AP Statistics Section 14.
advertisement

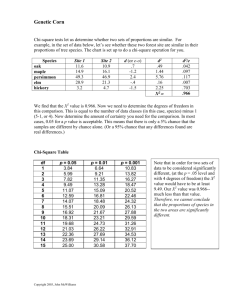
AP Statistics Section 14. The main objective of Chapter 14 is to test claims about qualitative data consisting of frequency counts for different categories. In section 14.1, we consider multinomial experiments which are defined in much the same way as binomial experiments (section 8.1) except that a multinomial experiment has more than two categories. A multinomial experiment meets the following criteria: 1. The number of trials is fixed 2. The trials are independent 3. The outcome of each trial can be classified into exactly one of several different categories 4. The probabilities for the different categories remain the same for each trial The goal of section 14.1 is to consider a method for testing a claim that the frequencies observed in the different categories “fit” a particular distribution. The method is consequently called a goodness-of fit test. A goodness-of-fit test is used to test a hypothesis that an observed frequency distribution fits some claimed form. We will use the following notation: O represents the observed frequency in a particular category E represents the expected frequency in a particular category k represents the number of different categories n represents the number of trials Let’s discuss E, the expected frequency, further. If the expected frequencies in the various categories are equal, then n E= k If the expected frequencies in the various categories are not equal, then E = np Sample frequencies typically deviate, at least somewhat, from the values that we would expect. The question we want to answer is, “are the differences between the observed values, O, and the expected values, E, statistically significant?” The Chi-Square ( 2 ) Test for Goodness of Fit To test the hypotheses equal the hypothesized proportions H0: the actual population proportions _________________________ at least two of the actual population proportions differ from their Ha: _______________________________________ hypothesized proportions Test Statistic: 2 O E 2 X = E Use the 2 distribution with _____ k 1 degrees of freedom, written as 2(k-1). 2 2 X P-value = P(________) Conditions: All individual expected counts are at least _____ 1 and not more than 20% of the counts are less than _____. 5 Example 1: Four car-pooling students missed their statistics test and gave a flat tire as their excuse. At the make-up test the instructor asked them to identify the tire that went flat. If they didn’t really have a flat tire, would they be able to randomly identify the same tire? The instructor asked his 40 other students to identify the tire they would select and the results are given in the following table. Tire selected # selected left-front 11 right-front 15 left-rear 8 right-rear 6 Use a .05 significance level to test the claim that the results fit a uniform distribution. Hypothesis: The population of interest is ________________ all statistics students PLF PRF PLR PRR .25 H0: _____________________ at least two of the population proportions differ from .25 Ha: ________________________________________ each P is the proportion of students picking that tire where _____________________________________ Conditions: SRS : This is actually a convenience sample, so results may not generalize to the population. All expected counts are greater than 5. (i.e. 40 10) 4 No reason not to expect trails are not independent. Calculations: 2 2 2 2 11 10 15 10 8 10 6 10 2 10 10 10 10 2 4.6 D of F 4 - 1 3 P - value : Table : between .20 and .25 Calc. : .204 4.6 2 cdf (lower , upper , DofF ) Conclusions: With a p - value of .204, we fail to reject the H 0 at the .05 significance level. We conclude that the proportions for the 4 tires picked by stastistic students do not differ from .25. Example 2: Among drivers who have had a car crash in the last year, 88 are randomly selected and categorized by age. Age under 25 # of drivers 36 25 - 44 21 45 - 64 12 over 64 19 If all ages have the same crash rate, we would expect, because of the age distribution of drivers, the four categories to have rates of 16%, 44%, 27% and 13% respectively. At the .05 significance level, test the claim that the distribution of crashes conforms to the distribution of ages. Hypothesis: The population of interest is _________ all drivers P 25 .16, P25 44 .44, P4564 .27, P65 .13 H0: ________________________________________ Ha: ________________________________________ at least two of the population proportions differ from these each P is the proportion of crashes in each age group where _____________________________________ Conditions: No reason not to assume the sample is an SRS. All expected counts are greater than 5, the smallest being (88)(.13) 11.44. Reasonable to assume sample results are independent. If sampling done w/o replacement then N 10n Calculations: 2 36 14 . 08 2 53.05 14.08 p value 1.79 x10 11 53.05 Conclusions: Our p - value is less than the .05 significance level so we reject the H 0 and conclude that in at least two of the categories the proportion of crashes differs from the proportion of drivers in that category. Properties of the Chi-Square Distributions 1. The total area under a chi-square density curve is equal to ______. 1 2. Chi-Squared distributions take only positive values. 3. Each chi-square curve is __________________. right skewed The curve becomes more symmetrical and looks more Normal as the number of degrees of freedom increases. Follow-up Analysis If we find significance in a chi-square test for goodness of fit, we can conclude that our variable has a distribution different from the specified one. In this case, it is always a good idea to determine which categories of the variable provide the greatest differences between observed and expected counts. This category is called the largest ____________of component the chi-square statistic. For example 2, the largest component was __________ under 25