EDFR 6720
advertisement

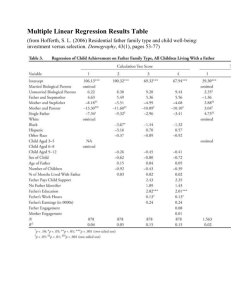
EDF 802 Dr. Jeffrey Oescher ANCOVA I. Introduction A. Description: A large class of research designs and analyses in which a continuous independent variable known as a covariate is introduced into an analysis of variance design to increase the statistical power of the analysis. The covariate is systematically related to the dependent variable and is used to reduce the estimate of random or error variance in the dependent measure. The reduction of error variance is accomplished by regressing the dependent variable onto the covariate and extracting the sum of squares due to regression from the sum of squares due to error. Covariates can be used in virtually all ANOVA designs. B. Application: Analysis of covariance (ANCOVA) is commonly used in pretest-posttest designs with the pretest as a covariate. Aptitude measures are often used as covariates in analyses that have achievement as dependent variables. ANCOVA is sometimes used to correct for sampling bias or error, although the results derived from it use can be misleading. C. Data: The dependent variable is interval or ratio. Independent variables are discrete and may be nominal, ordinal, or sometimes interval. The covariate is continuous and is interval or ratio. D. Limitations: All assumptions of the corresponding ANOVA procedures apply to ANCOVA. In addition, ANCOVA assumes that the relationship between the covariates and the dependent measure are statistically equivalent within all groups or cells in the design. In a one factor ANCOVA, this assumption states that the regression lines of the dependent variable that has been regressed on the covariate within each group are parallel. In general this assumption is known as homogeneity of regression. Violations of this assumption preclude the use of ANCOVA or seriously jeopardize any inferences drawn from the analysis. E. Purposes: eliminate systematic variance and reduce error variance 1. Elimination of systematic bias a. Relationship between covariate and dependent variable b. The adjustment of means is a statistical way of reducing systematic bias 1 i. Alternative methods - gain scores, matching subjects, etc. 2. Reduction of error variance a. In a traditional ANOVA approach, the computed F-statistic is F = MSb / MSw b. The within group variance (i.e., error) is denoted as MSw c. As MSw is decreased, the F-statistic for the ratio of MSb / MSw increases d. Alternative methods - homogenous sampling, factorial designs, etc. II. Concepts underlying ANCOVA A. Adjustment of means 1. Adjusting the means on the dependent variable to what they would have been if all groups started out equally on the covariate (i.e., the grand mean) 2. Algebraic background (see Figure 7.1, Stevens, 2007) a. Concept of a linear regression line b. Slope = b = change in y / change in x c. Isolating 𝑌̅𝑖∗ by manipulating the formula 3. Geometric explanation (see Figure 7.2, Stevens, 2007) B. Reduction of error variance 1. If the correlation between the covariate and the dependent variable is denoted as rxy, the proportion of the variance in the dependent 2 variable that is accounted for by the covariate is 𝑟𝑥𝑦 (MSw), that is, r-squared multiplied by the mean square within 2. The within group variability left after the proportion due to the 2 covariate is removed is MSw – 𝑟𝑥𝑦 (MSw) which is equal to MSw(1 2 𝑟𝑥𝑦 ) 3. This will reflect a reduction in the adjusted mean square within which is denoted as 𝑀𝑆𝑤∗ 2 4. Example a. A three group, one-way ANOVA results in F = 200/100 = 2, p > .05; this is a non-significant result b. The correlation between the pretest and dependent variable is .71 c. Using the equation above, the 𝑀𝑆𝑤∗ ≈ 100[1 – (.71)2] ≈ 50 d. There is a corresponding adjustment made to the 𝑀𝑆𝑏∗ that can be calculated using the formula discussed in Stevens (2007) on pages 293—297 e. The final F ratio is F* = 𝑀𝑆𝑏∗ / 𝑀𝑆𝑤∗ = 190/50 = 3.8, p <.05; this is a statistically significant result C. Covariates (see Stevens, p. 163) 1. High correlations with dependent variable 2. Low inter-correlations among covariates III. Hypotheses A. Similarity to ANOVA with the exception that the adjusted means are used B. H0: 𝜇1∗ = 𝜇2∗ = … 𝜇𝑖∗ C. H1: 𝜇𝑖∗ ≠ 𝜇𝑗∗ for some i, j IV. Assumptions A. ANOVA assumptions B. Additional assumptions 1. A linear relationship between the dependent variable and the covariate(s) a. Examine with a scatterplot of the relationship between the dependent variable and covariate b. In SPSS use the GRRAPHS menu, LEGACY DIALOGS, and select SCATTER/DOT. Click on SIMPLE SCATTER 3 and then DEFINE. 2. Homogeneity of regression slopes a. See Figure 7.3, Stevens, 2007 b. In SPSS program a two factor ANOVA using the covariate as one of the independent variables. Examine the interaction effect for the independent and dependent variables. 3. Covariate is measured without error V. Post-hoc procedures A. See Stevens (p. 174-179) and Hinkle (p. 524-528) VI. Comments on using ANCOVA A. Importance of assumptions B. Adjusting means 1. Any statistical adjustment is incomplete 2. Adjusting means a. Any statistical adjustment is incomplete b. Logic of “equating” groups and then generalizing results to this average group c. Differential growth of subjects 3. Use of highly reliable instruments VII. Examples A. Hinkle (p.520) B. Stevens (p.164) C. SPSS programming 4 5 6 7 Algebraic Proof of Adjusted Means Formula Slope of a Straight Line = b = (Change in Y) (Change in X) Y b ' i Y i X Xi ' b X X i Y i Y i ' Yi Yi b X Xi Y i Y b 1 1 X X i ' Yi Y b X i X ' Means and Adjusted means for Hypothetical Three Group Data Set Mean Xi Yi Group 1 32 70 Group 2 34 65 Group 3 42 62 ' 72↑ 66↑ 59↓ Yi The grand mean is 36 and a common slope of 0.50 is being assumed here. ' Y 1 = 70 - 0.50(32 -36) = 72 ' Y 2 = 65 - 0.50(34 -36) = 66 ' Y 3 = 62 - 0.50(42 -36) = 59 The arrows next to the adjusted means indicate that the means are adjusted linearly upward or downward to what they would be if the groups had started out at the grand mean on the covariate. 8