3.2 Least-Squares Regression
advertisement

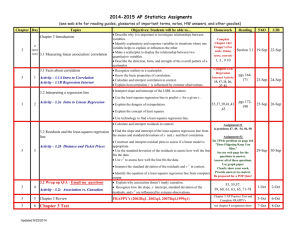
3.2 Least-Squares Regression Objectives SWBAT: • INTERPRET the slope and y intercept of a least-squares regression line. • USE the least-squares regression line to predict y for a given x. • CALCULATE and INTERPRET residuals and their standard deviation. • EXPLAIN the concept of least squares. • DETERMINE the equation of a least-squares regression line using a variety of methods. • CONSTRUCT and INTERPRET residual plots to assess whether a linear model is appropriate. • ASSESS how well the least-squares regression line models the relationship between two variables. • DESCRIBE how the slope, y intercept, standard deviation of the residuals, and r 2 are influenced by outliers. What is the general form of a regression equation? What is the difference between y and ŷ? • A regression line relating y to x has an equation of the form • ŷ = a + bx • In this equation, • ŷ (read “y hat”) is the predicted value of the response variable y for a given value of the explanatory variable x. • b is the slope, the amount by which y is predicted to change when x increases by one unit. • a is the y intercept, the predicted value of y when x = 0. • (note: y is the actual value for the response variable) • You can write the regression equation a few ways. Let’s say we want to use number of homeruns a baseball team hits to try and predict their number of runs scored. • The MLB data from 2008 has a slope of 1.25 and a y-intercept of 550. • You can write the equation as: or or Note: It is NOT enough to simply write Don’t you hate it when you open a can of soda and some of the contents spray out of the can? Two AP® Statistics students, Kerry and Danielle, wanted to investigate if tapping on a can of soda would reduce the amount of soda expelled after the can has been shaken. For their experiment, they vigorously shook 40 cans of soda and randomly assigned each can to be tapped for 0 seconds, 4 seconds, 8 seconds, or 12 seconds. After opening up the can and cleaning up the mess, the students measure the amount of soda left in each can (in ml). Here is a scatterplot with the least-squares regression line a) Interpret the slope and y-intercept the regression line. The slope b = 2.63 tells us that the amount of soda remaining in the can is predicted to increase by 2.63 ml for each additional second that the can is tapped. The y intercept a = 248.6 is the predicted amount of soda remaining in the can if it isn’t tapped at all (0 seconds). b) Predict the amount remaining for a can that has been tapped for 10 seconds. c) Predict the amount remaining for a can that has been tapped for 60 seconds. How confident are you in this prediction. Don’t predict the amount for 60 seconds!!! We have data only for cans that were tapped between 0 and 12 seconds. We don’t know if the linear pattern will continue beyond these values. In fact, if we did make a prediction for 60 seconds of tapping, we would get 406.4 ml, over 50 ml more than the can originally contained (355 ml)! This is known as extrapolation. Extrapolation is trying to make predictions outside of the range of the data we have. It is a bad idea to extrapolate!!! It is risky to make predictions using extrapolation since the association between the variables may not be the same for extremely small or extremely large values of the explanatory variable. What is a residual? How do you interpret residuals? In most cases, no line will pass exactly through all the points in a scatterplot. A good regression line makes the vertical distances of the points from the line as small as possible. A residual is the difference between an observed value of the response variable and the value predicted by the regression line. residual = observed y – predicted y residual = y - ŷ • A negative residual means an actual value is below a predicted value. • A positive residual means an actual value is above a predicted value. Calculate and interpret the residual for a can that was tapped for 4 seconds and had 260 ml of soda remaining. This can had 0.88 ml more soda remaining than expected, based on how long it was tapped. How can we determine the “best” regression line for a set of data? • The closer a residual is to 0, the more accurate a prediction is. • In general, when statisticians compare models to see which one makes the best predictions, they compare the sum of squared residuals for each model and choose the model with the smallest sum. • This is known as the “least-squares” method. The least-squares regression line of y on x is the line that makes the sum of the squared residuals as small as possible. Is the least-squares regression line resistant to outliers? A single observation can have a big effect on the equation of the least-squares regression line, as well as on related measures such as the standard deviation of the residuals (more to come on this soon). To the right is a scatterplot showing shooting percentage and number of wins for the 30 NBA teams in the 2008-2009 regular season. • The Phoenix Suns made 50.4% of their shots but only won 46 of their games, which seems to be out of the pattern of the rest of the teams. • You can see two least-squares regression lines on the scatterplot, one that includes the Suns and one that does not. • We can see that the Suns performance had a strong influence on the slope of the equation. Removing the Suns causes the slope to go from 6.8 to 10.8. It also causes the standard deviation of the residuals to go from s=11 wins to s=9 wins, and correlation to go from r=0.65 to r=0.79. Example: McDonald’s Beef Sandwiches Calculate the equation of the least-squares regression line using technology Make sure to define variables! Sketch the scatterplot with the graph of the least-squares regression line. To graph the LinReg equation, store it into Y1 Question: How do we know that a line is the right model to use? Why not use a parabola or something exponential, or something shaped like a cat tail? One of the first principles of data analysis is to look for an overall pattern and for striking departures from the pattern. A regression line describes the overall pattern of a linear relationship between two variables. We see departures from this pattern by looking at the residuals. If there is not a pattern to A residual plot is a scatterplot of the residuals against the explanatory variable. Residual plots help us assess how well a regression line fits the data. the residual graph, then a linear model is acceptable to use. How can we plot the residuals with our McDonald’s example? Once you’ve calculated a linear regression line, the calculator automatically stores the residuals in a list called “RESID” AFTER you calculate the linear regression line, go into STAT, Edit, and put the cursor on L3 so that L3 is highlighted. Then press 2nd, STAT(list) and select the RESID list. Note: The purpose of the residual plot is to address FORM, meaning linear or non-linear. Now, turn off Y1, and do STATPLOT with L1 as x-list and L3 as y-list. Examining Residual Plots A residual plot magnifies the deviations of the points from the line, making it easier to see unusual observations and patterns. The residual plot should show no obvious patterns The residuals should be relatively small in size. Pattern in residuals Linear model not appropriate What is the standard deviation of the residuals? How do you calculate and interpret it? The standard deviation of the residuals (s) estimates the typical distance between the actual values of the response variable and their corresponding predicted values (the approximate size of a “typical” prediction error (residual)). s= å residuals n-2 2 = å(y 2 ˆ y ) i n -2 For the can tapping example, the standard deviation of the residuals is s=5.00. Interpret this value. When we use the least-squares regression line to predict the amount of soda remaining using the amount of tapping time, our predictions will typically be off by about 5 ml. s= å residuals n-2 2 = å(y 2 ˆ y ) i n -2 To help find s on the calculator, store the residuals as L3. Press STAT, CALC, 1: 1-Var Stats, and enter L3 for the list. Let’s do this for our McDonald’s example. The standard deviation of the residuals gives us a numerical estimate of the average size of our prediction errors. There is another numerical quantity that tells us how well the least-squares regression line predicts values of the response y. The coefficient of determination r2 is the fraction of the variation in the values of y that is accounted for by the least-squares regression line of y on x. We can calculate r2 using the following formula: r 2 =1- 2 residuals å 2 (y y) å i r2 tells us how much better the LSRL does at predicting values of y than simply guessing the mean y for each value in the dataset Below is the relationship between the average number of points scored per game x and the number of wins y for the 12 college football teams in the Southeastern Conference. A scatterplot with the least-squares regression line and a residual plot are shown. The equation of the least-squares regression line is y-hat = −3.75 + 0.437x. Also, s = 1.24 and r2 = 0.88. a) Is a linear model appropriate for these data? Explain. Because there is no obvious pattern left over in the residual plot, the linear model is appropriate. b) Interpret the value r2 = 0.88. About 88% of the variation in wins is accounted for by the linear model relating wins to points per game. (The other 12% are accounted for by other factors) Interpreting Computer Output • On the AP Statistics exam, you will be given computer output and asked to interpret. • A number of statistical software packages produce similar regression output. Be sure you can locate • the slope b • the y intercept a • the values of s and r2 • How would you find r? • Is r positive or negative? • Since the slope is positive, we must have a positive correlation. Therefore r is positive. When Mentos are dropped into a newly opened bottle of Diet Coke, carbon dioxide is released from the Diet Coke very rapidly, causing the Diet Coke to be expelled from the bottle. Will more Diet Coke be expelled when there is a larger number of Mentos dropped in the bottle? Two statistics students, Dale and Brennan, decided to find out. Using 16 ounce (2 cup) bottles of Diet Coke, they dropped either 2, 3, 4, or 5 Mentos into a randomly selected bottle, waited for the fizzing to die down, and measured the number of cups remaining in the bottle. Then, they subtracted this measurement from the original amount in the bottle to calculate the amount of Diet Coke expelled (in cups). Output from a regression analysis is shown above. What is the equation of the least-squares regression line? Regression to the Mean Using technology is often the most convenient way to find the equation of a least-squares regression line. It is also possible to calculate the equation of the least- squares regression line using only the means and standard deviations of the two variables and their correlation. Find the equation of the least-squares regression line for predicting height from foot length. Show your work. Correlation and Regression Wisdom Correlation and regression are powerful tools for describing the relationship between two variables. When you use these tools, be aware of their limitations. 1. The distinction between explanatory and response variables is important in regression. Correlation and Regression Wisdom 2. Correlation and regression lines describe only linear relationships. r = 0.816. r = 0.816. r = 0.816. r = 0.816. Correlation and Regression Wisdom 3. Correlation and least-squares regression lines are not resistant. Outliers and Influential Observations in Regression Least-squares lines make the sum of the squares of the vertical distances to the points as small as possible. A point that is extreme in the x direction with no other points near it pulls the line toward itself. We call such points influential. An outlier is an observation that lies outside the overall pattern of the other observations. Points that are outliers in the y direction but not the x direction of a scatterplot have large residuals. Other outliers may not have large residuals. An observation is influential for a statistical calculation if removing it would markedly change the result of the calculation. Points that are outliers in the x direction of a scatterplot are often influential for the least-squares regression line.