Product Reliability
advertisement

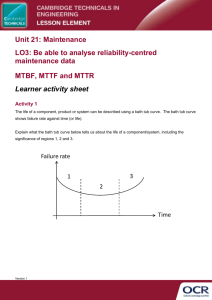
Product Reliability Chris Nabavi BSc SMIEEE 1 © 2006 PCE Systems Ltd Reliability Reliability is the probability that an equipment will operate for some determined period of time under the working conditions for which it was designed 2 The “Bathtub” Curve Failures per hour Infant Mortality End of Life Operational Life Phase Time 3 Operational Strategy 1. Run the equipment without traffic until the infant mortality period has passed - (the burn-in period) 2. Use the equipment during the operational life period 3. Retire or replace the equipment before the end of life period 4 Failure Rate This is a statistical measure, applicable to a large number of samples The failure rate, is the number of failures per unit time, divided by the number of items in the test is constant during the operational phase is often expressed in % / 1000 hours or FITs (failures in ten to the 9 hours) 5 Mean Time Between Failures (MTBF) This is a statistical measure, applicable to a large number of samples The MTBF, is the average time between failures, times the number of items in the test MTBF = 1 / failure rate 6 =1/ Measured MTBF and Failure Rate A manufacturer tests 3000 light bulbs for 300 hours and observes 5 failures Note: we don’t know the average time between failures from this test, because they have not all failed! But approximately: MTBF = 3000 x 300 / 5 = 180,000 hours Failure rate = 0.556 % per 1000 hours This measured MTBF is an under-approximation of the true MTBF 7 MTBF and End of Life MTBF is a measure of quality and has nothing to do with the expected lifetime To visualise this, think of a candle. After three hours, the wax will all be used up and it will have reached its end of life. This is its expected lifetime. However, a quality candle (higher MTBF) will be less likely to fizzle out half way down. If we light a new candle, just as each old one runs out of wax, the mean time between being unexpectedly plunged into darkness is the MTBF 8 Failure Rate (Graphical Representation) Failures per hour The failure rate is the size of this gap Time 9 Example: Typical Hard Disc 10 Rated or expected life = 5 years Guaranteed life = 3 years MTBF = 1,000,000 hours (approx. 114 years) Modern hard discs are fairly reliable, but being mechanical, they wear out after a few years Disc Replacement Strategy Observation: The expected life is much less than the MTBF and discs are the “weak link” in the system Conclusion: Replace the discs just before they wear out under a preventative maintenance program 11 Example MTBF Figures 12 ITEM MTBF N. American Power Utility 2 months ! Router 10 years Uninterruptible Power Supply 11 years File Server 14 years Ethernet Hub 120 years Transistor 30,000 years Resistor 100,000 years Operational Life Phase Reliability theory only works in the operational life phase, where the failure rates are constant With this proviso, the maths is well established and closely related to statistics There is a large amount of statistical theory concerned with sampling procedures, aimed at estimating the MTBF of components From now on, we are only concerned with the operational phase 13 Probability of Survival 1 Probability of survival p= e-t 0.37 0 14 MTBF, Time Non-Redundant System Reliability For a system S, made up of components A, B, C, etc. 1 / MTBFS = 1 / MTBFA + 1 / MTBFB + 1 / MTBFC + etc. or S = A + B + C + etc. These formulae are used to calculate the MTBF or failure rate of equipment, using published tables covering everything from a soldered joint to a disc sub-system 15 Mean Time To Repair (MTTR) The formulae discussed earlier assume zero maintenance, i.e. if a device breaks down, it is not fixed. Often, it is important to know the probability of fixing a broken system within a given time T For this we need to know the MTTR, which is worked out by examining all the steps involved and the failure modes The probability of fixing the broken system within time T can then be predicted using similar exponentials as seen already 16 Operational Readiness Operational readiness is the probability that a system will be ready to fulfil its function when called upon E.g. The probability that an email sent at a random time will get through MTBF Operational readiness = 17 / (MTBF + MTTR) Active Redundancy Either device can do the job Device 1 Device 2 18 Active Redundancy Calculations MTBFS = 1 / 1 + 1 / 2 - 1 / (1 + 2 ) Probability of survival = e-1t + e-2t - e-1t . e-2t For an active redundancy system, S made from two identical sub-systems, A MTBFS = 1.5 x MTBFA Note: The failure rate is no longer constant with time 19 Passive Redundancy When device 1 fails, switch over to device 2 Device 1 Device 2 (Device 2 not normally powered) 20 Passive Redundancy Calculations For a passive redundancy system, S made from two identical sub-systems, A and ignoring the reliability of the switch-over system Probability of survival = e-At x (1+At) MTBFS = 2 x MTBFA Note: The failure rate is no longer constant with time 21 Error Detection and Correction There are two trivially simple ways to guard against errors Send the information twice: Then at the receiver, if they are different, we have detected an error Send the information three times: Then at the receiver, accept the majority verdict to correct an error But we can do better than this ..... 22 The Hamming (7,4) code 0 0 1 0 1 0 0 0 0 1 0 0 0 0 0 1 1 1 0 1 0 1 1 1 1 0 1 1 Pink are parity check bits Green are information bits 16 codes can be obtained by adding any rows mod 2 All 16 codes have Hamming distance of 3 or more, so the code can correct a single error ----------------- The Golay (23,12) code has 12 information bits and 11 parity check bits and can correct 3 errors 23 Redundant Array of Independent Discs There are 5 RAID levels: 1 2 3 4 5 Mirrored discs Hamming code error correction Single check disc per group Independent read and write Spread data and parity over all discs In each case, disc errors are corrected; the differences are largely in the system performance 24 Effect of Non-Maintenance Consider a file server with 6 discs in an array The probability of getting a disc failure in a 6 disc RAID array in one year is about 5% which is fairly high. Assume that this happens and the problem is left unfixed for a further 3 weeks The probability of another disc failing in this time is about .25% If this happens too, you loose the server! The odds for this happening in any year are 5% of 0.25% or 1 in 8000 divided by the number of RAIDs 25 Effect of Improving the MTTR If the MTTR of the RAID had been 3 hours instead of 3 weeks, the odds are somewhat different: The probability of the first failure is still 5%. But now the probability of getting a second failure in the ensuing 3 hours is .0003% instead of .25% So the odds of loosing the RAID in any year improve to 1 in 6,666,675 from the previous 1 in 8000 Moral of the story: Fix the First Fault Fast 26