STAT 510 Homework 4 Due Date: 11:00 A.M., Wednesday, February 10
advertisement

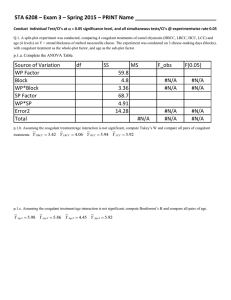
STAT 510 Homework 4 Due Date: 11:00 A.M., Wednesday, February 10 1. Consider a completely randomized experiment in which a total of 10 rats were randomly assigned to 5 treatment groups with 2 rats in each treatment group. Suppose the different treatments correspond to different doses of a drug in milliliters per gram of body weight as indicated in the following table. Treatment Dose of Drug (mL/g) 1 0 2 2 3 4 4 8 5 16 Suppose for i = 1, . . . , 5 and j = 1, 2, yij is the weight at the end of the study of the jth rat from the ith treatment group. Furthermore, suppose yij = µi + ij , where µ1 , . . . , µ5 are unknown parameters and the ij terms are iid N (0, σ 2 ) for some unknown σ 2 > 0. Use the R code and partial output provided below to answer the following questions. > > > > > > d=rep(c(0,2,4,8,16),each=2) #y is the data vector with entries ordered to appropriately #match the vector d. dose=factor(d) o1=lm(y˜dose) summary(o1) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 351.000 6.576 53.372 4.37e-08 *** dose2 -10.000 9.301 -1.075 0.331406 dose4 -6.000 9.301 -0.645 0.547277 dose8 -17.000 9.301 -1.828 0.127119 dose16 -70.500 9.301 -7.580 0.000634 *** > anova(o1) Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value dose 6505.6 Residuals 432.5 > is.numeric(d) [1] TRUE > o2=lm(y˜d) > anova(o2) Pr(>F) Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value d 5899.6 Residuals 1038.5 Pr(>F) > o3=lm(y˜d+dose) > anova(o3) Analysis of Variance Table Response: y Df Sum Sq Mean Sq F value Pr(>F) d 0.0004245 *** dose 0.1907591 Residuals (a) Provide the numerical value of the BLUE of µ1 . (b) Provide the numerical value of the BLUE of µ2 . (c) Determine the standard error of the BLUE of µ2 . (d) Conduct a test of H0 : µ1 = µ2 . Provide a test statistic, the distribution of that test statistic (be very precise), a p-value, and a conclusion. (e) Provide an F -statistic for testing H0 : µ3 = µ4 . (f) Does a simple linear regression model with body weight as a response and dose as a quantitative explanatory variable fit these data adequately? Provide a test statistic, its degrees of freedom, a p-value, and a conclusion. (g) Provide a matrix C and a vector d so that the null hypothesis of the test in part (f) may be written as H0 : Cβ = d, where β = (µ1 , . . . , µ5 )0 . (h) Fill in the missing entries in the ANOVA table produced by the R command anova(o3). (This is the last R command in the provided code.) 2. Suppose X is an n × p matrix and B is a p × p non-singular matrix. Prove that C (X) = C XB −1 . 3. Consider the simple linear regression model yi = β0 + β1 xi + i i = 1, . . . , n where 1 , . . . , n are iid and have a normal distribution N 0, σ 2 and β0 ,β1 , and σ 2 > 0 are unknown parameters. The model matrix for this linear model can be written as X = [1, x], where 1 is an n × 1 vector of ones and x = (x1 , . . . , xn )0 . (a) We have learned that the least squares estimator of β in a general linear model with a full-rank −1 matrix X is given by β̂ = (X 0 X) X 0 y. Simplify this expression for the special case of simple linear regression to obtain an expression for the least squares estimators of β0 and β1 . Express your final answers using summation notation. Page 2 (b) There are some computational advantages to working with a model matrix whose columns are orthogonal. For the simple linear regression problem consider the model matrix W = [1, x − x̄· 1] This design matrix is obtained by “centering” the explanatory variable around its mean x̄· = P n −1 = W . It will follow that i=1 xi /n. Find a matrix B so that XB Xβ = XB −1 Bβ = W α where Bβ = α. (c) Derive expressions for the least squares estimators of α0 and α1 (where α = (α0 , α1 )0 from part −1 (b)) using α̂ = (W 0 W ) W 0 y. (d) Multiply α̂ from part (c) by B −1 from part (b) to obtain expressions for β̂0 and β̂1 . (e) Show that your answer to part (a) matches your answer to part (d). Page 3