Class IV: complex (edge of chaos)
–
–
–
–
• Basin of attraction
• Imprinted patterns as attractors
– pattern restoration, completion, generalization,
association
12/3/07
39
persistent state maintenance
bounded cyclic activity
global coordination of control & information
order for free
12/3/07
Energy / Fitness Surface
40
Biased Randomness
• Descent on energy surface / ascent on
fitness surface
• Lyapunov theorem to prove asymptotic
stability / convergence
• Soft constraint satisfaction / relaxation
• Gradient (steepest) ascent / descent
• Adaptation & credit assignment
12/3/07
38
•
•
•
•
•
•
41
Exploration vs. exploitation
Blind variation & selective retention
Innovation vs. incremental improvement
Pseudo-temperature
Diffusion
Mixed strategies
12/3/07
42
7
Part 7: Neural Networks & Learning
12/3/07
Natural Computation
•
•
•
•
•
•
Tolerance to noise, error, faults, damage
Generality of response
Flexible response to novelty
Adaptability
Real-time response
Optimality is secondary
12/3/07
Student Course Evaluation!
(We will do it in class this time)
43
12/3/07
44
8