Chp 8
advertisement

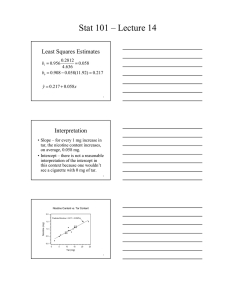
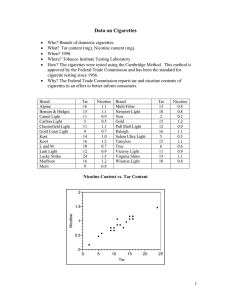
AP Statistics Chapter 8: Linear Regression Ashwin Varma, Period II Definitions: • Linear Model: Equation in the form y=mx+b that models a data relationship; also known as a “best-fit line”. • Residual (e): The difference between the actual data point (y’) and the predicted value (y); e=y’-y; a line of best fit is the line for which the sum of the squared residuals is smallest (e2). • One must also know how to calculate a “Z-score”. See Chapter 6 & 7 for a theoretical background. • Note: n’ will be used to denote the expected value of any quantity “n” as given by a model. Creating a Model • Generalized model for linear model passing through the origin: y=mx, where m is the slope. • The model: [Zy=rZx]where Zy outputs the expected “y-value” for a given Zx input, related by, r, the correlation coefficient. • Moving one standard deviation away in the x-direction, moves the estimated output “r” SDs away in the y-direction. • Ex. 1: Zfat=0.83Zprotein This model predicts that for every one SD above/below the mean protein content a certain food is, it will be 0.83 SD above/below the mean fat content. • If r=1.0, or r=-1.0, then there is a perfectly linear correlation in the positive and negative direction respectively, and a r=0 means there is no linear relationship between the two variables. • NOTE: Each predicted y-value tends to be closer to the mean (in zscores), than the corresponding x-value was. This is called regression to the mean. Converting to Real Units • Generalized Linear Regression Model in Real Units: y’=b0+b1x, where b0 is the y-intercept, and b1 is the slope. • Slope in real units: b1=r(sy/sx), where r is the correlation coefficient, sy and sx are the standard deviations for the y and x data sets respectively. • Finding b0 : Note, the linear model must pass through the mean x and y values, (xavg, yavg). • Plug means in to model: y=b0 +b1x, and solve for b0. • NOTE: The y-intercept serves only as a starting point. In reality, there is no point at which the x-value will be “0”. Residuals • Residual = Data – Model: e = y – y’ • A scatter plot of the residuals of any data set with a linear association should be very nondescript. • o No particular direction, shape, or trends. o No outliers. r2, the squared correlation, accounts for how much of the model is accounted for by the model and 1-r2 outputs the amount of data unaccounted by the model. • A “good” r2 value can be variable. Some studies have values above 90%, while in others 50% can be useful. R2 values only demonstrate how much of the data can and cannot be explained by the model, nothing more. Assumptions • To check data sets to assure the validity in using linear models to describe data, several assumptions must be verified: o Quantitative Variables Condition-Are the variables being associated quantitative in nature? o Linearity Assumption- Is the relationship between the two variables relatively linear in nature? o Straight Enough Condition-Is the data set relatively straight? It does not have to be perfectly straight, but there cannot be excessively obvious curves/bends, or outliers. o Analyze the RESIDUAL’s scatterplot: Check the Equal Variance Assumption. The spread of the residuals should fit a normal model. What Can Go Wrong? • One CANNOT reverse the model. o E.g. If given the model: fat; = 6.8 + 0.97 protein, and the fat content of a particular food, one cannot determine the protein content of the food. o To do this, one would have to derive a new model from the initial z-score model: Zprotein=rZfat • Do NOT extrapolate the data. The model becomes less predictive as the distance from the mean x value increases. Problem #19, P.g. 191 • A) r=√(0.924)=0.961 b1=0.065052 (given value)b0=0.154030 (given value) Nicotine’=0.15403+.065052(tar) • B) 4mg tar: 0.15403+.065052(4.0)=0.414mg Nicotine’ • C) Meaning of Slope: In this context, the slope indicates that for every milligram of tar added to a cigarette, 0.065052 milligrams of nicotine is predicted to be added to that cigarette. • D) The intercept provides a base value for nicotine in every cigarette. That is, ever cigarette has a base value of 0.154 mg of nicotine with no tar, and adding milligrams of tar will add to that content at some linear rate. • E) Step I, Find Predicted Nicotine Value: 0.15403+.065052(7)=0.6094 mg Nicotine’ • Step II, use residual (-0.5mg): e = y – y’ y=e+y’y=0.6094+ (0.5)= 0.1094 mg Nicotine. Problem #21, P.g. 191 • Problem: If you create a regression model for predicting the weight of a car (in pounds) from its length (in feet), is the slope most likely to be 3, 30, 300, or 3000? Explain. • Answer: Assume that an “average” car has a length of 10 feet and weight of around 3000 pounds (check online to verify these figures). Only a slope of 300 pounds/foot produces values around 3000 lbs. Others are too large or too small. Note, you can use this method of “averaging”, because the linear model has to pass through the mean x and y values, (xavg, yavg).