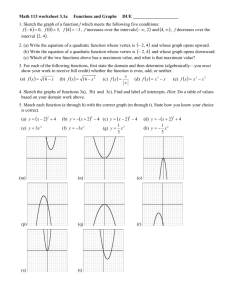
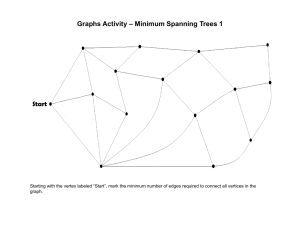
14_Graphs
advertisement

Graphs
Last Update: Dec 4, 2014
Graphs
1
Graphs
• A graph is a pair (V, E), where
– V is a set of nodes, called vertices
– E is a collection of pairs of vertices, called edges
– Vertices and edges are positions and store elements
• Example:
– A vertex represents an airport and stores the three-letter airport code
– An edge represents a flight route between two airports and stores the
mileage of the route
PVD
ORD
SFO
LGA
HNL
Last Update: Dec 4, 2014
LAX
DFW
Graphs
MIA
2
Edge Types
• Directed edge
–
–
–
–
ordered pair of vertices (u,v)
first vertex u is the origin
second vertex v is the destination
e.g., a flight
ORD
flight
AA 1206
PVD
ORD
849
miles
PVD
• Undirected edge
– unordered pair of vertices (u,v)
– e.g., a flight route
• Directed graph
– all the edges are directed
– e.g., route network
• Undirected graph
– all the edges are undirected
– e.g., flight network
Last Update: Dec 4, 2014
Graphs
3
Applications
• Electronic circuits
– Printed circuit board
– Integrated circuit
• Transportation networks
– Highway network
– Flight network
• Computer networks
– Local area network
– Internet
– Web
• Databases
– Entity-relationship diagram
Last Update: Dec 4, 2014
Graphs
4
Terminology
• End vertices (or endpoints) of an edge
– U and V are the endpoints of a
• Edges incident on a vertex
a
– a, d, and b are incident on V
• Adjacent vertices
– U and V are adjacent
U
• Degree of a vertex
V
b
d
X
c
– X has degree 5
e
W
• Parallel edges
• Self-loop
j
Z
i
g
f
– h and i are parallel edges
h
Y
– j is a self-loop
Last Update: Dec 4, 2014
Graphs
5
Terminology (cont.)
• Path
–
–
–
–
V
sequence of alternating vertices and edges
a
begins with a vertex
ends with a vertex
d
U
each edge is preceded and followed
P2
by its endpoints
c
• Simple path
– path such that all its vertices and edges
are distinct
– P1 = (V,b,X,h,Z) is a simple path
– P2 = (U,c,W,e,X,g,Y,f,W,d,V) is a path that is not simple
Graphs
P1
X
e
W
• Examples:
Last Update: Dec 4, 2014
b
Z
h
g
f
Y
6
Terminology (cont.)
• Cycle
– circular sequence of alternating vertices and edges
– each edge is preceded and followed by its endpoints
• Simple cycle
– cycle such that all its vertices and
edges are distinct
• Examples:
U
– C1 = (V,b,X,g,Y,f,W,c,U,a,)
is a simple cycle
– C2 = (U,c,W,e,X,g,Y,f,W,d,V,a,)
is a cycle that is not simple
Last Update: Dec 4, 2014
a
Graphs
c
V
b
d
C2
X
e
C1
g
W
f
h
Z
Y
7
Properties
Notation
Property 1
v
deg(v) = 2m
Proof: each edge is counted twice
n
m
deg(v)
number of vertices
number of edges
degree of vertex v
Property 2
In an undirected graph with no self-loops and
no multiple edges
m n (n - 1)/2
Proof: each vertex has degree at most (n - 1)
What is the bound for a directed graph?
Last Update: Dec 4, 2014
Graphs
8
Vertices and Edges
• A graph is a collection of vertices and edges.
• We model the abstraction as a combination of three data
types: Vertex, Edge, and Graph.
• A Vertex is a lightweight object that stores an arbitrary
element provided by the user (e.g., an airport code)
– We assume it supports a method, element(), to retrieve the stored
element.
• An Edge stores an associated object (e.g., a flight number,
travel distance, cost), retrieved with the element( )
method.
Last Update: Dec 4, 2014
Graphs
9
Graph ADT: part 1
Last Update: Dec 4, 2014
Graphs
10
Graph ADT: part 2
Last Update: Dec 4, 2014
Graphs
11
Edge List Structure
• Vertex object
– element
– reference to position in vertex sequence
• Edge object
–
–
–
–
element
origin vertex object
destination vertex object
reference to position in edge sequence
• Vertex sequence
– sequence of vertex objects
• Edge sequence
– sequence of edge objects
Last Update: Dec 4, 2014
Graphs
12
Adjacency List Structure
• Incidence sequence for each vertex
– sequence of references to edge objects
of incident edges
• Augmented edge objects
– references to associated positions in
incidence sequences of end vertices
Last Update: Dec 4, 2014
Graphs
13
Adjacency Map Structure
• Incidence sequence for each vertex
– sequence of references to adjacent
vertices, each mapped to edge object of
the incident edge
• Augmented edge objects
– references to associated positions in
incidence sequences of end vertices
Last Update: Dec 4, 2014
Graphs
14
Adjacency Matrix Structure
• Edge list structure
• Augmented vertex objects
– Integer key (index) associated with vertex
• 2D-array adjacency array
– Reference to edge object for adjacent vertices
– Null for non-adjacent vertices
• The “old fashioned”
version just has
0 for no edge and
1 for edge
Last Update: Dec 4, 2014
Graphs
15
Performance
n vertices, m edges
no parallel edges
no self-loops
Edge
List
Adjacency
List
Adjacency
Matrix
Space
n+m
n+m
n2
incidentEdges(v)
areAdjacent (v, w)
m
m
deg(v)
min(deg(v), deg(w))
n
1
insertVertex(o)
1
1
n2
insertEdge(v, w, o)
1
1
1
removeVertex(v)
m
n2
removeEdge(e)
1
deg(v)
max(deg(v), deg(w))
Last Update: Dec 4, 2014
Graphs
1
16
Subgraphs
• A subgraph S of a graph G is a graph such that
– The vertices of S are a subset of the vertices of G
– The edges of S are a subset of the edges of G
• A spanning subgraph of G is a subgraph that
contains all the vertices of G
Subgraph
Last Update: Dec 4, 2014
Spanning subgraph
Graphs
17
Connectivity
• A graph is connected if there is a path between every
pair of vertices
• A connected component of a graph G is a maximal
connected subgraph of G
Non connected graph with two
connected components
Connected graph
Last Update: Dec 4, 2014
Graphs
18
Trees and Forests
• A (free) tree is an undirected graph T such that
– T is connected
– T has no cycles
This definition of tree is different from the one of a rooted tree
• A forest is an undirected graph without cycles
• The connected components of a forest are trees
Tree
Last Update: Dec 4, 2014
Forest
Graphs
19
Spanning Trees and Forests
• A spanning tree of a connected graph is a spanning
subgraph that is a tree
• A spanning tree is not unique unless the graph is a tree
• Spanning trees have applications to the design of
communication networks
• A spanning forest of a graph is a spanning subgraph
that is a forest
Spanning tree
Graph
Last Update: Dec 4, 2014
Graphs
20
Depth-First Search
A
B
D
E
C
Last Update: Dec 4, 2014
Graphs
21
Depth-First Search
• DFS is a general graph traversal
technique
• DFS(G)
– Visits all the vertices and edges of G
– Determines whether G is connected
– Computes the connected
components of G
– Computes a spanning forest of G
• DFS on a graph with n
vertices and m edges
takes O(n + m ) time
• DFS can be further
extended to solve other
graph problems
– Find and report a path
between two given vertices
– Find a cycle in the graph
• Depth-first search is to
graphs what Euler tour is
to binary trees
Last Update: Dec 4, 2014
Graphs
22
DFS Algorithm from a Vertex
Last Update: Dec 4, 2014
Graphs
23
Java Implementation
Last Update: Dec 4, 2014
Graphs
24
Example
A
unexplored vertex
visited vertex
unexplored edge
discovery edge
back edge
A
A
B
D
E
A
D
E
B
C
Last Update: Dec 4, 2014
E
C
A
B
D
C
Graphs
25
Example (cont.)
A
B
A
D
E
B
C
C
A
A
B
D
E
B
C
Last Update: Dec 4, 2014
D
E
D
E
C
Graphs
26
DFS and Maze Traversal
• The DFS algorithm is
similar to a classic
strategy for exploring a
maze
– We mark each
intersection, corner and
dead end (vertex) visited
– We mark each corridor
(edge ) traversed
– We keep track of the
path back to the
entrance (start vertex)
by means of a rope
(recursion stack)
Last Update: Dec 4, 2014
Graphs
27
Properties of DFS
Property 1: DFS(G, v) visits all the vertices and edges in
the connected component of v
Property 2: The discovery edges labeled by DFS(G, v)
form a spanning tree of the connected component of v
A
B
D
E
C
Last Update: Dec 4, 2014
Graphs
28
Analysis of DFS
• Setting/getting a vertex/edge label takes O(1) time
• Each vertex is labeled twice
– once as UNEXPLORED
– once as VISITED
• Each edge is labeled twice
– once as UNEXPLORED
– once as DISCOVERY or BACK (for undirected graphs)
• Method incidentEdges is called once for each vertex
• DFS runs in O(n + m) time provided the graph is
represented by the adjacency list structure
– Recall that
Last Update: Dec 4, 2014
v deg(v)
= 2m
Graphs
29
Path Finding
• We can specialize the DFS algorithm
to find a path between two given
vertices u and v using the template
method pattern
• Initially call pathDFS(G, u, v)
• Use a stack S to keep track of the
path between the start vertex and
the current vertex
• As soon as destination vertex v is
encountered, return the path as the
contents of the stack
Last Update: Dec 4, 2014
Graphs
Algorithm pathDFS(G, x, v)
setLabel(x, VISITED)
S.push(x)
if x = v return S.elements()
for all e G.incidentEdges(x)
if getLabel(e) = UNEXPLORED
w opposite(x,e)
if getLabel(w) = UNEXPLORED
setLabel(e, DISCOVERY)
S.push(e)
pathDFS(G, w, v)
S.pop(e)
else setLabel(e, BACK)
S.pop(x)
30
Path Finding in Java
Last Update: Dec 4, 2014
Graphs
31
Cycle Finding
• We can specialize the DFS algorithm
to find a simple cycle using the
template method pattern
• Use a stack S to keep track of the
path between the start vertex and
the current vertex v
• As soon as a back edge (v, w) is
encountered, return the cycle as the
portion of the stack from the top
vertex v to vertex w
Last Update: Dec 4, 2014
Algorithm cycleDFS(G, v)
setLabel(v, VISITED)
S.push(v)
for all e G.incidentEdges(v)
if getLabel(e) = UNEXPLORED
w opposite(v,e)
S.push(e)
if getLabel(w) = UNEXPLORED
setLabel(e, DISCOVERY)
cycleDFS(G, w)
S.pop(e)
else
T new empty stack
repeat
o S.pop()
T.push(o)
until o = w
return T.elements()
S.pop(v)
Graphs
32
DFS for an Entire Graph
Algorithm DFS(G) // main algorithm
Input: graph G
Output: labeling of the edges of G
as discovery edges and
back edges
for all u G.vertices()
setLabel(u, UNEXPLORED)
for all e G.edges()
setLabel(e, UNEXPLORED)
for all v G.vertices()
if getLabel(v) = UNEXPLORED
DFS(G, v)
Last Update: Dec 4, 2014
procedure DFS(G, v)
Input: graph G and a start vertex v of G
Output: labeling of the edges of G
in the connected component of v
as discovery edges and back edges
setLabel(v, VISITED)
for all e G.incidentEdges(v)
if getLabel(e) = UNEXPLORED
w opposite(v,e)
if getLabel(w) = UNEXPLORED
setLabel(e, DISCOVERY)
DFS(G, w)
else
setLabel(e, BACK)
Graphs
33
All Connected Components
Loop over all vertices, doing a DFS from each unvisted one.
Last Update: Dec 4, 2014
Graphs
34
Breadth-First Search
L0
L1
B
L2
Last Update: Dec 4, 2014
A
C
E
D
F
Graphs
35
Breadth-First Search
• BFS is a general graph traversal
technique
• BFS takes O(n + m ) time
• A BFS traversal of a graph G
• BFS can be extended to solve
other graph problems, e.g.,
–
–
–
–
Visits all vertices and edges of G
Determines whether G is connected
Computes connected components of G
Computes a spanning forest of G
– Find a path with minimum
number of edges between two
given vertices
– Find a simple cycle,
if there is one
Last Update: Dec 4, 2014
Graphs
36
BFS Algorithm
• The algorithm uses a
mechanism for setting and
getting “labels” of vertices
and edges
• Assume all vertices and
edges of G are initialized to
“UNEXPLORED”
• BFS(G, s) will partition all
vertices reachable from s in G
into levels 𝐿0 , 𝐿1 , …
Last Update: Dec 4, 2014
procedure BFS(G, s)
i 0
Li new empty queue
Li . enque(s)
setLabel(s, VISITED)
while Li . isEmpty()
Li+1 new empty queue // next level
for all v Li . elements()
for all e G.incidentEdges(v)
if getLabel(e) = UNEXPLORED
w opposite(v,e)
if getLabel(w) = UNEXPLORED
setLabel(e, DISCOVERY)
setLabel(w, VISITED)
Li +1 . enque(w)
else setLabel(e, CROSS)
i i +1 // start next level exploration
end-while
Graphs
37
Java Implementation
Last Update: Dec 4, 2014
Graphs
38
Example
L0
unexplored vertex
visited vertex
unexplored edge
discovery edge
cross edge
A
A
L0
L1
L1
L0
C
E
Last Update: Dec 4, 2014
B
C
E
A
B
A
L1
D
F
F
A
B
C
E
Graphs
D
D
F
39
Example (cont.)
L0
L1
L0
A
B
C
E
L0
L1
D
F
L0
C
E
Last Update: Dec 4, 2014
B
L2
A
B
L2
L1
L1
D
Graphs
C
E
D
F
A
B
L2
F
A
C
E
D
F
40
Example (cont.)
L0
L1
L0
L1
A
B
L2
C
E
L1
D
B
L2
F
A
C
E
D
F
A
B
L2
L0
C
E
Last Update: Dec 4, 2014
D
F
Graphs
41
Properties
Notation: Gs = connected component of s
Property 1: BFS(G, s) visits all the vertices and edges of Gs
Property 2: Discovery edges labeled by BFS(G, s) form
a spanning tree Ts of Gs
Property 3: For each vertex v in level Li
– The path of Ts from s to v has i edges
– Every path from s to v in Gs has at least i edges
A
B
L0
C
E
Last Update: Dec 4, 2014
D
L1
F
B
L2
Graphs
A
C
E
D
F
42
Analysis
• Setting/getting a vertex/edge label takes O(1) time
• Each vertex is labeled twice
– once as UNEXPLORED
– once as VISITED
• Each edge is labeled twice
– once as UNEXPLORED
– once as DISCOVERY or CROSS
• Each vertex is inserted once into a sequence Li
• Method incidentEdges is called once for each vertex
• BFS runs in O(n + m) time provided the graph is
represented by the adjacency list structure
– Recall that
Last Update: Dec 4, 2014
v deg(v)
= 2m
Graphs
43
Applications
• Using the template method pattern, we can
specialize the BFS traversal of a graph G to solve
the following problems in O(n + m) time
–
–
–
–
Compute the connected components of G
Compute a spanning forest of G
Find a simple cycle in G, or report that G is a forest
Given two vertices of G, find a path in G between them
with the minimum number of edges, or report that no
such path exists
Last Update: Dec 4, 2014
Graphs
44
DFS vs. BFS
Applications
DFS
BFS
Spanning forest, connected
components, paths, cycles
Shortest paths
Biconnected components
A
B
L0
C
E
D
L1
F
Last Update: Dec 4, 2014
B
L2
DFS
A
C
E
D
F
BFS
Graphs
45
DFS vs. BFS (cont.)
Back edge (v,w)
Cross edge (v,w)
– w is an ancestor of v in
the tree of discovery edges
– w is in the same level as v
or in the next level
A
L0
B
C
E
D
L1
F
Last Update: Dec 4, 2014
B
L2
DFS
A
C
E
D
F
BFS
Graphs
46
Directed Graphs
SFO
JFK
BOS
ORD
DFW
LAX
Last Update: Dec 4, 2014
MIA
Graphs
47
Digraphs
• A digraph is a graph
whose edges are all
directed
E
D
– Short for “directed graph”
C
• Applications
– one-way streets
– flights
– task scheduling
Last Update: Dec 4, 2014
B
A
Graphs
48
E
Digraph Properties
• A graph G=(V,E) such that
Each edge goes in one direction:
Edge (a,b) goes from a to b, but not b to a
D
C
B
A
• If G is simple, m < n(n - 1)
• If we keep in-edges and out-edges in separate
adjacency lists, we can perform listing of incoming
edges and outgoing edges in time proportional to
their size
Last Update: Dec 4, 2014
Graphs
49
Digraph Application
• Scheduling: edge (a,b) means task a must be
completed before task b can be started
cs21
cs22
cs46
cs51
cs53
cs52
cs161
cs131
cs141
cs121
the
good
life
cs151
Last Update: Dec 4, 2014
cs171
Graphs
50
Directed DFS
• We can specialize the traversal algorithms
(DFS and BFS) to digraphs by traversing
E
edges only along their direction
• In the directed DFS algorithm,
we have four types of edges
discovery edges
C
back edges
forward edges
cross edges
A
• A directed DFS starting at a vertex s
determines the vertices reachable from s
Last Update: Dec 4, 2014
Graphs
D
B
51
Reachability
• DFS tree rooted at v:
vertices reachable from v via directed paths
E
E
D
D
C
C
A
F
A
E
B
C
A
Last Update: Dec 4, 2014
D
Graphs
F
B
52
Strong Connectivity
Each vertex can reach all other vertices
a
g
c
d
e
b
f
Last Update: Dec 4, 2014
Graphs
53
Strong Connectivity
Algorithm
• For each vertex v in G do:
– Perform a DFS from v in G
G:
If there’s a w not visited, return “no”
– Let G’ be G with edges reversed
– Perform a DFS from v in G’
If there’s a w not visited, return “no”
• Else, return “yes”
• Running time: O(n(n+m))
a
d
Graphs
e
b
f
a
G’:
g
c
d
f
Last Update: Dec 4, 2014
g
c
e
b
54
Strongly Connected Components
• Maximal subgraphs such that each vertex
can reach all other vertices in that subgraph
• Can be done in O(n+m) time using DFS,
but is more complicated (similar to biconnectivity).
• [Covered in EECS3101]
a
g
c
d
e
b
f
Last Update: Dec 4, 2014
Graphs
{a,c,g}
{f,d,e,b}
55
Transitive Closure
Transitive closure of digraph G is the digraph G* such that
1. G* has the same vertices as G
2.
G* has a directed edge u v
G has a directed path from u to v (u v)
G* provides reachability information about G
D
B
C
E
D
B
G
C
A
Last Update: Dec 4, 2014
E
G*
A
Graphs
56
Computing the Transitive Closure
If there's a way to get
from A to B and from
B to C, then there's a
way to get from A to C.
• We can perform
DFS starting at each
vertex
– O(n(n+m))
Alternatively ... Use
dynamic programming:
The Floyd-Warshall
Algorithm
Last Update: Dec 4, 2014
Graphs
57
Floyd-Warshall Transitive
Closure
• Idea 1: Number the vertices 1, 2, …, n.
• Idea 2: Consider paths that use only vertices
numbered 1, 2, …, k, as intermediate vertices:
i
Uses only vertices numbered 1,…,k
(add this edge if it’s not already in)
j
Uses only vertices
numbered 1,…,k-1
k
Last Update: Dec 4, 2014
Graphs
Uses only vertices
numbered 1,…,k-1
58
Floyd-Warshall’s Algorithm
• Number vertices v1 , …, vn
• Compute digraphs G0 , … , Gn
– G0 = G
– Gk has directed edge (vi , vj) if
G has a directed path from vi
to vj with intermediate
vertices in {v1 , …, vk}
• We have that Gn = G*
• In phase k, digraph Gk is
computed from Gk – 1
• Running time: O(n3),
assuming areAdjacent is O(1)
(e.g., adjacency matrix)
Last Update: Dec 4, 2014
Algorithm FloydWarshall(G)
Input: digraph G
Output: transitive closure G* of G
i 1
for all v G.vertices()
denote v as vi
i i+1
G0 G
for k 1 .. n do
G k Gk - 1
for i 1 .. n (i k) do
for j 1 .. n (j i , k) do
if Gk – 1 . areAdjacent(vi, vk)
Gk – 1 . areAdjacent(vk, vj)
if Gk . areAdjacent(vi, vj)
Gk . insertDirectedEdge(vi, vj , k)
return Gn
Graphs
59
Java Implementation
Last Update: Dec 4, 2014
Graphs
60
Floyd-Warshall Example
SFO
JFK
BOS
ORD
DFW
LAX
Last Update: Dec 4, 2014
MIA
Graphs
61
Floyd-Warshall Example
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
62
Iterataion k = 1
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
63
Iterataion k = 1
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
64
Iterataion k = 2
No new edges added
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
65
Iterataion k = 3
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
66
Iterataion k = 3
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
67
Iterataion k = 4
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
68
Iterataion k = 4
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
69
Iterataion k = 5
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
70
Iterataion k = 5
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
71
Iterataion k = 6
No new edges added
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
72
Iterataion k = 7
No new edges added
v2
v6
v7
v4
v3
v1
Last Update: Dec 4, 2014
v5
Graphs
73
Conclusion
G*
G
v2
v6
v7
v2
v6
v4
v4
v3
v3
v1
Last Update: Dec 4, 2014
v1
v5
Graphs
v7
v5
74
DAGs and Topological Ordering
• A directed acyclic graph (DAG) is a
digraph that has no directed cycles
• A topological ordering of a
digraph is a numbering
v1 , …, vn
of the vertices such that for every
edge (vi , vj), we have i < j
• Example: in a task scheduling
digraph, a topological ordering of
tasks satisfies the precedence
constraints
• Theorem:
A digraph admits a topological
ordering if and only if it is a DAG
Last Update: Dec 4, 2014
Graphs
D
E
B
DAG G
C
A
v2
v1
D
B
C
v4
E
v5
v3 Topological
ordering of G
A
75
Topological Sorting
Number vertices, so that (u,v) in E implies u < v
wake up
1
2
study computer sci.
3
5
4
nap
7
play
eat
A typical
student day
more c.s.
8
write c.s. program
9
6
work out
bake cookies
10
sleep
11
dream about graphs
Last Update: Dec 4, 2014
Graphs
76
Algorithm for Topological Sorting
• Note: This algorithm is different than the one in the book
• Running time: Can be implemented to run in O(n + m) time
How?
Algorithm TopologicalSort(G)
H G
// temporary copy of G
n G.numVertices()
while H is not empty do
let v be a vertex with no outgoing edges
label v n
n n–1
remove v from H
Last Update: Dec 4, 2014
Graphs
77
Implementation with DFS
• Simulate the algorithm by
using DFS
• O(n+m) time.
Algorithm topologicalDFS (G)
Input: dag G
Output: topological ordering of G
n G.numVertices()
for all u G.vertices()
setLabel(u, UNEXPLORED)
for all s G.vertices()
if getLabel(s) = UNEXPLORED
topologicalDFS (G, s)
Last Update: Dec 4, 2014
procedure topologicalDFS (G, v)
Input: DAG G and a start vertex v
Output: labeling of the vertices of G
in the DFS (sub-)tree rooted at v
setLabel (v, VISITED)
for all e G.outEdges(v)
// outgoing edges
w opposite(v,e)
if getLabel(w) = UNEXPLORED
// e is a discovery edge
topologicalDFS (G, w)
else
// e is a forward or cross edge
Label v with topological number n
nn–1
Graphs
78
Topological Sorting Example
Last Update: Dec 4, 2014
Graphs
79
Topological Sorting Example
9
Last Update: Dec 4, 2014
Graphs
80
Topological Sorting Example
8
9
Last Update: Dec 4, 2014
Graphs
81
Topological Sorting Example
7
8
9
Last Update: Dec 4, 2014
Graphs
82
Topological Sorting Example
6
7
8
9
Last Update: Dec 4, 2014
Graphs
83
Topological Sorting Example
6
5
7
8
9
Last Update: Dec 4, 2014
Graphs
84
Topological Sorting Example
4
6
5
7
8
9
Last Update: Dec 4, 2014
Graphs
85
Topological Sorting Example
3
4
6
5
7
8
9
Last Update: Dec 4, 2014
Graphs
86
Topological Sorting Example
2
3
4
6
5
7
8
9
Last Update: Dec 4, 2014
Graphs
87
Topological Sorting Example
2
1
3
4
6
5
7
8
9
Last Update: Dec 4, 2014
Graphs
88
Java Implementation
Last Update: Dec 4, 2014
Graphs
89
Shortest Paths
0
A
8
4
2
B
2
Last Update: Dec 4, 2014
8
7
5
C
3
2
1
9
E
8
F
Graphs
D
3
5
90
Weighted Graphs
• In a weighted graph, each edge has an associated numerical
value, called the weight of the edge
• Edge weights may represent, distances, costs, etc.
• Example:
– In a flight route graph, the weight of an edge represents
the distance in miles between the endpoint airports
PVD
ORD
SFO
LGA
HNL
Last Update: Dec 4, 2014
LAX
DFW
Graphs
MIA
91
Shortest Paths
• Given a weighted graph and two vertices u and v, we want to find a
path of minimum total weight between u and v.
– Length of a path is the sum of the weights of its edges.
• Example: Shortest path between Providence and Honolulu
• Applications:
– Internet packet routing
– Flight reservations
– Driving directions
PVD
ORD
SFO
LGA
HNL
Last Update: Dec 4, 2014
LAX
DFW
Graphs
MIA
92
Shortest Path Properties
Property 1: A subpath of a shortest path is itself a shortest path
Property 2: There is a tree of shortest paths from a start vertex to all
the other vertices
Example:
Tree of shortest paths from Providence
PVD
ORD
SFO
LGA
HNL
Last Update: Dec 4, 2014
LAX
DFW
Graphs
MIA
93
Dijkstra’s Algorithm
• The distance from a vertex s to v is the length of a
shortest path from s to v
• Assumptions:
– connected & undirected graph
– edge weights nonnegative
• Dijkstra’s algorithm computes distances of all vertices
from a given start vertex s
Last Update: Dec 4, 2014
Graphs
94
Dijkstra’s Algorithm
• We grow a “cloud” of vertices, beginning with s and
eventually covering all vertices
• We store with each vertex v a label d(v) representing the
distance of v from s in the subgraph consisting of the cloud
and its adjacent vertices
• At each step
– We add to the cloud the vertex u outside the cloud with
the smallest distance label, d(u)
– We update the labels of the vertices adjacent to u
Last Update: Dec 4, 2014
Graphs
95
Edge Relaxation
• Consider an edge e = (u,z) such that
– u is the vertex most recently
added to the cloud
s
– z is not in the cloud
• The relaxation of edge e updates
distance d(z) as follows:
d(z) min{d(z), d(u) + weight(e)}
s
Last Update: Dec 4, 2014
Graphs
d(u) = 50
u
e
z
d(u) = 50
u
d(z) = 75
d(z) = 60
e
z
96
Example
A
8
0
4
A
8
2
B
8
7
2
C
2
1
D
9
E
F
A
8
4
B
5
8
7
5
E
2
C
3
B
2
7
5
E
A
8
Last Update: Dec 4, 2014
3
D
8
5
0
4
2
C
3
1
9
0
4
2
F
2
8
4
2
3
0
2
1
9
D
11
F
3
B
5
2
Graphs
7
7
5
E
C
3
2
1
9
D
8
F
3
5
97
Example (cont.)
A
8
0
4
2
B
2
7
7
C
3
5
E
2
1
9
D
8
F
3
5
A
8
0
4
2
B
2
Last Update: Dec 4, 2014
Graphs
7
7
C
3
5
E
2
1
9
D
8
F
3
5
98
Dijkstra’s Algorithm
Last Update: Dec 4, 2014
Graphs
99
Analysis of Dijkstra’s Algorithm
• Graph operations: We find all the incident edges once for each vertex
• Label operations:
– We set/get the distance and locator labels of vertex z O(deg(z)) times
– Setting/getting a label takes O(1) time
• Priority queue operations:
– Each vertex is inserted/removed once into/from the priority
queue, where each insertion or removal takes O(log n) time
– The key of a vertex in the priority queue is modified at most
deg(w) times, where each key change takes O(log n) time
• Dijkstra’s algorithm runs in O((n + m) log n) time provided the
graph is represented by the adjacency list/map structure
– Recall that v deg(v) = 2m
• So, running time is O(m log n) since the graph is connected
Last Update: Dec 4, 2014
Graphs
100
Java Implementation
Last Update: Dec 4, 2014
Graphs
101
Java Implementation, 2
Last Update: Dec 4, 2014
Graphs
102
Why Dijkstra’s Algorithm Works
Dijkstra’s algorithm is based on the greedy method.
It adds vertices by increasing distance.
Suppose it didn’t find all shortest distances.
Let F be the first wrong vertex the algorithm
processed.
When the previous node, D, on the true
shortest path was considered, its distance
was correct
But the edge (D,F) was relaxed at that time!
Thus, so long as d(F) > d(D), F’s distance
cannot be wrong.
That is, there is no wrong vertex
Last Update: Dec 4, 2014
Graphs
A
8
0
4
2
B
2
7
7
C
3
5
E
2
1
9
D
8
F
5
103
3
Why It Doesn’t Work for
Negative-Weight Edges
Dijkstra’s algorithm is based on the greedy method.
It adds vertices by increasing distance.
If a node with a negative incident
edge were to be added late to the
cloud, it could mess up distances
for vertices already in the cloud.
A
8
0
4
6
B
2
7
7
C
0
5
E
5
1
-8
D
9
F
4
5
C’s true distance is 1, but it
is already in the cloud with
d(C) = 5!
Last Update: Dec 4, 2014
Graphs
104
Bellman-Ford Algorithm
(not in book)
• Works even with negativeweight edges
• Must assume directed edges
(for otherwise we would have
negative-weight cycles)
• Iteration i finds all shortest
paths that use up to i edges.
• Running time: O(nm).
• Can be extended to detect a
negative-weight cycle if it exists
Algorithm BellmanFord(G, s)
for all v G.vertices()
if v = s then setDistance(v, 0)
else setDistance(v, )
for i 1 .. n - 1 do
for each e G.edges()
// relax edge e
u G.origin(e)
z G.opposite(u,e)
r getDistance(u) + weight(e)
if r < getDistance(z)
setDistance(z,r)
– How?
Last Update: Dec 4, 2014
Graphs
105
Bellman-Ford Example
Nodes are labeled with their d(v) values
0
8
4
0
8
-2
7
-2
1
3
-2
8
7
9
3
5
0
8
-2
4
7
1
-2
6
Last Update: Dec 4, 2014
1
5
4
9
0
8
4
-2
1
-2
3
-2
-2
5 8
4
9
9
4
-1
5
7
3
5
-2
Graphs
1
1
-2
9
4
9
-1
5
106
DAG-based Algorithm
(not in book)
• Works even with
negative-weight edges
• Uses topological order
• Does not use any fancy
data structures
• Is much faster than
Dijkstra’s algorithm
• Running time: O(n+m).
Last Update: Dec 4, 2014
Algorithm DagDistances(G, s)
for all v G.vertices()
if v = s then setDistance(v, 0)
else setDistance(v, )
Perform a topological sort of the vertices
for u 1 .. n do // in topological order
for each e G.outEdges(u)
// relax edge e
z G.opposite(u,e)
r getDistance(u) + weight(e)
if r < getDistance(z)
setDistance(z,r)
Graphs
107
DAG Example
Nodes are labeled with their d(v) values
1
1
0
8
4
0
8
-2
3
2
7
-2
4
1
3
-5
3
8
2
7
9
6
5
-5
5
0
8
-5
2
1
3
6
Last Update: Dec 4, 2014
4
1
4
9
6
4
5
5
0
8
-2
7
-2
1
8
5
3
1
3
4
4
-2
4
1
-2
4
3
-1
5
2
7
9
7
5
-5
5
Graphs
0
1
3
6
4
1
-2
9
4
7
(two steps)
-1
5
5
108
Minimum
Spanning Trees
Last Update: Dec 4, 2014
Graphs
109
Minimum Spanning Trees
Spanning subgraph
– Subgraph of a graph G containing
all the vertices of G
ORD
1
Spanning tree
– Spanning subgraph that is itself a
(free) tree
DEN
Minimum spanning tree (MST)
– Spanning tree of a weighted
graph with minimum total edge
weight
PIT
9
8
– Communications networks
– Transportation networks
DFW
Graphs
6
STL
4
• Applications
Last Update: Dec 4, 2014
10
7
3
DCA
5
2
ATL
110
Cycle Property
Cycle Property:
– Let T be a minimum spanning tree of
a weighted graph G
– Let e be an edge of G that is not in T
and let C be the cycle formed when
e is added to T
– For every edge f of C,
weight(f) weight(e)
Proof:
– By contradiction
– If weight(f) > weight(e) we can get a
spanning tree of smaller weight by
replacing e with f
f
2
8
4
C
6
9
3
e
8
7
7
Replacing f with e yields
a better spanning tree
f
2
6
8
4
C
9
3
8
e
7
7
Last Update: Dec 4, 2014
Graphs
111
Partition Property
U
f
Partition Property:
– Consider a partition of the vertices of G into
subsets U and V
– Let e be an edge of minimum weight across
the partition
– There is a minimum spanning tree of G
containing edge e
Proof:
– Let T be an MST of G
– If T does not contain e, consider the cycle C
formed by e+T and let f be an edge of C
across the partition
– By the cycle property,
weight(f) weight(e)
– Thus, weight(f) = weight(e)
– We obtain another MST by replacing f with e
V
7
4
9
5
2
8
8
3
e
7
Replacing f with e yields
another MST
U
f
2
V
7
4
9
5
8
8
e
3
7
Last Update: Dec 4, 2014
Graphs
112
Prim-Jarnik’s Algorithm
• Similar to Dijkstra’s algorithm
• We pick an arbitrary vertex s and we grow the MST as a cloud of
vertices, starting from s
• We store with each vertex v label d(v) representing the smallest
weight of an edge connecting v to a vertex in the cloud
• At each step:
– We add to the cloud the vertex u outside the cloud with the
smallest distance label
– We update the labels of the vertices adjacent to u
Last Update: Dec 4, 2014
Graphs
113
Prim-Jarnik Pseudo-code
Last Update: Dec 4, 2014
Graphs
114
Example
2
7
B
0
2
B
5
C
0
Last Update: Dec 4, 2014
2
0
A
4
9
5
C
5
F
8
8
7
E
7
7
2
4
F
8
7
B
7
D
7
3
9
8
A
D
7
5
F
E
7
2
2
4
8
8
A
9
8
C
5
2
D
E
2
3
7
B
0
Graphs
A
3
7
7
4
9
5
C
5
F
8
8
7
D
7
E
3
7
115
4
Example (contd.)
2
2
B
A
4
9
5
C
5
F
8
8
0
D
7
7
7
E
4
3
3
2
2
B
0
Last Update: Dec 4, 2014
Graphs
4
9
5
C
5
F
8
8
A
D
7
7
7
E
4
3
3
116
Analysis
• Graph operations
– We cycle through the incident edges once for each vertex
• Label operations
– We set/get the distance, parent and locator labels of vertex z O(deg(z)) times
– Setting/getting a label takes O(1) time
• Priority queue operations
– Each vertex is inserted once into and removed once from the priority queue,
where each insertion or removal takes O(log n) time
– The key of a vertex w in the priority queue is modified at most deg(w) times,
where each key change takes O(log n) time
• Prim-Jarnik’s algorithm runs in O((n + m) log n) time provided the graph is
represented by the adjacency list structure
– Recall that
v deg(v)
= 2m
• The running time is O(m log n) since the graph is connected
Last Update: Dec 4, 2014
Graphs
117
Kruskal’s Approach
• Maintain a partition of the vertices into clusters
– Initially, single-vertex clusters
– Keep an MST for each cluster
– Merge “closest” clusters and their MSTs
• A priority queue stores the edges outside clusters
– Key: weight
– Element: edge
• At the end of the algorithm
– One cluster and one MST
Last Update: Dec 4, 2014
Graphs
118
Kruskal’s Algorithm
Last Update: Dec 4, 2014
Graphs
119
Example
8
B
5
1
A
9
E
C 11
7
10
Last Update: Dec 4, 2014
E
2
C 11
7
F
3
H
1
2
A
Graphs
5
C 11
7
10
4
F
3
H
7
9
G
6
8
B
4
E
D
10
G
6
D
1
7
9
5
A
7
9
F
H
D
8
5
6
8
B
4
3
C 11
10
B
1
7
7
A
G
E
2
G
4
6
F
3
D
H
2
120
Example (contd.)
8
B
5
1
9
E
6
D
10
F
H
8
B
4
3
C 11
7
A
G
7
9
5
1
2
7
C 11
7
A
E
G
4
6
F
3
H
D
10
2
4 steps
8
B
1
A
5
7
9
C 11
7
10
Last Update: Dec 4, 2014
E
G
6
F
3
D
H
8
B
4
1
2
A
Graphs
7
5
9
C 11
7
10
E
G
4
6
F
3
D
H
2
121
Data Structure for Kruskal’s Algorithm
• The algorithm maintains a forest of trees
• A priority queue extracts the edges by increasing weight
• An edge is accepted if it connects distinct trees
• We need a data structure that maintains a partition,
i.e., a collection of disjoint sets, with operations:
makeSet(u): create a set consisting of u
find(u): return the set storing u
union(A, B): replace sets A and B with their union
Last Update: Dec 4, 2014
Graphs
122
List-based Partition
• Each set is stored in a sequence
• Each element has a reference back to the set
– operation find(u) takes O(1) time, and returns the set
of which u is a member.
– in operation union(A,B), we move the elements of
the smaller set to the sequence of the larger set and
update their references
– the time for operation union(A,B) is min(|A|, |B|)
• Whenever an element is processed, it goes into a
set of size at least double, hence each element is
processed at most log n times
Last Update: Dec 4, 2014
Graphs
123
Partition-Based Implementation
• Partition-based version of Kruskal’s Algorithm
– Cluster merges as unions
– Cluster locations as finds
• Running time O((n + m) log n)
– Priority Queue operations: O(m log n)
– Union-Find operations: O(n log n)
Last Update: Dec 4, 2014
Graphs
124
Java Implementation
Last Update: Dec 4, 2014
Graphs
125
Java Implementation, 2
Last Update: Dec 4, 2014
Graphs
126
Boruvka’s Algorithm (Exercise)
• Like Kruskal’s Algorithm, Boruvka’s algorithm grows many clusters at
once and maintains a forest T
• Each iteration of the while loop halves the number of connected
components in forest T
• The running time is O(m log n)
Algorithm BoruvkaMST(G)
T V // just the vertices of G
while T has fewer than n – 1 edges do
for each connected component C in T do
Let edge e be the smallest-weight edge from C
to another component in T
if e is not already in T then Add edge e to T
return T
Last Update: Dec 4, 2014
Graphs
127
Example of Boruvka’s
Algorithm (animated)
2
4
3
8
8
5
7
4
9
1
5
9
4
3
6
6
6
4
2
4
3
8
7
4
9
1
5
Last Update: Dec 4, 2014
5
3
6
6
4
Graphs
128
Union-Find Partition
Structures
Last Update: Dec 4, 2014
Graphs
129
Partitions with Union-Find
Operations
makeSet(x): Create a singleton set containing
the element x and return the
position storing x in this set
union(A,B ): Return the set A U B, destroying
the old A and B
find(p): Return the set containing
the element at position p
Last Update: Dec 4, 2014
Graphs
130
List-based Implementation
• Each set is stored in a sequence represented with
a linked-list
• Each node should store an object containing the
element and a reference to the set name
Last Update: Dec 4, 2014
Graphs
131
Analysis of List-based
Representation
• When doing a union, always move elements
from the smaller set to the larger set
Each time an element is moved it goes to a set of
size at least double its old set
Thus, an element can be moved at most O(log n)
times
• Total time needed to do n unions and finds is
O(n log n).
Last Update: Dec 4, 2014
Graphs
132
Tree-based Implementation
• Each element is stored in a node, which contains a pointer
to a set name
• A node v whose set pointer points back to v is also a set
name
• Each set is a tree, rooted at a node with a self-referencing
set pointer
• Example: The sets “1”, “2”, and “5”:
1
4
2
7
3
6
9
Last Update: Dec 4, 2014
5
8
10
11
12
Graphs
133
Union-Find Operations
• To do a union, simply make
the root of one tree point to
the root of the other
5
2
8
3
10
6
11
9
• To do a find, follow setname pointers from the
starting node until reaching
a node whose set-name
pointer refers back to itself
12
5
2
8
3
10
6
11
9
Last Update: Dec 4, 2014
Graphs
12
134
Union-Find Heuristic 1
• Union by size:
– When performing a union, make the root of smaller tree point to the
root of the larger
• Implies O(n log n) time for performing n union-find operations:
– Each time we follow a pointer,
we are going to a subtree of size
at least double the size of the
previous subtree
– Thus, we will follow at most
O(log n) pointers for any find.
5
2
8
3
6
11
9
Last Update: Dec 4, 2014
Graphs
10
12
135
Union-Find Heuristic 2
• Path compression:
– After performing a find, compress all the pointers on the path just
traversed so that they all point to the root
5
8
5
10
8
11
3
11
12
2
10
12
2
6
3
9
6
9
• Implies O(n log* n) time for performing n union-find operations:
– [Proof is somewhat involved and is covered in EECS 4101]
Last Update: Dec 4, 2014
Graphs
136
Java Implementation
Last Update: Dec 4, 2014
Graphs
137
Java Implementation, 2
Last Update: Dec 4, 2014
Graphs
138
Summary
• Graph terminology & representation data structures
• Graph Traversals:
– Depth First Search
– Breadth First Search
• Transitive Closure: Floyd-Warshall
• Topological Sorting of DAGs
• Shortest Paths in Weighted graphs
– Dijkstra, Bellman-Ford, DAGs
• Minimum Spanning Trees
– Prim-Jarnik, Boruvka, Kruskal
• Disjoint Partitions & Union-Find Structures
Last Update: Dec 4, 2014
Graphs
139
Last Update: Dec 4, 2014
Graphs
140