talk
advertisement

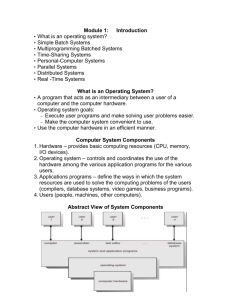
Summary Problem: Exponential Performance Gap: Computer architectures transitioned from exponential frequency scaling to parallelism ending decades of free exponential performance gains The natural “MapReduce” Belief Propagation (BP) algorithm: Embarrassingly Parallel Highly Inefficient: (Asymptotically slower than efficient sequential algorithms) Solution: Explore the limiting sequential structure using chain graphical models Introduce approximation which improves parallel performance Propose ResidualSplash, a new parallel dynamic BP Algorithm and show that it performs optimally on chain graphical models in the approximate inference setting Results: We demonstrate that our new algorithm outperforms existing techniques on two real-world tasks Many Core Revolution Transition from exponential frequency scaling to exponential parallelism Exponentially Growing Gap 512 Picochip Ambric PC102 AM2045 256 128 64 # cores Single Processor Performance Cisco CSR-1 Intel Tflops 32 Raw 16 Niagara 8 4 2 1 Raza Cavium XLR Octeon 4004 8080 8086 286 386 486 Pentium 8008 1970 1975 1980 1985 1990 Boardcom 1480 Xbox360 PA-8800 Opteron Tanglewood Power4 PExtreme Power6 Yonah P2 P3 Itanium P4 Athlon Itanium 2 1995 Year Cell 2000 Graph courtesy of Saman Amarasinghe 2005 20?? Inference in Markov Random Fields Pair wise Markov Random Field (MRF): P(X 1; : : : ; X N ) / Q Ãi (xi ) i2V Graph encoding conditional independence assumptions Factors encoding functional dependencies ( Ãi ;j ( x i ; x j ) = Noisy Image X2 X3 X4 X5 X6 X7 X8 X9 Pixels Binary Potentials Ãi (xi ) = N(oi ; ¾2) Compute marginal distribution for all variables MRF Ãi ;j (xi ; xj ) f i ;j g2 E Unary Potentials Inference Objective: X1 Q 1 e¡ xi = xj ¸ Predicted Image xi 6 = xj Loopy Belief Propagation Loopy Belief Propagation: Approximate inference method Exact on trees X m i ! j (x j à i m2! 1(x1) X1 2 A (x i ;j i ; x j )à i (x i m k 2 ¡ m4 i k ! i (x i n j m 3! m2! 1(x1) X1 Y (X i = x i ) ¼ bi ( x i ) / à i (x i ) m k 2 ¡ i X5 ) At Convergence: P X4 ! 2( x2 ) ) i m4! 2(x2) X2 Y ) / x m 3! 2) X3 x ( 2 k ! i (x i ) 2) X3 x ( 2 m4! 2(x2) X2 X4 m4 ! 2( x2 ) X5 Levels of Parallelism Message Level Parallelism Making a single message update calculation run in parallel Limited by the complexity of individual variables Graph Level Parallelism Simultaneously updating multiple messages More “parallelism” for larger models Running Time Definition: Message calculations as unit time operations Running time is measured in message calculations “MapReduce” Belief Propagation CPU 1 CPU 2 Update all messages simultaneously using p · 2(n-1) processors. Chain graphs provide a challenging performance benchmark: 2n Message Calculations t=1 n Rounds Read Only New Messages (t) Old Messages (t-1) Iterate t=n Shared Memory Running Time: 2( n ¡ p 1) 2 Efficient Chain Scheduling Optimal Sequential Scheduling Optimal Parallel Scheduling Using one processor Using two processors Send messages left to right and then right to left: Send messages left to right and right to left at the same time: CPU 1 CPU 1 t=n+1 CPU 1 t=1 n Rounds 2n Rounds t=1 CPU 2 CPU 1 t=n t=2n CPU 2 CPU 1 Running Time: Running Time: 2(n ¡ 1) n ¡ 1 Efficiency Gap! “MapReduce” Parallel Optimal Parallel (p=2) Optimal Single Processor 2n Messages CPU 1 t=n t=n+1 CPU 1 t=2n CPU 1 t=1 n Rounds n Rounds t=1 2n Rounds t=1 CPU 2 CPU 1 t=n CPU 2 CPU 1 2n p 2 2n p 2 2n n Factor n Gap! For p<n the MapReduce algorithm is slower than the efficient single processor algorithm n Cannot efficiently use more than 2 processors Breaking Sequentially with ¿²-Approximation Message errors decay over paths: m 1! True Messages 1 2 m 2! 3 2 m 3! 4 3 m 03! m 4! 5 4 4 m 04! m 5! 6 5 5 m 6! 7 6 m 05! 6 m 7! 8 7 m 06! 7 m 07! m 8! 9 8 8 m 9! 10 9 m 08! 9 m 09! 10 10 ¿²-Approximation ¿² The value of ¿² Maximum length of dependencies for a given accuracy ² Not known in practice Not known to the algorithm jjm 9! 10 ¡ 0 m 9! 10 jj · ² Based on work by [Ihler et al., 2005] Synchronous BP and ¿²-Approximation For an approximate marginal, we only need to consider a small ¿² subgraph 1 2 3 4 5 6 7 8 9 10 ¿² Theorem: 2 ( n ¡ 1 ) ¿² p = O n ¿² p t=1 ¿² Steps Given an acyclic MRF with n vertices a ¿²approximation is obtained by running Parallel Synchronous BP using p processors (p·2n) in running time: ³ ´ 2n Messages t=n Optimal Approximate Inference 2n p Evenly partition the vertices: Processor 2 Processor 3 Run sequential exact inference on each “tree” in parallel: Step 1 Step 2 Processor 1 Processor 2 Processor 3 Processor 1 Processor 2 Processor 3 Processor 1 Processor 2 Processor 3 ¿² n =p + 1 Processor 1 time per iteration We obtain the running time on chain graphs: µ O n p ¶ + ¿² Theorem: For an arbitrary chain graphical model with n vertices and p processors, a ¿²-approximation cannot in general be computed with fewer message updates than: ³ ´ n + ¿² p Proof sketch: After kth iterations of parallel message computations in one direction: n ¡ ¿² · Total required work in one direction p 2 ³ ( k ¡ ¿² + 1) Maximum possible work done by a single processor k ¸ Solving for k 2n p + ¿² ´ 1¡ 2 p ¡ 1 Splash Operation Generalizes optimal tree inference: Construct a BFS tree of a fixed size Starting at leaves invoke SendMessages on each vertex [13,12,11,…,1] Start at root invoke send SendMessages on each vertex [1,2,3,…,13] 7 6 13 5 2 1 8 3 SendMessages Routine: Using all current inbound messages compute all outbound messages 7 7 8 2 1 3 2 9 1 12 4 10 11 8 3 9 Splash(1) SendMessages(8) 9 Scheduling Splashes Not all vertices are equal: Useful Work Wasted Work Time = t A B Time = t+1 A B Difficult Easy Some vertices need to be updated more often than others Residual Scheduling Intuition: Prioritize updating messages which change the most. Message Residual: Difference between current message value and next incoming message value ¯¯ next ¯ ¯ ¯¯mi ! u ¡ mlast ¯ ¯ i! u 1 Vertex Residual: Maximum of all incoming message ¯¯ next ¯ ¯ last ¯ ¯ residuals max mi ! u ¡ mi ! u ¯¯ i2¡ m(x) residual=0.1 u 1 Vertex update! Update vertex residual! m0(x) m0(x) residual=0.1 residual=0.4 Parallel Residual Splash Shared Memory Shared Priority Queue Vertex 5 Vertex 91 Vertex 62 Vertex 22 Vertex 28 Pop top vertex from queue Build BFS tree of size s 3 2 CPU 1 CPU 2 1 Update vertices in tree in reverse Update BFS order. Update priority queue as needed CPU 1 Update vertices in tree in forward BFS order. Update priority queue as needed Return root vertex to queue CPU 1 Update 4 4 3 2 1 2 3 4 Residual Splash Running Time Theorem: For an arbitrary chain graphical model with n vertices and p processors (p ·n) and a particular initial residual scheduling the Residual Splash algorithm computes a ¿²-approximation in time: ³ ´ O np + ¿² Using a random initial priorities the Residual Splash algorithm computes a ¿²-approximation in time: ³ ³ ´´ n O l og( p) p + ¿² We suspect that the log(p) factor is not tight. Overall Performance: True Predicted Non-uniform complexity Difficult (1) (2) (3) (4) (5) (6) Region Difficulty Execution Phase Log Scale Easy Total Updates Experimental Setup Software Implementation Optimized GNU C++ using POSIX threads with MATLAB wrapper www.select.cs.cmu.edu/code Protein Side Chain prediction Video Popup Extension of Make3D [ref] to videos with edges connecting pixels over frames Depths discretized to 40 levels. 500K vertices. 3D Grid MRF 107x86x60 Predict protein side chain positions [Chen 02] 276 proteins Hundreds of variables per protein with arity up to 79 Average degree of 20 Chen Yanover and Yair Weiss. Approximate Inference and Protein Folding. NIPS 2002 Movie Stereo Images Depth Map 3D Movie (Anaglyph) Protein Results Experiments performed on an 8-core AMD Opteron 2384 processor @ 2.7 Ghz with 32 GB RAM. 3D-Video Results Experiments performed on an 8-core AMD Opteron 2384 processor @ 2.7 Ghz with 32 GB RAM. Conclusions and Future Work Trivially parallel MapReduce algorithm is inefficient Approximation can lead to increased parallelism Provided new parallel inference algorithm which performs optimal on chain graph and generalizes to loopy graphs Demonstrated superior performance on several real world tasks A cluster scale factor graph extension is under review Extend running time bounds to arbitrary cyclic graphical models Efficient parallel parameter learning Acknowledgements David O’Hallaron and Jason Campbell from Intel Research Pittsburgh who provided guidance in algorithm and task development and access to the BigData multi-core cluster. Funding provided by: ONR Young Investigator Program Grant N00014-08-1-0752 ARO under MURI W911NF0810242 NSF Grants NeTS-NOSS and CNS-0625518 AT&T Labs Fellowship Program References R. Nallapati, W. Cohen, and J. Laf erty. Parallelized variational EM for latent Dirichlet allocation: An experimental evaluation of speed and scalability. InICDMW ’07: Proceedings of the Seventh IEEEInternational Conference on Data Mining Workshops, pages 349–354, 2007. D. Newman, A. Asuncion, P. Smyth, and M. Welling. Distributed inference for latent dirichlet allocation. InNIPS, pages 1081– 1088. 2008. D. M. Pennock. Logarithmic time parallel bayesian inference. In Proc. 14th Conf. Uncertainty in Artificial Intelligence, pages 431–438. Morgan Kaufmann, 1998. C.T. Chu, S.K. Kim, Y.A. Lin, Y. Yu, G.R. Bradski, A.Y. Ng, and K. Olukotun. Map-reduce for machine learning on multicore. In NIPS, pages 281–288. MIT Press, 2006. M. Kearns. Efficient noise-tolerant learning from statistical queries. J. ACM , 45(6):983–1006, 1998. A. I. Vila Casado, M. Griot, and R.D. Wesel. Informed dynamic scheduling for belief-propagation decoding of LDPC codes. CoRR, abs/cs/0702111, 2007. A. Mendiburu, R. Santana, J.A. Lozano, and E. Bengoetxea. A parallel framework for loopy belief propagation. InGECCO ’07: Proceedings of the 2007 GECCO conference companion on Genetic and evolutionary computation , pages 2843–2850, 2007. D. Koller and N. Friedman. Probabilistic graphical models. J. Pearl. Probabilistic reasoning in intelligent systems: networks of plausible inference. 1988. ISBN 0-934613-73-7. R.J. McEliece, D.J.C. MacKay, and J.F. Cheng. Turbo decoding as an instance of Pearl’s belief propagation algorithm. Selected Areas in Communications, IEEE Journal on, 16(2):140–152, Feb 1998. J. Sun, N.N. Zheng, and H.Y. Shum. Stereo matching using belief propagation.Pattern Analysis and Machine Intelligence, IEEE Transactions on, 25(7):787–800, July 2003. J.S. Yedidia, W.T. Freeman, and Y. Weiss. Understanding belief propagation and its generalizations. pages 239–269, 2003. C. Yanover and Y. Weiss. Approximate inference and protein folding. In NIPS, pages 84–86. MIT Press, 2002. C. Yanover, O. Schueler-Furman, and Y. Weiss. Minimizing and learning energy functionsfor side-chain prediction. pages381– 395. 2007. J. Dean and S. Ghemawat. MapReduce: simplified data processing on large clusters.Commun. ACM, 51(1):107–113, 2008. A.T. Ihler, J.W. Fischer III, and A.S. Willsky. Loopy belief propagation: Convergence and ef ects of message errors. J. Mach. Learn. Res., 6:905–936, 2005. Y. Weiss. Correctness of ocal probability propagation in graphical models with loops.Neural Comput., 12(1):1–41, 2000. J.M. Mooij and H.J. Kappen. Sufficient conditions for convergence of the Sum-Product algorithm. Information Theory, IEEETransactions on , 53(12):4422–4437, Dec. 2007. G. Elidan, I. Mcgraw, and D. Koller. Residual belief propagation: Informed scheduling for asynchronous message passing. In Proceedings of the Twenty-second Conference on Uncertainty in AI (UAI) , Boston, Massachussetts, 2006. A.Y. Ng A. Saxena, S.H. Chung. 3-d depth reconstruction from a single still image. In International Journal of Computer Vision (IJCV) , 2007. SelectLab. ResidualSplash Pairwise MRF code, 2009. URL http://www.select.cs.cmu.edu/code .