CUDA
advertisement

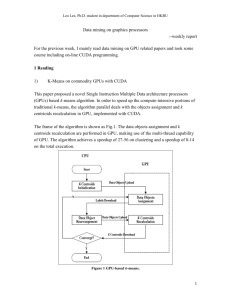
Object Oriented Framework for CUDA based Image Processing Pritam Prakash Shete, Venkat P. P. K., Dinesh M. Sarode, Mohini Laghate, S. K. Bose & R. S. Mundada, Bhabha Atomic Research Centre, Mumbai, India International Conference on Communication, Information & Computing Technology (ICCICT) Oct. 19-20,2012, Mumbai, India Keywords: Object oriented framework, CUDA, design patterns, image processing 組員名單: P76004588 P76004423 P76014216 徐華煊 曾郁凱 吳品頡 1 1. Introduction • Compute Unified Device Architecture (CUDA) – CUDA is a novel and promising GPU programming frame work from NVIDIA. – The CUDA has been speedup many computationally intensive graphics as well as nongraphic • Essential for a seamless panoramic mosaic – A pyramidal image blending algorithm • Our goal – To show that use of design patterns facilitate extending existing functionality by adding new classes, rather than modifying an existing classes or functionality 2 1. Introduction - Panoramic Mosaic 3 1. Introduction - Finding Key Point 4 2. Analysis and Design - Gaussian Blur Operation 5 2. Analysis and Design - Laplacian Pyramid doubles for the next octave σ=2*1.6σ=1.6 High frequency σ=k4*1.6 σ=k3*1.6 k = 2(1/s) s: Image per octave s = 3 in this case σ=k2*1.6 σ=k*1.6 σ=1.6 σ=k-1*1.6 Gaussian filter D(σ) L(σ) L( x, y, ) G( x, y, ) * I ( x, y) G ( x, y , ) 1 2 2 exp ( x2 y 2 ) 2 2 DoG filter n 1,2,, s D( x, y, k ( n1) ) (G( x, y, k ) G( x, y, k )) * I ( x, y ) n ( n 1 ) L( x, y, k n ) L( x, y, k ( n1) ) 6 2. Analysis and Design - Remove Edges Response 7 3. Implementation - Modules • Image Blending Library (IBL): They developed framework for CUDA based image processing. • This frame work offers 3 modules for an image processing: 1) CPU Module 2) Simple-CUDA Module 3) IO-CUDA Module 8 3. Implementation - Modules 1) CPU Module – Using single thread – Implementation function: 1. Gaussian blur 2. Laplacian pyramid 3. REDUCE operation 4. EXPAND operation 9 3. Implementation - Modules 2) Simple-CUDA Module CPU CPU Memory Send Return image image GPU Global Memory Process Image 10 3. Implementation - Modules 3) IO-CUDA Module GPU Image already get Global Memory Send Return image image Shared Memory Process Image 11 3. Implementation - Automatic Image Conversion • Visitor Design pattern – Image type: CPUBuffer image and CUDABuffer image Output: CUDABuffer Concrete Element Element Concrete Element Concrete Visitor Visitor Concrete Visitor Output: CPUBuffer 12 3. Implementation - Image Source Integration • General Hierarchy Pattern 13 3. Implementation - Extensible Architecture • Construction of Gaussian & Laplacian Pyramid 14 3. Implementation - Extensible Architecture • Building the Gaussian pyramid – Non modifiable code along with placeholders for extending it • Using Factory Method pattern placeholders – Creating the image buffer – Gaussian blur – REDUCE operation • Realized by the respective subclasses – Ex. CPUBlendingFactory – Ex. IOCUDABlendingFactory 15 3. Implementation - Extensible Architecture • Combine Pyramid Operation 16 3. Implementation - Extensible Architecture • Combine Pyramid Operation – Validating an input pyramids – Allocating memory for an output pyramid – Combining high pass and low pass images • The Template Method pattern is used to define the skeleton • Combining high pass images and low pass image are placeholder or extension points • Subclasses redefine combining high pass and low pass images without changing basic algorithm structure – Ex. CPUCombinePyramidOperation – Ex. IOCUDACombinePyramidOperation 17 4. Result • Specification – Intel Core 2 Duo with E8400 3.00 GHz processor – 2GB RAM – NVIDIA’s Quadro FX 4600 – Input images covers low resolution (128x128) as well as a high resolution (2048x2048) 18 4. Result • Panoramic image stitching 19 4. Result • CUDA based modules perform much better than the CPU module • Simple-CUDA – Device global memory • IO-CUDA module – Fast on-chip shared memory 20 5. Conclusion • Implemented an object oriented framework for a GPU based image processing • Using software engineering principles and design patterns • Extending the framework for computation using the GPU memory 21 THANK YOU 22