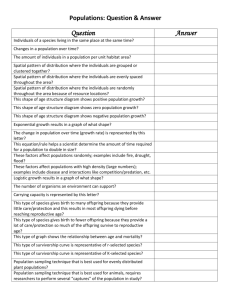
Diversity in Evolving Systems: Scaling and... Genealogical Trees Erik Rauch
advertisement

Diversity in Evolving Systems: Scaling and Dynamics of Genealogical Trees by Erik Rauch B.S., Computer Science and Mathematics Yale University (1996) S.M., Electrical Engineering and Computer Science Massachusetts Institute of Technology (1999) Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY F~ V~ j,- 7 ( 1 January 2004 rt @Erik Rauch, 2004. All rights reserved. The aumor hereby gtvlh to Mfr penmtson to reproduce and to duMibute pub* pope and elacwonic copes of this thesis documentin whole or in port Author . . . ................................ Department of Electrical Engineering and Computer Science January 30, 2004 Certified by. ................ Gerald Jay Sussman Matsushita Profgssor of Electrical Engineering Thsig's Sup ifrisor Accepted by........ Arthur C. Smith Chairman, Department Committee on Graduate Students MASSACHUSETTS INSTIuTE OF TECHNOLOGY APR 15 2004 LIBRARIES BARKER Diversity in Evolving Systems: Scaling and Dynamics of Genealogical Trees by Erik Rauch Submitted to the Department of Electrical Engineering and Computer Science on January 30, 2004 in partial fulfillment of the degree of Doctor of Philosophy Abstract Diversity is a fundamental property of all evolving systems. This thesis examines spatial and temporal patterns of diversity. The systems I will study consist of a population of individuals, each with a potentially unique state, together with a dynamics consisting of copying or reproduction of individual states with small modifications to them (innovations). I show that properties of diversity can be understood by modelling the evolving genealogical tree of the population. This formulation is general enough that it captures interesting features of a range of natural and artificial systems, though I will pay particular attention to genetic diversity in biological populations, and discuss the implications of the results to conservation. I show that diversity is unevenly distributed in populations, and a disproportionate fraction is found in small sub-populations. The evolution of diversity is a dynamic process, and I show that large fluctuations in diversity can result purely from the internal dynamics of the population, and not necessarily from external causes. I also show how diversity is affected by the structure of the population (spatial or well-mixed), and determine the scaling of diversity with habitat area in spatial systems. Predictions from the model agree with existing experimental genetic data on global populations of bacteria. I then apply the method of modelling the genealogical tree of a population to further questions in evolution. Using a generic model of a pathogen evolving to coexist with a population of hosts, I show that the evolutionary dynamics of the system can be better understood by considering the dynamics of strains (groups of individuals descended from a common ancestor) rather than individuals. A fundamental question in the study of evolution is how selection can operate above the level of the individual, and these results suggests a more general mechanism for such selection. 3 Thesis supervisor: Gerald Jay Sussman Title: Matsushita Professor of Electrical Engineering 4 Acknowledgements Yaneer Bar-Yam acted as a co-supervisor for this work and contributed especially to the presentation of the results and their relevance. Hiroki Sayama contributed to the work on host-pathogen evolution. Gerald Jay Sussman provided valuable guidance and strongly encouraged this work. Stephen Hubbell, James Tiedje, John Wakeley, Simon Levin, Mehran Kardar and Stuart Pimm provided useful comments on the diversity results. Jae-Chang Cho and James Tiedje provided the original figure with data on Pseudomonas bacteria populations. Charles Goodnight provided valuable comments on the host-pathogen evolution papers. Daniel Rothman and Joshua Weitz organized the Theoretical Ecology seminar which led to the genesis of the work on host-pathogen evolution. 5 Table of contents Overview 7 1 Scaling, dynamics and distribution of diversity 8 2 Within-species diversity - analytic and simulation results and 23 comparison with experimental data 3 Details of comparison with experimental results 44 4 Dynamics and genealogy of strains in spatially extended host- 51 pathogen models 5 Long-range interactions and evolutionary stability in a predator- 76 prey system 6 Related work 86 7 Conclusion and future work 94 6 Overview The mechanisms that give rise to the enormous variety found in natural systems are of great inherent interest. What causes the enormous variation we see in nature? Why are some species and environments highly diverse, and others less so? How can we characterize the diversity that exists? How does diversity affect evolution? These questions have been studied since Darwin's Origin of Species and before, but this thesis presents a new approach to aspects of this problem based on analyzing and simulating properties of evolving genealogical trees of populations. Chapter 1 gives an overview of the results on diversity. Chapter 2 presents the results covered in Chapter 1 in detail, and gives additional results. I also compare these results with experimental genetic data on microbial populations, showing that the distribution of diversity within populations and fundamental property relating to the shape of genealogical trees both match the data. Chapter 3 details this comparison. In chapter 4 I apply the method of dynamically tracing the genealogical tree of a population to further questions in evolution. In many systems, organisms modify their environment, which in turn affects the evolution of the organisms, but the effects of this are not yet well understood. I show that such systems can be better understood by considering evolution as the dynamics of strains (groups of genealogically related organisms) rather than individuals. In chapter 5 I use the methods of chapter 4 to explore the effect of local and long-range interactions on such evolutionary systems. Chapter 6 reviews existing work related to this thesis, and chapter 7 concludes and presents potential future work. 7 Chapter 1: Scaling, dynamics and distribution of diversity Abstract Here we introduce the method of modelling the evolving genealogical tree of a population, and show how it can be used to study spatial and temporal patterns of diversity. These results are given in more detail in Chapter 2. Why diversity is important Evolution is the phenomenon of a population of interacting individuals changing over time. We usually think of evolution as happening in biological systems, but the concept of evolution can be applied more broadly to other complex systems as well. These systems have the property that they are made up of individual elements, each with possibly unique characteristics, with new elements arising or replacing old elements in the following way: some other element or elements are copied, but occasionally small changes are introduced into the copy. The small changes can be thought of as potential innovations. The more times an element is copied, the more different it becomes from the original. For example, in a biological context, the small changes are mutations and the copying process is reproduction with inheritance. (The 'copy' does not have to be of a single individual; in sexually reproducing organisms, it is a combination of two individuals). There are several ways for interaction to take place: it can occur directly between individuals (for example, through predatator-prey interaction), but more commonly it takes place through the environment. In the simplest way to account for this, individuals can be thought of as "replacing" others because limited resources support a finite population. A population evolving according to this process explores the space of possible states that the individuals can have. A fundamental way to characterize such a population is its diversity - a measure of how much of the state space it covers. Diversity is fundamental to adaptation, which is one of the most important charac- 8 teristics of evolving systems. In complex systems, the individuals are generally coupled to a complex environment. To be suited to a complex environment, the individuals' state space must be large. To discover adaptive parts of this state space, it is more effective if the population explores it in parallel, that is, if it is spread out over a region of the state space rather than be concentrated in one part of it. The more variation exists in a population, the faster it can change[1]. Furthermore, complex environments are usually dynamic, and in order to remain adapted, the population must change in response to changes of the environment. This requires that it be flexible (that is, capable of a wide range of responses), because these new conditions may never have been experienced by the system before. However, populations generally cannot change all at once. Any 'solution' must usually start as an innovation in a single or small number of individuals, and adaptation at the level of the population happens when these innovations spread. Potential solutions could conceivably be generated by modifying existing ones when they are needed; however, when the state space is large, it generally takes a long time to discover an adaptive solution from scratch - possibly too much time for the response to happen quickly enough. Although in the immune system, variation is generated only when it is needed, evidence from biology[2] suggests that response to change is usually more effective when there is an existing pool of variation from which adaptive innovations can be drawn. This implies that effective adaptation to change also depends on diversity. Model of diversity in evolving systems I will now choose a simple state space for individuals in order to illustrate how the properties of diversity can be obtained from the genealogical tree of a population. It is chosen only for concreteness, and this method does not depend strongly on what the state space is as long as it satisfies a certain basic property I will give. Consider the state of an individual to be represented by a string of numbers, each standing for a characteristic (trait) which can change separately from the others. The string of numbers could represent a genome, for example. For simplicity, I will restrict each to be a 0 or 1. Mutation occurs when a single bit is flipped during the copying process. In the next generation, this new, mutated individual can also be copied, and further mutations can be introduced (Fig. 1). In this way, the descendants of a single individual become successively more different from each other. To measure the difference between two individuals, we need a distance metric. In the case of bit strings, we can use the Hamming distance - the distance between A and B is the number of one-bit changes needed to transform A into B. (This is similar to the measures used in genetics.) If we make 9 (00 0 00 0 00) (010000 0 (010100) (0 000 00100) distance 4 -distance 40 (10000100) Figure 1: When small changes can be introduced on copying, the descendents of an individual become successively more different from each other. A line represents a parent-offspring relationship, with time going down the page; there is one mutation per generation. the assumption that mutations are random and happen at a constant rate, then every link from parent to offspring represents a chance for a mutation. Therefore, the expected distance between two individuals is proportional to the number of links traced back until their common ancestor is reached. Diversity is a measure of how much potential variation is actually found in the population - that is, the amount of state space covered by the population. There are several ways to measure this. One can simply count the number of different types in the population. This is the measure most often used in studying biodiversity at the species level: one simply counts the number of different species represented. However, descendants that accumulate changes become successively more different from their ancestors and relatives over time, and counting the number of distinct types does not account for this. A number of individuals that are very similar to each other (close together in state space) would be measured as having equal diversity to the same number that are spread out more over the space. This can be seen in figure 1, where the additional diversity caused by additional mutations in the second generation are not counted by this measure. In order to account for differing distances between individuals, the diversity measure should have the following property: any mutation that arises that is not already found in any member of the population should increase the diversity. A measure that satisfies this criterion is the number of positions at which both 'O' and '1' are represented in the population. This is similar to measures used in genetics[3]. Just as we did for two individuals, we can trace back the ancestry of a whole population. This produces a genealogical tree, and each parent-offspring link in this tree is a chance for a mutation. Therefore, the expected diversity of the population is proportional to the number of links (the total branch length B) of the tree assuming each mutation is different. In fact, assuming that mutations happen at a constant rate, we can ignore the individual states themselves entirely, since what we are interested in is cap- 10 , , x , , Ie+05 80000 60000D(B) 40000 20000 0 20000 40000 60000 B 80000 le+05 Figure 2: The total diversity D of a population as a function of the total length B of the branches of its genealogical tree. Two cases are compared: one in which the state space (107 bits) is large enough compared to the mutation rate (it = 1 mutation per generation) that diversity is roughly linear, and one with a smaller state space (106 bits), where identical mutations tend to happen in different parts of the tree when the tree is large enough. Since we do not count these duplicate mutations in the diversity, the rate of increase of D with B slows down. tured by the genealogical tree. From here on, I will no longer consider the underlying state of the individuals, as the properties we are interested in can be obtained from the genealogical tree itself. The results will thus apply to any state space and form of mutation for which the distance between an ancestor and its descendants grows linearly with the number of generations. (If the state space is small enough relative to the mutation rate, the same mutation may appear independently in different individuals. We should not count these duplicate mutations in the diversity, so the total diversity will saturate as we consider larger and larger trees - the larger the tree, the greater the chance that the same mutation is found more than once in the tree. This method also applies in these cases, however, because there is a simple way to take this into account - Figure 2 shows the relationship between the branch length and the actual diversity). In order to determine how the diversity evolves, we need to know which individuals will reproduce, and which ones will be removed or replaced. In a real system, this may depend on the characteristics of the individual, some being more adapted than others. In evolutionary biology, this dependence is called selection. However, much work in mathematical genetics has shown that many important properties of diversity can be understood by assuming that the reproduction process does not depend on the individuals' state. Using this assumption allows us to use simple models to predict properties of the diversity of populations. In the next chapter, I will show ways in which selection can be added. 11 I will add random reproduction to the model as follows. At every time step (generation), all the individuals in the population are replaced, and each new individual is the offspring of an individual chosen randomly from a subset the previous generation. An important consideration is where an innovation can spread once it arises. Many biological systems tend towards local dispersal. For microbes in the soil, most plants, and many terrestrial animals, offspring are generally located near their parents. Long-range transmission is possible, but rare. Other biological systems combine local and longrange dispersal. For example, most spores land close to the organism that produced them, but they can be carried far away by wind or water. Marine organisms also show this mixture of local and long range, with mixing in the aquatic environment acting against locality. This important aspect can be captured in the model as follows. We can think of the population as having a fixed number A of "places" (sites), each of which is occupied by an individual. A copy can spread from one site only to others that are connected to it. These connections form a network; at one extreme, when innovations can spread anywhere (that is, when the population is well-mixed), we have a fully-connected network (Fig. 3a). At the other extreme, an innovation can be transmitted only locally; this connectivity can be modelled using a lattice (Fig. 3b). In this case, I will refer to the number of sites as "area." Intermediate connectivities can be modelled using a small-world network[4], which is a lattice with some long-range connections. In all cases, the individual at a site is the offspring of a random individual from the previous generation located at one of the sites it is connected to. Evolution of the total diversity Now that we have specified the reproduction dynamics, we can model how the diversity of a population changes over time by determining how the genealogical tree changes. New diversity continually arises when new copies, which are chances for mutations, are made. On the other hand, when an individual is removed or replaced, any of its mutations that are not shared with other individuals are lost (Fig. 4). The change in diversity is governed by the balance between the generation of variation and its extinction. When we start from a homogeneous population (or a single founder), the generation of new variants exceeds the rate at which diversity is lost through extinction, so the diversity increases over time. However, the rate at which diversity accumulates slows down (Fig. 5). Eventually, a balance between the increases and decreases is reached. The longterm average diversity, which is determined by this balance, can be thought of as the 12 (a) T=2 T=l T=O (present) (b) time oresent Figure 3: Model of random reproduction in a population. (a) A well-mixed population: each individual is descended from a random individual of the previous generation. (b) Example genealogical tree for a one-dimensional population. The bottom row represents the currently living population. The tree corresponding to the ancestry of the currently living individuals is shown as solid lines; the ancestry of those that have no descendants in the present, and thus do not contribute to diversity, is shown as dashed lines. At the arrow, a lineage goes extinct, causing the loss of any accumulated differences that have arisen on the line of descent from A, the most recent ancestor that has descendants in the present. 13 A B C D A C D Figure 4: Gains and losses of diversity. After one generation, individual A has had one offspring (adding one unit of branch length), B has had two (adding two units), and D had one (adding one). C had no offspring in the current generation, so the two units that have accumulated since it diverged from the rest of the population are lost. Total branch length increases by two units. 'ANNN1. I5051M B 10000 5000 0S ' 250 ' 500 T ' 750 ' 1000 Figure 5: Increase in diversity of a two-dimensional population with initially low diversity, before it reaches its long-term average. The dotted line corresponds to the analytic result B(t) ~ A(log(t))2 . 14 le+05 B 10000:- 100010 100 1000 A Figure 6: Average branch length B of the genealogical tree of a two-dimensional population simulated for 500,000 generations (squares) as a function of number of sites A (which can be interpreted as habitat area), compared to the analytic result B = A(Iog(A)) 2 . Also shown is the branch length for a well-mixed population (circles) compared to the analytic result B = A log A. capacity for diversity of the system. This balance can be upset by perturbing the population. For example, part of the population can be killed off, or the population may be replaced by the descendants of one highly adapted individual in a short time. However, after the perturbation, the population will return to the diversity capacity. The capacity depends on two things. First, the size of the population is very important, since the larger it is, the more opportunities for novelty there are. Second, diversity depends on the structure of the population (here modelled as the connectivity of the network). In general, the further offspring can be from their parents, the lower the diversity. Smaller dispersal distances or barriers increase diversity. This can be seen from Figure 6. Figure 6 also shows that the diversity of a spatial population, in addition to being higher than that of a well-mixed population, also grows faster with area. For example, at N = 100, the population has 6.3 times the diversity it would have if it were well-mixed, but at N = 2500, this has grown to 9.1 times. The ratio depends on the specifics of the model, but we can quantify, in a more general and robust way, the effect of a property on diversity by expressing how diversity scales with that property. For a well-mixed population, diversity scales as A log A[3]. For a two-dimensional population (Figure 6) it scales as A log 2 A. Though the logarithmic factor is not a dramatic 15 difference from the well-mixed case, the difference can grow appreciably with population size, as the example shows. For a one-dimensional population (as illustrated in Figure 3a), the difference is much larger: the branch length scales as A 2 . (There are several kinds of biological populations that have effectively one-dimensional habitats, such as those that live along coasts or rivers). These scaling results are not affected by the details of the model, such as how dispersal happens or whether multiple individuals can exist on a site. If properties of the system change, so will the diversity capacity. A decrease in population size will, of course, decrease the diversity. However, decreases do not necessarily happen because of the removal of individuals. For example, the connectivity may change, by introducing long range dispersal to a population which is locally connected. At the time of the change itself, diversity is not affected immediately, but decreases to the new capacity over time. Diversity is unevenly distributed Up to this point, we have been concerned the total diversity of a population. When we look at the genealogical tree of a simulated population (Fig. 7), we see that there are branches containing a minority of the population that diverged early from the rest of the population, such as branch A in Fig. 7. Within each particular branch, the same pattern can be seen, such as in the two subgroups of branch D. Since these groups have been separate for a long time, they have had time to accumulate mutations that make them distinct. Thus they will contain a disproportionate share of the total diversity in the population. This uneven distribution is a typical characteristic of populations. We can quantify this by considering the uniqueness of a group. This is the number of generations since its common ancestor with its most closely related group, which is proportional to how many mutations it has that are not shared with any other group. A particular individual is a member of multiple overlapping groups, so we define a group to consist of all individuals whose genealogical distance is less than Tg from the others. (This corresponds to drawing a horizontal line on Fig. 7 at a height of Tg generations, and taking each of the distinct subtrees below the line to be a group). The uniqueness has a power law distribution, shown in Fig. 8. The important features of such a distribution are that very large values can occur (the distribution has a "long tail"), and that a disproportionate fraction of the total diversity is contained in a small fraction of the population. The same distribution is found whether the population is well-mixed or spatial. Thus, the uneven distribution of diversity is a general property of such systems. 16 Ak Figure 7: An illustration of the uneven distribution of diversity: the genealogical tree for a two-dimensional population of 130 individuals. Group A diverged from the rest of the population early and so has had more time to accumulate unique mutations. It carries more of the population's total diversity than any one of groups B, C, or D, and so it accounts for a disproportionate fraction of the diversity. The most recent common ancestor is 472 generations ago. 17 0.1 ".0.01 3a - 0.0010.0001 le-05 P(u) le-06 le-07 le-08 - losses uniqueness le-09 _ 1e-10 le-11 -well-mixed - le-12r-, , r- 0 , spatial a ,,_ 0 - U- 0 0 - 0 +. - Figure 8: The distribution of diversity in populations. The plot shows the distribution P(u) of genetic uniqueness of individuals, in a well-mixed (small symbols) and a two-dimensional population (larger symbols). The horizontal axis represents uniqueness u in generations of divergence. The distribution can be fit by a power law with exponent -2.8 (dotted line). The distribution for T. = 1 (that is, single individuals) is shown, but the same distribution also applies to groups with T > 1. Also shown is the distribution of the sizes of of losses of branch length in a single time step. Because essentially randomly selected individuals die off at each time step, this has the same underlying distribution as uniqueness. The flattening of the curve for small losses reflects the effect of averaging several individuals that die off in the same time step. Data is logarithmically binned. 18 1. 0.1 0.01 0.001 0.0001 le-05 P(u) le-06 le-07 le-08 le-09 le-10 le-l1 le-12 ' - U - Figure 9: The effect of inheriting from multiple parents on the distribution of uniqueness in a population. There are assumed to be g separately inherited parts of the individual's state. For simplicity, each is assumed to be inherited from a random neigboring parent. (The effect of sexual reproduction would be somewhat less than shown here, since each unit can be inherited from one of only two parents). From left to right, g = 5, 20, and 100. When a new individual is a combination of multiple individuals (for example, in sexual reproduction), the uniqueness of the offspring is an average of the uniqueness of the contributions of the parents. This reduces the unevenness of the diversity distribution, because it is less likely that both parents are highly unique than that a single individual is highly unique. However, because of the long tail of the distribution, a large uniqueness in traits inherited from one parent is enough to make the whole individual highly unique. Fig. 9 shows that separately inheriting larger numbers of units (such as parts of chromosomes) makes the distribution tend more towards a Gaussian distribution. However, even when the number of separately inherited units is relatively high, the power law tail of the distribution remains, though it disappears when the number is very large. 19 Diversity undergoes large fluctuations Every generation, some individuals die or are replaced without leaving any offspring. This means that all their unique mutations are lost. We have seen that diversity becomes concentrated into small subgroups. Such a group could become the ancestor of the whole population, but it is more likely that it will eventually die off. When these subgroups die off, the result is a sudden decrease in diversity. Fig. 10 shows that these decreases can be very large, and cause the diversity, even when the population has reached a steady state, to continually fluctuate. Diversity builds up gradually through the accumulation of mutations, but is "dissipated" in these decreases. Fig. 8 shows that distribution of the sizes of these decreases is a power law. Because the individuals that die off without offspring are essentially randomly chosen, this distribution is essentially the same as the uniqueness distribution of individuals. Thus, large fluctuations in diversity happen even when the population is not perturbed by external forces. Since the decreases have a power law distribution, they have no characteristic time scale or size. The time between a loss of diversity of at least u scales as u2 . In the simulation, 10% of the diversity is lost in a single generation every 3,700 generations on average; a quarter is lost every 12,600 generations, and half the diversity is lost every 218,000 generations. Spatial distribution of diversity Another way to look at the distribution of diversity is how it is distributed over space. When reproduction is local, nearby individuals tend to be related to each other, and as Fig. 11 shows, subpopulations (corresponding to branches in Fig. 7) are concentrated in particular regions. This leads to boundaries between divergent subpopulations. An observer might be tempted to conclude that there are differences in the local conditions on either side of the boundary which caused the population to diverge because the subpopulations on each side have specialized, or that the boundary is due to a barrier to dispersal. Alternately, an observer might conclude that boundary is there because one of the subpopulations migrated from somewhere else. However, these boundaries are a consequence of the local reproduction process only, and do not require selection or unusual historical events in order to form. When inheritance is from multiple parents, each set of traits inherited separately has its own such pattern of diversity. 20 B 420000 20000 - 10000- 0 0 50000 5000 2W0 le+05 t Figure 10: Diversity in populations, even when they have reached a steady state, undergoes large fluctuations. The plot shows a time series of the diversity of a spatially distributed population. The diversification phase, during which the population approaches the diversity capacity, lasts roughly until time t = 20, 000 generations. Thereafter, the average remains constant but there are losses of all sizes up to about 2/3 of the total branch length. The distribution of these losses is shown in Fig. 8. The inset shows that the time series of a well-mixed population is similar. U;.. V I U d6 -6 16 Figure 11: Simulated spatial pattern of diversity in a two-dimensional space (represented as a lattice of I x 1 sites with 1 = 50). Inheritance is from one parent. In the left panel, the individuals shown in grey or black represent a genealogically divergent group whose most recent ancestor in common with the rest of the population (white) lived about 10,000 generations ago. Gray and black represent related branches that diverged about 2,000 generations ago. The four panels at right show the most divergent groups in the later evolution of the same population (in black, subgroups not distinguished), every 2,000 generations starting at t = 20, 000. 21 References [1] R. A. Fisher, The genetical theory of naturalselection (Oxford University Press, London, 1930); [2] R. Frankham, K. Lees, M.E. Montgomery, P.R. England, E.H. Lowe, D.A. Briscoe, 1999. Do population size bottlenecks reduce evolutionary potential? Anim. Cons. 2, 255-260. [3] Watterson, G. A. On the number of segregating sites in genetical models without recombination. Theor.Pop. Biol. 7, 256 (1975). [4] Watts, D.J., & Strogatz, S.H. (1998). Collective dynamics of "small-world" networks. Nature 393, 440-442. 22 Chapter 2: Within-species diversity - analytic and simulation results and comparison with experimental data' Abstract In this chapter we give analytic arguments and simulation results for the results stated in the previous chapter, and investigate additional properties of diversity. We discuss the relevance of our findings to biological systems, and show that two predictions from the model - the number of ancestors of the living population at a given time in the past, and the distribution of uniqueness - agree with existing experimental data on global samples of Pseudomonas bacteria. The study of diversity is central to biology, and the mechanisms that give rise to the enormous variety found in nature are of great inherent interest. Understanding diversity also has practical value for the conservation of biological resources [2] since it is important to the resistance of a population to disease and its adaptability to environ- mental changes [3,4]. DNA sequencing is increasingly being used to probe the genetic structure within species, providing opportunities for comparison with experiment. The genetic structure of populations has been studied using coalescent theory and related methods [5-9], including studies of subdivided and continuous populations [10, 11], and simulations have been used to study particular models of spatial populations [12]. Here, we focus on the scaling dependence of population properties - including diversity, its distribution in the population, and the sizes of losses of diversity - on key variables such as area and time. The scaling behavior is robust to many variations in the model, and provides predictions that can be compared with experiments. We first present the model in detail and show that properties of diversity can be obtained by modelling the ancestry of the population as a coalescing random walk. We use this to derive the distribution of genetic distances between individuals in the population, showing that a spatial population has a power law distribution, which is fundamentally different from well-mixed populations, which have an exponential distribution. By 23 deriving the scaling of diversity with habitat area, we will demonstrate that area has a stronger effect on within-species diversity than on species diversity. We will then give results for the power law distribution of genetic uniqueness and of the sizes of fluctuations in diversity. Model. Our lattice model for the population itself is similar to the stepping stone model [13]. The essential features of spatial populations are locality and a form of competitive interaction that results in local limitation on density. A step of the simulation consists of the birth of a new generation. At each site, new individuals are born, and we identify the parent of each organism as being either a previous organism at that site, or one at one of the neighbors (Fig. 3 in Chapter 1). Local competition is included by allowing only a fixed number nmax of individuals to exist on a given site. For simplicity, we will take nmax to be I unless otherwise noted. A well-mixed simulation is similar except that each organism can be the offspring of any parent in the previous generation (the Wright-Fisher model [14, 15]); the population remains of constant size N. Mutation will not be included in the model directly; instead, we can superimpose assumptions about mutation on the properties of genealogical trees to obtain genetic diversity. We will first make the assumption of neutrality (that natural selection plays a negligible role); thus, the individual at any site is equally likely to be the offspring of an individual at any connected site in the previous generation. We will then characterize conditions under which selection alters the results. We will also first treat the case where individuals have only one parent, which applies to genes, organelle DNA, and asexual organisms, and then use these results to obtain approximate results for sexual populations. Genetic distances between individuals. Consider an individual on the lattice at time T = 0 (the present); we will use T to stand for the number of generations before the present. The sequence of its ancestors can be traced backward in time, with the parent always located at one of the lattice sites connected to that of its offspring. The sequence of locations of the ancestors of an individual is thus a random walk. Two such walks stepping onto the same site corresponds to two individuals having a common parent; so, for two individuals x, and X2 at different locations on the lattice, the time until their common ancestor is distributed as the first intersection time of two random walkers. (Other assumptions such as different dispersal distances or migration rates, lattice geometry, overlapping generations and number of occupants per site do not change the scaling properties). If mutations are random, the number of mutations occurring since the lineages of x, and x2 diverged is binomially distributed with mean proportional to the number of generations. 24 0.11 ID 0.01 -2D 0.001 P( 0.0001 well-mixed I e-05 Ie-06, 10 100 1000 10000 T Figure 1: Distribution P(T) of pairwise genealogical distances in a two-dimensional population and a one-dimensional population (L = 150), and the analytic result P(T) = _( - )T 1 e-T/N for a well-mixed population (N = 150). Here and in subsequent figures, the two-dimensional lattice size L = 30 unless otherwise noted. It is known that in spatial populations a typical pair of individuals is more distantly related to each other than in well-mixed populations [14]. In well-mixed populations, the number of pairs at a given genetic distance from each other has an exponential distribution [5]. In spatial populations, by contrast, we find that the genetic distances have a power law distribution (Fig. 1). In a well-mixed population, there is a probability 1/N of two individuals having the same parent. With probability 1 - -, these individuals did not have the same parent, but with probability (1 - ) they had the same grandparent; and so on. A(T) is thus exponentially distributed: A(T) = (1 - ±)T-z eT/N. In spatial populations, the distribution of genetic distances is a consequence of the distribution of first intersection times of random y walks averaged over pairs of starting points. Shape of the genealogical tree. Now consider the entire population of individuals on the lattice. The ancestry of this population can be described by a spatial genealogical tree, which we will use to obtain properties of diversity. Fig. 2 shows the genealogical tree of a one-dimensional population. The lineage of each member of the current population executes a random walk. Two walkers (lineages) coalesce into one when they collide. The number of lineages L(T) is the number of individuals that lived T generations ago that have descendants in the present. L(T) decreases with time into the past as individual lineages coalesce, and is equal to the number of remaining walkers 25 Figure 2: Spatial genealogical tree for a one-dimensional population of 300 individuals. The y-coordinate represents time, with the present generation at the bottom. The ancestors of the current population are shown, with the x-coordinate representing their physical position. At left, the full tree is shown; the common ancestor is 9248 generations before the present. At right, the most recent 300 generations are enlarged. 26 in the coalescing walk. We will derive this function for well-mixed and spatial populations, compare it with experimental genetic data, and then use it to derive the scaling of diversity with habitat area. The scaling of L(T) in well-mixed populations [15, 16] can be understood as follows. In a genealogical tree, two lineages coalesce if two individuals have the same parent in the previous generation. In the Wright-Fisher model of a well-mixed population, each lineage can be thought of as jumping to a random site on each time step (time being measured as number of generations before the present), with multiple lineages on the same site coalescing. The number of lineages L(T + 1) in generation T + 1 is therefore the number of distinct individuals in L(T) samples from the set of ancestors in generation T + 1 with replacement. Let p(T) = L(T)/N be the fraction of individuals in generation T that have descendants in the present. For p(T) sufficiently small (that is, when T is not small) we can neglect all but pairwise coalescence. The probability that two lineages coalesce into the previous generation is p(T) 2 when p(T) is not large, with a resulting change in p(T) of Ap ~ -p 2 /2 (the factor of 1/2 arises because only one lineage is lost for a pairwise coalescence [17]; still, the scaling behavior depends only on the proportionality of change to p 2 and not on the coefficient), which = -p 2 /2, giving p(T) = 2, i.e. the scaling behavior: in the continuous limit is p(T) ~' In a spatial population, L(T) can be expressed as p(T)Ad, where d is the population density, A is the habitat area, and p(T) is the fraction of individuals in generation T that have descendants in the present. p(T) is the probability that a given site is occupied at time T in a coalescing random walk starting with all sites occupied. Expressions for p(T) in different dimensions have been derived [18]; in two dimensions, p(T) - 1/vi/t and in two dimensions, p(t) ~ log(T)/T. Thus, the scaling behavior of L(T) with time for a spatial population differs from that of a well-mixed population by a logarithmic factor, which is a relatively small distinction when compared to the quite different scaling behavior of the distributions of pairwise genetic distances. Comparison with experimental data. An experimental test of this model is shown in Figure 3. L(T) was obtained from a clustering analysis of Pseudomonasbacteria [19] sampled at different sites around the world. The experimental data is long-tailed, and this tail is well approximated by both the well-mixed and spatial prediction. It is important to emphasize, however, that the original theoretical result is the result expected for the genealogical tree of the entire population rather than a limited set of samples of the population, as was obtained in the experiment. We thus performed 27 theoretical calculations using simulations (shown in the figure) that directly represented the sampling of the population at specific geographical locations used in obtaining the Pseudomonasdata. To model the sampling of the population, we directly represented the organisms at the specific geographical locations where the Pseudomonas samples were obtained. In the simulations, lattice cells represent a physical region of the earth. 248 lineages were placed at sites whose cells contain the latitude/longitude coordinates of the 248 samples in the Cho and Tiedje data. At each step of the simulation, moving backward in time, a lineage performs a random walk staying in place or moving to a neighboring site. At its destination, with a certain probability pc, it coalesces with other lineages at that site. Pc and the number of simulation time steps NT corresponding to one unit To of biological time, as well as the lattice size, are adjustable parameters. The parameters were set by a simple fitting procedure that adjusts the intercepts of L(T) at the L and T axes but does not affect the shape of the curve. The parameters were adjusted to simultaneously fit both L(T) and a different property of the same genealogical tree: the distribution of genetic distinctiveness, that is, the number U(T) of samples whose most closely related sample diverged from it T generations ago, as described below. No special allowances were made for earth curvature or topography (e.g. oceans) that might affect the last few points, which represent global dispersal of only a few most ancient lineages. The result is the solid line in Fig. 3. To understand this curve, we note that the deep part of the genealogical tree (long times) corresponds directly to the scaling result given for the full population (thin line in Fig. 3). This result is consistent with the recognition that the samples taken from all over the world should be a complete representation of the deepest part of the genealogical tree. An extrapolation of this curve to T/To = 1 gives a rough estimate of the total diversity of the population, in terms of the number of genotypes that could be distinguished at the level of resolution of the data (a genomic similarity value r = .95), suggesting on the order of 1,000 genotypes. For the part of the curve corresponding to recent times, the sampling should underrepresent the number of lineages in the genealogical tree. This can be seen the figure as values of L(T) which are lower than the scaling result for the full population for short times. The degree to which the sampling underrepresents the tree, however, depends on the spatial structure of the population. Although a simulation of a well-mixed population also matches the data from samples taken from around the world, it does not match a spatially correlated sub-sample. The lower data points (diamonds) in Fig. 3 correspond to a sub-sample consisting of the samples taken in California. A comparison with what would be expected for a completely mixed population (dotted line in Fig. 3) shows it is inconsistent with the experimental results for the spatially correlated sampling. Therefore, the overall 28 (a) 1000 0 L(T/To) 10: io0I10 100 1000 T/1O (b) L(Tfr,) *e. 100 Figure 3: (a) Number of lineages as a function of time in the past L(T), comparing experimental data (circles) and a spatial simulation of the sampled population (solid line). The dotted line corresponds to theory for the whole population. The L-intercept of this line provides a rough estimate of the genetic diversity of the entire population, that is, on the order of 1000 genotypes that could be distinguished at the level of resolution of the data. (b) A comparison of the spatial and well-mixed cases. L(T) for a subset of the sampled population consisting of the samples from one geographic region is shown as stars, with a comparison of a spatial (dashed line) and well-mixed (dotted line) simulation of the subset. The experimental data (circles) and simulation (solid line) for the full population is as in part (a). The spatial simulation matches the data for the spatially correlated sample more closely, indicating the importance of spatial structure. Experimental data was obtained from Cho and Tiedje [19]. Time T in the past (the current generation being at T = 0) is normalized by dividing by To, the time to the smallest genetic difference considered. The number of simulation time steps NT corresponding to one unit To of biological time is 160 and the coalescence probability p, is 0.15. 29 diversity of the California samples is lower than it would be if the population were well-mixed. A spatial simulation of the ancestry of the California samples alone, using the same parameters as for the full simulation, matches the experimental data for the California samples. This effect of correlated spatial sampling occurs only for the case of a spatially structured population, and not for a well-mixed population where local samples and random samples would be equivalent. The results confirm the importance of spatial structure to the Pseudomonasglobal population. The results of spatial theoretical calculations closely match the experimental data over its full range. Details of our method are given in the appedix. Scaling of diversity with area. Area is an important factor in biodiversity. The area of habitat available to organisms has been found to be a primary determinant of their diversity above the species level, as measured by the number of species [20, 21]. Experimental results have found that the number of species S in a sample area A scales as S = AZ on most scales, with z typically 0.25 and ranging from 0.15 to 0.4 [20,21]., and this scaling has been modelled theoretically [20,22]. We will now use the scaling of L(T) to derive the scaling of the total diversity within a population. Geographically limited dispersal has been found to increase diversity in many species [23] (including human Y-chromosome [24] and mitochondrial DNA [25]). Geographic differentiation has been found in viruses [26], bacteria [19], plants [27], trees [28], invertebrates [29], amphibians [30], mammals [31] and birds [32], both in two-dimensional and one-dimensional [33] habitats. Every parent-offspring link in the ancestry of the living population represents a chance for mutation. Therefore, diversity is a function of the total length of all branches of its spatial genealogical tree. A key difference between species diversity, as measured by the number of species, and genetic diversity is that the former treats all species as equally distinct, not considering the degree to which species are different from each other. The measures used in this paper, by contrast, count additional mutations along a lineage that make a descendant progressively more different from its ancestor and relatives. We can obtain the branch length B by summing the number of lineages over all generations in the past up to the expected time TA of the most recent common ancestor of the population. Any mutations that occurred before the most recent common ancestor will be shared by the whole population and will not contribute to diversity. Thus, B =ZTA L(T). TA is the expected time at which there is only a single lineage, and is obtained by set30 ting L(TA) = 1. Any individuals that do not have descendants in the present are not counted in B, thus excluding mutations that have become extinct. Under the assumption that the same mutation is not likely to arise more than once in the ancestry of the population (sometimes known as the "infinitely many sites" assumption), the genetic diversity measured as the total number of distinct mutations is proportional to B. If this assumption does not hold, we must ensure that mutations that are found more than once in the tree are counted only once; thus the expected number of distinct mutations in the population is D(B) =a " (1 - e-LB), where 1 is the per-genome mutation rate and pL is the probability of a particular mutation arising at a particular locus. (This is akin to the Jukes-Cantor correction for estimating the divergence time between two sequences, but in reverse [34]). Fig. 2 in Chapter 1 shows that diversity is roughly proportional to branch length for a range of plausible mutation rates, but saturates for high mutation rates (or small genomes). In two dimensions, L(T) is proportional to A*I , implying that TA scales as A log(A), so the branch length scales as: B(A) ~ A[log(A) + log(log(A))]2 - A(log(A)) 2 Thus, for a two-dimensional habitat, B grows somewhat faster than area, but by a relatively slowly increasing factor of log 2 (A). Still, this implies a much faster increase with area for genetic diversity than has been measured for species diversity. Fig. 6 in Chapter 1 shows that this function well approximates the average diversity of a simulated population. We can also consider an effectively one-dimensional habitat, whose topology corresponds to a number of natural habitats such as rivers and coastal or tidal zones, if the width of the habitat is not much more than the dispersal distance. In one dimension, L(t) ~ . The expected time of the most recent common ancestor TA ~ A 2, and so the branch length scales as: B(A) ~ A L' dT ~ A 2 Thus the total branch length in one dimension grows much faster than length or population size; it quadruples when length or population size is doubled [35]. This is different from well-mixed populations, whose diversity scales as N log N, where N is the population size [5]. These results assume that dispersal occurs to a neighboring site. When there is longer-range dispersal (e.g. with Gaussian dispersal distances), and local populations are effectively well-mixed within the dispersal distance, the same scaling results should 31 be expected, as long as the dispersal distance is significantly smaller than the size of the habitat. This was confirmed by simulations. When some dispersal happens at long distances, a transition between spatial and well-mixed behavior is expected. The above has also assumed that there is no recombination; in sexual populations, the tree for different portions of the genome (such as genes and organelle genomes) may be different. However, the diversity-area relationship is essentially the same in sexual and asexual populations. To illustrate the effect of recombination, consider the following hypothetical extreme case: each individual has g separately inherited units of the genome, each inherited independently from a random neighboring individual in the previous generation without linkage. Each unit has its own genealogical tree, and total diversity is the sum of the contribution of each unit. Thus, the total is the same as in an asexual population with the same per-genome mutation rate [36]. Another measure of diversity is the average genealogical distance between individuals, sometimes known as nucleotide diversity [37]. In nonspatial and spatial populations alike, the scaling of this quantity is the same as the scaling of the most recent common ancestor of the whole population. In a well-mixed population, the average genealogical distance between members of the population is Aavg = fOT A(T) = N. In a spatial population, the average genealogical distance Aavg between members of the population is the first hitting time of a pair of random walkers, averaged over all walks and pairs of locations. This quantity scales as N 2 in one dimension and NlogN in two dimensions [38]. Founding and perturbation. The dependence of diversity on habitat area or population size implies that habitats have a diversity capacity. A population in which mutation and extinction are in balance in the long term will have a long-term average diversity equal to this capacity, though the genetic makeup of the population will be constantly changing. (A similar concept applies to species richness [22]). Diversity may be lower than the capacity of the habitat due to recent founding of the population or to perturbations that kill off part of the population. A population with initially low diversity increases in diversity until its average reaches the diversity capacity. In a spatial population, we can assume that the size of the population increases to its long-term average in a time much shorter than TA, the time to most recent common ancestor in a non-perturbed population, since the time to populate an unoccupied habitat scales as A1/ 2 in two dimensions (given a uniform rate of spreading) whereas TA scales as A(log(A)) 2. (In one dimension the values are A and A 2 respectively). Given this assumption, the genealogical tree looks like that of a non-perturbed population, except its more distant history is effectively "cut off" by the diversity-reducing or found- 32 1.2e+06 I e+06 8e+05 B 6e+05 4e+05 2e+05 5000 I e- 5 T 1.5e+05 2e+05 2.5e+05 Figure 4: Increase in diversity of a one-dimensional population with initially low diversity, before it reaches its long-term average TA. The dotted line is the analytic result B (t)~, A Vt. ing event. Diversity at a time of t generations after the event is B(t) ~' fL(t) dt for t < TA, giving B(t) ~ Avft in one dimension; the fraction of diversity recovered by time t is F(t) = Vt/A. In two dimensions, B(t) ~ A(log(t)) 2 and the fraction F(t) = (log(t)/log(A)) 2 . In a well-mixed population, B(t) ~ Nlog(t) F(t) = log(t)/ log(N). Figs. 4 compares these results to simulations in one dimension, and Fig. 5 in Chapter 1 does the same for two dimensions. Thus, initially the increase proceeds rapidly but it slows down with time, and continues until full recovery at time t = TA. Whether events that cause the loss of most of a population's diversity affect its long-term average diversity therefore depends on the frequency of such events relative to TA; if the time between events is large compared to the recovery time, they will not decrease the long-term average. Diversity may also be higher than the capacity of the habitat, as when a population is restricted in range to part of its original habitat or moved to a smaller one. Though the diversity may remain high in the short term, it will eventually decrease to the capacity of the smaller habitat. Effect of selection. Selection can impact diversity in at least two ways. Spatially varying selection (that is, local adaptation) favors different genotypes in different parts of the habitat. This causes barriers to dispersal which will tend to increase the diversity of the whole population, though it may decrease diversity in a local area. On the other hand, spatially uniform selection, in which particular mutants can have higher fitness anywhere in the habitat, can decrease diversity, since the descendants of a mutant can take over the population in a short time, thus wiping out the population's existing diversity before an equivalent amount of diversity has had time to develop in the descendants of the mutant. (This is known as periodic selection or genetic hitchhiking [39,40]). We 33 define a periodic selection event to be one where the descendants of a mutant take over the population in a time less than the recovery time TA, and denote the rate of such mutations arising in an individual as AR. (Mutations that take on the order of TA generations are not distinguishable from neutral mutations.) Whether periodic selection affects the long-term average diversity therefore depends on the frequency of such selected mutants arising relative to the recovery time TA; if the time tE = 1/uRN is large compared to TA, average diversity will be systematically reduced. As area increases, both N and TA increase (larger populations require longer to recover their diversity), so A may reach a size at which selection causes the rate of increase in diversity with area to slow. A first approximation for the reduced diversity when the time between events is smaller than the recovery time is B(t = tE), where B(t) is the diversity at t generations after a founding event, giving B - A[log( 1 )]2 in two dimensions; more rigorous and comprehensive results for well-mixed populations are given in Ref. [39]. Distribution of diversity and its fluctuation. Unlike the result on relatedness, which allows us to distinguish well-mixed and spatial populations, the following results are similar for both well-mixed and spatial populations, illustrating their highly robust (universal) nature. The uniqueness u(i) of an individal, which we use to quantify how diversity is distributed within the population, is defined as the number of generations to i's most recent common ancestor that has another currently living descendant. The mutations that took place since that ancestor are not shared with any other member of the population. Since the probability distribution P(u) is a power law (Fig. 8 in Chapter 1), u has no characteristic size. Its distribution implies that a disproportionate fraction of the genetic diversity is typically contained in a small fraction of the population. This distribution can be understood as follows. The probability P(U > u) that an individual has uniqueness greater than u is the probability that its lineage, traced backward through time, never exists on a site that has another lineage for all T < u. In the well-mixed model, the probability that no other lineage jumps to a particular site is: (-_)p(T)N t-- exp(-p(T)) p(T) is approximately A, with a measured from simulations of p(T) to be 1.95, and expected analytically to be 2. This gives: P(U > u) flu= exp(-g) exp(-alog(bu)) 34 = 2 exp(-a F U-a 1 ) Thus the exponent depends on the coefficient a of the scaling of p(T). The probability density is P(u) = - , giving: P(u) ~ U-ai u -- 2.95, consistent with both the well-mixed and spatial simulations of P(u). The scale-free distribution of uniqueness also applies to subgroups defined by a given level of relatedness T.. For each individual, define its subgroup by the identity of its ancestor T. generations ago. We define the uniqueness ug of the group to be the uniqueness of the ancestor. The genealogical tree of the ancestors of these groups have the same properties as that of the present population of individuals, only starting with a smaller initial value of L(T). Thus, their uniqueness follows the same power-law distribution. In Fig. 5, we compare these results to experimental data. The above distribution applies to the whole population. Sampling changes the distribution by making it longertailed, corresponding to a greater proportion of individuals which are more unique with respect to the sampled population. We obtained U(T), the number of samples whose genetic distance to their most closely related sample is T, from the same genetic data as in Fig. 3. Fig. 5 compares this distribution with a simulation of U(T) for a sampled spatial population. By adjusting the parameters of the simulation, we simultaneously fit both U(T) and L(T); the simulation is in good agreement with experimental data using the same simulation parameters as in Fig. 3. In sexual populations, uniqueness is the sum of u(i, g) over all genes g. Figure 9 in Chapter I shows the distribution of uniqueness for sexual populations for different numbers of independently inherited units. Summing the uniqueness of these multiple units changes the shape of the distribution, making smaller values of u rarer, and medium values of u more common relative to large ones. However, the long-tailed, power-law character of the distribution remains, and very divergent individuals can still occur in the power-law tail. For the figure we use the simplifying assumption that each unit is independently inherited from a random connected site. Each can actually only be inherited through one of two parents, which correlates the trees with each other, and genes are not inherited independently because of linkage, so the actual change in the shape of the distribution is not as great. Diversity is often characterized using measures such as Wright's FST [41], which measures the degree of differentiation between subpopulations relative to the diversity of the whole population. However, the unevenness of the distribution of genetic diversity among individuals is not adequately captured by FST. Divergent individuals and groups do not necessarily correspond to geographically isolated populations, and if a 35 100 10 0 U(T/To) 0 1 0 0.1 0.01" 1 10 T/To 100 Figure 5: Distribution of diversity in a population, comparing experimental values of U(T/To), the number of samples with a uniqueness of T/To, for a sampled Pseudomonas population (circles) and average over 1,000 spatial simulations (solid line). We normalize T by dividing by To, the time to the smallest genetic difference considered. Sampling causes a shallower slope than the distribution for the whole population, and this exponent is matched by the simulation. The simulation and its parameters are as in Fig. 3. 36 divergent subgroup is not identified as a subpopulation for the purposes of calculating FST, much of its contribution in the form of unique mutations will not be counted because of the averaging within subpopulations. Furthermore, a single subpopulation, if it diverged long enough ago, may contribute a significant fraction of the total diversity of a population, but most of this contribution will not be recognized because of the averaging over subpopulations. For a model with N well-mixed populations arranged spatially (the stepping stone model), FST has been calculated to grow only weakly (as log(N) [42]). The uneven distribution of diversity in populations causes large fluctuations in total diversity over time (Fig. 10 in Chapter 1). Since individual death is random, the amount of diversity lost due to the death of an individual is distributed as P(u). The levelling off of the curve for small losses is because the several losses that occur in a single time step are averaged. As with the distribution of genetic uniqueness, recombination affects the shape of the distribution, but the long tail remains (Fig. 6). Biological relevance. Although the models used here are simple, the results are robust to changes such as different density or multiple occupancy of a site, overlapping generations, and, for spatial populations, different dispersal distances (as long as they are significantly shorter than the habitat size). These features do not change the scaling of diversity or the nature of its distribution and fluctuations. The results show that genetic diversity is very unevenly distributed in the population. Furthermore, diversity has its own internal dynamics, which are distinct from possible outside influences such as habitat change and species interactions. Increases happen only gradually, but large decreases may occur without a corresponding extrinsic perturbation. Our results imply that the genetic diversity of a population strongly depends on habitat area, supporting the growing recognition of the dramatic effects that the loss of habitat area loss has on the diversity of populations. Indeed, while the observed number of species scales as a weak power of the area, so that a reduction in area by a factor of 16 causes a reduction in number of species by a factor of 2 [20], the effect on within-species genetic diversity is much more dramatic. It only requires a reduction in area by a factor of 2 to cause a reduction in diversity by more than a factor of 2, and the effect is much more dramatic in one-dimensional habitats where the same loss of area gives rise to a loss of 3/4 of the genetic diversity. From the point of view of conservation efforts, our result that diversity is unevenly distributed within species suggests that the preservation of genetic diversity may often lie in the identification of specific highly unique individuals or groups and ensuring their continued reproduction. The relevance of valuing individuals or groups for con- 37 (a) 10000 r 1000 g=20 100 10 0.1 0 0.01 0.001 0.0001f -- 10 100 1000 M 10000 le+05 100 +5 (b) 10000 = 100 g= 10 I rg=10 0.1 r8=20 0.01r 0.001 0.0001" 10 "" 100 1000 T Figure 6: Distribution of the number of unique mutations lost per generation for different numbers g of heritable units. No linkage is assumed; linkage causes less averaging and hence a smaller reduction in the size of fluctuations. g = 1 corresponds to organelles or asexual populations. (a) The number of loci per heritable unit is kept constant for all g, so the per-genome mutation rate Ip increases with g. The per-gene mutation rate is 1. (b) The total size of the genome I is kept constant for all g (p has a constant value of 1), so the per-locus mutation rate pI is set to P. 9g 38 servation by their genetic uniqueness [3,43-45] is underscored by our results. The results also suggest, however, that a highly variable diversity is a characteristic of populations in nature. Our result on the spatial distribution of diversity (Fig. I1 in Chapter 1) is relevant to explanations of the evolutionary history of species. Explanations for the occurrences of divergent populations in particular areas, and the existence of boundaries between divergent types, are often sought either in habitat variation or in a past migration event. The model shows that highly divergent populations can arise even without specific geographic barriers or adaptation to divergent habitats, particularly when there is no recombination. Though boundaries between particular lineages move and disappear after a finite time, the balance between diversification and extinction leads to the constant presence of strong genetic boundaries which are not due to past population movements or specialization to divergent habitats, but rather to historical accidents. These divergent populations are not necessarily confined to a single area, however; alleles can be geographically widespread in a population with strong geographic structure, and the occurrence of particular alleles in widely separated areas in an asexual or sexual population does not imply that the population is well-mixed. Thus the spatial patterns of genetic variation that arise in homogeneous habitats in the absence of migrations or disturbances must be considered before making inferences about the properties and history of a population, particularly when analyzing mitochondrial DNA, sex-linked chromosomes or sets of genes that are strongly linked. References [1] Rauch, E. & Bar-Yam, Y. Scaling, dynamics, and distribution of within-species diversity (manuscript). [2] Ehrlich, P.R. & Wilson, E.O. Biodiversity studies: science and policy. Science 253, 758-761 (1991). [3] Amos, W. & Balmford, A. When does conservation genetics matter? Heredity87, 257 (2001). [4] Frankham, R., Lees, K., Montgomery, M.E., England, P.R., Lowe, E.H. & Briscoe, D.A. Do population size bottlenecks reduce evolutionary potential? Anim. Cons. 2, 255-260 (1999). [5] Watterson, G. A. On the number of segregating sites in genetical models without recombination. Theor: Pop. Biol. 7,256 (1975). 39 [6] Hudson, R. R. Gene genealogies and the coalescent process. Oxford Surv. Evol. Biol. 7, 1-44 (1990). [7] Barton, N.H. & Wilson, I. Genealogies and geography. Phil. Trans. Roy. Soc. B 349,49-59 (1995). [8] Epperson, B.K. (1993). Recent advances in correlation studies of spatial patterns of genetic variation. Evol. Biol. 27:95-155. [9] J. Wakeley, T. Takahashi, Mol. Biol. Evol. 20,208 (2003). [10] Notohara, M. The structured coalescent process with weak migration. J. Appl. Prob.38, 1-17 (2001). [11] Wilkins, J. F. & Wakeley, J. The coalescent in a continuous, finite, linear population. Genetics 161, 873 (2002). [12] G. A. Hoelzer, J. Wallman, D.J. Melnick. The effects of social structure, geographic structure, and population size on the evolution of mitochondrial DNA. II. Molecular clocks and the lineage sorting period. J.Mol. Evol. 47, 21-31 (1998). [13] Kimura, M. & Weiss, G.H. The stepping stone model of population structure and the decrease of genetic correlation with distance. Genetics 49, 313-326 (1964). [14] Wright, S. Isolation by distance. Genetics 28, 114-138 (1943). [15] Fisher, R. A. The distribution of gene ratios for rare mutations. Proceedingsof the Royal Society of Edinburgh,50, 205-220 (1930). [16] S. Wright. Evolution in mendelian populations. Genetics 16, 97-159 (1931). [17] A more precise recursion relationship for the Wright-Fisher model is p(T + 1) = (1 - eP(T)). [18] Bramson, M. & Griffeath, D. Asymptotics for some interacting particle systems on Zd. Z fuer Wahr 53, 183-196 (1980). [19] Cho, J.C. & Tiedje, J.M. Biogeography and degree of endemicity of fluorescent Pseudomonasstrains in soil. Appl. Env. Microbiol. 66, 5448-5456 (2000). [20] M.L. Rosenzweig, Species Diversity in Space and ime (Cambridge Univ. Press, Cambridge, UK, 1995). 40 [21] Condit, R., Hubbell, S.P., Lafrankie, J.V., Sukumar, R., Manokaran, N., Foster, R.B. & Ashton, P.S. Species-area and species-individual relationships for tropical trees: A comparison of three 50-ha plots. J. Ecol. 84, 549-562(1996). [22] S. P. Hubbell, The Unified Neutral Theory of Biodiversity and Biogeography (Princeton University Press, Princeton, 2001). [23] J. C. Avise, Phylogeography: The History and Formation of Species (Harvard University Press, Cambridge, MA, 2000). [24] Zerjal, T., Beckman, L., Beckman, G., Mikelsaar, A.V., Krumina, A., Kucinskas, V., Hurles, M.E. & Tyler-Smith, C. Geographical, linguistic, and cultural influences on genetic diversity: Y-chromosomal distribution in Northern European populations. Mol Biol Evol 18, 1077-1087 (2001). [25] Richards, M., Macaulay, V., Torroni, A. & Bandelt, H.J. In search of geographical patterns in European mitochondrial DNA. Am. Jour Hum. Genet. 66, 262-278 (2002). [26] Bowen M.D., Rollin, P.E., Ksiazek, T.G., Hustad, H.L., Bausch, D.G., Demby, A.H., Bajani, M.D., Peters, C.J. & Nichol, S.T. Genetic diversity among lassa virus strains. J. Viml. 74, 6992-7004 (2000). [27] Schiemann, K., Tyler, T. & Widen, B. Allozyme diversity in relation to geographic distribution and population size in Lathyrus vernus (L.) Bernh. (Fabaceae). PlantSyst. Evol. 225, 119-132(2000). [28] Lee, S.W., Choi, W.Y., Kim, W.W. & Kim, Z.S. Genetic variation of Taxus cuspidata Sieb. et Zucc. in Korea. Silvae Genet. 49, 124-130 (2000). [29] Elderkin, C.L. & Klerks, P.L. Shifts in allele and genotype frequencies in zebra mussels, Dreissenapolymorpha, along the latitudinal gradient formed by the Mississippi River. J.N. Amer BenthologicalSoc. 20, 595-605 (2001). [30] Rowe, G., Beebee, T.J.C. & Burke, T. A microsatellite analysis of natterjack toad, Bufo calamita, metapopulations. Oikos 88, 641-651 (2000). [31] Goossens, B., Chikhi, L., Taberlet, P., Waits, L.P. & Allaine, D. Microsatellite analysis of genetic variation among and within Alpine marmot populations in the French Alps. Mol. Ecol. 10, 41-52 (2001). 41 [32] Baker, A.M., Mather, P.B. & Hughes, J.M. Evidence for long-distance dispersal in a sedentary passerine, Gymnorhina tibicen (Artamidae).Biol. J.Linnaean Soc. 72, 333-342 (2001). [33] Clausing, G., Vickers, K. & Kadereit, J.W. Historical biogeography in a linear system: genetic variation of Sea Rocket (Cakile maritima) and Sea Holly (Eryngium maritimum) along European coasts. Mol. Ecol. 9, 1823-1833 (2000). [34] T. H. Jukes, C. R. Cantor, in MammalianPotein Metabolism, M. N. Munro, Ed. (New York: Academic Press, 1969). [35] Because rivers and coastlines are often fractals, the scaling behavior should be more generally given by B(A) ~ A , where d is the fractal dimension. [36] Since D is a measure of genetic diversity, it does not include the additional phenotypic diversity of new combinations enabled by recombination which is important when gene interactions are present. [37] M. Nei, Molecular Evolutionary Genetics (New York: Columbia University Press, 1987). Chains Markov Fill. Reversible and J. Aldous [38] D. Manuscript, on Graphs. Walks Random and http://www.stat.berkeley.edu/users/aldous/book.html. [39] Kaplan, N.L., Hudson, R.R. & Langley, C.H. The "hitchhiking effect" revisited. Genetics 123, 887-899 (1989). [40] Majewski, J. & Cohan, F.M. Adapt globally, act locally: the effect of selective sweeps on bacterial sequence diversity. Genetics 152, 1459-1474 (1999). [41] S. Wright. Evolution and the Genetics of Populations,vol. 1: Genetic and Biometric Foundations(Univ. Chicago Press, Chicago, 1968). [42] Cox, J.T. & Durrett, R. The stepping stone model: new formulas expose old myths. Ann. Appl. Prob. 12: 1348-1377 (2002). [43] Faith, D.P. Genetic diversity and taxonomic priorities for conservation. Biol. Cons. 68, 69-74 (1994). [44] Crozier, R.H. Preserving the information content of species: genetic diversity, phylogeny, and conservation worth. Ann. Rev. Ecol. Syst. 28, 243-268 (1997). 42 [45] Moritz, C. Defining evolutionarily significant units for conservation. Trends Ecol. Evol. 9, 373-375 (1994). 43 Chapter 3: Details of comparison with experimental results' 2 Abstract In this chapter, we describe in detail the comparison of theoretical results with experimental genetic data on global populations of bacteria given in the previous chapter. We address the robustness of the methods used to extract the data, and of our comparison with theoretical results on the shape of the genealogical tree and the distribution of diversity. The data was obtained from the results of Cho and Tiedje [3] on global samples of Pseudomonasbacteria. They sampled the soil of pristine ecosystems (Mediteranean woody grasslands and Boreal forests) at ten geographic locations on five continents, taking multiple samples at each location along 200 meter transects. From these samples they cultured 248 strains of phosphorescent Pseudomonas bacteria. They compared them by genomic fingerprinting, characterizing the genetic distances between them using digitized gel images prepared from repetitive extragenic palindromic PCR with a BOX-Al R primers (BOX-PCR) according to the protocol of Ref. [4]. Cho and Tiedje constructed a hierarchical clustering dendogram from effective distances between the digitized gel images. From their dendogram, we obtained counts of the number of ancestors at a particular effective genomic similarity (r-value) as measured by this fingerprinting technique to obtain L(r), corresponding to the number of ancestors that existed at a time such that their living descendants have diverged to a similarity value of r. L(r) was sampled at intervals of 0.05. For r-values less than 0.45, the sampling resolution was doubled because of the smaller intervals between coalescences in this range. In order to obtain L(T), the r-values were first mapped onto DNA-DNA homology values h using a regression curve h = V1.046 - (1.15 - r ) 2 obtained from experimental results[5], as shown in Figure 2. These results are from Xanthomonas, a genetically similar bacterial genus, whose r-values were obtained using the same protocol as the Pseudomonasresults, and whose h-values were obtained using AFLP. There is substantial noise in this data; however, this noise does not impact on the 44 comparison of the Pseudomonas data with theoretical results. Because each value of L(T) is determined by measurements of multiple isolates, the impact of noise is reduced. Moreover, both noise in the values of r and h and variation in the transformation between them has little impact on the results described in the paper, since the comparison is with the robust scaling behavior. To verify this, noise was added to the r-values of the original data with the same variance as the data in Figure 2. Figure 3 shows that the resulting L(T) values are not substantially affected. We note that the only significant sensitivity to noise is found in the region just above T/To = 1000 where the original points are least in agreement with theory and the size of the error is approximately the difference between data values and the theoretical curve, suggesting that even this disagreement may be due to noise. The effect of systematic changes in the shape of the fitted r-to-h curve were also tested and found insignificant. The h-values were then mapped onto values proportional to T using the Tajima form[6] of the Jukes-Cantor correction. In the figures, this is normalized by dividing by To, the time to the smallest genetic difference considered(r = .95)[7]. The final results are shown as circles in Figs. 3 and 5 in Chapter 2. 45 % Similatity C . - vamu r ) ] *i-Ir 11 EWt~IT I -I -A :1LLf K-, It r I~1 'I 4 *1 L1 p I .4 1 -g *1 ''I L '-.4- 1! - 4 -1 Figure 1. Dendrogram of Pseudomonas bacteria showing values at which L(r) was sampled as vertical lines. 46 . . .. *. .. . E Z 0 20 -4) 60) 1WM W) BOX-PCR r value( 100) Figure 2. Regression curve fit to experimental data (red line) on DNA-DNA homology values as a function of BOX-PCR r-values (adapted from Rademaker et al.[5]). The large amount of noise in the data has little impact on the comparison of experimental data with theory, as discussed in the supporting online text and Figure 3. 100 - - L(T/To) 10:0 0 1 10 100 1000 T/TO Figure 3. Sensitivity of L(T) to noise. The figure shows the data extracted from the original experimental values (circles) and the data extracted after the addition of noise (plusses). Gaussian noise was added to the r-values with the standard deviation (a = .12) of the data in Figure 2. Since the r-value of a coalescence between two subtrees is an aggregate of individual data points, the error in the r-value of a particular coalescence depends on the number of lineages that are coalescing, with less noise when there are more samples. For an aggregate of number of lineages m, the error in an aggregate coordinate is reduced by the factor V/ii, and the error in the relative coordinate (r-value) of two such aggregates is reduced by the square root of the geometric mean of their numbers of lineages (i.e. this is the error of the effective distance between them as a relative coordinate). Thus, Gaussian noise was added to the r-value of each coalescence between two branches that have m 1 and m 2 lineages respectively ( with standard deviation ao r-value between two lineages is a. + , where 47 ao = o/V 2 so that the noise for the Simulation of sampled population Here we describe specifics of the simulation of the sampled population (solid line in Figure 3 in Chapter 2, and dashed line in figure 5 in Chapter 2) and the fitting of parameters. The lineages of the sampled population were simulated directly as random walkers, with simulated time corresponding to time in the past. Any walkers that moved onto the same site coalesced with probability pc = 0.15. Initial random walkers were placed, one per isolate, on a 50 x 25 lattice on sites whose coordinates were proportional to the latitude and longitude of samples of the Cho & Tiedje data (Table 1). In order to produce a curve that is smooth at long times, the average of 100 runs was taken. Error bars for the simulation are shown in Fig. 4. Latitude -34.00 Longitude I y-coordinate 116.25 x-coordinate] num. of lineages 7 41 116.12 8 41 53 -122.48 18 7 39 -122.48 18 7 39 -33.85 -70.48 7 15 8 -32.95 -71.08 7 15 5 -33.07 18.67 7 27 20 53.68 -105.37 19 10 24 54.00 -106.58 20 10 5 52.65 -102.38 19 10 5 -32.38 40.17 40.48 52 Table 1. Coordinates of isolates in Cho & Tiedje data. The theoretical simulations included a fitting of two parameters. These parameters do not set the key features of the comparison - the slopes of the long and short time behaviors - but rather only set the intercepts (offsets), since the shape of the curve is highly constrained by the theory. The fitting of the two parameters, shown in Figure 5, is determined by the two intercepts. The slope of the long-time portion of the curve (the scaling regime) is determined by the scaling of the number of lineages, which has no adjustable parameters. 48 100- L(T/TO) 10 - 1 10 100 T/o 1000 Figure 4. L(T) for spatial simulation of the sampled population, showing standard deviation of 100 runs as error bars. Experimental data is shown as circles. References [1] Rauch, E.M. & Bar-Yam, Y. Diversity is unevenly distributed within species (manuscript). [2] Rauch, E.M. & Bar-Yam, Y. Characterizing the amount of genetic diversity in a population by simulating its genealogy (manuscript). [3] J. C. Cho, J. M. Tiedje, Appl. Env. Microbiol. 66,5448 (2000). [4] J. L. W. Rademaker, F. J. Louws, F. J. de Bruijn, in A. D. L. Akkermans, J. D. van Elsas, F. J. de Bruin (eds.), Molecular MicrobialEcology Manual, suppl. 3 (Dordrecht: Kluwer Academic Publishers, 1998). [5] J. L. W. Rademaker et al., Int. J. Systematic Evol. Microbiol. 50, 665 (2000). [6] F. Tajima, Mol. Biol. Evol. 10, 677 (1993). [7] Cho & Tiedje found r-values of individual samples to be reliable only for differences of 0.1; however, the average implied in the use of many such measurements to determine L(r) allows a finer grid down to 0.05. 49 (a) 0- pC = 0.07 0- p, 0.15 L(T/T0 ) to ooe 10 100 -- p =0. . 1000 To (b) -- T =80 -T =160 -- T =320 100 L(T/TO) to 0- I I 10 100 1000 TO Figure 5. Effect of varying the two parameters of the model. (a) The coalescence probability pc. (b) The number of simulation time steps NT corresponding to one unit To of biological time. 50 Chapter 4: Dynamics and genealogy of strains in spatially extended host-pathogen models' Abstract In the previous chapters, we have used the method of tracing the genealogical tree to study how diversity evolves within populations. In the next two chapters, we will use this method to understand the the dynamics of evolution in a population that differs in that it interacts ecologically with another population. Using a generic spatial model of a pathogen infecting a population of hosts (which can also be considered a predator-prey system), we examine the spatial and temporal dynamics of strains (pathogens descended from a common mutant ancestor). Instead of diversity, we will study the dynamics of evolution of a trait. In the model, the transmissibility of the pathogen can evolve by mutation. Strains of intermediate transmissibility dominate even though high-transmissibility mutants have a short-term reproductive advantage. Mutant strains continually arise and grow rapidly for many generations but eventually go extinct before dominating the system. We find that, after a number of generations, the mutant pathogen characteristics strongly impact the spatial distribution of their local host environment, even when there are diverse types coexisting. Extinction is due to the depletion of susceptibles in the local environment of these mutant strains. Studies of spatial and genealogical relatedness reveal the self-organized spatial clustering of strains that enables their impact on the local environment. The method of genealogical tracing enables us to show that selection acts against the high-transmissibility strains on long time scales as a result of the feedback due to environmental change, and provides a more general measure of evolutionary fitness that reflects the importance of time scale in evolutionary processes. Our study shows that averages over space or time should not be assumed to adequately describe the evolutionary dynamics of spatially-distributed host-pathogen systems. 51 Background Evolution in host-pathogen systems is a topic of great interest because pathogen generation times are short, and hence adaptation can occur rapidly [2,3]. There are many medically and ecologically relevant examples of pathogen evolution, such as the emergence of drug-resistant strains [4] and the decreased virulence of introduced control agents [5]. Host-pathogen systems are typically not well-mixed, but rather are spatially distributed. Mutant pathogen strains arise locally, and considerable variation in type is possible from one locality to another [6]. Moreover, host and pathogen densities are inhomogeneous and dynamic. It has become apparent in recent research that inhomogeneities in spatially distributed populations can fundamentally change the dynamics of ecological systems [7,8], and host-pathogen systems are no exception [9,10]. Spatial extent can also fundamentally change evolutionary dynamics [11]. We note, in particular, that the characteristics of the pathogen can greatly affect the spatial and temporal dynamics of the host, which in turn affects the evolution of the pathogens. Host-pathogen systems can be considered as a type of predator-prey system, and these characteristics and our investigation also apply to predator-prey systems. Most pathogenic species are found to consist of a number of distinct strains, distinguished from one another by a mutation or set of mutations. Our study of strain dynamics will allow us to discuss the relationship of local spatial effects and the longterm behavior of the system. In particular, we will show that mutant strains can arise that (1) increase in number rapidly over many generations; (2) are spatially clustered; (3) become extinct over longer times due to the local extinction of hosts. The evolutionary dynamics can be understood as a selection process that favors different types at different time scales. There are two regimes, with a sharp transition between them: a short time regime in which mutant strains with high reproduction ratios dominate, and a long time regime in which environmental feedback causes those these strains to be selected against. The model We consider a simple spatially-extended model of a pathogen spreading through a host population. This model allows for the mutation of a single quantitative trait, the transmissibility of the pathogen from one host to another. Similar to other recent studies [12-14], mutation is part of the dynamics of the model. The evolving population is composed of different types of pathogens. We will study the mechanisms that give rise to this composition. The class of models we consider assume that reproduction of hosts and infection 52 of pathogens occur locally in space (e.g. by contact or airborne transmission rather than waterborne transmission). We also assume that infection is ultimately fatal, so that our models are relevant to the case where infection is at least usually fatal and not to the case where infected hosts normally recover with or without immunity. As a model of predator-prey systems, it is relevant to the case where predators are capable of causing the local extinction of their prey, and when a local population is "infected" with prey it cannot recover. Our main results are insensitive to the detailed aspects of the model, including not only parameter values but also the inclusion of additional factors such as uninfected host death, limited local movement of hosts, occasional long-range dispersal of hosts, and different lattice structures. Such changes affect specific values of measured quantities, but not the generic behavior of the model. Although it could be considered a model of specific systems, our investigation is one of generic properties common to many spatially distributed systems. The model without mutation The model we use [15-17] is a probabilistic cellular automaton, with possible states 0 (empty), S (susceptible host), and I (infected host). At each time step, healthy hosts reproduce into each empty neighboring cell with probability g; this occurs independently for each neighboring cell. To model the carrying capacity of the environment, each cell can have at most one host individual. Alternately, each cell can be considered to represent local populations, either absent or at carrying capacity. An infected host dies with probability v (virulence). Finally, an infected host I causes a neighboring uninfected host to become infected with probability r (transmissibility). The state transition probabilities are: P(O - S) = 1 - (1 - g), P(S --+ I) = 1 - (1 - r" 1 P(I -4 0) = v where n is the number of uninfected host neighbors, and m is the number of infected neighbors. Rand et al. [16] note that asynchronous updating does not significantly change the dynamics. The model differs from that in Ref. [13] only in the use of discrete time and the lack of death of susceptibles. Fig. 1 and 2 show snapshots of simulations after the long-term behavior is established, revealing how the geometry changes with differing transmissibility, virulence and reproduction rate. The system is spatially inhomogeneous, with host and pathogen distributed patchily, and spatial correlations in the distribution and reproduction of host 53 -1 0.2 0.6 0.4 0.8 1.0 0.2 0.4 v 0.6 0.8 1.0 Figure 1: Snapshots of the host-pathogen model with no mutation. Each of the 25 blocks is from a simulation with distinct parameter values. Transmissibility r and virulence v are varied, with host reproduction rate g held at 0.05. Green represents healthy hosts, red represents infected hosts, and black represents empty sites. The snapshots for those parameters for which hosts, but not pathogens, survive after 100 generations appear completely green. For those that appear black, the outcome is uncertain and can be either pathogen extinction or extinction of both pathogen and host. We use an L x L square lattice with periodic boundary conditions and a von Neumann neighborhood (north, south, east and west neighbors); here L = 80. and pathogen. As in all host-pathogen models, the pathogen must have a minimum transmissibility in order to propagate. In this model, the pathogen can drive the host to extinction if it exceeds a certain transmissibility [15]. Thus, there is a minimum and maximum transmissibility at which the pathogen and host can coexist. The region of parameter space in which there is coexistence has been obtained [13]. Rand et al. compared simulations of the spatially-extended model with a mean field (well-mixed) version of the model. In both cases, they considered the dynamics of a system with pathogens of transmissibility r, and introduced pathogens with transmissibility r ± Ar (Ar = 0.01). In the well-mixed version, the higher-r population always invades, driving the lower-r one to extinction but itself surviving. By contrast, in the spatially-extended version, there is a value of r above which the mutant population does not successfully invade. 54 0.2 0.6 0.4 0.8 1.0 0.2 0.4 g 0.6 0.8 1.0 Figure 2: As in Fig. 1, but with transmissibility r and host reproduction rate g varied, with virulence v held at 0.5. The model with dynamic mutation In real systems, characteristics of the pathogen can mutate, and this must be considered when making statements about the long-term behavior of a host-pathogen system. In order to investigate the evolutionary dynamics of the system, mutation should be incorporated into the dynamics of the model [12, 13]. The transmissibility becomes a variable quantitative trait which is part of an infected individual's state, rather than a global parameter. The states become 0, S, and I, (host infected with pathogen of transmissibility -r).Mutation can be introduced by assuming that there is a probability p that when a pathogen of transmissibility r spreads, the newly infected individual has transmissibility r ± E: P(O- P(S - Ir) = 1 -1(l - ) S) = 1 - (1 - g), [ P_ Pr-e + Pr+e + (1 - I)pr ET11 (PP-1 -e + LP tau"+eF + (1-P)Pr-) (2) P(IT -+ 55 0) = V where m, is the number of infected neighbors of transmissibility r. The assumption of incremental mutation will be extended later. Behavior of the model with mutation Mutation causes pathogens of differing transmissibility to coexist on the lattice. However, the system always reaches an evolutionarily stable value of r [13], and that this value is somewhat lower than the maximum value for which pathogen and host can coexist. We show in figure 3 an evolving system at intervals of 20 generations after it has reached the evolutionarily stable average transmissibility, showing patches of prey growing and being depleted by predators of various types. Fig. 4 shows snapshots of simulations with dynamic mutation for different combinations of parameters. Each snapshot is taken after 10,000 generations, a time long enough to allow the evolved transmissibility to reach a stable value, aside from fluctuations. We find that in the presence of mutation, host and pathogen coexist for a wide range of virulence and host reproduction rate. The evolutionarily stable value is substantially below the maximum possible value. Fig. 5 shows two typical time series of the average, minimum and maximum transmissibility of the population. In each case, the average transmissibility is seen to approach an evolutionarily stable value after several thousand generations, and then stay within 5% of this value. (For some combinations of parameters, the average varies over time by as much as 17%, but varies by no more than 5% for most). We show in fig. 5a and 5b that it will reach the same value whether the system starts with pathogens with transmissibility above or below this value. Dynamics of Strains An important clue to the evolutionary dynamics of the system can be seen in fig. 6, a density plot of the distribution of pathogen transmissibilities over time. Most pathogens are within 0.05 of the evolutionarily stable value of r = 0.3. However, there is an additional temporal structure that is apparent in the figure: the population appears to have offshoots that persist for tens to hundreds of generations before disappearing. These offshoots are part of the characteristic behavior of the evolving population, even after it has converged to the evolutionarily stable average transmissibility. In the plot, an example of such an offshoot occurs at time T = 26000. The offshoots are visual traces of genetically related pathogens - strains. In particular, they reflect the presence of mutant strains which substantially exceed the evolutionarily stable value of r, but then go extinct. 56 Figure 3: Snapshots of the lattice for the evolving pathogen-host model. 20 generations have elapsed between each frame. Susceptible hosts are shown as green and infected hosts are colored depending on their value of -T, as shown in the legend. In this and all subsequent figures, the system has settled to a stable value of r. The lattice size L = 100. The depletion rate v = 0.2 and prey reproduction rate g = 0.05. In the remainder of this paper, we will analyze the evolutionary dynamics by examining features related to properties of strains. We will examine: (1) the reproductive success of mutant pathogens and their descendants; (2) the lineage histories of strains; (3) the effect of pathogen phenotype on the local environment of susceptibles; and (4) the relationship of spatial and genealogical structure. Our analysis elucidates the mechanisms by which the population comes to be dominated by strains of intermediate transmissibility. We believe similar mechanisms may be at work in many natural systems. In order to distinguish the identity of strains, we track the genealogy of pathogens. A strain is the set of individuals descended from a single common ancestor. One can choose any ancestor, but when studying evolutionary dynamics, it is particularly useful to consider a mutant strain to begin when a mutation occurs. Mutant descendants of this first mutant can be considered the beginning of a new strain. To obtain adequate sampling of high-transmissibility cases, which are rare under incremental mutation because of selection, we modify the evolutionary model given in equation 2 to have large, uniformly distributed mutations: #hutations to a random value of transmissibility between 0.2 and 1.0 with a mutation rate p = 0.002. This rate is low enough that it is rare that a mutant strain itself mutates again. This modification does not significantly change the evolutionarily stable transmissibility. 57 A 0.2 g 0.6 0.4 0.8 1.0 0.2 0.4 v 0.6 0.8 1.0 Figure 4: Snapshots of the host-pathogen model with mutation after 10,000 generations. The transmissibility has evolved to an evolutionarily stable value. Each of the 25 blocks represents a simulation with different values of g and v as indicated. The dimension of the lattice L is 175, the mutation rate p is 0.15 and the mutation increment e is 0.005. 58 l ' | ' 1 ' I 0.51- 0.4 111111MO 0.3 0.2 U.16 10000 20000 30000 40000 50000 40000 50000 T (b) 0.5 1110 1111 11111 1 J- 0.4 0.3 0.2P 0.16 10000 20000 30000 T Figure 5: Time series of transmissibility r in the population, showing average, maximum, and minimum values. (a) -ris started at 0.15, below the evolutionarily stable value of 0.3. -r evolves upward to reach the evolutionarily stable value within 7,000 generations. (b) -r started at 0.49; -r evolves downward to the evolutionarily stable value, again within 7,000 generations. The virulence v is 0.2, host reproduction rate g is 0.05, lattice size L is 250, mutation rate M is 0.15, and mutation increment e is 0.005. All of the following figures use these parameters unless otherwise noted. 59 0.5 0.45 0.4 0.35 0.3 0.250 - 0.2 -0.150 10000 20000 30000 Figure 6: Time series of the distribution of -r. Each vertical slice of this threedimensional plot shows the distribution of transmissibilities at a given moment in time. Note that strains temporarily exceed the evolutionarily stable value of 0.3 but then go extinct. These correspond to the long excursions, for example at T =26000. Parameters are as in fig. 5. 60 Reproductive success of mutants and their descendants To gain insight into the reproductive success of mutants, we examine the net reproduction ratio R, which is defined as the average number of other individuals infected during the course of an individual's infection in a population where the infection is present. R has been commonly used as a measure of fitness in theoretical evolutionary studies of host-pathogen and many other ecological systems [18, 19]. In spatially homogeneous treatments of host-pathogen systems, selection will tend to increase R, and R increases with transmissibility [20]. The reason is that if two pathogens have the same number of susceptible neighbors (a condition that applies to the homogeneous version of the model), the one with the higher transmissibility has a greater probability of infecting. This is indeed the case of the reproduction ratio of initial mutants in the spatially distributed host-pathogen model; fig. 7a plots the expected number of offspring of a mutant one generation after it arises. R increases rapidly and roughly linearly with r, from a value of one at T- = 0.3 to a value of 1.4 at r = 1. This must occur due to the equivalence of the environments into which all the mutants are introduced on average. On the other hand, this conflicts with the observation that, in the model, pathogens with intermediate transmissibility dominate. The reproduction ratio averaged over many generations, in fact, has a peak at the evolutionarily stable transmissibility. Fig. 7b shows R averaged over many generations. For values of -rcentered on the evolutionarily stable value of 0.3, R is slightly greater than one. (A self-sustaining stable population without mutation would have a reproduction ratio of exactly one; here the reproduction ratio is greater than one because of mutated offspring which have lower reproduction ratios.) R is significantly lower for both higher and lower values of the transmissibility, consistent with the observation of the evolutionarily stable type. Thus, selection does not act instantaneously to favor pathogens of intermediate transmissibility. The difference between the time-averaged and mutant reproduction ratios points out the need to consider the reproductive success of pathogens over the lineage history of a strain. Lineage history of strains Figs. 8 and 9 plot a measurement of the average population size Fj (T, r) of a strain as a function of transmissibility r and number of generations T since the beginning of the strain. Strains with higher r grow much faster than ones with lower r for a large number of generations. They reach a maximum and start declining after about 30 generations and eventually go extinct. This is consistent with both Figs. 7a and b. Because 61 (a) 1.4 1.2 R 0.2 0.4 0.6 0.8 (b) 1.0005- R 0.9995 - 0.999 - 0.9985 -- 0.2 0.4 0.6 0.8 1 Figure 7: The net reproduction ratio R in an evolving population, as a function of transmissibility r. The dominant type has reached its evolutionarily stable value of r = 0.3. (a) For mutants, showing the expected number of offspring of a mutant one generation after it arises. (b) For all pathogens, averaged over 3 x 107generations. 62 r=.9 6 =. 4 2 =.3 ~=.2 0 100 200 300 400 S0 T Figure 8: The average population of mutant strains as a function of time since the first (ancestor) mutant arose. The average population is plotted as a function of time T, with curves for various transmissibilties r. High-transmissibility strains initially grow rapidly, but reach a maximum and then decline after about 30 generations. In order to collect data for all r, mutations are large - mutants' transmissibility is set to a random value between 0.2 and 1. p is 0.002; other parameters are as in fig. 5. 63 81 I I I T=38 6 4 T=100 2 T=I 1 \T1000T=0 0.2 0.3 0.4 0.6 0.8 1.0 -r Figure 9: As in Fig. 8, but the average population is plotted as a function of r, with curves for various T. Between T = 100 and T = 200, it can be seen that selection changes from favoring higher-transmissibility mutant strains to favoring strains of intermediate transmissibility. 64 1.31 1.2 R R .99 - 0.9 0. 0 40. 0 0 00 1 200 T==. 400 T 600 800 10 T Figure 10: The normalized per-generation reproduction ratio of a mutant strain R(T, r) = N(T, r) /T. Within 200 generations, this value drops below I for transmissibilities significantly greater than the evolutionarily stable type. The plot on the left shows R(T, -r)for the full range of R. To show that R(T, r) < 1 when r is not the evolutionarily stable value, the right plot shows the same data with a truncated R-axis. Parameters are as in figure 8. F (T, 7-) is the expected number of descendants of a mutant after T generations, it quantifies the reproductive success of strains. It therefore can be considered a measure of evolutionary fitness that generalizes the reproduction ratio R. In order to make a more explicit comparison with the reproduction ratio R, one can calculate the normalized reproduction ratio of the mutant strain over the course of its lineage history as a function of time R(T, p) = F (T, p)1/T, representing the average number of offspring per generation from the beginning of the strain to time T. In Fig. 10, this measure of reproductive success can be seen to decrease below one for types significantly greater than the evolutionarily stable value at around T = 200 generations. The high-r strains can grow in the short term, but die out in the long term, despite the fact that they have a higher net reproduction ratio for a significant time after they are first introduced. Considering the fitness of strains as a function of time allows one to characterize evolutionary systems in which the reproductive success of mutants differs on different time scales. The populations of such systems can contain a mixture of strains, each of which is successful on a different time scale. For a given time scale T, the most successful type for that time scale popt (T) is the value of p such that R(T, p) is maximized (popt (T) = argnaxp(R(T,p))). Figure II a shows that, for the model, one type dominates for short time scales, and another dominates for long time scales, with a sharp transition between the two scales. Since selection acts differently on a given type at different time scales, one can determine the relevant time scales for a particular type. For all types p define the time scale T (p) at which selection acts against p as: 65 $ Pes we can (a) (b) 1.U 6000.8 T 40- 0.6 200 0.4 I 0 500 T 1000 0 0.2 - 0.4 0.6 0.8 1.0 T Figure 11: Time scale of selection. (a) The most successful type r4 pt(T) as a function of time since the beginning of the strain. Types of high transmissibility (those with high values of R in figure 7a) dominate for time scales shorter than about T = 175, while types close to the evolutionarily stable type (those with high values of time-averaged R in figure 7b) dominating on time scales longer than T = 250. (b) The time scale T, (r) at which selection acts against strains of pathogens with transmissibility T. T,(7-) is 0 for r < re,, indicating that selection acts instantaneously. For -r> re, the time scale is very long for values close to re,, converging on T, 180 for high r. Parameters are as in figure 8. T,(p) = minT such that for all t > T , F (t, p) < F (t,Pe,) Thus for some T < T,(p), mutants of phenotype p have more descendants than those of pe,. The time scale at which the evolutionarily stable type begins to dominate is given by TL = minT such that Popt (T) = pea. For the host-pathogen system, figure 1 lb shows T,(7) (p = t). For -r < 7-,, T,(7) = 0 since these low-transmissibility types have a disadvantage on all time scales. For r > Tea, T (-) approaches a constant number of generations (about 200 for the parameters used in figure 1 lb) but is larger when r is close to re,. Thus, for r > r,,, on time scales significantly shorter than T., the dynamics of the relative frequencies of different types can be determined from their values of the net reproduction ratio R; on longer time scales, other mechanisms are essential to the dynamics, such as the feedback between the population and the environment. In general, when a type has a short-term advantage (R(p) < R(pea)), T,(p) is a quantitative measure of the time scale in which instantaneous change in frequency dominates the evolutionary dynamics for that type. Finally, one can measure the long-term invasibility by a particular strain. Define the limiting invasionfitnessF1 (p) of type p to be 1iMT _,'F(T,p). of type p. Similarly to R averaged over time, F peaks at the evolutionarily stable value. However, considering 66 fitness to be a function of time, rather than a single number, allows one to characterize the time-inhomogeneous nature of evolutionary systems in which short-term and longterm fitness are different. Because some of the individuals in the population can be of rapidly-reproducing types that have high short- or medium-term fitness but low long-term fitness, considering only the strain fitness F plus mutation-selection balance does not present a complete picture of the long-term composition of types in the population. Instead, the distribution of types P(p) in the population is related to F as follows: P(p) f* T = n.+,s Fi(T,p) A(PI)(f JT 7 (TIp71) where pL(p) is the rate of initial mutants of type p arising, and ne, is the average number of individuals of type pe, present; ne, must be measured directly since the integral of Fi(T, p,,) is infinite. P(p) measured numerically agrees with the above (except for types which are within 0.1 of the evolutionarily stable type, since these strains take a long time to decline and were not tracked longer than 1000 generations). Relationship of pathogen type and spatial structure To understand the lineage history of strains, it is helpful to examine the relationship of pathogen phenotype and the local environment of susceptible hosts. Fig. 12 shows a mutant strain 50 generations after it arose, with a value of -r that is significantly above the evolutionarily stable type. This strain has arisen from a single ancestor at time to which mutated from a lower value of r. By time to + 250, the strain has become extinct. The figure suggests that the local environment is significantly altered by the mutant type. Fig. 13 shows enlarged views of two panels of Fig. 1, where it can be seen that the local configuration of susceptibles that an average pathogen finds itself in changes with r. Thus, the characteristics of the pathogen shape the host patches that they find themselves in. While a complete characterization of the local envrironment is difficult, we can consider the local density of susceptible hosts adjacent to an infected host as a first approximation. Using this measure, the effect of the pathogen phenotype on the local environment of susceptible hosts is apparent in Fig. 1, where only a single type is present in any one simulation. Fig. 14 shows that the characteristic length scale of host patches also changes with r. 67 0 .25 .5 .75 1 Figure 12: A snapshot of the model with mutation, with r shown as color as indicated in the legend. Yellow represents a high-transmissibility (r = 0.9) mutant strain which arose 50 generations ago. Hosts are shown as dark green. The lattice size L is 175. We see that the mutant strain is spatially clustered and is depleting the hosts from its local environment. This environmental change leads to the eventual extinction of the strain. 68 (a) (b) Figure 13: Magnification of the model with no mutation, showing an example of how transmissibility governs the local spatial structure of susceptible hosts the pathogens find themselves in. (a) The transmissibility r is 0.2. (b) r is 0.45. -=0.15 - 0.8 - 0.6 0.25 =0.35 T=0.40 -- 0.45 c(d) 0.40.2- OL 0 20 40 60 80 100 d Figure 14: Spatial auto-correlation c(d) in healthy hosts as a function of distance d. The decrease with distance shows the characteristic length scale of host patches. The inset shows the characteristic length scale 1 of the patches as a function of r, the length at which the correlation drops to 1/e. (Note, however, that the extinction of the parasite for high r is not necessarily due to the length scale approaching the size of the lattice; high-r populations can eventually go extinct even an infinite system). 69 1=0.29 0.8- - r=0.3 0.7- T=0.9 0 X 4 a 0 IN IM I4* T Figure 15: The contact rate, p (the number of neighboring susceptible hosts), averaged over all individuals infected with a strain of a particular type, as a function of time since the strain first arose. Within 40 generations, the local environment in the vicinity of the strain has been changed from the value characteristic of the evolutionarily stable type to a value characteristic of the mutant strain. This characteristic value is plotted in fig. 16. Parameters are as in fig. 8. Strains that arise by mutation are generally located in an area whose local environment has been determined by the strain it mutated from. We find, however, that after the first mutant arises, the new strain changes the local environment, measured by the local density, to the environment that is characteristic of it. Fig. 15 shows the local contact rate of susceptible hosts as a function of the time since the strain arose, where the change can be seen to take about 40 generations. Fig. 16 shows an average over time of the local contact rate for the evolving system and compares it with the system with only one type. We see that, for all values of -, the local contact rate for mixed systems (with mutation) is the same as that for homogeneous systems (without mutation), even though in the mixed system, many strains exist on the same lattice and individuals are constantly mutating. 70 'I 'I 0.3(- 0.25- d 0.2- 0.15- 0.10.2 0.6 0.4 0.8 1 Figure 16: The contact rate, p, as a function of transmissibility r. Squares represent data measured in nonmutating populations where all pathogens are of the same type, and circles represent data taken in evolving populations, where many other strains with different r are present. Parameters are as in fig. 8. (Data for high -rin homogeneous systems are more variable since the pathogen drives the host to extinction and hence a shorter time series is available). 71 Spatial and genealogical structure In order for the strains to systematically modify the local spatial structure of their environment, we expect that they are at least partially spatially segregated. To study this directly, we show in fig. 17 a representation of the spatial structure of genealogical distance. In this picture, the colors show the degree of genealogical relatedness to a particular pathogen. The left and right panels show this for two different individuals at the same time in an evolving population, simulated using incremental mutations. Fig. 18 plots the average genealogical distance as a function of physical distance between the two individuals in space, averaged over all pairs at that physical distance. The genealogical distance is small for short distances, reflecting the likelihood that nearby individuals are genetically related because of the locality of reproduction. It increases for longer spatial distances, indicating that strains are physically clustered on short and medium time scales. We note that physical distance remains small for genealogical distances of hundreds of generations. This implies that the typical lifespan of mutant strains (200 generations) is small enough so that strains go extinct before spreading throughout the space. Conclusion We have shown that the evolutionary dynamics of a generic host-pathogen model can be understood by characterizing the reproductive success of strains on different time scales. Neither spatially averaged properties nor time-averaged local properties can reveal the mechanisms responsible for the long-term composition of the population. Characterizing the strain dynamics is made possible by tracing the genealogical tree of the population. In particular, we have shown that: (a) the time-averaged reproduction ratio has a maximum at intermediate transmissibilities, but the reproduction ratio of mutants when they first arise increases with transmissibility; (b) the lineage history of hightransmissibility strains shows that they grow faster than intermediate-transmissibility ones for a significant length of time before declining and going extinct; (c) the characteristics of the pathogen determine the spatial distribution of the host, and hence the environment that the pathogens find themselves in. Strains that reproduce and grow over several generations change the local environment over time, and their local effect is the same whether or not there are other types on the lattice; (d) the genealogical distance between pathogens is correlated with their spatial distance. In summary, we find that high-transmissibility strains change their environment in a way that is ultimately detrimental to their survival. However, there is a significant 72 ... 1380 0 b 1386 Figure 17: Genealogical distance between individuals in space. Distance from the individual marked by the arrow is shown as color. Yellow indicates pathogens that have a recent ancestor in common with the pathogen indicated by an arrow; red represents ones that have the most distant common ancestor (a distance of 1,380 generations). Pathogens of the same color are not necessarily related to each other. The two plots show relatedness from two different individuals at the same time. 1000 750 T 500 250 "0 10 20 30 40 50 60 70 d Figure 18: The average number of generations since a pair of individuals had their most recent common ancestor (coalescence time), as a function of their distance from each other. Since the size of the system being simulated is only 100 x 100, the levelling off of the curve may be due to the finite system size. Other parameters are as in fig. 5. 73 time delay before this change leads to their extinction. During this time, these strains take advantage of the host spatial structure generated by the evolutionarily stable type and are able to propagate rapidly before going extinct. Since new mutant strains arise by mutation, it is possible for strains which, by themselves, would drive the host to extinction, to be continually present in a population if mutations are frequent enough. In systems like the one studied, reproductive success must be thought of as a function of time. The composition of types of this, and, we believe, many natural systems, can be understood as a mixture of types, each of which is successful on a particular time scale. References [1] Rauch, E.M., Bar-Yam, Y. & Sayama, H. Dynamics and genealogy of strains in spatially extended host-pathogen models. J.Theor: Biol. 221, 655-664 (2003). [2] Anderson, R.M. & May, R.M. Coevolution of Hosts and Parasites. Parasitology 85,411-426 (1982). [3] Levin, S.A., Grenfell, B., Hastings, A. & Perelson, A.S. (1997). Mathematical and Computational Challenges in Population Biology and Ecosystems Science. Science 275, 334-343. [4] Schrag, S.J. & Perrot, V. (1996). Reducing antibiotic resistance. Nature 381, 120121. [5] Fenner, F. (1983). Biological control as exemplified by smallpox eradication and myxomatosis. Proc.R. Soc. Lond. B Biol. Sci. 218, 259-285. [6] Pielou, E.C. (1974) Biogeographic range comparisons and evidence of geographic variation in host-parasite relations. Ecology 55, 1359-1367. [7] Kareiva, P. (1990). Population-dynamics in spatially complex environments - theory and data. Phil. Trans. R. Soc. Lond. B Biol. Sci. 330, 175-190. [8] Tilman, D. & Kareiva, P. eds. (1997). SpatialEcology: The Role ofSpace in PopulationDynamics and Interspecific Interactions.Princeton Univ. Press, Princeton, NJ. [9] Mollison, D. (1977). Spatial contact models for ecological and epidemic spread. J.R. Stat. Soc. Ser: B 39,283-326. 74 [10] Comins, H.N., Hassell, M.P. & May, R.M. (1992). The spatial dynamics of hostparasitoid systems. J.Anim. Ecol. 61, 735-748. [11] Sayama, H., Kaufman, L. & Bar-Yam, Y. (2000). Symmetry breaking and coarsening in spatially distributed evolutionary processes including sexual reproduction and disruptive selection. Phys. Rev. E 62, 7065-7069. [12] Savill, N.J. & Hogeweg, P. (1998). Spatially induced speciation prevents extinction: the evolution of dispersal distance in oscillatory predator-prey models. Proc. R. Soc. Lond. B Biol. Sci. 265, 25-32. [13] Haraguchi, Y. & Sasaki, A. (2000) The evolution of parasite virulence and transmission rate in a spatially structured population. J. Theo. Bio. 203, 85-96. [14] Boots, M. & Sasaki, A. (2000). The evolutionary dynamics of local infection and global reproduction in host-parasite interactions. Ecol. Lett. 3, 181-185. [15] Sato, K., Matsuda, H. & Sasaki, A. (1994). Pathogen invasion and host extinction in lattice structured populations. J. Math. Biol. 32, 251-268. [16] Rand, D.A., Keeling, M., & Wilson, H.B. (1995). Invasion, stability and evolution to criticality in spatially extended, artificial host-pathogen ecologies. Proc.R. Soc. Lond. B Biol. Sci. 259,55-63. [17] Andjel, E. & Schinazi, R. (1996). A complete convergence theorem for an epidemic model. J.Appl. Prob.33, 741-748. [18] Fisher, R.A. (1930). The genetical theory of naturalselection. Oxford University Press, London. [19] Brommer, J.E. (2000). The evolution of fitness in life-history theory. Biol. Rev. CambridgePhil. Soc. 75, 377-404. [20] May, R.M. & Anderson, R.M. (1983). Epidemiology and genetics in the coevolution of parasites and hosts. Proc.R. Soc. Lond. B Biol. Sci. 219, 281-313. 75 Chapter 5: Long-range interactions and evolutionary stability in a predator-prey system Abstract It is now becoming recognized that spatial distribution is crucial to many ecological and evolutionary processes [1]. At the same time, many natural systems have both local and long-range connections, a structure recently modelled as "SmallWorld networks" [2], This raises the questions of whether spatial models are relevant and how spatial evolutionary systems are able to persist, since long-range interactions tend to counteract the effects of spatial separation. In this chapter, we use the predator-prey model of the previous chapter to illustrate the effect of longrange interactions on evolving systems. The evolutionary steady state in which predators are prevented from overexploiting their prey can be disrupted by the addition of long-range links. However, spatial behavior can remain even with a high density of long-range links. A parallel between this result and recent results from network theory is shown. The results suggest that the addition of long-range interactions may destabilize an evolutionary system, even if that system already contains a significant density of such interactions. Systems with larger spatial scale are more sensitive to the addition of long-range links. Traditional approaches to biological modelling represent evolutionary and ecological systems using quantities averaged over space and time. These systems are represented as the frequencies of various genes or types in the population. In this formulation, the environment experienced by a particular individual is effectively the average over all environments. Such averaging is done on the principle that spatial fluctuations become unimportant in the limit of large populations. However, real populations are distributed spatially. Organisms are located at different points in space and thus experience different environments, and interactions between organisms are local. In recent times the importance of spatial inhomogeneity on the dynamics, stability, and diversity of ecological [1] and evolutionary [3] systems has begun to be recognized; this inhomogeneity may be crucial to the predictions of evolutionary and ecological models. A common 76 theme of this work is that spatial distribution is necessary for the stability of evolutionary systems. A number of such systems are unstable when they are well-mixed (that is, when interactions are global rather than local) [4,5]. Many real spatially distributed systems, however, though interacting mostly locally, also have long-range interactions. In a biological context, long-range interactions can arise when individuals can disperse via spores or when their seeds are transported long distances, for example, or when invasive types are introduced from other locations by humans. In the limit of many long-range links, spatial models change to the behavior charasteristic of well-mixed systems. The desire to investigate the effect of long-range connections on the connectivity of natural and artificial networks has led to the study of "Small-World" networks [2], which has shown that in fact it takes only a small amount of long-range interaction to make a mostly locally interacting system behave as a well-mixed system in some respects. The prevalence of long-range interactions thus calls into question the relevance of spatial models, and raises the question of how evolutionary systems that depend on spatial separation are able to persist. The work on Small-World networks has emphasized the implications of long-range links for the diameter and average shortest path length of the network: a small fraction of long-range links (with most of the links remaining local) is enough to make these values scale as a random network (in which there is no locality), and thus allows almost any node to be reached from any other by traversing a small number of links [2,6]. The diameter of the network is relevant to the dynamics of simple processes such as the spreading of epidemics [2,7,8] and diffusion [9], and thus the phenomenon of reduced diameter captures what is important about long-range links for the dynamics of these systems. However, this is not necessarily the case for other types of dynamics on the network. Here we will study the effect of long-range links on the ability of predator and prey to coexist. Previous work has considered the evolutionary dynamics of dispersal distance in systems where this distance can evolve [10-14]. Ref. [10] showed that in a spatial predator-prey system exhibiting spiral waves, increasing dispersal distances are selected for and this may lead to the extinction of the population (though effects related to the boundary may prevent this). We will relate spatial evolution to recent work on networks, and show that the best-known "Small-World" phenomenon, the dramatic reduction in the diameter of the network that results from adding only a few links, is not the one that is relevant to the evolutionary dynamics of the predator-prey system. The stability of the predator-prey system is shown to depend on local spatial separation rather than global properties, and thus can be understood in light of the result [7,15,16] that the transition between spatial and non-spatial connectivity on a lattice as links are 77 0.80.60.40.2- 0 100 150 200 L Figure 1: Evolutionary stability as a function of lattice size L. Each point represents the probability pe, that the predator and prey will coexist for at least 100,000 generations, obtained from 10 runs. There is a sharp transition at a size Les. For the left curve (circles), the prey reproduction rate g = 0.2. For the right curve (x symbols), g = 0.05. The depletion rate v = 0.2 and the lattice size L = 250. added is not a sudden transition, but takes the form of a crossover, with the system remaining spatial on length scales shorter than a crossover distance which depends on the density of long-range links. Effect of long-range interactions In the predator-prey model, evolutionary stability requires a minimum lattice size Les. Below this size, the predator-prey system is evolutionarily unstable: a high-r strain eventually dominates the whole space and causes its own extinction (Fig. 1), thus causing the predator species to go extinct. Les is obviously related to the spatial structure of the predator and prey patches, but it is, in general, larger than the characteristic size of these patches, indicating that more than one patch is necessary for overexploiting mutants to keep from dominating the system before going extinct. With its dependence on spatial separation, the evolving predator-prey model thus provides a way to examine the effect of long-range interactions on spatial evolutionary processes. We introduce long-range connections into the predator-prey system by replacing the lattice of the model with a Small-World network [2]: we begin with a square lattice in which each site is connected to its four neighbors, and randomly rewire each link with probability p. Thus, there are 4pL 2 long-range connections; a regular lattice is a special case with p = 0. We will first assume that the connections are fixed in order to make direct connections to work on Small-World networks. We will then also consider long-range connections that arise dynamically. In the limit of p = 1, there are no local links; predators and prey can interact with 78 others anywhere on the lattice, so the predator-prey system reduces to the spatially homogeneous behavior [4, 17] in which higher-r predator strains always outcompete lower-T ones. This occurs even when this leads to the extinction of the predator, as it does for a wide range of parameter values. However, since many real systems consist of mostly local interactions with some long-range ones, we are interested in the behavior of the system as p is increased from 0. The most basic question is under what conditions the system remains stable, that is, in what cases predator and prey can coexist. Figure 2 shows the probability of predator and prey coexisting over a long time scale (100, 000 generations) as a function of p, showing that there is a sharp transition from coexistence to extinction at a value pc which depends on the parameters. For some parameters, pc can be quite high, corresponding to a small network diameter; that is, the system is stable even in part of the Small-World regime. For example, in figure 2a, as p is increased, the system becomes unstable only at a value of p at which the diameter of the network has been reduced to approximately that of a random network. Thus, the system remains in the spatially-extended regime despite long-range interaction and the Small-World effect. For the parameters in Fig. 2a, the value of pc is 0.45, so that the system is still stable when there is, on average, about one long-range connection attached to every site. The following table shows pc for a range of prey reproduction rates and depletion rates. At right is a measure of the characteristic size of the patches; the table shows the length 4, at which spatial auto-correlation drops to when there are no long-range links. pc * | g=.05 | g=. |Ig=.2| l g=.05 g=.1 g=.2 v=.1 .02 .3 1* v=.1 9.8 2.9 2.6 v=.2 .001 .02 .45 v=.2 4.8 3.3 2.6 v=.4 .0001 .002 .3 v=.4 4.9 3.5 2.5 indicates the system is stable for all p. pc is somewhat correlated with patch size (R 2 = 0.32). When patches are larger in the absence of long-range links, the system is more sensitive to the addition of links. lP, however, is only a rough indication of the characteristic spatial scale of the system, since the addition of long-range links changes its spatial structure. For some biological scenarios, such as pathogens dispersing by spores, it is more realistic that only the predator disperses long distances, and does so dynamically instead of along fixed long-range connections. We model this as follows: p describes the 79 (a) 0.8 -0.8 0.6- -0.6 0.4- -0.4 0.2- -0.2 I(p) p"l p (b) 0.93 1 0.1 0.01 0.001 0.0001 (c) T '.5 0.920.91. r 0.9 T 0.4 0.89- 0.350.88- 0.87 0.2 0.25 0.3 0.35 0.4 0.45 . o.ooo 0.00075 0.01 0.00125 P P Figure 2: (a) Evolutionary stability on a two-dimensional Small-World network as a function of p. The plot shows the probability pe, that predator and prey will coexist for 100,000 generations, as a function of p, averaged over 11 runs. This is plotted for two prey reproduction rates: g = 0.05 (circles) and g = 0.2 (squares). There is a sudden transition to instability at a density pc, defined as the density such that for all p > p,, the probability of coexistence is less than I. For comparison, the average path length 1(p) between nodes is plotted as a fraction of the average path length 1(0) for p = 0 (dashed line, same scale). The dotted line shows the value of l(p)/l(0) for a random network. Note the logarithmic scale of p. The depletion rate v = 0.2 and the lattice size L = 250. (b) The evolutionarily stable reproduction rate r, as a function of p on a 2D Small-World network, averaged over the last 200 generations of 10 runs of 100,000 generations. r,, is also plotted for values of p for which the predators go extinct; these values are indicated with shading and the average of the last 200 generations before extinction is plotted. (c) As (b), but for g = 0.05. 80 probability that a predator (pathogen) will have a chance to disperse to a randomly chosen site, and the pathogen infects with probability r if that site contains a host (prey). This leads to similar results, although the value of pc is increased: PC g=.1_] g=.2 1* .8 v=.1 1 g=.05 .1 v=.2 .005 .2 1* v=.4 .001 .02 .9 Insight into the nature of the transition to instability can be gained by examining the evolved reproduction rate res of the predators. Increasing the density of longrange interactions raises res. Figures 2b and c plot the evolved average value of the reproduction rate res as a function of p, showing that higher values of p are associated with higher res. This is consistent with exploiting predators being able to escape local extinction more easily through long-range links. Evolutionary stability and Small-World phenomena The work on Small-World networks has found that adding a small density of links to a locally connected network causes these networks to have an average path length and diameter that scales logarithmically with the number of nodes, like a random network, even though most links are nearest-neighbor links like those of a lattice. By contrast, on a lattice, the maximum distance between two nodes scales polynomially in the number of nodes N: in two dimensions, for example, it scales as vH. Further work has elucidated the nature of this phenomenon and the transition to small-world behavior [7,18]. The small-world phenomenon of shortening path lengths is actually effective only between nodes that are more than a certain distance 6(p) from each other on the underlying lattice (that is, the distance on the lattice without the addition of long-range links). For nodes whose distance on the underlying lattice r is less than this crossover distance, the path length still scales linearly in r. Thus, a spatially extended network with long-range links retains its spatial connectedness in local areas, and only exhibits the small-world property between more distant nodes. 6 depends on the link density p, and adding additional long-range links to the network shrinks the neighborhood in which "large-world" scaling of distances holds. Figure 3 plots the average path length 1 between nodes whose distance on the original lattice is r, showing that this length scales linearly for r < 6 but is approximately constant for r > 6. 81 80 - ' ' I ' r p= - ' ' 10-4- 1 ' i ' 60- P=I0-3 1 40- P= 2020 0 20 40 60 80 100 10-2 120 140 160 r Figure 3: (a) Average path length 1 as a function of distance r on the original lattice and density of long-range links p. The lattice size L = 250. Discussion The original work on Small-World networks emphasized the sudden nature of the transition to short path lengths between nodes. However, there are at least two "small world phenomena": the abrupt reduction in the diameter of the network, which is relevant to global properties of the system, such as the time for a spreading process to reach all sites; and the crossover between "large-world" and "small-world" behavior. The persistence of spatial behavior in the presence of long-range links suggests that the latter is more relevant to processes, such as the predator-prey dynamics, that occur at particular length scales. The predator-prey system can remain stable even when the network diameter has been reduced considerably, even in some cases to that of a random network, showing that the reduction in average path length is not the relevant phenomenon for understanding the effect of long-range interactions. The system undergoes a transition from stability to instability as p is increased and the crossover distance (or spatial neighborhood size) decreases, suggesting that characteristically spatial behavior can remain if the spatial neighborhood size is large enough to allow the necessary spatial separation. The simulation results show an inverse relationship between the characteristic size of the patches and pc This, and the observation that p is a decreasing function of , suggest that the larger the spatial structure in the distribution of predator and prey, the smaller the density of long-range links it takes to destabilize the system. The link density pc at which the system becomes unstable has a corresponding spatial neighborhood size (pc). This value is, in general, larger than the characteristic length scale of the patches. If the spatial size of the system is such that there is only a single patch on average, this patch can be taken over overexploiting strains, caus- 82 ing the extinction of the system. There need to be several patches within the spatial neighborhood size in order for the overexploiting strains to go extinct. The fact that the system can remain in the spatially-extended regime despite longrange connections suggests that evolutionary systems that depend on spatial separation can be robust to the presence of long-range interactions. Accordingly, spatially extended models can be appropriate to such systems even when they have long-range interactions, as long as the density of links is not too high. There are many other processes in spatially extended biological systems that operate on particular length scales, and such systems may, as the predator-prey system, require spatial separation only in a limited spatial neighborhood for their characteristically spatial behavior. Possible other systems include formation of patterns in ecosystems by short-range activation and longer-range inhibition [19] and pattern formation in excitable media, such as spiral waves [20]. The transition from spatial to homogeneous behavior can be sudden, however. In the predator-prey system, this transition takes the form of the extinction of the predator when enough links are added. As shown in fig. 2, adding a few links at the critical value of p allows an overexploiting predator strain to dominate the system before depletion of prey causes its extinction, leading to the extinction of the predator species (and in some cases the prey as well). Thus, the effect of increasing long-range interactions in a system depends on how close it is to the transition, but systems with larger spatial structure are more sensitive to destabilization by increasing long-range interactions. References [1] Tilman, D. & Kareiva, P., eds. (1997). SpatialEcology: The Role of Space in PopulationDynamics andInterspecificInteractions.Princeton Univ. Press, Princeton, NJ. [2] Watts, D.J., & Strogatz, S.H. (1998). Collective dynamics of "small-world" networks. Nature 393, 440-442. [3] Sayama, H., Kaufman, L. & Bar-Yam, Y. (2000). Symmetry breaking and coarsening in spatially distributed evolutionary processes including sexual reproduction and disruptive selection. Phys. Rev. E 62, 7065-7069. 83 [4] Rand, D.A., Keeling, M., & Wilson, H.B. (1995). Invasion, stability and evolution to criticality in spatially extended, artificial host-pathogen ecologies. Proc. R. Soc. Lond. B Biol. Sci. 259, 55-63. [5] Rauch, E. M., H. Sayama, and Y. Bar-Yam (2002). Dynamics and genealogy of strains in spatially extended host-pathogen models. J. Theor. Biol. 221, 665-664. [6] Newman, M. E. J., Moore, C., and Watts, D. J. (2000). Mean-field solution of the small-world network model. Phys. Rev. Lett. 84: 3201-3204. [7] Moukarzel, C.F. Spreading and shortest paths in systems with sparse long-range connections. Phys. Rev. E 60, R6263. [8] Moore, C. and M. E. J. Newman (2000). Epidemics and percolation in smallworld networks. Phys. Rev. E 61, 5678-5682. [9] Jespersen, S., and Blumen, A. (2000). Small-World networks: Links with longtailed distributions. Phys. Rev. E 62, 6270-6274. [10] Savill, N.J. and Hogeweg, P. (1998). Spatially induced speciation prevents extinction: the evolution of dispersal distance in oscillatory predator-prey models. Proc Roy. Soc. Lond. B x 265: 25-32. [11] Savill, N.J. and Hogeweg, P. Competition and Dispersal in Predator-Prey Waves. TheoreticalPopulationBiology 56, 243-263 (1999). [12] Koella, J.C. (2000). The spatial spread of altruism versus the evolutionary response of egoists. Proc Roy. Soc. Lond. B 267: 1979-1985. [13] Murrel, D.J., Travis, J.M.J. and Dytham, C. (2002). The evolution of dispersal distance in spatially-structured populations. Oikos 97:229-236. [14] Rousset F, Gandon S. (2002). Evolution of the distribution of dispersal distance under distance-dependent cost of dispersal. Jour.Evol. Biol. 15: 515-523. [15] Barthelemy, M. and Amaral, L.A.N. (1999). Small-World Networks: Evidence for a Crossover Picture. Phys. Rev. Lett. 82, 3180-3183. [16] Moukarzel, C.F., & Argollo de Menezes, M. (2002). Shortest paths on systems with power-law distributed long-range connections. Phys. Rev. E 65, 056709. [17] de Aguiar, M. A. M., Rauch, E. M., and Bar-Yam, Y. (2003). On the mean field approximation to a spatial host-pathogen model. Phys. Rev. E 67, 047102 (2003). 84 [18] Sen, P., and Chakrabarti, B. (2001). Small-world phenomena and the statistics of linear polymers. J.Phys. A 34, 7749. [19] Hutson, V., and Vickers, G.T. (2000). Reaction-diffusion models. In The Geometry of EcologicalInteractions,U. Dickmann, R. Law and J.A.J. Metz, eds. Cambridge University Press, Cambridge, pp. 461-486. [20] E. Meron (1992). Pattern formation in excitable media. Phys. Rep. 218, 1. 85 Chapter 6: Related work Abstract The prior work which is most relevant to this thesis is identified in the introductions to Chapters 2, 4, and 5. Here we describe and briefly give key results from these and additional related works. Scaling and dynamics of diversity Genetic structure in spatial populations. The theoretical study of genetic structure in populations dates the work of Wright [1,2] and Malecot [3,4]. Their work on "isolation by distance" models the dependence of genetic distance on spatial distance in populations with spatial structure. More recent work on this topic is reviewed in Ref. [9]. More recently the genetic structure of populations has been studied by studying properties of the genealogical tree of a population, a method known as coalescent theory, and related methods [5-10]. They study the time to most recent common ancestor and the time between successive coalescences, for eaxample. In a well-mixed population, the time TA until the most recent common ancestor scales as the population size N [5]. These works, however, have not generally focused on the scaling of diversity in populations or its distribution within a population. Coalescent methods normally assume a well-mixed population, but have been extended to models that include structure in the population. Approaches to modelling spatial structure in these related works generally have generally been of two types: island models and stepping stone models. Island models contain an infinite number of of panmictic populations with migration between them; individuals migrate at some rate to other populations chosen at random [2, 11]. Thus they model the effect of separation but not spatial extent. A major reason for the use of this model is analytic tractability. Ref. [12] gives results on genetic structure using this model. The time to common ancestor is also linear in population size in the island model [11, 13]. The stepping stone model [14] consists of a group of well-mixed populations connected in a spatial structured way, with nearby populations interacting weakly via migration. The lattice model used in this work is a fine-grained 86 version of the stepping stone model. Refs. [15, 16] gives results for genetic distance as a function of spatial distance in this model. The distribution of coalescence times t for two individuals separated by a distance d has been determined in a two-dimensional stepping stone model to be c(d, t) ~e / [17]. Total diversity. The diversity of alleles at a particular locus was studied in models of both well-mixed and spatial populations [18-21]. However, the allelic diversity of these studies is not the same as genetic diversity, since, like species diversity, it treats all nonidentical individuals as equally distinct, and does not consider the differing degrees to which individuals can diverge from each other. Thus, the statistical methods that were used to study allelic diversity are not readily generalizable to genetic diversity. From results in Ref. [22], the scaling of diversity (number of segregating sites) can be obtained: it scales as N log(N), where N is the population size. For a well-mixed, sexually reproducing population, the number of polymorphic sites was approximated as S ~ Nu, where u is the mutation rate [23]. These results have also been found using coalescent theory to hold for the island model under a range of conditions [11, 24-26]. The diversity-area relationships given in this thesis are concerned with the scaling of diversity with the whole population. The question of scaling of number of segregating sites with sample size, when the population is of fixed size, has been found to be logarithmic in panmictic populations [22] and the island model [12, 15]. This logarithmic relationship was found via simulations to hold for the spatial model used in this thesis. The quasi-species model [27] has been studied in the physics literature. The work on this model considers the dynamics of mutation and reproduction of sequences directly. The population is assumed to be very large so the dynamics can be described using ordinary differential equations. This work considers questions such as the time to convergence to the optimum on simple fitness landscapes. Diversity as measured by the number of species has been modelled theoretically [28,29]. However, as in the work on allelic diversity, these works treat all non-identical individuals as equally distinct, and does not consider the differing degrees of divergence. Distribution of diversity and fluctuations. A result related to our finding on the distribution of uniqueness is found in Ref. [30]. The line of descent from an individual to the most recent common ancestor of any other individual is referred to as an external branch. The average length of the external branches in a panmictic population was calculated to be linear in population size, but these works did not calculate the 87 distribution. Ref. [31] found that the time to the most recent common ancestor can exhibit large discontinuous jumps. Measures of diversity. There are three commonly used measures of within-species diversity: number of segregating sites, Wright's FST statistic, and nucleotide diversity. The number of segregating sites [22] is a common measure of genetic diversity, and the one used in most of the results in this paper. It is defined as the number of loci at which more than one allele is represented in the population. Wright's FST statistic is often used in experimental studies. It measures the degree of differentiation between subpopulations relative to the diversity of the whole population. It is defined [4] as FST = (Ko - K,)/(1 - K,), where KO is the probability of identity by descent for two alleles drawn at random from within a single (panmictic) population, and K, is the probability of identity by descent for two alleles drawn at random from different (separated) populations, averaged over all pairs of populations. For the Island model, Wright found that FST 4n+1 where n is the size of each panmictic population and m is the migration rate. For the stepping stone model, FST has been calculated to grow only weakly (as log(N), where N is the number of panmictic populations [32]). As discussed in Chapter 2, FST is very dependent on the choice of the division of the population into subpopulations, and may miss much of the existing diversity because it averages over pairs of populations. Many populations are not divided into discrete subpopulations but nevertheless exhibit structure (such as the lattice model in this thesis). Furthermore, FST does not make sense when the population is finely divided into small subpopulations, because KO tends to I and hence FST tends to 1, whatever the makeup of the population. Another measure of diversity, nucleotide diversity [33], is defined as the average genealogical distance between all pairs of individuals in the population. It is similar to segregating sites, but counts mutations more if they are represented in more individuals in the population. Furtherconnections. The dynamics of reproduction in the diversity model used in this work is the same as the voter model [34]. In this model, each site on a lattice has a state, and at every time step, each site adopts the state of a randomly chosen neighbor. Similar processes have more generally been studied in the physics literature under the name of coarsening. In the diversity model used in this thesis, the dynamics of any subset of the population, including any set of descendants of a single ancestor, follows the coarsening dynamics of the voter model. However, it includes the additional feature, not found in the voter model, of mutation which allows diversity to increase as well as 88 decrease. Spatial tree processes with similarities to genealogical trees, called branching Brownian motion and branching diffusions, have been studied [35]. In these models, the branching is viewed as happening forward in time, in contrast to coalescent models where time is considered from the present backwards. However, in these processes, the branches take place without regard to the local density of individuals present, so they lack any interaction between the individuals. It was shown in Chapter 2 that populations evolve to a state where their diversity changes intermittently, increasing smoothly but decreasing in jumps with no characteristic size. This resembles critical point phenomena in physics, in which, when a particular parameter reaches a critical value, fluctuations or structures appear that have no characteristic size, but rather come in all sizes up to the size of the system. These fluctuations or structures have a power law distribution of sizes. In particular, the fluctuations in diversity resemble self-organized criticality [36], since there is no parameter that must be tuned in order to obtain critical behavior. Self-organized criticality models exhibit "avalanches", chains of activity, of all sizes up to the system size, which are triggered by small events. The loss of unique mutations in the lattice diversity model can be compared with these avalanches. Dynamics and genealogy of strains in spatially extended host-pathogen models This thesis proposes a generalized fitness measure F (T, p) of a type p, that takes evolutionary time scale T into account. T is the number of generations since introduction of a mutant strain. The most common measures of fitness currently used are based on the instantaneous rate of change in frequency of a type (that is, they do not consider whether an organisms descendants may have a fitness that is systematically different from it). Two related measures, R and r, are most often used to quantify reproductive success [37] [38] [39]. R, the net reproduction ratio, measures the expected number of surviving offspring produced by an organism over its lifetime. In a nonmutating population, R is equal to one. In a population of constant size with mutation, the maximum R may be greater than one to balance the mutant types which have a value of R less than one. r is the "Malthusian parameter" [40] [39], and measures the per capita instantaneous rate of increase of the population of a type per unit time. The two measures differ mainly in that R measures time in generations whereas r measures time irrespective of the length of a generation. Fi (1, p) is equivalent to the net reproduction ratio R for mutants of type p. 89 The concept of invasibility is another approach to the question of what types will come to dominate a population. One considers a population dominated by a phenotype p and asks whether a mutant phenotype p/ can invade. An evolutionarily stable strategy [41] is one for which no mutant can invade. Under the assumptions normally used, the evolutionarily stable strategy is the one that maximizes R [42]. The assumption that populations will be composed mainly of types with the highest number of offspring has been applied successfully to analyzing a number of biological systems [43] [37]. However, it only applies to systems where the instantaneous change in frequency is sufficient to determine the long-term composition of the population. Systems for which this condition does not hold cannot be analyzed by assuming that selection maximizes conventional measures of fitness, thus the need for a fitness measure which is a function of time scale. References [1] Wright, S. (1943). Isolation by distance. Genetics 28:114-138. [2] Wright, S. (1968). Evolution and the Genetics of Populations,vol. 1: Genetic and Biometric Foundations.Univ. Chicago Press, Chicago. [3] Malecot, G. (1948). Les mathematiques de l'heredite. Masson, Paris. [4] Malecot, G. (1973). Isolation by distance. In: Genetic Structure of Populations (N.E. Morton, ed.), University of Hawaii Press, Honolulu. [5] Hudson, R. R. Gene genealogies and the coalescent process. Oxford Surv. Evol. Biol. 7, 1-44 (1990). [6] Hudson, R. R. (1991). Gene genealogies and the coalescent process. In Oxford Surveys in Evolutionary Biology (D. Futuyama and J. Antonovics, eds.), Vol. 7, 1-44. [7] Donnelly, P. & Tavare, S. (1995). Coalescents and genealogical structure under neutrality. Ann. Rev. Genet. 29, 401-21. [8] Barton, N.H. & Wilson, I. Genealogies and geography. Phil. Trans. Roy. Soc. B 349, 49-59 (1995). [9] Epperson, B.K. (1993). Recent advances in correlation studies of spatial patterns of genetic variation. Evol. Biol. 27, 95-155. 90 [10] G. A. Hoelzer, J. Wallman, D.J. Melnick, J. Mol. Evol. 47, 21 (1998). [11] Nei, M., and Takahata, N. (1993) Effective population size, genetic diversity, and coalescence time in subdivided populations. J. Mol. Evol. 37, 240-244. [12] Notohara, M. The structured coalescent process with weak migration. J. Appl. Prob. 38, 1-17 (2001). [13] Takahata, N. (1991). Genealogy of neutral genes and spreading of selected mutations in a geographically structured population. Genetics 129:585-595. [14] Kimura, M. & Weiss, G. H. The stepping stone model of population structure and the decrease of genetic correlation with distance. Genetics 49, 313 (1964). [15] Wilkins, J. F. & Wakeley, J. The coalescent in a continuous, finite, linear population. Genetics 161, 873 (2002). [16] Cox, J.T. & Geiger, J. (2000). The genealogy of a cluster in the multitype voter model. Annals of Probability28: 1588-1619. [17] Barton, N.H. and Wilson, I. (1995). Genealogies and geography. Philos. Trans. R. Soc. Lond. Ser B 349: 49-59. [18] Maruyama, T. Analysis of population structure I. One-dimentional stepping stone models of finite length. Ann. Human Genet. Lond. 34, 201-219 (1970). [19] Maruyama T., Analysis of population structure II. Two-dimentional stepping stone models of finite length and other geographically structured populations. Ann Human Genet Lond, 35: 179-196 (1971). [20] Maruyama T., Distribution of gene frequencies in a geographically structured finite population. I. Distribution of neutral genes and of genes with small effect. Ann Human Genet Lond, 35: 411-423 (1972). [21] Maruyama T., Distribution of gene frequencies in a geographically structured finite population. II. Distribution of deleterious genes and of lethal genes. Ann Human Genet Lond, 35: 425-432 (1972). [22] Watterson, G. A. On the number of segregating sites in genetical models without recombination. Theor Pop. Biol. 7,256 (1975). [23] Kimura, M. (1969). The number of heterozygous nucleotide sites maintained in a finite population due to steady flux of mutations. Genetics 61: 893-903. 91 [24] Li, W.-H., (1976). Distribution of nucleotide differences between two randomly chosen cistrons in a subdivided population: the finite island model. Theor. Pop. Biol. 10: 303308. [25] Slatkin, M., (1987). The average number of sites separating DNA sequences drawn from a subdivided population. Theor Pop. Biol. 32: 42-49. [26] Nagylaki, T. (1998). The Expected Number of Heterozygous Sites in a Subdivided Population. Genetics 149: 1599-1604. [27] Nowak, M. A. What is a Quasi-species? Trends in Ecology and Evolution 7, 118-121 (1992). [28] Rosenzweig, M.L. Species Diversity in Space and Time (Cambridge Univ. Press, Cambridge, UK, 1995). [29] Hubbell, S. P. The Unified Neutral Theory of Biodiversity and Biogeography (Princeton University Press, Princeton, 2001). [30] Wakeley, J. & Takahashi, T. Gene genealogies when the sample size exceeds the effective size of the population. Mol. Biol. Evol. 20, 208 (2003). [31] G. A. Watterson. Mutant substitutions at linked nucleotide sites. Adv. Appl. Prob. 14, 206 (1982). [32] Cox, J.T. & Durrett, R. The stepping stone model: new formulas expose old myths. Ann. Appl. Prob.12: 1348-1377 (2002). [33] Nei, M. Molecular Evolutionary Genetics (New York: Columbia University Press, 1987). [34] Liggett, T. M. (1999). Stochastic InteractingSystems: Contact, Voter and Exclusion Processes.Springer Verlag. [35] Donnelly, P. & Kurtz, T.G. Particle representations for measure-valued population models. Ann. Prob.27:166-205 (1999). [36] Bak P., Tang C. & Wiesenfeld K. Self organized criticality. Phys. Rev. A. 38 , 364-374 (1988). [37] J.E. Brommer, Biol. Rev. Camb. Phil. Soc. 75, 377 (2000). [38] 0. Diekmann, J.A.P. Hesterbeek, and J.A.J. Metz, J. Math. Biol. 28, 365 (1990). 92 [39] B. G. Murray, Oikos 44, 509 (1984). [40] Fisher, R. A. The distribution of gene ratios for rare mutations. Proceedingsof the Royal Society of Edinburgh, 50, 205-220 (1930). [41] J. Maynard Smith, On Evolution (Edinburgh University Press, Edinburgh, 1972). [42] B. Charlesworth, American Naturalist 107, 303 (1973); J. A. J. Metz, R. M. Nisbet and S. A. H. Geritz, Trends Ecol. & Evol. 7, 198 (1992); H. M. Taylor, R. S. Gourley and C. E. Lawrence, Theor. Pop. Biol. 5, 104 (1974). [43] S. C. Steams, The Evolution of Life Histories (Oxford University Press, Oxford, 1992). 93 Chapter 7: Conclusion and future work Conclusion I have used the method of modelling the evolving genealogical tree of a population to study patterns of diversity. Though I have paid particular attention to diversity within biological species, the method is general enough that it applies to a broader range of systems. The genealogical tree of a population can be modelled as a coalescing random walk. Each step in the random walk is another generation into the past. Sampled spatial populations can be modelled by simulating the ancestry of the samples: the random walk is initialized by placing random walkers in positions corresponding to the locations they were taken. Using this method, I showed that predictions from the model agree with experimental genetic data from Pseudomonasbacteria. A given habitat has a diversity capacity, and a population whose diversity is lower than this capacity, due to recent founding or disturbance of the population, will grow until it reaches this capacity. Initially the increase is rapid, but it slows down with time. The fraction F(t) of the diversity capacity reached by time t is v/t/A in one dimension, (log(t)/ log(A)) 2 in two dimensions, and log(t)/ log(A) in a well-mixed population, where A is the number of sites or area. Full diversity is recovered by time TA, the expected time to the most recent common ancestor of a population in a steady state. The total diversity of a population depends on the population structure - whether it is well-mixed or spatially distributed. The effect of limited dispersal on diversity can be characterized in a way that is independent of many details of the model by determining the scaling of diversity with the number of sites. This also reveals the effect of habitat area on diversity. In two dimensions, diversity B(A) scales as A(log(A)) 2. It thus, grows somewhat faster than a well-mixed population whose diversity scales as A log(A), but by a relatively slowly increasing factor of log(A). In one dimension, B(A) scales as A 2 , significantly faster than area. The spatial distribution of populations (that is, limited dispersal) also has a significant effect on the distribution of genetic distances between individuals. In spatial 94 populations, this distribution is a power law. This is fundamentally different from the exponential distribution found in well-mixed populations. Diversity is unevenly distributed within species. I introduced a way of quantifying the distribution of diversity: the distribution of uniqueness. This distribution is a power law; the probability of an individual being more unique than u is P(U > u) ~ u-, implying that a disproportionate fraction of the diversity is concentrated in small subpopulations. This distribution holds even when the population is well-mixed. The distribution of diversity predicted from the model matches experimental results. Small groups are of such importance to overall population diversity that even without extrinsic perturbations, there are large fluctuations in diversity due to extinctions of these small groups. The distribution of losses of diversity within a single generation is also a power law with the same distribution as that of uniqueness. Diversity in populations with local dispersal is geographically non-uniform, with sharp boundaries between distantly related individuals, without extrinsic causes such as barriers or differing local conditions. The results presented on the scaling of diversity with habitat area and its distribution in the population have important implications for the conservation of biodiversity. The uneven distribution of diversity implies that much existing diversity in a population may be missed in when sampling a population, and the most commonly used measure of diversity does not take these divergent groups into account. The results suggests identifying divergent groups within species and ensuring their survival as a strategy to conserve genetic diversity. The results also imply that habitat area plays a greater role in within-species diversity than it does in species diversity. Observations show that biodiversity as measured by the number of species scales slowly with area (roughly as A' 2 1), but the effect on within-species genetic diversity is much more dramatic. In two dimensions, losing half the area leads to a loss of more than half the diversity, and the effect is much larger in one-dimensional habitats where a reduction of a factor of 2 causes a loss of 3/4 of the genetic diversity. I then showed an application of the method of tracing the genealogical tree of a population to a different question in evolution: how pathogens (or predators) evolve to coexist with their hosts (or prey). In a simple host-pathogen or predator-prey model, the rate at which pathogens infect hosts evolves; higher rates give a short term advantage to pathogens since they can reproduce faster, but a rate that is too high leads to depletion of prey and hence the extinction of the predator. However, because types are spatially segregated from each other, the overexploiting types eventually cause their own local extinction while the evolutionarily stable type survives. Thus over the long 95 term selection favors a sustainable level of predation. Evolution in this system can be understood by considering the dynamics of strains. Reproductive success is systematically different over the lifetime of a strain: overexploiting types initially increase rapidly but selection acts against them on long time scales. This calls for a generalized measure of fitness which includes not only the organism's type, but also the time scale as an argument. The contrast between long-term and short-term fitness may be a property of other systems which have the general property that a population depends on, and can deplete, a resource that grows locally, and where reproduction is local. Understanding evolution in systems with a contrast between short- and long-term fitness requires one to look for mechanisms that allow phenotypes that have a short-term disadvantage to persist. I showed one possible mechanism for this: feedback between the environmental change caused by the organism and selection. In the model, the local reproduction and depletion of the resource (hosts) makes it possible for some types to change their environment locally in a way that is ultimately detrimental to their own survival. The evolutionary stability of such a system can be disrupted by the addition of long-range interactions. The system may be stable for a significant density of such interactions (depending on the parameters), but there is a sudden transition to instability at a critical density. The larger the spatial scale of patches in the system, the more sensitive it is to the addition of long-range interactions. Future work The methods developed in this thesis are potentially applicable to other aspects of biodiversity, and perhaps to non-biological systems. Future work will extend them to study other questions relating to why some species and environments are highly diverse and others less so, and how we can characterize the diversity that exists. Consequences of uneven distribution of diversity. I have identified that diversity is unevenly distributed in populations. There are many consequences of this that can be investigated. In particular, there are implications for efforts to experimentally characterize the diversity of populations. When even careful sampling from populations can miss distinctive sub-populations carrying much of the population's diversity, how can we assess diversity? Simulations may identify opportunities for experiments whose results can best improve this characterization. Understanding the scaling may make it possible to infer the relationship between sampled and true diversity. There may also be implications for conservation. The uneven distribution of diversity suggests the pos- 96 sibility of identifying particularly unique and thus valuable organisms or small groups of organisms whose preservation will preserve a substantial fraction of the diversity of their species. Geographic history of a population. It is widely believed that the center of diversity of a population is often the center of its origin, though this is not always the case. By further investigating spatial patterns of diversity, the work in this thesis can be extended by determining to What extent the center of origination of a population can be detected in the genetics of the present population. Diversity in host-pathogen systems. Diversity plays an important part in the dynamics of host-pathogen systems, and there is the potential to model it using the methods I have developed. Outbreaks are often caused by the emergence of new strains whose genetic distinctness allows them to evade existing host immune responses. Recent studies, taking advantage of new high resolution molecular fingerprinting techniques, have revealed high levels of genetic diversity in common human pathogens [1-6]. This has become increasingly relevant in epidemiology, as many recently emerged pathogens, such as HIV, are similarly characterized by a high level of diversity [7-9], a characteristic with important consequences for the epidemiology of the disease [10, 11] and for the design of potential vaccines [12]. There is the opportunity to combine the modelling of host-pathogen interactions with the modelling of their diversity. In particular, recent work [13] suggests that the diversity of HIV (unlike that of influenza for example) has not yet reached a steady state, so modelling the change in HIV diversity may be an application of my proposed work on the dynamics of non-steady-state diversity in populations. Additional theoretical results. The approach developed in this thesis of applying results from the study of random walkers might be extended by using results on systems of walkers with different kinds of interactions. For example, selection might be modelled with an attractive force between walkers. Species diversity. In addition to within-species diversity, the approach presented in this thesis makes it possible to study new aspects of the problem of species diversity. The evolutionary history of life on Earth is dominated by the opposing forces of diversification and extinction, so understanding the dynamics of diversity is crucial to understanding evolutionary change. Models of species diversity can be developed based on the applicable features of my within-species model (lineages would represent species rather than individuals). In particular, my finding that within-species diversity undergoes large "extinctions" even without extrinsic perturbations, such as environmental 97 changes or disease, should be applicable to species diversity as well, and I intend to investigate whether this has implications for macroevolutionary patterns. An important difference in what I plan to do is that most existing models ignore the accumulation of successive differences between species. In other words, if species A gives rise to a daughter species B, and B in turn gives rise to C, C will be more different from A than B is. This fact may however be crucial to patterns of diversity [14]. References [1] Musser, J.M., Kapur, V., Szeto, J., Pan, X., Swanson, D.S. & Martin, D.R.. Genetic diversity and relationships among Streptococcuspyogenes strains expressing serotype MI protein - recent intercontinental spread of a subclone causing episodes of invasive disease. Infection And Immunity 63 994-1003 (1995). [2] Salama, N., Guillemin, K., McDaniel, T.K., Sherlock, G., Tompkins, L., Falkow, S. A whole-genome microarray reveals genetic diversity among Helicobacterpylori strains. Proc. R. Soc. Lond. B Biol. Sci. 97, 14668-14673 (2000). [3] Blaser, M.J., Berg D.E., Helicobacterpylori genetic diversity and risk of human disease. Journalof Clinical Investigation 107, 767-773 (2001). [4] Hinchliffe, S.J., Isherwood, K.E., Stabler, R.A. et al. TI Application of DNA microarrays to study the evolutionary genomics of Yersinia pestis and Yersinia pseudotuberculosis.Genome Res. 13, 2018. [5] Boyd, E.F., Porwollik, S., Blackmer, F. & McClelland, M. Differences in gene content among Salmonella enterica serovar Typhi isolates. J. Clin. Microbiol. 41, 3823. [6] Anjum, M.F., Lucchini, S., Thompson, A., Hinton, J.C.D. & Woodward, M.J. Comparative genomic indexing reveals the phylogenomics of Escherichia coli pathogens Infection Immun. 71, 4674. [7] Gao, F., Yue, L., Robertson, D.L., Hill, S.C., Hui, H.X., Biggar, R.J., Neequaye, A.E., Whelan, T.M., Ho, D.D., Shaw, G.M., Sharp, P.M. & Hahn, B.H. Genetic Diversity Of Human-Immunodeficiency-Virus Type-2 - Evidence For Distinct Sequence Subtypes With Differences In Virus Biology. Journal Of Virology 68, 7433-7447 (1994). 98 [8] McCutchan, F.E. Understanding the genetic diversity of HIV-1. AIDS 14, S31S44 (2000). [9] Korber, B., Gaschen, B., Yusim, K., Thakallapally, R., Kesmir, C., Detours, V. Evolutionary and immunological implications of contemporary HIV-1 variation. Brit. Med. Bull. 58, 19-42 (2001). [10] Peeters, M., Sharp, P.M. Genetic diversity of HIV-1: the moving target. AIDS 14, S129-S140 (2000). [11] Tatt ID, Barlow KL, Nicoll A, Clewley JP. The public health significance of HIV1 subtypes. AIDS 15, S59-S71 (2001). [12] Gaschen, B., Taylor, J., Yusim, K., Foley, B., Gao, F., Lang, D., Novitsky, V., Haynes, B., Hahn, B.H., Bhattacharya, T. & Korber, B. AIDS - Diversity considerations in HIV- 1 vaccine selection. Science 296, 2354-2360 (2002). [13] Korber, B., Muldoon, M., Theiler, J. et al. Timing the ancestor of the HIV-1 pandemic strains. Science 288, 1789 (2000). [14] Faith, D.P. (1994). Phylogenetic pattern and the quantification of organismal biodiversity. Philos. Trans. R. Soc. Lond. Ser. B 345:45-58. 99