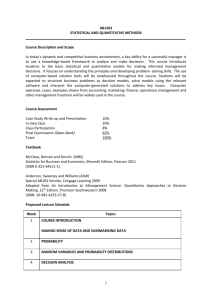
Notes 2: Inference
advertisement

Regression Models Professor William Greene Stern School of Business IOMS Department Department of Economics 2-1/49 Part 2: Model and Inference Regression and Forecasting Models Part 2 – Inference About the Regression 2-2/49 Part 2: Model and Inference The Linear Regression Model 1. The linear regression model 2. Sample statistics and population quantities 3. Testing the hypothesis of no relationship 2-3/49 Part 2: Model and Inference A Linear Regression Predictor: Box Office = -14.36 + 72.72 Buzz 2-4/49 Part 2: Model and Inference Data and Relationship We suggested the relationship between box office and internet buzz is Box Office = -14.36 + 72.72 Buzz 2-5/49 Note the obvious inconsistency in the figure. This is not the relationship. The observed points do not lie on a line. How do we reconcile the equation with the data? Part 2: Model and Inference Modeling the Underlying Process A model that explains the process that produces the data that we observe: Regression model 2-6/49 Observed outcome = the sum of two parts (1) Explained: The regression line (2) Unexplained (noise): The remainder The “model” is the statement that part (1) is the same process from one observation to the next. Part (2) is the randomness that is part of real world observation. Part 2: Model and Inference The Population Regression THE model: A specific statement about the parts of the model Model statement 2-7/49 (1) Explained: Explained Box Office = β0 + β1 Buzz (2) Unexplained: The rest is “noise, ε.” Random ε has certain characteristics Box Office = β0 + β1 Buzz + ε Part 2: Model and Inference The Data Include the Noise 2-8/49 Part 2: Model and Inference The Data Include the Noise 0+ 1Buzz Box = 41, 0+ 1Buzz = 10, = 31 2-9/49 Part 2: Model and Inference Model Assumptions y i = β0 + β1 x i + ε i β0 + β1xi is the ‘regression function’ Contains the ‘information’ about yi in xi Unobserved because β0 and β1 are not known for certain εi is the ‘disturbance.’ It is the unobserved random component Observed yi is the sum of the two unobserved parts. 2-10/49 Part 2: Model and Inference Regression Model Assumptions About εi Random Variable (1) The regression is the mean of yi for a particular xi. εi is the deviation of yi from the regression line. (2) εi has mean zero. (3) εi has variance σ2. ‘Random’ Noise 2-11/49 (4) εi is unrelated to any values of xi (no covariance) – it’s “random noise” (5) εi is unrelated to any other observations on εj (not “autocorrelated”) (6) Normal distribution - εi is the sum of many small influences Part 2: Model and Inference Regression Model Scatterplot of FUELBILL vs ROOMS 1400 1200 FUELBILL 1000 800 600 400 200 2 2-12/49 3 4 5 6 7 ROOMS 8 9 10 11 Part 2: Model and Inference Conditional Normal Distribution of Scatterplot of FUELBILL vs ROOMS 1400 1200 FUELBILL 1000 800 600 400 200 2 2-13/49 3 4 5 6 7 ROOMS 8 9 10 11 Part 2: Model and Inference A Violation of Point (4) c = 0 + 1 q + ? 2-14/49 Electricity Cost Data Part 2: Model and Inference A Violation of Point (5) - Autocorrelation Time Trend of U.S. Gasoline Consumption 2-15/49 Part 2: Model and Inference No Obvious Violations of Assumptions Auction Prices for Monet Paintings vs. Area 2-16/49 Part 2: Model and Inference Samples and Populations Population (Theory) Expected value = 0 Standard deviation σ No correlation with xi Sample (Observed) β0 + β1xi Mean of yi | xi Disturbance, εi 2-17/49 yi = β0 + β1xi + εi Parameters β0, β1 Regression Fitted regression yi = b0 + b1xi + ei Estimates, b0, b1 b0 + b1xi Predicted yi|xi Residuals, ei Sample mean 0, Sample std. dev. se Sample Cov[x,e] = 0 Part 2: Model and Inference Disturbances vs. Residuals e=y-b0 –b1Buzz =y- 0 - 1Buzz True : β 0 + β1Buzz Sample : b0 + b1Buzz 2-18/49 Part 2: Model and Inference Standard Deviation of Residuals se = 2-19/49 Standard deviation of εi = yi- β0 – β1xi is σ σ = √E[εi2] (Mean of εi is zero) Sample b0 and b1 estimate β0 and β1 Residual ei = yi – b0 – b1xi estimates εi Use √(1/N)Σei2 to estimate σ? Close, not quite. N i=1 e N- 2 2 i = N i=1 (yi - b0 - b1 x i ) N- 2 2 Why N-2? Relates to the fact that two parameters (β0,β1) were estimated. Same reason N-1 was used to compute a sample variance. Part 2: Model and Inference 2-20/49 Part 2: Model and Inference Linear Regression Sample Regression Line 2-21/49 Part 2: Model and Inference Residuals 2-22/49 Part 2: Model and Inference Regression Computations N = 62 complete observations. 1 N yi = 20.721 N i1 1 N x = i1 xi = 0.48242 N 1 N Var(x) = s2x = (x i x)2 = 0.02453 i 1 N-1 1 N Var(y) = s2y = (y i y)2 = 305.985 i 1 N-1 Cov(x,y) = s xy y= = 2-23/49 b1 = s xy s = 72.72 2 x b0 = y - bx = -14.36 i 1 yi - b0 - b1 x i 62 se = N- 2 2 = 13.386 1 N (xi x)(yi y) = 1.784 N-1 i1 Part 2: Model and Inference 2-24/49 Part 2: Model and Inference 2-25/49 Part 2: Model and Inference Results to Report 2-26/49 Part 2: Model and Inference The Reported Results 2-27/49 Part 2: Model and Inference Estimated equation 2-28/49 Part 2: Model and Inference Estimated coefficients b0 and b1 2-29/49 Part 2: Model and Inference Sum of squared residuals, Σiei2 2-30/49 Part 2: Model and Inference S = se = estimated std. deviation of ε 2-31/49 Part 2: Model and Inference Interpreting (Estimated by se) Remember the empirical rule, 95% of observations will lie within mean ± 2 standard deviations? We show (b0 +b1x) ± 2se below.) This point is 2.2 standard deviations from the regression. Only 3.2% of the 62 observations lie outside the bounds. (We will refine this later.) 2-32/49 Part 2: Model and Inference yi = β0 + β1xi + εi No Relationship: 1 = 0 Relationship: 1 0 How to Distinguish These Cases Statistically? 2-33/49 Part 2: Model and Inference Assumptions (Regression) The equation linking “Box Office” and “Buzz” is stable E[Box Office | Buzz] = α + β Buzz Another sample of movies, say 2012, would obey the same fundamental relationship. 2-34/49 Part 2: Model and Inference Sampling Variability Samples 0 and 1 are a random split of the 62 observations. Sample 0: Box Office = -16.09 + 79.11 Buzz Sample 1: Box Office = -13.25 + 68.51 Buzz 2-35/49 Part 2: Model and Inference Sampling Distributions Sampling Distribution of the Mean Estimator: x 2 s2 1 i=1 (x i -x) Standard Error: s x N N N 1 Confidence Interval: x t* s x N where t* is the appropriate value from the t table (N-1 degrees of freedom). Sampling Distribution of a Regression Coefficient Estimator: b1 Standard Error: s b1 = s e2 i=1 (x i -x)2 N N 1 (y i -b0 -b1 x i )2 i 1 N-2 N i=1 (x i -x)2 Confidence Interval: b1 t* s b1 where t* is the appropriate value from the t table (N-2 degrees of freedom). 2-36/49 Part 2: Model and Inference n = N-2 Small sample Large sample 2-37/49 Part 2: Model and Inference Standard Error of Regression Slope Estimator 2-38/49 Part 2: Model and Inference Internet Buzz Regression Regression Analysis: BoxOffice versus Buzz The regression equation is BoxOffice = - 14.4 + 72.7 Buzz Predictor Coef SE Coef T Constant -14.360 5.546 -2.59 Buzz 72.72 10.94 6.65 P 0.012 0.000 S = 13.3863 R-Sq = 42.4% R-Sq(adj) = 41.4% Analysis of Variance Source DF SS Regression 1 7913.6 Residual Error 60 10751.5 Total 61 18665.1 MS 7913.6 179.2 F 44.16 Range of Uncertainty for b is 72.72+1.96(10.94) to 72.72-1.96(10.94) = [51.27 to 94.17] If you use 2.00 from the t table, the limits would be [50.1 to 94.6] P 0.000 2-39/49 Part 2: Model and Inference Some computer programs report confidence intervals automatically; Minitab does not. 2-40/49 Part 2: Model and Inference Uncertainty About the Regression Slope Hypothetical Regression Fuel Bill vs. Number of Rooms The regression equation is Fuel Bill = -252 + 136 Number of Rooms Predictor Coef SE Coef T P Constant -251.9 44.88 -5.20 0.000 Rooms 136.2 7.09 19.9 0.000 S = 144.456 R-Sq = 72.2% R-Sq(adj) = 72.0% This is b1, the estimate of β1 This “Standard Error,” (SE) is the measure of uncertainty about the true value. The “range of uncertainty” is b ± 2 SE(b). (Actually 1.96, but people use 2) 2-41/49 Part 2: Model and Inference Sampling Distributions and Test Statistics For Testing a Hypothesis about a Mean Hypothesis: H0: μ=0, H1:μ 0 Estimator: x 2 s2 1 i=1 (x i -x) N N N 1 N Standard Error: s x = Test Statistic: t = x 0 ; t statistic N-1 D.F. sx Rejection Region: |t| > Critical Value from Table For Testing a Hypothesis about a Regression Coefficient Hypothesis: H0: 1 = 0, H1: 1 0 Estimator: b1 Standard Error: s b1 = Test Statistic: t = s e2 i=1 (x i -x)2 N N 1 (y i -b0 -b1 x i )2 i 1 N-2 N i=1 (x i -x)2 b1 0 ; t statistic N-2 D.F. s b1 Rejection Region: |t| > Critical Value from Table 2-42/49 Part 2: Model and Inference t Statistic for Hypothesis Test 2-43/49 Part 2: Model and Inference Alternative Approach: The P value Hypothesis: 1 = 0 The ‘P value’ is the probability that you would have observed the evidence on this hypothesis that you did observe if the null hypothesis were true. P = Prob(|t| would be this large | 1 = 0) If the P value is less than the Type I error probability (usually 0.05) you have chosen, you will reject the hypothesis. Interpret: It the hypothesis were true, it is ‘unlikely’ that I would have observed this evidence. 2-44/49 Part 2: Model and Inference P value for hypothesis test 2-45/49 Part 2: Model and Inference Intuitive approach: Does the confidence interval contain zero? Hypothesis: 1 = 0 The confidence interval contains the set of plausible values of 1 based on the data and the test. If the confidence interval does not contain 0, reject H0: 1 = 0. 2-46/49 Part 2: Model and Inference More General Test For Testing a Hypothesis about a Regression Coefficient Hypothesis: H0: 1 = B, H1: 1 B Estimator: b1 Standard Error: s b1 = se N i=1 2 (x i -x) 2 N 1 2 (y -b -b x ) N-2 i 1 i 0 1 i N 2 (x -x) i=1 i b1 B Test Statistic: t = ; t statistic N-2 D.F. s b1 Rejection Region: |t| > Critical Value from Table 2-47/49 Part 2: Model and Inference H0:β1 =100; H1:β1 100 Test statistic: t = b1 -100 SE(b1 ) 72.72 100 10.94 = -2.49 Critical t = -2.00. H0 is rejected. = 2-48/49 Part 2: Model and Inference Summary: Regression Analysis Investigate: Is the coefficient in a regression model really nonzero? Testing procedure: Model: y = β0 + β1x + ε Hypothesis: H0: β1 = B. Rejection region: Least squares coefficient is far from zero. Test: α level for the test = 0.05 as usual Degrees of Compute t = (b1 – B)/StandardError Freedom for Reject H0 if t is above the critical value 2-49/49 the t statistic is N-2 1.96 if large sample Value from t table if small sample. Reject H0 if reported P value is less than α level Part 2: Model and Inference