005_arizona_MM2
advertisement

Issues with
Mixed Models
Model doesn’t converge…
OR
Convergence
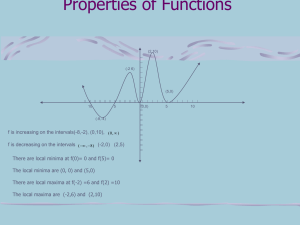
Likelihood Landscape
Likelihood Landscape
Maximum Likelihood
Estimation
Maximum Likelihood
Estimation
Maximum Likelihood
Estimation
Maximum Likelihood
Estimation
Maximum Likelihood
Estimation
Likelihood = the probability of seeing the data
we actually collected given a particular model
Maximum Likelihood Estimates = those
values that make the observed data most
likely to have happened
Sources of Convergence Problems
• You estimate more parameters than data (or,
in general, too many parameters
• Severe collinearity (e.g., two predictors are
exactly correlated)
• Missing cells in your design
• Predictors of vastly different metrics
Failure to converge
ATTITUDE
polite
informal
GENDER
male female
16
0
16
32
… and then trying to test the
ATTITUDE*GENDER interaction
How can this happen?
“Death by
Design”
(coined by
Roger Mundry)
Solutions to Convergence Problems
• Drop a random slope
(not preferred, should be reported)
• Drop subjects/items for which there is not
enough data (not preferred, should be reported)
• Rescale variables so that they lie range between 0
and 1; or make them on similar metrics overall
• Center continuous predictors
• Nonlinear transformations of skewed predictors
Solutions to Convergence Problems
• Change order of variable names in model
formula
• Have a balanced and complete design
p-values
The p-value conundrum
What are the degrees of freedom?
How to get p-values out of
mixed models is not
entirely straightforward…
Douglas
Bates
“There are a number of ways to
compute p-values from LMEMs,
none of which is
uncontroversially the best.”
Barr et al.
(2013)
Ways to get p-values
• t-test/F-test with normal approximation
• Likelihood Ratio Test
• Boostrapping
• Permutation
• Markov Chain Monte Carlo (MCMC)
Getting p-vals with normal
approximation
xmdl
coefs=data.frame(summary(xmdl)@coefs)
coefs$p = 2*(1-pnorm(abs(coefs$t.value)))
coefs
Function for getting p-vals with
normal approximation
create.sig.table =
function(x){
coefs=data.frame(summary(x)@coefs)
coefs$p = 2*(1-pnorm(abs(coefs$t.value)))
coefs$sig = character(nrow(coefs))
coefs[which(coefs$p < 0.05),]$sig = "*"
coefs[which(coefs$p < 0.01),]$sig = "**"
coefs[which(coefs$p < 0.001),]$sig = "***"
return(coefs)
}
Likelihood Ratio Test
First model needs to be nested in second
Likelihood Ratio
The likelihood ratio expresses how many
times more likely the data are under one
model than the other
Likelihood Ratio Test
Likelihood Ratio Test
Important when
doing likelihood ratio tests
lmer(…,REML=FALSE)
http://anythingbutrbitrary.blogspot.com/2012/06/r
andom-regression-coefficients-using.html
Final issue:
Random slopes
DANGEROUS!!!
Random intercept only
models are known to be
very anti-conservative
in many circumstances
(cf. Barr et al., 2013,
Schielzeth & Forstmeier, 2008)
Random intercept only
Schielzeth & Forstmeier (2008)
Type I error simulation
10 subjects
10 data points
each
5 of those in
condition A,
5 in B
LRT
LRT
LRT
LRT
z-test
z-test
z-test
z-test
intercept
slope
intercept
slope
intercept
slope
intercept
slope
ML
ML
REML
REML
ML
ML
REML
REML
0.052
0.035
0.052
0.035
0.053
0.039
0.054
0.042
Add to this explicit subject slopes
for A/B
10 subjects
10 data points
each
5 of those in
condition A,
5 in B
LRT
LRT
LRT
LRT
z-test
z-test
z-test
z-test
intercept
slope
intercept
slope
intercept
slope
intercept
slope
ML
ML
REML
REML
ML
ML
REML
REML
0.24
0.15
0.24
0.069
0.24
0.079
0.25
0.091
Add to this explicit subject slopes
for A/B
10 subjects
10 data points
each
5 of those in
condition A,
5 in B
LRT
LRT
LRT
LRT
z-test
z-test
z-test
z-test
intercept
slope
intercept
slope
intercept
slope
intercept
slope
ML
ML
REML
REML
ML
ML
REML
REML
0.24
0.15
0.24
0.069
0.24
0.079
0.25
0.091
Add to this explicit subject slopes
for A/B + take item slopes
10 subjects
10 data points
each
5 of those in
condition A,
5 in B
LRT
LRT
LRT
LRT
z-test
z-test
z-test
z-test
intercept
slope
intercept
slope
intercept
slope
intercept
slope
ML
ML
REML
REML
ML
ML
REML
REML
0.18
0.085
0.18
0.052
0.21
0.064
0.23
0.08
Add to this explicit subject slopes
for A/B + take item slopes
10 subjects
10 data points
each
5 of those in
condition A,
5 in B
LRT
LRT
LRT
LRT
z-test
z-test
z-test
z-test
intercept
slope
intercept
slope
intercept
slope
intercept
slope
ML
ML
REML
REML
ML
ML
REML
REML
0.18
0.085
0.18
0.052
0.21
0.064
0.23
0.08
“Keep it maximal”
“Keep it maximal”
random effects
justified by the design
vs.
random effects
justified by the data
Barr et al.
(2013)
“Keep it maximal”
“for whatever fixed effects are of
critical interest, the
corresponding random effects
should be in that analysis”
Barr et al.
(2013)
That’s it
(for now)