Session Slides/Handout

Biostatistics in Practice
Session 2:
Quantitative and Inferential Issues II
Youngju Pak
Biostatistician http://research.LABioMed.org/Biostat
1
What we have learned in Session 1?
Basic Study Design
Parameters vs. Statistics
Inferential vs. Descriptive statistics
Categorical vs. Quantitative Data? Why important?
Summarizing the data with graphs:
Contingency Tables, Box Plots, Histogram, etc.
How to run MYSTAT
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
Today’s topics
Article : McCann, et al., Lancet 2007 Nov
3;370(9598):1560-7
•
Subject selection /Randomization
•
Efficiency from study design
•
What statistics were used?
•
Experimental Units /
• Independence of Measurements
Normal Distributions
Confidence Intervals & P-values
78
McCann, et al., Lancet 2007 Nov 3;370(9598):1560-7
Food additives and hyperactive behaviour in 3-yearold and 8/9-year-old children in the community: a randomised, double-blinded, placebo-controlled trial.
Target population: 3-4, 8-9 years old children
Study design : randomized, double-blinded, controlled, crossover trial
Sample size: 153 (3 years), 144(8-9 years) in
Southampton UK
Objective : test whether intake of artificial food color and additive (AFCA) affects childhood behavior
McCann, et al., Lancet 2007 Nov 3;370(9598):1560-7
Sampling: Stratified sampling based on SES in Southampton, UK
Baseline measure: 24h recall by the parent of the child’s pretrial diet
Group : Three groups, for 3 years old
– mix A : 20 mg of food colorings + 45 mg sodium benzoate, which is a widely used food preservative
– mix B : 30mg of food coloring + 45 mg sodium benzoate(current average daily consumption)
– Placebo
– For 8/9 years old: multiply these by 1.25
Cross-over Design
Typical Diet Randomize Washout Randomize Washout Randomize
T0 (baseline) Week 1 Week 2 Week 3 Week 4 Week 5 Week 6
A participants receive one of 6 possible random sequences. In a separate study with
N=20, no significant difference in looks and taste of drinks among three groups was found even though people ask about which diet type they got when they received placebo (65%) > mix B (52%) > mix A (40%)
80
McCann, et al., Lancet 2007 Nov 3;370(9598):1560-7
Outcomes: Global Hyper Activity( GHA ) Score
Attention-Deficit Hyperactivity Disorder(ADHD) rating scale IV by teachers, scaled 1 – 5, higher number means more hyperactive
Weiss-Werry-Peters(WWP) hyperactivity scale by parents,
Classroom observation code,
Conners continuous performance test II (CPTII)
GHA to be aggregated from these four scores
81
Why standardized outcome measure?
GHA = Global Hyperactivity Aggregate
, where a higher value ↔ more hyperactive
For each child at each time:
Z1 = Z-Score for ADHD from Teachers
Z2 = Z-Score for WWP from Parents
Z3 = Z-Score for ADHD in Classroom
Z4 = Z-Score for Conner on Computer
, where Z-score= (Score-Score at T0)/SD to make each measure scaled similarly.
GHA= Mean of Z1, Z2, Z3, Z4
82
Why normal distribution?
• Symmetric.
• One peak.
• Roughly bell-shaped.
• No outliers.
Many statistical tests(parametric) rely on the assumption that outcome measures follow the normal distribution.
83
A property of the normal distribution
For bell-shaped distributions of data
(“normally” distributed):
• ~ 68% of values are within mean ± 1 SD
• ~ 95% of values are within mean ±2 SD
“(Normal) Reference Range”
• ~ 99.7% of values are within mean ±3 SD
84
What if it is not normally distributed
Skewed Multi-Peak
150
100
50
0
0 1 2 3 4
Intensity
5 6 7 8
Need to transform intensity to another scale, e.g.
Log(intensity)
Or Nonparametric tests
20
10
0
20 70
Tumor Volume
120
Need to summarize with percentiles, not mean.
Nonparametric tests
85
Representative or Random Samples
How were the children to be studied selected
(second column on the first page)?
The authors purposely selected "representative" social classes.
Is this better than a "randomly" chosen sample that ignores social class?
Often hear: Non-random = Non-scientific .
Case Study: Participant Selection
No mention of random samples.
Case Study: Participant Selection
It may be that only a few schools are needed to get sufficient individuals.
If, among all possible schools, there are few that are lower SES, none of these schools may be chosen.
So, a random sample of schools is chosen from the lower SES schools, and another random sample from the higher SES schools.
Non-Completing or Non-Adhering Subjects
Is it really a random sample? If not, what are the problems?
Why Randomize?
So that groups will be similar except for the intervention.
So that, when enrolling, we will not unconsciously choose an “appropriate” treatment for a particular subject.
Minimizes the chances of introducing bias when attempting to systematically remove it, as in plant yield example .
Case Study: Crossover Design
Each child is studied on 3 occasions under different diets.
Is this better than three separate groups of children?
Why, intuitively?
How could you scientifically prove your intuition?
Estimated mean changes and their Confidence Intervals
Confidence
Line or Profile Plot Interval
92
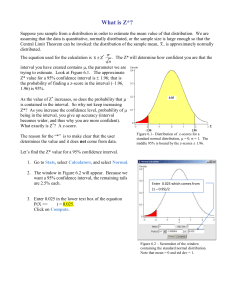
What information was given by these confidence intervals?
Confidence Interval (CI)
• How well your sample mean(m) reflects the true( or population) mean
How confident?
95%?
• A confidence interval (CI) is one of inferential statistics that estimate the true unknown parameter using interval scales.
93
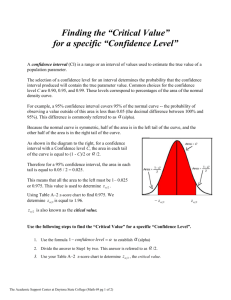
Confidence Interval for Population Mean
95% Reference range or “Normal Range”, is sample mean ± 2(SD)
_____________________________________
95% Confidence interval (CI) for the (true, but unknown) mean for the entire population is sample mean ± 2(SD/√N)
SD/√N is called “Std Error of the Mean” (SEM)
94
Table 2
Confidence Interval: Case Study
Adjusted
CI
0.13
-0.12
-0.37
Confidence Interval :
-0.14 ± 1.99(1.04/√73) =
-0.14 ± 0.24 → -0.38 to 0.10
Normal Range :
-0.14 ± 1.99(1.04) =
-0.14 ± 2.07 → -2.21 to 1.93
close to
95
96
P-values !
• Used the evidence of contradiction to your null hypothesis (H
0
)
– e.g., H
0
: no difference in mean GHA scores among three different diet.
• Based on the statistical test
– Eg., T test statistics = Signal / Noise
– if Signal >> Noise statistically significant
• Usually p < 0.05 called as “statistically significant” in favor of H a
97
Experimental Units
_____
Independence of
Measurements
98
Units and Independence
Experiments may be designed such that each measurement does not give additional independent information.
Many basic statistical methods require that measurements are “independent” for the analysis to be valid.
In mathematics, two events are independent if and only if the occurrence of one event makes it neither more nor less probable that the other occurs.
99
Experimental Units in Case Study
What is the experimental unit in this study?
1. School
2. Child
3. Parent
4. GHA score (results from three diets)
Are all GHA scores(eg. 153 x 3 groups=459 GHA scores for 3-4 years old children) independent?
The analysis MUST incorporate this possible correlation (clustering) if there exists.
eg.,
Mixed Model allowing for clustering due to schools.
100
What have we learned today?
Announcements
• Keys for HW1 and HW 2 will be posted on class website by Wednesday.
102