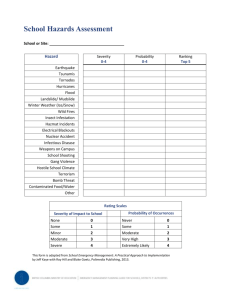
Estimating Treatment Effects with Observational Data using Instrumental
advertisement

Estimating Treatment Effects with Observational Data using Instrumental Variable Estimation: The Extent of Inference John M. Brooks, Ph.D. • Estimate casual relationships between "treatment" and “outcome” in healthcare... → → → Health Effectiveness Research Center (HERCe) Colleges of Pharmacy and Public Health University of Iowa June 26, 2005 Research Goal: Health Effectiveness Research Center → treatment on outcome; behavior on outcome; system change on behavior (e.g. guideline implementation); system change on outcome. 1 • Written as a linear relationship: 2 • Key research design issues for isolating and using “T” variation: Y = a0 + a1• T our goal is to obtain estimate(s) of “a1”. • To estimate “a1” T must move or vary. • To make inferences about “a1” the source of the variation in T must be scrutinized relative to your research goal. 1. the manner in which the researcher collects data; and 2. the approach to deal with “confounding factors” confounding factors: factors that vary both with T and Y. 3 Sources of Treatment Variation in Health Care Research Environments and Estimation Methods Statistical “Matching” Techniques (Propensity Scores) Secondary Databases Quasi-Experimental Designs 1. Randomized Controlled Trials: study of patients with a given medical condition in which treatment is randomly assigned. ANOVA Logistic Regression Instrumental Variables 4 Multiple Regression – “Ex Post Design” – “Risk Adjustment” • Why randomly assign treatment to patients? Statistical Control of Confounding Factors Design Control of Confounding Factors Weighted Regression Techniques of Survey Databases: • NMES • MEPS Entirely Controlled 2 Tests Experiment - 3 – Randomized Controlled Trials Researcher-Collected Databases To help ensure that estimated treatment effects result from the treatment variation and not unmeasured confounders. The Gold Standard 5 6 1 • Why not more Randomized Controlled Trials? → ethical problems once treatment is approved 2. Observational Healthcare Databases Containing Healthcare Treatment Choices: • Secondary: → Claims: medical service treatment claims from individuals with health insurance → expensive and time-consuming → little motivation → patient sampling problems when comparing existing treatments (so who wants to be randomized?) 7 • Strengths: → Provider-Specific: databases describing the utilization of a set of providers. • Primary: → Health Care Surveys: surveys of patients or providers detailing health 8 care utilization. • Weaknesses: → plenty of variation in treatment choice; → often data usually not collected for researcher’s purpose (secondary); → ability to study effects of treatment across a variety of clinical scenarios; → patient enrollment variation; → can assess treatments in practice – estimate “effectiveness”; → confounding information may be unobserved. - → often unobtrusively collected; → the power of large numbers and time. care not covered is not observed care not claimed is not observed claim form limitations nuances of illness, treatment, and patient that can’t be recorded on claims forms 9 Is the Main Weakness with Observational Data Unmeasured Confounders or Treatment Selection Bias? 10 • Assume true outcome relationship is: Y = ao + 1. Unmeasured Confounders a1•T + a2•L + e where: Y = measure of outcome (e.g. 1 if survive to a certain time period, 0 otherwise); • Unmeasured Confounders argument: → homogenous treatment effect (a1 same for all patients); and → unmeasured factors related to both treatment and outcome is the source of bias. 11 T = 1 if receive treatment, 0 otherwise; and L = additional factor (e.g. severity, other treatments). Goal is to estimate a1 – the effect of treatment on outcome. 12 2 • For Estimation Suppose: • Define the ordinary least squares (ANOVA) estimate of a1 as â1 . → L is not measured and the estimation model is: Y = ao + u a1•T + u = → It can be shown that under these assumptions â1 is a biased estimate of a1 through its expected value: where: (a2•L + e) E [ aˆ1 ] = a1 + Cov(T,L)•a2 → L is related to Y (a2 ≠ 0); and → Also note that E [ aˆ1 ] will equal a1 if either: → T and L are related (Cov(T,L) ≠ 0). -- Cov(T,L) = 0; or Cov(T,L) – covariance of T & L. Cov(T,L) ≠ 0 essentially means that T & L move together. -- a2 = 0. 13 • Suppose theory about the unmeasured variable “L” suggests: 14 • Problem with the Unmeasured Confounders argument to describe bias in observational data: → “a2 < 0” (patients with higher severity are less likely to survive). → No theoretical foundation linking treatments to unmeasured factors.... → Cov(T,L) > 0 (treated patients are generally more severe). • Plug in “signs” into our expected value formula to find: E [ aˆ1 ] = a1 + (+)(−) E [ aˆ1 ] < → In the example above, if treatment effect (a1) is the same for all patients, why would Cov(T,L) > 0? Perhaps patients getting treated: ( −) → Why is Cov(T,L) ≠ 0? -- live in areas with high/low poverty; -- live in areas with more pollution; or -- also tend to get other unmeasured treatments. a1. 15 2. Treatment Selection Bias (the gestalt underlying most negative reviewer’s comments) 16 • Assume true outcome relationship is: Y = bo + (b1•L) •T + b2•L + e • Treatment Selection Bias argument: → Heterogeneous treatment effect -- Cov(T,L) is a reflection of decision-maker’s beliefs about the treatment effectiveness across patients related to unmeasured factors “L”. → “Bias” comes from unmeasured factors (L) being related to the treatment choice and outcome. → Researcher must address both bias and ability to generalize (to whom do the results apply?). 17 where: Y = measure of outcome (e.g. 1 if survive to a certain time period, 0 otherwise); T = 1 if receive treatment, 0 otherwise; L = unmeasured factor (e.g. severity, other treatment); b2 = the direct effect of L on Y; and (b1•L) = effect of T on Y that depends on L. 18 3 → L is now related to T through theory linking "treatment choice" to the decision-maker’s expectations of treatment benefits across patients with different “L”. T = co + c1•L + c2•W + v where: • Ultimate goal should be to estimate (b1•L) – the effect of treatment T on outcome Y across levels of L. • For estimation suppose: T = 1 if receive treatment, 0 otherwise; L = unmeasured factor (e.g. severity, other treatment) affecting treatment choice through expected treatment effectiveness; and → L is not measured and it is wrongly assumed by the researcher that the effect of T is homogenous, and the estimation model is: Y = ao + W = other factors affecting treatment choice. If decision makers use L in treatment decisions, c1 ≠ 0 and Cov(T,L) ≠ 0. 19 → It can be shown that the expected value of â1 is: E [â ] ≈ b ⋅ E [ L | T =1 ] + c ⋅ b 1 1 2 Yields an average estimate of the treatment effect for “the treated” in the sample. Result can be generalized 21 only to those with L similar to those treated. → If treatment benefit is greater for more severe cases (e.g. antibiotics for otitis media) then: b > 0 ⇒ c > 0 ⇒ c ⋅ b = (+ )⋅ (− ) < 0 1 → Assume that L is unmeasured illness severity and that higher L means more severe illness. → Higher L lowers survival which implies b2 < 0. 1 1 1 • How does c1 • b2 affect this estimate? b < 0 ⇒ c < 0 ⇒ c ⋅ b = (− )⋅ (− ) > 0 E [â ] ≈ b ⋅ E [ L | T =1 ] 1 20 → If treatment benefit is less for more severe cases (e.g. surgery for heart attacks) then: → If b2 = 0 (L has no direct effect on Y) or c1 = 0 (no selection based on L), then E [â1 ] becomes: 1 where: u = f(L,T, e, b1,b2) • Define the ordinary least squares (ANOVA) estimate of a1 as â1 . 1 a1•T + u 2 benefit falls with higher severity 1 1 2 less treatment in more severe cases Estimate of the effect of the treatment on the treated 22 will be biased high. • So what do we have here? → Observational data contains treatment variation. → If treatment benefits are heterogeneous the best you can get is an estimate of the treatment effect on the treated (Does this address the benefits from expanding treatments?). benefit increases more treatment with higher in more severity severe cases Estimate of the effect of the treatment on the treated will be biased low. → Treatment selection may be based on unmeasured factors related to both treatment effectiveness and outcomes. → If unmeasured factors affecting selection also effect outcomes directly, estimate will be biased. 23 Do we have any alternatives? 24 4 Instrumental Variables (IV) Estimation and “Subset B” • Where do Marginal Patients come from? • IV estimation offers consistent estimates for a subset of patients (McClellan, Newhouse 1993): Marginal Patients: patients whose treatment choices vary with measured factors called instruments that do not directly affect outcomes. Distribution of Patients by Prior Assessment of the Certainty of Treatment Benefit A 0% • McClellan and Newhouse argued that estimates of treatment effects for Marginal Patients are useful. → Estimates may be more suitable than RCT estimates to address the question of whether existing treatment rates should change. B C 50% 100% More certainty about treatment benefits Less certainty about treatment benefits A = subset of patients all providers agree to treat. C = subset of patients all providers agree not to treat. B = subset of patients whose treatment choice is situation/provider dependent. 25 • Patients in Subset B are interesting because: 26 • Size and location of Subset B varies with clinical scenario. → the “best” treatment choice (treat or don’t treat) is least certain; → treatment or no-treatment for a patient in this subset is not considered bad medicine – the “art” of medicine; → the possibility of gaining new RCT evidence for patients in this subset is remote (ethics, motivation); → McClellan et al. 1994 argue that (1) policy interventions and (2) non-clinical factors (e.g. provider access, market pressures) affect mainly the treatment choices of patients in this subset. Ý treatment with little consensus (e.g. aggressive treatment for early-stage prostate cancer): A C B 0% 50% 100% More Certainty Less Certainty Ý off-label use for new treatment (e.g. new anti-cancer drugs used in non-tested cancer populations): B 0% C 50% 100% More Certainty Less Certainty 27 • Changes in the underlying population definition will affect the location of Subset B. Ý aggressive treatment for early-stage prostate cancer for 50-60 year-olds with no comorbidities: A 0% B 50% C 100% More Certainty A More Certainty 50% 1. Finding measured variables or “instruments” (Z) that: a. are related to the possibility of a patient receiving treatment (cov(T,Z) ≠ 0); and The theoretical basis for “Z” variables should come from a model of treatment choice – the “W” variables in: T = co + c1•L + c2•W + C B • IV estimation involves: b. are assumed (through theory) unrelated directly to Y or to unmeasured confounding variables (cov(Z,L) = 0). Less Certainty Ý aggressive treatment for early-stage prostate cancer for 70-80 year-olds with one comorbidity: 0% 28 100% v where: W = other factors affecting treatment choice. Less Certainty 29 30 5 • IV estimation involves con’t: • For example, if an instrument divides patients into two groups, a simple IV estimate can be found by calculating: 1. the overall treatment rate in each group (ti = treatment rate in group “i”); and 2. Grouping patients using values of the “instrument”. 2. 3. Estimate treatment effects for marginal patients by exploiting treatment rate differences across patient groups. the overall outcome rate in each group (yi = outcome rate in group “i”); and estimate: aˆ1IV = difference in outcome rate y − y2 = 1 difference in treatment rate t1 − t 2 where: Local Average Treatment Effect -(Imbens & Angrist 1994) aˆ1IV 31 • Hypothetical Treatment Choices Across Patients Grouped by Access to Providers Required for Treatment treated B M Suppose we also measured “cure” rates in both groups: C 0% More Certainty • We have treatment rates for each group: Closer Group Treatment Rate: .60 Further Group Treatment Rate: .50 Patient Group Closer to Providers Required for Treatment: A = average treatment effect for the “marginal patients” specific to the instrument used in the analysis – only those patients whose treatment choices were affected by the instrument who must have come 32 from Subset B. 100% Less Certainty Closer Group Cure Rate: .40 Further Group Cure Rate: .38 Patient Group Further From Providers Required for Treatment: • Four numbers lead to the following IV estimate: treated A 0% More Certainty M B M 50% 60% C 100% Less Certainty = patients within Subset B whose treatment choices are affected by the instrument – the Marginal Patients for that instrument. 33 â = 1IV .40 −.38 .02 = = .2 .6 − .5 .1 34 • Strict Interpretation: → If the treatment rate in the Further Group was increased .01 percentage point (e.g. .50 to .51) by increasing treatment for the M patients in the Further Group, the Cure rate in the Further Group would increase .002 (.01 • .2) – from .38 to .382. • Stretched “Policy-Relevant” Interpretation (McClellan et al. 1994) → A behavioral intervention that increases the overall treatment rate by .01 percentage point (e.g. .55 to .56) would lead to an increase in the cure rate of .002 (.01 • .2). 35 • Stretched interpretation assumes that the treatment effect for patients in Subset B is fairly homogenous and an IV estimate from a single instrument can be generalized to all patients in Subset B. • Stretched interpretation may not be accurate if treatment effects are heterogeneous within Subset B and different instruments affect treatment choices from different patients within Subset B. → Results from a single instrument may still be more appropriate than assuming RCT results apply to Subset B. → Ability to generalize results may increase if more than one instrument is used in an IV analysis. 36 6 • IV qualifiers to remember: Hypothetical Example to Demonstrate “4-Number” Result Suppose: → second property of IV variables (cov(Z,L) = 0) is forever an assumption (unless more data are obtained); • 2100 children with Otitis Media (OM) in a population. • Two treatment possibilities: → unmeasured but correlated treatments may still bias estimated treatment benefits; and → ability to generalize is limited. 1. 2. antibiotics; watchful waiting. • The patients in our sample are in one of three severity types “low”, “medium”, and “high” Researchers should fully qualify their IV estimates – don't oversell. • Severity type is observed by the provider/patient but is not observed by the researcher. 37 • The 2100 patients are distributed across severity type in the following manner: number of patients High 800 severity type Medium 800 Low 500 • The actual underlying cure rates for each severity type by treatment are: treatment antibiotics watchful waiting High .95 .80 severity type Medium .97 .90 38 → Higher severity means a lower the cure rate in general (b2 < 0). → Treatment effects are heterogeneous and antibiotics have a higher curative effect in more severe patients and offer no advantage to the less severe (b1 > 0). → All providers have inclination that antibiotics work well in the "high" severity patients; have little effect on the "low" severity patients; but the effect in the "medium" type is unknown. Low .98 .98 → Leads to treatment selection bias...the more severe kids are treated (c1 > 0) and more severe kids are less likely cured (b2 < 0). 39 40 1. Randomize Patients Across Population – ANOVA. Potential Methods to Get Treatment Variation for Analysis: 1. Randomize Patients Into Treatments -- ANOVA Patient Treatment Assignments After Randomization by Severity Type 2. Providers Assign Treatments -- ANOVA patient groups antibiotics watchful waiting High 400 400 severity type Medium 400 400 Low 250 250 3. Instrumental Variable Grouping 41 42 7 Expected average cure rates for each group: Antibiotic Cure Rate = W .W .Cure Rate = 2. 400 400 250 × .95 + × .97 + × .98 = .965 1050 1050 1050 Providers Assign Treatments -- ANOVA If providers follow “inclinations”, we may end up with something like: Number of Patients Assigned by Providers to Each Treatment Group by Severity Type 400 400 250 × .80 + × .90 + × .98 = .881 1050 1050 1050 • Unbiased average antibiotic treatment effect for the entire population (.965-.881 = .084), but patient group antibiotics watchful waiting High 800 0 severity type Medium 400 400 Low 0 500 • Estimate will vary with the average severity in the population...E[L|T=1]. • To whom does it apply? A patient randomly chosen 43 from an urn? Are patients chosen from urns? Expected average cure rates for each group: 3. Instrumental Variable Grouping – Further assume: 800 400 0 Antibiotic Cure Rate = × .95 + ×.97 + ×.98 = .957 1200 1200 1200 W .W .Cure Rate = 44 0 400 500 × .80 + × .90 + ×.98 = .944 900 900 900 • For this population the average treatment effect is on the treated (800/1200*.15 + 400/1200*.07=.123). a. Information is available to the researcher to approximate distances from patients to providers • address of patient • supply of providers in area around patients b. Evidence suggests that patients in areas with more physicians per capita have a higher probability of being treated with antibiotics for their OM than patients in areas with fewer physicians per capita. • We find a biased low estimate of the antibiotic treatment effect for the average treated patient (.957 - .944 = .013 < .123). • “Biased low” follows our theory as... 45 46 If “b” is true, divide 2100 patients into two groups based on the physicians per capita in the area around their home: Using our assumptions, does this grouping qualify as an instrument? Group 1: the group of patients living in areas with a higher number of physicians per capita. 1. Doc supply related to treatment? Yes, if patients tend to go to the closest provider for treatment. Group 2: the group of patients living in areas with a lower number of physicians per capita. 47 If true, and providers follow inclinations we may see treatment patterns something like: Patient Treatment Assignments by Severity Type patient group Group 1 High 100% antibiotics Group 2 100% antibiotics severity type Medium 80% antibiotics 20% W.W. 30% antibiotics 70% W.W. Low 100% W.W. 100% W.W. 48 8 Expected average estimated cure rates for these groups: 2. Is grouping related to unmeasured confounding variables (e.g. severity)? Related to severity only if parents chose residences in expectation of the severity of a future acute condition. If not related to severity, we assume equivalent severity distributions across groups: Number of Patients in Each Group by Severity Type patient group Group 1 Group 2 High 400 400 severity type Medium 400 400 Group 1 Cure Rate = 250 400 320 80 ×.95 + ×.97 + ×.90 + ×.98 = .959428 1050 1050 1050 1050 Group 2 Cure Rate = 400 120 280 250 ×.95 + ×.97 + ×.90 + ×.98 = .946092 1050 1050 1050 1050 Well, (.959428 - .946092) = .013336 doesn't appear to reveal much of anything…! Low 250 250 49 • Remember the actual “unknown” cure rates for each group by treatment are: Now look at the antibiotic treatment rate in each group: 720/1050 = .68571 in Group 1 520/1050 = .4952381 in Group 2 treatment antibiotics watchful waiting These differences also don't look very informative…. The IV change in the cure rates resulting from a one unit increase in the drug treatment rate equals: aˆ1IV = 50 .959428 − .946092 .013336 = = .07 .68571 − .4952381 .190471905 • This estimate is the average difference in the antibiotic cure rate for the marginal or in this example the “Medium” severity patients. High .95 .80 severity type Medium .97 .90 .07 Low .98 .98 • This estimate was found using only measured treatment rates and outcome rates across “groups” that are defined by the instruments. • Which of the estimates above is the most important for policy-makers wondering about over/underutilization of a treatment? 51 52 • General IV Estimation Model IV Brass Tacks Treatment Choice Equation (1st stage): • Where do instruments come from? T = c + c ⋅ X + c ⋅Z + (v + c ⋅L i → Theory on what motivated choices, not theory on how choices can be motivated. 0 2 i 3 i Outcome Equation (2nd stage): i 1 i ) Yi = a0 + a1 ⋅ Tˆi + a2 ⋅ X i + (ei + a3 ⋅ Li → Observed differences in: -- guideline implementation (timing/interpretation) -- product approval rules across payers -- reimbursement differences across payers/geography -- area provider “treatment signatures” -- geographic access to relevant providers -- provider market structure/competition → Generally, “Natural Experiments” (Angrist and Krueger, 2001) 53 ) Yi = 1 if health outcome occurs, 0 otherwise; Xi = measured patient clinical characteristics; Ti = 1 if patient received treatment, 0 otherwise; Tˆi = predicted treatment from 1st stage; Zi = a set of binary variables grouping patients based on values of instrumental variables (from W); and Li = unmeasured confounding variables assumed related to both Y and T but not Z. The only variation in T used to estimate a1 comes from Z. 54 9 • Define the IV estimate of a1 as aˆ1IV . → The estimate of a1 can only be definitively generalized to the patients whose treatment choices were affected by Z (Angrist, Imbens, Rubin 1996). → It can be shown that the expected value of aˆ1IV is: E [â 1 IV ] ≈ b ⋅ E [ L |T ( Z )] → F-test of whether the parameters within c3 are simultaneously equal to zero provides a test of the first instrumental variable criterion: 1 Yields an average estimate of the treatment effect for the set of patients whose treatment choices were dependent on their value of Z. Finding measured variables or “instruments” (Z) that: a. are related to the possibility of a patient receiving treatment (cov(T,Z) ≠ 0) 55 56 • How many groups? → Model can be estimated via: -- Two-Stage Least Squares (2SLS) – PROC SYSLIN in SAS. -- Bivariate Probit – BIPROBIT function in STATA. -- Two-Stage Replacement (e.g. Beenstock & Rahav, 2002). → 2SLS offers consistent estimates that are asymptotically normal with the fewest assumptions (Angrist 2001). -- essentially regressing group-level outcome rate changes on group-level treatment rate changes. → Z can be specified as continuous variables, but results are then conditional on this assumption and are less interpretable. → Creating many groups from an instrument (more binary variables in Z) uses more information and yields a weighted average of many two-group comparisons, e.g. -- low/high groups using the median of the instrument VS -- low/med low/med high/high groups using the quartiles of the instrument. → Too many groups may introduce bias. → Best to report estimates for several grouping strategies. 57 58 Introduction In a meta-analysis of observational studies, Devereaux et al (1) found that patient survival at for-profit dialysis centers was poorer than nonprofit centers. Effect of Dialysis Center ProfitStatus on Patient Survival: An Instrumental Variables Approach Objective Brooks, Irwin, Pendergast, Chrischilles, Flanigan, Hunsicker Compare estimates of the effect of dialysis center profit status on patient survival using riskadjustment and IV estimation. 59 60 10 Sample • N = Instrumental Variable Strategy 101,669 incident ESRD patients from United States Renal Data System (USRDS) from 1996-1999 that: -- were between 67 and 100 years old at dialysis initiation; -- had hemodialysis as initial modality; -- obtained dialysis in a non-government dialysis facility; -- had complete information on all model variables; -- zip codes linked to 1990 census data. Key Variable Definitions • Outcome: one-year survival after dialysis initiation = 1, 0 otherwise. • Treatment Setting: patient initiated dialysis in a for-profit dialysis center = 1, 0 otherwise. • Followed McClellan et al. (1994) and grouped patients based on Differential Distance (DD) to various hospital classifications: DD = (DFP - DNP) where DFP = distance from patient residence to the nearest for profit dialysis center; and DNP = distance from patient residence to the nearest non-profit dialysis center. • Assessed whether IV estimates were robust to the number of patient groups defined using differential distance. 61 Percent Initial For-Profit and Number of Comorbidities by Patient Differential Distance % for-profit comorbidities 0.8 % for-profit 4 0.6 3 0.4 0.2 2 0.0 for-profit closer not for-profit closer 1 -100 -50 0 50 100 Miles a not for-profit is closer 63 “Marginal” End Stage Renal Disease Patients, 1996-1999 48.1% 92.8% M 0% More Likely to For-Profit 50% Table 1: Attributes of Dialysis Patient Groups, 1996-1999 Patient Treatment Setting Characteristics For-Profit Non-Profit For Profit % 100 0 White % 70.6 73.3** Black % 23.5 20.0** Cardiac Failure % 42.6 44.2** Diabetes % 45.1 41.3** CerebroVasc Dis% 11.9 12.5** Isch Heart Disc % 32.1 36.1** AMI 11.6 13.2** a Reside in: High Hlth State % 61.2 47.4** Med Hlth State % 16.4 40.3** Low Hlth State % 22.4 12.3** Number 73,480 30,678 5 Average number of comorbidities 1.0 62 100% Less Likely to For-Profit M = patients whose dialysis center choice is dependent on the relative distance to for-profit and non-profit dialysis centers – Marginal Patients. 65 Differential Distance (DD) Patient Closer to: For-Profit Non-Profit 92.8 48.1** 74.9 67.9** 19.8 25.1** 43.1 43.1 44.8 43.1** 12.0 12.1 33.5 33.1 12.2 12.0 61.4 13.7 24.9 52,443 52.9** 33.3 13.9** 51,715 a.Subramanian, S, Kawacki I, et al. (2001). “Does the state you live in make a difference? A multilevel analysis of self-rated health in the US.” Social Science & Medicine 53(1): 9-19. **,* statistically significant at the .01 and .05 levels, respectively 64 Table 2: F-Statistics Testing Factors in Center Choice Model are Related to the Use of For-Profit Dialysis Facilities, 1996-1999. Factora Differential Distance (instrument) Year Gender Age Race Comorbidity Previous Healthcare Use State of Residence Distance to Nearest Center Area Socioeconomic Status Partial F-Statistics . 2150.53** 59.53** 5.81** 7.29** 6.26** 8.55** 2.63* 212.00** 75.41** 21.83** a. specified using binary variables reflecting differences in respective characteristic. Differential distance was used to group patients into 20 separate groups. **,* statistically significant at the .01 and .05 levels, respectively 66 11 Table 3: 2SLS/IV and Ordinary Least Squares (OLS) Estimates of the Effect of Initial For-Profit Initial Dialysis Provider Relative to a Non-Profit Provider on 1-Year Patient Survival Estimation Model Number of Instrument and Specification Groups Specified OLS no covariates na OLS Devereaux covariatesa na b OLS Devereuax covariates plus na 2SLS/IVb 2 2SLS/IVb 5 2SLS/IVb 10 b 2SLS/IV 20 2SLS/IVb 40 Estimate (P-value) -0.0031c (0.3450) -0.0122c (<.0001) -0.0071c (0.0511) 0.0009 (0.9264) 0.0025 (0.7373) -0.00004 (0.9953) -0.0002 (0.9823) 0.0006 (0.9349) a. Factors consistently controlled for in the studies within the Devereaux meta-analysis – age, gender, race, comorbidities. b. Factors consistently controlled for in the studies within the Devereaux meta-analysis – age, gender, race, comorbidities, plus dialysis year, state of residence, previous healthcare utilization, provider access (distance to nearest dialysis center), socioeconomic status (patient zip percent rural, percent poverty, and per capita income). c. Logistic regression estimates were consistent in both magnitude and statistical significance. 67 OLS estimates were reported because their interpretation is more consistent with IV estimates. Summary • The foundation of IV estimation is theory that suggests instruments – what factors motivated treatment choices. • Ability to generalize is limited, but IV estimates offer a more natural estimate of the effects of rate changes than RCT estimates. • Estimates can vary by sample and instrument used. • Estimates are conditional on the truth (and acceptance) of a known identification restriction. The source of the treatment variation is known. The relationship between this variation source and unmeasured confounders can be debated. 68 References Angrist JD, 2001. Estimation of Limited Dependent Variable Models with Dummy Endogenous Regressors: Simple Strategies for Empirical Practice. Journal of Business & Economic Statistics. 19(1):2-16 Angrist, JD, Imbens GW, Rubin, DB. 1996. Identification of Causal Effects Using Instrumental Variables. Journal of the American Statistical Association. 91:444-454. Angrist JD, Krueger AB. 2001. Instrumental Variables and the Search for Identification: From Supply and Demand to Natural Experiments. Journal of Economic Perspectives. 15(4): 69-85. Beenstock M, Rahav G. Testing Gateway Theory: do cigarette prices affect illicit drug use? Journal of Health Economics 2002;21:679-98. Brooks JM, Chrischilles E, Scott S, Chen-Hardee S. 2003. Was Lumpectomy Underutilized for Early Stage Breast Cancer? – Instrumental Variables Evidence for Stage II Patients from Iowa. Health Services Research, 38(6):1385-1402. Brooks JM, McClellan M, Wong H. 2000. The Marginal Benefits of Invasive Treatment for Acute Myocardial Infarction: Does Insurance Coverage Matter? Inquiry, 37(1):75-90. Devereaux, P., H. Schunemann, et al. (2002). “Comparison of Mortality Between Private For-Profit and Private Not-For-Profit Hemodialysis Centers. A Systematic Review and Meta-analysis.” JAMA 288(19): 2449-2457. Imbens GW, Angrist, JD. 1994. Identification and Estimation of Local Average Treatment Effects, Econometrica. 62(2):467-475. McClellan M, McNeil BJ, Newhouse JP. 1994. Does More Intensive Treatment of Acute Myocardial Infarction in the Elderly Reduce Mortality: Analysis Using Instrumental Variables", Journal of the American Medical Association. 272:859-866. McClellan M, Newhouse JP. 1993. The Marginal Benefits of Medical Treatment Intensity. Cambridge, Mass: National Bureau of Economic Research: Working Paper. McClellan M, Newhouse JP. 1997. The Marginal Cost-Effectiveness of Medical Technology - a Panel Instrumental Variables Approach, Journal of Econometrics. 77:39-64. Subramanian, S, Kawacki I, et al. (2001). “Does the state you live in make a difference? A multilevel analysis of self-rated health in the US.” Social Science & Medicine 53(1): 9-19. 69 12