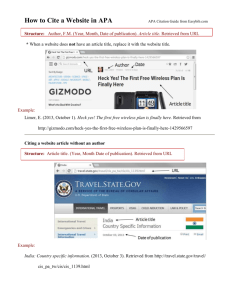
Relational Database Management Systems
advertisement

Knowledge Discovery in Databases & Information Retrieval University of Texas at Austin School of nformation i Knowledge Management Systems Presented April 29, 2003 By Anne Marie Donovan Knowledge Discovery in Databases “The nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data” (Fayyad, Piatetsky-Shapiro, and Smyth, 1996, p. 30) Also known as knowledge extraction, information harvesting, data archeology, and information extraction (p. 28) Information Retrieval “The methods and processes for searching relevant information out of information systems that contain extremely large numbers of documents” (Rocha, 2001, 1.1) “The ultimate goal of IR is to produce or recommend relevant information to users” (1.2) “Traditional IR does not identify users and classifies subjects only with unchanging keywords and categories” (1.2) Institutions that use KDD/IR systems Require knowledge-based decisions Have a large quantity of accessible, relevant, historical and current data Have a high payoff for correct decisions Financial: banking & investment Medical: healthcare & insurance Sales: marketing & customer relations (Piatetsky-Shapiro, 1998, Slides 28-31) Database Management Systems File Systems Relational Database Management Systems (RDBMS) Object-Oriented Database Management Systems (OODBMS) Object-Relational Database Management Systems (ORDBMS) (Devarakonda, 2001, ORDBMS) Relational Database Management Systems (RDBMS) Relational databases are composed of many relations in the form of two-dimensional tables of rows and columns RDBMS advantages include the SQL standard (enables migration between database systems), rapid data access and large storage capacity RDBMS disadvantages include an inability to handle complex data types and relationships (Devarakonda, 2001, RDBMS) Object-Oriented Database Management Systems (OODBMS) OODBMS use abstract data types (ADTs) in which the internal data structure is hidden OODBMS data is managed through two sets of relations, one describing the interrelations of data items and another describing the abstract relationships OODBMS handle complex data relationships, but suffer from poor performance and problems of scalability (Devarakonda, 2001, OODBMS) Object-Relational Database Management Systems (ORDBMS) ORDBMS store all database information in tables, but some entries have richer data structure that are also called abstract data types (ADTs). ORDBMS exhibit features of both the relational and object models such as scalability and support for rich data types Their main advantage is massive scalability (Devarakonda, 2001, ORDBMS) The KDD Process Collecting and pre-processing data The problem of continually increasing volumes of data The problem of increasingly complex forms of data Identifying and extracting useful knowledge from large data repositories What knowledge is in the data set? What can be observed about the data set? Presenting the knowledge in usable forms (Fayyad et al., 1996) The KDD Process (continued) Data management problems in data collection, storage, and retrieval Translation, change detection, integration, duplication, summarization; aggregation, timeliness/datedness (Widom, 1995) The impracticality of manual analysis Billions of records and hundreds of fields Increasing desire for on-the-fly analysis and more flexible presentation (Fayyad et al., p. 28) The KDD Process (continued) A need to automate the knowledge discovery and extraction processes Data selection and pre-processing Data transformation and mining Interpretation and evaluation (p. 28) Automation requires attention to: Data collection, storage, and retrieval Statistical foundations of search and retrieval processes (p. 29) Stages in the KDD process Learning the application domain Creating a target data set Data cleaning and preprocessing Data reduction and projection Choosing the function of data mining Choosing the data mining algorithm Data mining Interpretation Using discovered knowledge (pp. 30-31) Data mining The application of specific algorithms to a data set for the purpose of extracting data patterns (p. 28) “Fitting models to or determining patterns from observed data” (p. 31) Data warehousing Collecting and “cleaning” transactional data to make it available for online analysis and decision support (p. 30) Data mining tasks Classification: predicting an item class Forecasting: predicting a parameter value Clustering: finding groups of items Description: describing a group Deviation detection: finding changes Link analysis: finding relationships and associations Visualization: presenting data visually to facilitate human discovery (Piatetsky-Shapiro, 1998, Slide 17) Components of data mining systems Model functions: classification, regression, clustering, etc. (pp. 31 -32) Model representation: decision trees and rules, linear models, non-linear models, example-based methods, etc. (p. 32) Preference criterion: quantitative criterion embedded in the search algorithm; implicit criterion embedded in the KDD process Search algorithms: parameter search (given a model) or model search over model space There is NO universal search algorithm Each type of search suits specific types of search problems The searcher must be careful to properly formulate the question The searcher must understand the search goal (p. 31) Every search can be improved by an increase in data or query context Creating context for KDD and IR Extending IR throughout the social network of an organization, e.g., Answer Garden (Ackerman, 1994 & Ackerman and MacDonald, 1996) Providing social context for data exchange, e.g., PeopleGarden (Xiong and Donath, 1999) Relational database reverse engineering, “extracts a conceptual model from an existing relational database by analyzing data instances as well as metadata” (Lee and Hwang, 2002, Conclusion) KD & IR problems for Web resources Collecting and pre-processing data Even more continually changing data Complex data; streaming & multi-media The problem of identifying and extracting useful knowledge from Web resources No consistent data models; no context A lack of descriptive information Presenting the knowledge in usable forms More and more wireless devices and timesensitive, multi-media applications Current methods for Web KD & IR Collecting and pre-processing data Web crawlers and link-based ranking Human indexing and categorization Identifying and extracting useful knowledge from Web resources Keyword search on natural language text Topical directories or topical Web sites Presenting the knowledge in usable forms Content presented in native format (plugins) or in HTML Automating KD & IR for the Web Semantic markup to enable machine understanding/processing (RDF/S & DAML/OIL) & inference analysis Intelligent search engines and agents to exploit semantic statements Ontologies to provide context (a data model) for agents (Shah et. al.) Automating KD & IR for the Web (continued) Automated data collection, automated context collection (data pre-processing) Value-added services (query routing) Integrated query systems/knowledge delivery systems (accessibility) Social accounting metrics to provide context for humans (Smith, 2002, p. 52) Enhanced presentation for the Web Reformatting for presentation Differentiated service Variable visualization • Adaptive graphics, “a unifying framework that allows visual representations of information to be customized and mixed together into new ones” (Boier-Martin, 2003, pp. 6-9) • Previewing & interactive content • Selective presentation & customized views KDD and IR for pervasive computing Achieving “ubiquitous data access” (Cherniack, Franklin, & Zdonik, 2001, slide 7) Data management problems • Dissemination (context dependent pull/push) • Synchronization (multiple collectors/devices) • Recharging (renewing) multiple data streams • Profile-driven data management KDD and IR for pervasive computing (continued) Achieving “ubiquitous data access” (Cherniack, Franklin, & Zdonik, 2001, slide 7) Location aware, mobile devices Service discovery for mobile services Distributed sensors/collectors (slides 827) Next generation KDD & IR will…. Focus on solving business problems, not data analysis problems Embed knowledge discovery engines Integrate access to enterprise and external data on the back-end Integrate knowledge discovery process with knowledge delivery tools (Piatetsky-Shapiro, 1998, Slide 7) Next generation KDD & IR will…. Manage information retrieval contextually Allow contextual query/continuous query Synchronize multiple data flows from disparate sensors/input devices Enable KD in virtual networks of peer-topeer databases (data “clusters” or “cubes”) Interpolate or extrapolate for missing data (Cherniack et. al., 2001, slides 115-138) Next generation KDD & IR will…. Recognize individual users Characterize information resources Provide a way to exchange knowledge between users and information resources (push and pull of information Adapt to the user community and enable the reuse and recombination of information as well as its exchange (Rocha, 2001, 1.2) KDD research problems Massive data sets & high dimensionality User interaction & prior knowledge Determining statistical significance Missing data Understandability of patterns Management of changing data & knowledge Data integration Non-standard, multimedia, & objectoriented data (Fayyad, Piatetsky-Shapiro, & Smyth, 1996, pp. 33-34) “Top Ten” IR research issues Integrated solutions Distributed IR Efficient, flexible indexing and retrieval "Magic” (automatic query expansion) Interfaces and browsing Routing and filtering Effective retrieval Multimedia retrieval Information extraction Relevance feedback (Croft, 1995) Total Information Awareness - DARPA on the bleeding edge…... New database technologies Database architectures Database population New search algorithms and data models Genysis Goal is to produce technology enabling ultra-large, all-source information repositories http://www.darpa.mil/iao/Genisys.htm Social Issues Communicating context Creating trust/social value Inciting cooperation/collaboration Privacy tradeoffs: convenience/service or security/privacy? References Ackerman, M. S. (1998, July). Augmenting the organizational memory: A field study of Answer Garden. ACM Transactions on Information Systems, 16(3), 203-204. Retrieved March 28, 2003 from http://doi.acm.org/10.1145/290159.290160 Ackerman, M. S., & Malone, T. W. (1990, April). Answer Garden: A tool for growing organizational memory. ACM SIGOIS Bulletin, 11(.2-3), 31-39. Retrieved March 28, 2003 from http://doi.acm.org/10.1145/91474.91485 Ackerman, M. S., & McDonald, D. W. (1996). Proceedings of the ACM Conference on Computer-Supported Cooperative Work 1996 (CSCW96 Boston, MA). Retrieved March 28, 2003 from http://doi.acm.org/10.1145/240080.240203 Boier-Martin, I. M.. (2003, January/February). Adaptive graphics. In T. Rhyne (Ed.) Visualization Viewpoints, IEEE Computer Graphics and Application, 23(1), 6-10. Retrieved April 5, 2003 from http://www.research.ibm.com/people/i/imartin/papers/visviewpoints.pdf References Chakrabarti, S., Srivastava, S., Subramanyam, M., & Tiware, M. (2000). Using Memex to archive and mine community Web browsing experience. A paper presented at the 9th International World Wide Web Conference, Amsterdam, May 15-19, 2000. Retrieved April 12, 2003 from http://www9.org/w9cdrom/98/98.html Croft, W. B. (1995, November). What do people want from information retrieval?: The top 10 research issues for companies that use and sell IR systems. D-Lib Magazine. Retrieved April 5, 2003 from http://sunsite.anu.edu.au/mirrors/dlib/dlib/november95/11croft.html DARPA Information Awareness Office. (2003a). Genysis. Retrieved from the DARPA Information Awareness Office Web site at: http://www.darpa.mil/iao/Genisys.htm DARPA Information Awareness Office. (2003b). Total Information Awareness System. Retrieved from the DARPA Information Awareness Office Web site at: http://www.darpa.mil/iao/TIASystems.htm References Devarakonda, R. (2001, March). Object-Relational database systems - The road ahead. ACM Crossroads Student Magazine. Retrieved April 12, 2003 from www.acm.org/crossroads/xrds7-3/ordbms.html Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996, November). The KDD process for extracting useful knowledge from volumes of data. Communications of the ACM, 39(11), 27-34. Retrieved March 03, 2003 from http://wwwhome.cs.utwente.nl/~mpoel/colleges/dwdm/ACM_artikelen/fayyad 2.pdf Lee, D., & Hwang, Y. (2002, March 1). Extracting semantic metadata and its visualization. ACM Crossroads Student Magazine. Retrieved March 27, 2003 from www.acm.org/crossroads/xrds7-3/smeva.html Piatetsky-Shapiro, G. (1998, December 4). Data mining and knowledge discovery tools: The next generation. Retrieved February 27, 2003 from kdnuggets.com at http://www.kdnuggets.com/gpspubs/dama-nextgen-98/index.htm References Rauber, A., Aschenbrenner, A., Witvoet, O., Bruckner, R. M., & Kaiser, M. (2002, December). Uncovering information hidden in Web archives: A glimpse at Web analysis building on data warehouses. D-Lib Magazine, 8(12). Retrieved March 28, 2003 from http://www.dlib.org/dlib/december02/rauber/12rauber.html Rocha, L. M. (2001). TalkMine: A soft computing approach to adaptive knowledge recommendation [Electronic version]. In V. Loia & S. Sessa (Eds.), Studies in fuzziness and soft computing: Vol. 75. Soft computing agents: New trends for designing autonomous systems. (pp. 89-116). New York: Springer. Retrieved March 28, 2003 from http://www.c3.lanl.gov/~rocha/softagents.html Shah, U., Finin, T., Joshi, A., Cost, R. S., & Mayfield, J. (2002, November). Information retrieval on the Semantic Web. Paper presented at The ACM Conference on Information and Knowledge Management , November 2002. Retrieved March 28, 2003 from http://www.csee.umbc.edu/~finin/papers/cikm02/cikm02.pdf References Smith, M. (2002). Tools for navigating large social cyberspaces. Communications of the ACM, 45(4), 51-55. Retrieved March 28, 2003 from http://delivery.acm.org/10.1145/510000/505272/p51smith.html?key1=505272&key2=5541680501&coll=GUIDE&dl=GUIDE&C FID=9914049&CFTOKEN=12943474 Whitted, T. (1999, July/August). Draw on the Wall. IEEE Computer Graphics and Applications, 19(4), 6-9. Retrieved April 8, 2003 from ieeeexplore.ieee.org at: http://ieeexplore.ieee.org/iel5/38/16795/00773957.pdf?isNumber=16795&arnu mber=773957&prod=JNL&arSt=6&ared=9&arAuthor=Whitted%2C+T. Widom, J. (1995, November). Research problems in data warehousing. Proceedings of the 4th International Conference on Information and Knowledge Management (CIKM). Retrieved March 28, 2003 from http://www.ischool.utexas.edu/~i385tkms/readings/Widom-1995ResearchProblems.pdf References Xion, R., & Donath, J. (1999). PeopleGarden: Creating data portraits for users. CHI Letters, 1(1). 37-44. Retrieved April 8, 2003 from http://smg.media.mit.edu/papers/Xiong/pgarden_uist99.pdf