pptx
advertisement

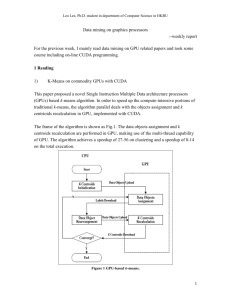
The Fast Evaluation of Hidden Markov Models on GPU Presented by Ting-Yu Mu & Wooyoung Lee Introduction Hidden Markov Model (HMM): ◦ A statistical method (Probability based) ◦ Used in a wide range of applications: Speech recognition Computer vision Medical image analysis One of the problems need to be solved: ◦ Evaluate the probability of an observation sequence on a given HMM (Evaluation) ◦ The solution of above is the key to choose the best matched models among the HMMs Introduction – Example Application: Speech Recognition Goal: Recognize words one by one Input: ◦ The speech signal of a given word → Represented as a time sequence of coded spectral vectors Output: ◦ The observation sequence → Represented as an index indicator in the spectral codebook Introduction – Example The tasks: ◦ Design individual HMMs for each word of vocabulary ◦ Perform unknown word recognition: Using the solution of evaluation problem to score each HMM based on the observation sequence of the word The model scores the highest is selected as the result The accuracy: ◦ Based on the correctness of the chosen result Computational Load Computational load of previous example consists of two parts: ◦ Estimate the parameters of HMMs to build the models, and the load varies upon each HMM Executed only one time ◦ Evaluate the probability of an observation sequence on each HMM Executed many times on recognition process The performance is depend on the complexity of the evaluation algorithm Efficient Algorithm The lower order of complexity: ◦ Forward-backward algorithm Consists of two passes: Forward probability Backward probability Used extensively Computational intensive ◦ One way to increase the performance: Design the parallel algorithm Utilizing the present day’s multi-core systems General Purpose GPU Why choose Graphic Processing Unit ◦ Rapid increases in the performance Supports floating-points operations Fast computational power/memory bandwidth GPU is specialized for compute-intensive and highly parallel computation More transistors are devoted to data processing rather that data caching CUDA Programming Model The GPU is seen as a compute device to execute part of the application that: ◦ Has to be executed multiple times ◦ Can be isolated as a function ◦ Works independently on different data Such a function can be compiled to run on the device. The resulting program is called a Kernel The batch of threads that executes a kernel is organized as a grid of blocks CUDA Programming Model Thread Block: ◦ Contains the batch of threads that can be cooperate together: Fast shared memory Synchronizable Thread ID ◦ The block can be one-, two-, or threedimensional arrays CUDA Programming Model Grid of Thread Block: ◦ Contains the limited number of threads in a block ◦ Allows larger numbers of thread to execute the same kernel with one invocation ◦ Blocks identifiable through block ID ◦ Leads to a reduction in thread cooperation ◦ Blocks can be one- or two-dimensional arrays CUDA Programming Model CUDA Memory Model Parallel Algorithm on GPU The tasks of computing the evaluation probability is split into pieces and delivered to several threads ◦ A thread block evaluates a Markov model ◦ Calculating the dimension of the grid: Obtained by dividing the number of states N by the block size ◦ Forward probability is computed by a thread within a thread block ◦ Needs to synchronize the threads due to: Shared data CUDAfy.NET What is CUDAfy.Net? Made by Hybrid DSP Systems in Netherlands a set of libraries and tools that permit general purpose programming of NVIDIA CUDA GPUs from the Microsoft .NET framework. combining flexibility, performance and ease of use First release: March 17, 2011 Cudafy.NET SDK Cudafy .NET Library ◦ Cudafy Translator (Convert .NET code to CUDA C) ◦ Cudafy Library (CUDA support for .NET) ◦ Cudafy Host (Host GPU wrapper) ◦ Cudafy Math (FFT + BLAS) The translator converts .NET code into CUDA code. Based on ILSPY (Open Source .NET assembly browser and decompiler) Cudafy Translator GENERAL CUDAFY PROCESS Two main components to the Cudafy SDK: ◦ Translation from .NET to CUDA C and compiling using NVIDIA compiler (this results in a Cudafy module xml file) ◦ Loading Cudafy modules and communicating with GPU from host It is not necessary for the target machine to perform the first step above. ◦ 1. Add reference to Cudafy.NET.dll from your .NET project ◦ 2. Add the Cudafy, Cudafy.Host and Cudafy.Translator namespaces to source files (using in C#) ◦ 3. Add a parameter of GThread type to GPU functions and use it to access thread, block and grid information as well as specialist synchronization and local shared memory features. ◦ 4. Place a Cudafy attribute on the functions. ◦ 5. In your host code before using the GPU functions call Cudafy.Translator.Cudafy( ). This returns a Cudafy Module instance. ◦ 6. Load the module into a GPGPU instance. The GPGPU type allows you to interact seamlessly with the GPU from your .NET code. Development Requirement NVIDIA CUDA Toolkit 4.1 Visual Studio 2010 ◦ Microsoft VC++ Compiler (used by NVIDIA CUDA Compiler) Windows( XP SP3, VISTA, 7 32bit/64bit) NVIDIA GPUs NVIDIA Graphic Driver GPU vs PLINQ vs LINQ GPU vs PLINQ vs LINQ Reference ILSpy : http://wiki.sharpdevelop.net/ilspy.ashx Cudafy.NET : http://cudafy.codeplex.com/ Using Cudafy for GPGPU Programming in .NET : http://www.codeproject.com/Articles/202792/Usi ng-Cudafy-for-GPGPU-Programming-in-NET Base64 Encoding on a GPU : http://www.codeproject.com/Articles/276993/Bas e64-Encoding-on-a-GPU High Performance Queries: GPU vs LINQ vs PLINQ : http://www.codeproject.com/Articles/289551/Hig h-Performance-Queries-GPU-vs-PLINQ-vs-LINQ