Lock_2011 - Duke Statistics
advertisement

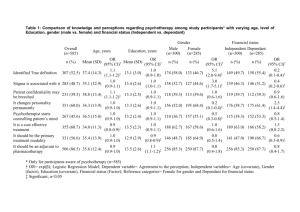
Rerandomization to Improve Covariate Balance in Randomized Experiments Kari Lock Harvard Statistics Advisor: Don Rubin 4/28/11 The Gold Standard • Randomized experiments are the “gold standard” for estimating causal effects • WHY? 1. They yield unbiased estimates 2. They eliminate confounding factors R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R Randomize R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R R Covariate Balance - Gender • Suppose you get a “bad” randomization • What would you do??? • Can you rerandomize??? When? How? 5 12 Females, Females, 15 8Males Males 15 8 Females, 5 12Males Males The Origin of the Idea Rubin: What if, in a randomized experiment, the chosen randomized allocation exhibited substantial imbalance on a prognostically important baseline covariate? Cochran: Why didn't you block on that variable? Rubin: Well, there were many baseline covariates, and the correct blocking wasn't obvious; and I was lazy at that time. Cochran: This is a question that I once asked Fisher, and his reply was unequivocal: Fisher (recreated via Cochran): Of course, if the experiment had not been started, I would rerandomize. Covariate Imbalance • The more covariates, the more likely at least one covariate will be imbalanced across treatment groups • With just 10 independent covariates, the probability of a significant difference (at level α = .05) for at least one covariate is 1 – (1-.05)10 = 40%! • Covariate imbalance is not limited to rare “unlucky” randomizations The Gold Standard • We all know that randomized experiments are the “gold standard” for estimating causal effects • WHY? 1. They yield unbiased estimates 2. They eliminate confounding factors … on average! For any particular experiment, covariate imbalance is possible (and likely!), and conditional bias exists 1) Collect covariate data Specify criteria determining when a randomization is unacceptable; based on covariate balance (Re)randomize subjects Randomize subjects to to treatment and and control treatment control 2) RERANDOMIZATION Check covariate balance unacceptable acceptable 3) Conduct experiment 4) Analyze results (with a randomization test) Unbiased Theorem: If the treatment groups are exchangeable for each randomization and for the rerandomization criteria, then rerandomization yields an unbiased estimate of the average treatment effect. • For exchangeability: • Equal sized treatment groups • Rerandomization criteria that is objective and does not favor a specific group Unbiased Options for unequal sized treatment groups: • Rerandomize into multiple equally sized groups, then combine groups after the rerandomization • Discard the extra units to form equal sized groups • Rerandomize to lower MSE, with perhaps slight bias • Do not rerandomize Rerandomization Test • Randomization Test: • Simulate randomizations to see what the statistic would look like just by random chance, if the null hypothesis were true • Rerandomization Test: • A randomization test, but for each simulated randomization, follow the same rerandomization criteria used in the experiment • As long as the simulated randomizations are done using the same randomization scheme used in the experiment, this will give accurate p-values Alternatives for Analysis • t-test: • Too conservative • Significant results can be trusted • Regression: • Regression including the covariates that were balanced on using rerandomization more accurately estimates the true precision of the estimated treatment effect • Assumptions are less dangerous after rerandomization because groups should be well balanced Criteria for Acceptable Balance We use Mahalanobis Distance, M, to represent multivariate distance between group means: M XT XC 'cov XT XC XT XC 1 1 1 1 XT XC 'cov X XT XC nT nC 1 Under adequate sample sizes and pure randomization: M ~ k2 k : Number of covariates to be balanced Choose a and rerandomize when M > a Distribution of M pa = Probability of accepting a randomization RERANDOMIZE Acceptable Randomizations a M Choosing pa • Choosing the acceptance probability is a tradeoff between a desire for better balance and computational time • The number of randomizations needed to get one successful one is Geometric(pa), so the expected number needed is 1/pa • Computational time must be considered in advance, since many simulated acceptable randomizations are needed to conduct the randomization test Another Measure of Balance • The obvious choice may be to set limits on the acceptable balance for each covariate individually 3 • This destroys the joint distribution of the covariates 1 2 D2 0 D1 0 -1 -1 -2 -2 -3 -3 1 2 3 Rerandomization Based on M • Since M follows a known distribution, easy to specify the proportion of accepted randomizations • M is affinely invariant (unaffected by affine transformations of the covariates) • Correlations between covariates are maintained • The balance improvement for each covariate is the same (and known)… • … and is the same for any linear combination of the covariates Covariates After Rerandomization Theorem: If nT = nC, the covariate means are normally distributed, and rerandomization occurs when M > a, then E XT XC | M a 0 cov XT XC | M a va cov XT XC . k va a 1, 2 2 2 k k a , 2 2 P k2 2 a P k2 a c where is the incomplete gamma function: (b, c) yb1e y dy. 0 Percent Reduction in Variance • For each covariate xj, the ratio of variances is: var X j ,T X j ,C ∣ rerandomization var X j ,T X j ,C va and the percent reduction in variance is var X j ,T X j ,C var X j ,T X j ,C ∣ rerandomization 100 var X X j , T j , C 100(1 va ) Shadish Data n = 445 undergraduate students randomization Randomized Experiment 235 Observational Study 210 randomization students choose Vocab Training 116 Math Training 119 Vocab Training 131 Math Training 79 Shadish, M. R., Clark, M. H., Steiner, P. M. (2008). Can nonrandomized experiments yield accurate answers? A randomized experiment comparing random and nonrandom assignments. JASA. 103(484): 1334-1344. Shadish Data vocabpre mathpre numbmath likemath likelit preflit actcomp collgpaa age male -3 -2 -1 0 1 2 Standardized Difference in Covariate Means k = 10 covariates 3 Shadish Data To generate 1000 rerandomizations: pa = 0.1: 11.6 seconds pa = 0.01: 1.8 minutes pa = 0.001: 18.3 minutes pa = 0.0001: 3.4 hours Shadish Data To generate 1000 rerandomizations: pa = 0.1: 11.6 seconds pa = 0.01: 1.8 minutes pa = 0.001: 18.3 minutes pa = 0.0001: 3.4 hours Shadish Data k = 10 covariates pa = 0.001 P 10 2 a 0.001 a 1.48 Rerandomize when M > 1.48 Ratio of Variances: a 1.48 k 10 1, 1, 2 2 2 2 2 2 0.12 va k 10 k a 10 1.48 , , 2 2 2 2 Percent Reduction in Variance: 100(1 – va) = 88% Shadish Data Vocab Pre-Test Pure Randomization Rerandomization -2 -1 0 XT XC 1 2 Shadish Data Actual Randomization Pure Randomization Rerandomization PRIV vocabpre 88% mathpre 88% numbmath 88% likemath 88% likelit 88% preflit 88% act 88% gpa 88% age 88% male 88% act+10gpa 88% -4 -2 0 2 Standardized Difference in Covariate Means 4 Estimated Treatment Effect After Rerandomization Theorem: If nT = nC , the covariate and outcome means are normally distributed, the treatment effect is additive, and rerandomization occurs when M > a, then E YT Y C | M a and the percent reduction in variance for the estimated treatment effect is 100 1 va R , 2 where R2 is the squared canonical correlation. Outcome Variance Reduction va Shadish Data n = 445 undergraduate students randomization Randomized Experiment 235 Observational Study 210 randomization students choose Vocab Training 116 Math Training 119 Vocab Training 131 Math Training 79 Outcomes: score on a vocabulary test, score on a mathematics test Shadish Data k 10, pa .001 Covariate Percent Reduction in Variance = 88% Percent Reduction in Variance for ˆ Y T Y C is 88R2 Vocabulary: R2 = 0.11 Percent Reduction in Variance = 88(0.11) = 9.68% Mathematics: R2 = 0.32 Percent Reduction in Variance = 88(0.32) = 28.16% Equivalent to increasing the sample size by 1/(1-0.28) = 1.39 Shadish Data Vocabulary -3 -2 -1 0 Mathematics 1 2 Estimated Treatment Effect 3 -2 -1 0 1 Estimated Treatment Effect 2 Rerandomization Based on M • Since M follows a known distribution, easy to specify the proportion of accepted randomizations • M is affinely invariant (unaffected by affine transformations of the covariates) • Correlations between covariates are maintained • The balance improvement for each covariate is the same… • … and is the same for any linear combination of the covariates Is that good??? Tiers of Covariates • In practice, covariates are often of varying importance • We can place covariates into tiers, with the top tier including the most important covariates, the second tier less important, etc. • Criteria for acceptable balance can be less stringent for each successive tier Tiers of Covariates 1) Check balance for covariates in tier 1 calculate M1 using the covariates in tier 1, rerandomize if M1 > a1 2) For each successive tier, regress each covariate on all covariates in previous tiers, and check balance for the residuals of that tier calculate Mt using the residuals of tier t, rerandomize if Mt > at at denotes the acceptance threshold for tier t Tiers of Covariates Theorem: If the nT = nC and the covariate means are normally distributed, and rerandomization occurs if any Mt > at, then the ratio of variances for covariate xj is va1 if in tier 1, t 1 va1 R va2 (1 R ) if in tier 2, 2 1 2 1 va1 R vai ( R R ) vat (1 R ), if in tier t 2, 2 1 i 2 2 i 2 i 1 2 t 1 where Rt2 denotes the squared canonical correlation between xj and all covariates in tiers 1 through t. 23.24 TIER 1: vocabpre mathpre TIER 2: numbmath likemath likelit actcomp collgpaa TIER 3: preflit hsgpaar credit majormi mars beck pextra pagree pconsc pemot pintell parentsIncome momdegr daddegr age male married cauc afram TIER 4: vocabpre2 mathpre2 vocabpre*mathpre vocabpre*numbmath vocabpre*likemath vocabpre*likelit vocabpre*actcomp vocabpre*collgpaa mathpre*numbmath mathpre*likemath mathpre*likelit mathpre*actcomp mathpre*collgpaa numbmath*likemath numbmath*likelit numbmath*actcomp numbmath*collgpaa likemath*likelit likemath*actcomp likemath*collgpaa likelit*actcomp likelit*collgpaa actcomp*collgpaa 40.75 78.24 94.82 Covariates Residuals 0 20 40 60 Empirical Percent Reduction in Variance 80 100 PRIV TIER 1: vocabpre mathpre TIER 2: numbmath likemath likelit actcomp collgpaa TIER 3: preflit hsgpaar credit majormi mars beck pextra pagree pconsc pemot pintell parentsIncome momdegr daddegr age male married cauc afram TIER 4: vocabpre2 mathpre2 vocabpre*mathpre vocabpre*numbmath vocabpre*likemath vocabpre*likelit vocabpre*actcomp vocabpre*collgpaa mathpre*numbmath mathpre*likemath mathpre*likelit mathpre*actcomp mathpre*collgpaa numbmath*likemath numbmath*likelit numbmath*actcomp numbmath*collgpaa likemath*likelit likemath*actcomp likemath*collgpaa likelit*actcomp likelit*collgpaa actcomp*collgpaa 95% 94% 79% 80% 79% 85% 79% 67% 52% 44% 45% 46% 38% 47% 43% 43% 41% 53% 31% 41% 44% 43% 42% 39% 51% 55% 94% 89% 92% 79% 78% 84% 90% 85% 81% 82% 84% 91% 88% 74% 76% 79% 78% 72% 78% 77% 80% 78% 81% -4 -2 0 2 Standardized Difference in Covariate Means 4 Multiple Treatment Groups • Rerandomization is easily extended to multiple treatment groups • To measure balance, one of the MANOVA test statistics (such as Wilks’ ) can be used, measuring the ratio of within group variability to between group variability for multiple covariates • This is equivalent to rerandomizing based on Mahalanobis distance if used on only two groups Blocking • This is not meant to replace blocking, and blocking and rerandomization can be used together • Blocking is great for balancing a few very important covariates, but is not easily used for many covariates • “Block what you can, rerandomize what you can’t” Small Samples or Non-Normality • The theoretical results given depend on M ~ k2 • If the covariate means are not normally distributed, that is fine! The theoretical results given are used nowhere in analysis. Rerandomization does NOT depend on asymptotics. • The threshold a corresponding to pa, and the percent reduction in variance for the covariates can be estimated via simulation Conclusion • Rerandomization improves covariate balance between the treatment groups, giving the researcher more faith that an observed effect is really due to the treatment • If the covariates are correlated with the outcome, rerandomization also increases precision in estimating the treatment effect, giving the researcher more power to detect a significant result Thank you!!!