cudaMemcpy - Arctic Region Supercomputing Center
advertisement

Scientific discovery, analysis and
prediction made possible through
high performance computing.
An Introduction to GPGPU
Programming
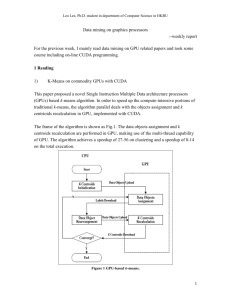
Bob Torgerson
Arctic Region Supercomputing Center
March 14th, 2014
Introduction
Contents
•
•
•
•
•
What is GPU computing?
Brief History of GPGPU
Introduction to CUDA
CUDA API Basics
Advanced CUDA Concepts
What is GPU computing?
• GPU computing is the use of the GPU
together with the CPU to accelerate
general purpose applications
– GPGPU (General Purpose Computing on GPUs)
• Offload the most computationally intense
work to the GPU
• As a tag-team, the CPU and GPU work well
together
– CPU: Optimized for serial processes – SISD (MIMD)
– GPU: Optimized for parallel processes – SIMD
Why GPU computing?
CPU vs GPU
AMD Opteron 2435 Specs
(CPU)
• 6 processor cores
– 12 virtual cores (hyperthreading)
• 904 million transistors
• ~100 GFLOPs
• 768 KB L1 Cache
• 3 MB L2 Cache
• 6 MB L3 Cache
Nvidia Tesla x2090 Specs
(GPU)
•
•
•
•
•
512 CUDA cores
3 billion transistors
1.33 TFLOPs (SP floating point)
665 GFLOPs (DP floating point)
6 GB on-board memory
– 177 GB/s memory bandwidth
Brief History of GPGPU
• On October 11th, 1999, Nvidia creates the
first ever GPU
– Offloaded the task of transformation & lighting
• In the early 2000’s, many started to notice
the power of the GPU
– Researchers started writing code in OpenGL and Cg
• Limited accessibility to general programmers and industry
• Seeing a need, Nvidia made their GPUs
fully programmable
– Offered the CUDA parallel programming model
• Works in a variety of languages, most notably C, C++ and
Fortran
Introduction to CUDA
• Compute Unified Device Architecture (CUDA)
• With CUDA, an Nvidia GPU can be used for general
purpose processing
– Only Nvidia GPUs are able to be used with CUDA
• Different versions of CUDA result in different API calls being available
• CUDA will work on all Nvidia GPUs from the
G8x series onwards
– Nvidia Tesla GPUs available on ARSC’s supercomputer
Fish compute nodes
• CUDA works on all major operating systems
– Microsoft Windows, Mac OSX, and many variants of Linux
Introduction to CUDA (cont.)
• To run CUDA at home, you can visit:
https://developer.nvidia.com/cuda-downloads
– Download the CUDA release for your operating system
• Follow the instructions in the provided “Getting Started” guide
• Once you have installed the CUDA toolkit, you
will have all of the necessary tools to compile
and run CUDA on your system
• An important tool is “nvcc” which does the
work of compiling your CUDA source code into
a binary
– CUDA source code is normally contained in a file with the
suffix .cu
CUDA API Basics
• In the following section, I will be going through
some of the basic API calls available in CUDA
• For those familiar with C/C++, these will seem
fairly natural to the language
– With a few caveats, such as << >>
• Each new API call will give information about
the API call and a small piece of example code
to show how it could be used.
DISCLAIMER: While there are Fortran examples online for
use with CUDA, I have neither tested nor tried any. All of the
following works with C.
cudaMalloc
• Similar to the malloc command for allocation
of memory on a server
– Allocates a chunk of memory in the GPU’s available
memory
• Can use a pointer to indicate the start of
available memory
– float * or void*
• Called with two arguments:
– A reference to a memory location (i.e. &var1)
– Size of memory to allocate to the memory location
• Made easier with a function called sizeof()
cudaMalloc
const int N = 20;
size_t size = 30 * sizeof(float);
float* d_A, d_B;
void* d_C;
cudaMalloc(&d_A, (10 * sizeof(float)));
cudaMalloc(&d_B, (N * sizeof(float)));
cudaMalloc(&d_C, size);
cudaFree
• cudaFree releases the memory that has been
allocated on the device
– Identical to free() for C/C++ malloc()
• cudaFree and cudaMalloc behave differently
depending on where they were executed
– cudaFree run on the device cannot free device memory that
was allocated by the host
– cudaMalloc run on the device will only be able to allocate
space up to the “cudaLimitMallocHeapSize”
• Called with a single argument:
– Pointer to memory location on device
cudaFree
float* d_A;
cudaMalloc(&d_A, 30 *
sizeof(float));
...
cudaFree(d_A);
cudaMemcpy
• This function copies data between the host system
and the GPU device
– It is required that the memory copy has a pre-allocated amount
of space available for the data to be copied
• The function is used for copying data to and from
the device and also to copy on the device
– cudaMemcpyHostToDevice
– cudaMemcpyDeviceToHost
– cudaMemcpyDeviceToDevice
• Called with 4 arguments:
– A pointer to the memory that is being copied to
– A pointer to the memory that is being copied from
– The size of the data being transferred from the second arg. to
the first arg.
– The direction to copy the data (host to device, device to host)
cudaMemcpy
cudaMemcpy(d_A, h_A, 30 * sizeof(float), cudaMemcpyHostToDevice);
...
cudaMemcpy(h_A, d_A, 30 * sizeof(float), cudaMemcpyDeviceToHost);
const int N = 50;
size_t size = N * sizeof(float);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
...
cudaMemcpy(h_B, d_B, size, cudaMemcpyDeviceToHost);
Example Code
• What does this code do?
• What would you expect the result to be from
this running on the GPU?
Kernels
• When I think of kernels, I think of two things…
CUDA Kernels
• A kernel is a function callable from the host system to the
CUDA-enabled device for being run on many threads in parallel
– This allows for work to be performed on data that has been loaded onto the
memory of the GPU
• CUDA expands the C language with a set of its own
directives for controlling the flow of execution
• Kernels are defined using one of three prefixes:
_ _ host _ _ : Runs only on the host, can only be executed from the host
_ _ device _ _ : Runs only on the device, can only be executed from device
_ _ global _ _ : Runs only on the device, can only be executed from the host
• A limitation of CUDA kernels is that they can not be recursive
(i.e. call themselves) and cannot have a variable number of
arguments
CUDA Kernel Examples
__device__ void increment_values(...) { ... }
__global__ float gpu_main(...) { ... }
__host__ int main(...) { ... }
CUDA Kernel Examples
__host__ void incrementOnHost(float *host_a, int N)
{
for (int i = 0; i < N; i++) {
host_a[i] = host_a[i] + 1.f;
}
}
__global__ void incrementOnDevice(float *device_a, int N)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
device_a[idx] = device_a[idx] + 1.f;
}
}
CUDA Thread Indexing
• You may have noticed the undefined syntax in
the previous example
– i.e. threadIdx.x, blockDim.x, blockIdx.x
• CUDA has these built-in variables for the
blocks of threads that are run against a kernel
– Rather than performing a loop, we use the parallel nature of
the threads to perform the same work
• For a better understanding of this concept,
take a look at the picture in the following slide
CUDA Thread Indexing
• The first thing to understand is that for every
kernel, a “grid” is created when executing that
kernel
– A grid is a 3-D array of blocks
• A block is a 3-D array of threads
– All of the threads within a block are able to communicate and
synchronize
– Threads within a block share memory
• A thread is a single instance of a parallel process
– To gain the true power of the GPU, hundreds of threads must be
executing in parallel
– Due to hardware restrictions, the most threads possible per block is
512
CUDA Thread Indexing
• Every CUDA thread has its own unique ID
– This can be determined in a straightforward way using its
blockDim, blockIdx & threadIdx variables
• For a 1D block:
int idx = blockIdx.x * blockDim.x + threadIdx.x;
• For a 2D block:
int idx = blockIdx.x * blockDim.x * blockDim.y +
threadIdx.y * blockDim.x + threadIdx.x;
• For a 3D block:
int idx = blockIdx.x * blockDim.x * blockDim.y *
blockDim.z + threadIdx.z * blockDim.x * blockDim.y +
threadIdx.y * blockDim.x + threadIdx.x;
CUDA Thread Indexing
• Modeling the block after the problem can
result in easier thread indexing
– For example, a matrix can be indexed like this:
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int idy = blockIdx.y * blockDim.y + threadIdx.y;
• These built-in variables can be used in a
variety of ways to index your data
• The data is accessible by all threads
– The programmer decides how best to access and
manipulate the data
CUDA Dim3 Variables
• Another CUDA addition to the C language is
the dim3 type for a variable
– dim3 provides a way of defining dimensions that a grid of
blocks or a block of threads can have
• These provide the ability for unsigned integers
to be used as the limits to these dimensions
– As their name implies, they are capable of being 3-D
definitions to match with thread structure within a block
• dim3 variables are defined using
parentheses to indicate the dimensions
– dim3 <varname>(<dim1>,<dim2>,<dim3>);
CUDA Dim3 Example
int M = 4;
int N = 8;
dim3 blocks_per_grid(M,M);
dim3 threads_per_block(N,N);
Running a CUDA Kernel
• To run a CUDA kernel, an extension to the C
language has been added
function_name<<<dimGrid, dimBlock>>>(args);
• CUDA kernels run asynchronously
– You can continue running sequential code on the CPU while
the parallel work is being done on the GPU
• Calls to the function cudaMemcpy() block the
execution of the next lines of code
– All threads running on the GPU are synchronized before
they are returned by cudaMemcpy
Example Code
• What does this code do?
• What would you expect the result to be from
this running on the GPU?
The More You Know…
• Now you know everything you need to make a
working CUDA program
– “Know enough to be dangerous…”
• Basics are easy just like in every parallel
programming extension
– Doing things right takes practice
• May not be obvious changes, requires optimization
• Understanding when a code should be written
for the GPU
– Lots of data to compute over (same data is even better)
– Using the same commands regardless of input
– Limited branching (or branching in an expected way)
CUDA Warps
• A warp may sound like something out of Star Trek
– A weaving term used to describe threads arranged lengthwise
on a loom and crossed by the “woof”
• In CUDA, the hardware is designed to execute in
groups of 32 threads
– This is known as a warp
• The smallest amount of threads that can be executed
• Naturally, 32 threads of parallel work on data is
hardly working the GPU to its fullest
– The GPU takes the input of blocks and breaks them down into
warps to be executed on the GPU
• Can be run on old, new, or future Nvidia GPUs due to the abstraction in
code for the SMs
• Conditional branching done based on warps can be
much more efficient
– Conditionals can have a profound effect on the runtime of kernels
Nvidia GPU Architecture
CUDA Memory
• Threads within the same block CAN communicate
with each other during execution
– This is due to a shared 48 KB memory block inside a streaming
multiprocessor
• Threads outside of the same block must write back
their results before they are accessible by other
blocks
– Makes memory management more complicated
• All of the threads in a block are guaranteed to run
on the same SM
– Uses the same shared memory block
• Similar to cache in CPUs, this shared memory block
is much faster than reading from the GPU memory
– Very nearly as fast as reading / writing to a GPU register
CUDA Memory
CUDA Limitations
• An SM has 32,768 registers shared amongst all
threads
– All blocks using that SM are limited by this value
• Choice of SM is done by the hardware, not by the programmer
• The number of active blocks on an SM can not
exceed 8
• The number of active warps on an SM can not
exceed 24
– Meaning only 1,024 threads per SM maximum
• 16,384 threads can be executing on all SMs at a time
• Optimizing a CUDA program
– Finding a balance between number of blocks and their size
• A block of 768 threads would be very inefficient since only one block could
be running on an SM (1024 – 768 = 256 threads idle)
• Nvidia recommends running between 128 and 256 threads per block
CUDA Shared Memory
• The shared memory available to all threads in
a block is managed by the programmer
– The CUDA software does not make use of this memory
unless requested
• Efficient use of the shared memory in blocks
contributes to faster execution of code
– Reads / writes to global device memory can be 100-150
times slower than shared memory accesses
• Takes 4 clock cycles to read from shared memory
• Takes 400 clock cycles to read from global memory!
• Registers >(=) Shared > Global
CUDA Shared Memory
• For a kernel to use shared memory, it must first
declare an amount of shared memory to allocate
– A third optional argument to the CUDA kernel execution
function_name<<<numBlocks, numDims, sharedMemSize>>>(args)
• To use the shared memory, it is easiest to let the
memory be dynamically allocated
extern __shared__ float* shared_data;
• This will allocate the full size of the shared memory to this variable
• To have more than one array of data allocated in
shared memory
extern __shared__ float* shared;
float* a = &shared[0];
float* b = &shared[count_a];
CUDA Shared Memory
Example
__global__ void testfunc(int count_a) {
extern __shared__ float* shared;
float* a = &shared[0];
float* b = &shared[count_a];
...
}
int problemSize = 256 * 2048;
int numThreadsPerBlock = 256;
int numBlocks = problemSize / numThreadsPerBlock;
int sharedMemSize = numThreadsPerBlock * sizeof(float);
int count_a = 64;
testfunc<<<numBlocks,numThreadsPerBlock,sharedMemSize>>>(count_a);
Synchronize Threads
• Before attempting to write out data to global
memory, you must synchronize the threads
– You run the risk of trying to pull from memory for data that
has not been written yet
• Race conditions…
__syncthreads();
• This is run from inside a kernel to block until all threads in a block reach
this point
• For blocking until all of the threads in a grid
have finished
cudaThreadSynchronize();
• This must be run from the host
Example Code
• What does this code do?
• What would you expect the result to be from
this running on the GPU?
CUDA Errors
• Detecting and handling errors is essential to
creating robust and usable software
– No one wants to use code that fails with no way to determine
why
• CUDA provides error codes specific to particular
problems encountered
– These error codes can be converted into a string of characters
to be displayed
• CUDA error codes have their own type: cudaError_t
char* cudaGetErrorString(cudaError_t code);
• Provides a human-readable description of the error code
• A convenient command to get the most recent
CUDA error
cudaGetLastError();
• Useful if done after a blocking call since it will get the latest error at the end
of a kernel execution for example
CUDA Error Example
void checkCUDAError(const char *msg) {
cudaError_t err = cudaGetLastError();
if ( cudaSuccess != err)
{
fprintf(stderr, “CUDA Error: %s: %s.\n”, msg,
cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
}
Example Code
• What does this code do?
• What would you expect the result to be from
this running on the GPU?
Conclusion
• CUDA is only one example of how to write
code for the GPU
– OpenCL, Microsoft’s DirectCompute, and C++ AMP
• CUDA attempts to make programming for the
GPU “easy” by providing a familiar code
structure
– Easier than passing textures in OpenGL
• Further work is being done to make running
code on the GPU truly easy
– OpenACC directives or compilation by LLVM
• Give GPU programming a try and have fun!