The Past, Present, and Future of Speech Processing
advertisement

Speech Coding (Part I)
Waveform Coding
虞台文
Content
Overview
Linear PCM (Pulse-Code Modulation)
Nonlinear PCM
Max-Lloyd Algorithm
Differential PCM (DPCM)
Adaptive PCM (ADPCM)
Delta Modulation (DM)
Speech Coding (Part I)
Waveform Coding
Overview
Classification of Coding schemes
Waveform coding
Vocoding
Hybrid coding
Quality versus Bitrate of Speech Codecs
Waveform coding
Encode the waveform itself in an efficient way
Signal independent
Offer good quality speech requiring a bandwidth of 16 kbps or
more.
Time-domain techniques
–
–
–
Frequency-domain techniques
–
Linear PCM (Pulse-Code Modulation)
Nonlinear PCM: -law, a-law
Differential Coding: DM, DPCM, ADPCM
SBC (Sub-band Coding) , ATC (Adaptive Transform Coding)
Wavelet techniques
Vocoding
‘Voice’ + ‘coding’ .
Encoding information about how the speech signal
was produced by the human vocal system.
These techniques can produce intelligible
communication at very low bit rates, usually below
4.8 kbps.
However, the reproduced speech signal often
sounds quite synthetic and the speaker is often not
recognisable.
LPC-10 Codec: 2400 bps American Military Standard.
Hybrid coding
Combining waveform and source coding methods in
order to improve the speech quality and reduce the
bitrate.
Typical bandwidth requirements lie between 4.8 and
16 kbps.
Technique: Analysis-by-synthesis
–
–
–
–
RELP (Residual Excited Linear Prediction)
CELP (Codebook Excited Linear Prediction)
MPLP (Multipulse Excited Linear Prediction)
RPE (Regular Pulse Excitation)
Quality versus Bitrate of Speech Codecs
Speech Coding (Part I)
Waveform Coding
Linear PCM
(Pulse-Code Modulation)
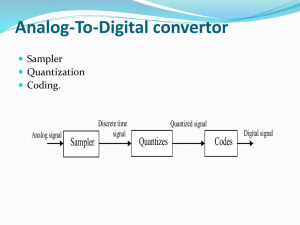
Pulse-Code Modulation (PCM)
A method for quantizing an analog signal for
the purpose of transmitting or storing the
signal in digital form.
Quantization
A method for quantizing an analog signal for
the purpose of transmitting or storing the
signal in digital form.
Linear/Uniform Quantization
Quantization Error/Noise
Quantization Error/Noise
overload
noise
overload
noise
granular noise
Quantization Error/Noise
2 X max
Quantization Step Size
b
2
Quantization Error/Noise
Unquantized
sinewave
3-bit
quantization
waveform
3-bit
quantization
error
8-bit
quantization
error
2 X max
2b
Quantization Step Size
The Model of Quantization Noise
x ( n)
x ( n)
+
2 e(n)
e( n )
x ( n)
+
e( n )
x ( n)
2
x ( n ) x ( n ) e( n )
SQNR
2
signal
2
q -noise
Signal-to-Quatization-Noise Ratio (SQNR)
A measurement of the effect of quantization
errors introduced by analog-to-digital conversion
at the ADC.
2
signal
signal
SQNRdB 10log 2
20 log
q -noise
q -noise
2
signal
signal
SQNRdB 10log 2
20log
q -noise
q -noise
Signal-to-Quatization-Noise Ratio (SQNR)
x ( n ) x ( n ) e( n )
2 e(n)
Assume e(n) ~ U ( 2 , 2 )
2
2
2
X
e2
max2b
12 3 2
x2
3 22b
SQNRdB 10 log 2 10 log
2
e
X max x
10 log 3 20b log 2 20 log
4.77 6.02b 20 log
X max
x
X max
x
2 X max
2b
2
signal
signal
SQNRdB 10log 2
20log
q -noise
q -noise
Signal-to-Quatization-Noise Ratio (SQNR)
x ( n ) x ( n ) e( n )
2 e(n)
Assume e(n) ~ U ( 2 , 2 )
2
2
2
X
e2
max2b
12 3 2
x2
3 22b
SQNRdB 10 log 2 10 log
2
e
X max x
10 log 3 20b log 2 20 log
4.77 6.02b 20 log
X max
x
X max
x
2 X max
2b
2
signal
signal
SQNRdB 10log 2
20log
q -noise
q -noise
Signal-to-Quatization-Noise Ratio (SQNR)
constant
Each code bit
contributes 6dB.
SQNRdB 4.77 6.02b 20 log
The term Xmax/x tells
how
big a signal can be
accurately represented
X max
x
2
signal
signal
SQNRdB 10log 2
20log
q -noise
q -noise
Signal-to-Quatization-Noise Ratio (SQNR)
Determined by
A/D converter.
SQNRdB 4.77 6.02b 20 log
Depending on the distribution
of signal, which, in turn,
depends on users and time.
X max
x
2
signal
signal
SQNRdB 10log 2
20log
q -noise
q -noise
Signal-to-Quatization-Noise Ratio (SQNR)
SQNRdB 4.77 6.02b 20 log
X max
x
Overload Distortion
X max
X max
midtread
X max
X max
midrise
Assume x ~ N (0, )
2
x
Probability of Distortion
x
X max
x
X max
midtread
X max
X max
midrise
Assume x ~ N (0, )
2
x
X max X max 3 x
P(" overlad
")
Probability
of
Distortion
P(" overlad ") 0.0026
x
x
X max
x
X max
midtread
X max
X max
midrise
Assume x ~ N (0, )
2
x
Overload and Quantization Noise with
Gaussian Input pdf and b=4
x
x
e
( dB )
X max
X max
midtread
X max
X max x (dB)
X max
midrise
Uniform Quantizer Performance
Uniform Input Pdf
Gaussian Input Pdf
SQNR
SQNR
(dB)
(dB)
X max x (dB)
X max x (dB)
SQNR 4.77 6.02b 20 log
X max
x
More on Uniform Quantization
Conceptually and implementationally simple.
–
Imposes no restrictions on signal's statistics
–
Maintains a constant maximum error across its total
dynamic range.
x varies so much (order of 40 dB) across sounds,
speakers, and input conditions.
We need a quantizing system where the SQNR is
independent of the signal’s dynamic range, i.e., a
near-constant SQNR across its dynamic range.
Speech Coding (Part I)
Waveform Coding
Nonlinear PCM
Probability Density Functions
of Speech Signals
Counting the number of samples in each interval
provides an estimate of the pdf of the signal.
Probability Density Functions
of Speech Signals
Probability Density Functions
of Speech Signals
Good approx. is a gamma distribution, of the form
1/ 2
3
p( x)
8 x | x |
e
3| x|
2 x
p(0)
Simpler approx. is a Laplacian density, of the form:
1
p( x)
e
2 x
2| x|
x
1
p(0)
2 x
Probability Density Functions
of Speech Signals
Distribution normalized so
that x=0 and x=1•
Gamma density more closely
approximates measured
distribution for speech than
Laplacian.
Laplacian is still a good model
in analytical studies.
Small amplitudes much more
likely than large amplitudes—
by 100:1 ratio.
Companding
The dynamic range of signals is compressed
before transmission and is expanded to the
original value at the receiver.
Allowing signals with a large dynamic range
to be transmitted over facilities that have a
smaller dynamic range capability.
Companding reduces the noise and crosstalk
levels at the receiver.
Companding
x
C ( x)
Compressor
ŷ
y
Uniform
Quantizer
1
C ( x)
Expander
x̂
Companding
x
g ( x)
Compressor
ŷ
y
Uniform
Quantizer
1
g ( x)
Expander
x̂
Companding
x
g ( x)
y
ŷ
1
After compression,
g ( xy)is
x̂
Nearly uniformly distributed
Compressor
Uniform
Quantizer
Expander
The Quantization-Error Variance of
Nonuniform Quantizer
x
g ( x)
ŷ
y
Compressor
Jayant and Noll
Uniform
Quantizer
2
e2
12
1
g ( x)
Expander
X max
X max
p( x)
C ( x)
2
dx
x̂
The Quantization-Error Variance of
Nonuniform Quantizer
x
g ( x)
ŷ
y
Compressor
Jayant and Noll
Uniform
Quantizer
2
e2
12
1
g ( x)
Expander
X max
X max
p( x)
C ( x)
2
dx
x̂
2
2
Jayant and Noll e
12
p( x)
X max
X max
C ( x)
2
dx
The Optimal C(x)
x
g ( x)
y
If the signal’s pdf is known,
ŷ
1
then the minimum g
SQNR,
( x)is x̂
achievable by letting
Compressor
Uniform
Quantizer
C ( x) X max
x
Expander
3
0
X max
0
p( x)dx
3
p( x)dx
2
2
Jayant and Noll e
12
p( x)
X max
X max
C ( x)
2
dx
The Optimal C(x)
x
g ( x)
y
If the signal’s pdf is known,
ŷ
1
then the minimum g
SQNR,
( x)is x̂
achievable by letting
Compressor
Uniform
Quantizer
C ( x) X max
x
Expander
3
0
X max
0
p( x)dx
3
p( x)dx
PDF-Independent
Nonuniform Quantization
Assuming overload free,
x2
SQNR 2 2
e
X max
X max
12
X max
X max
x 2 p ( x)dx
1
C ( x)
2
p ( x)dx
We require that SQNR is independent on p(x).
1
1 2
2 x C ( x) k / x C ( x) k ln x A
2
k
C ( x)
C ( x) k ln x A
Logarithmic Companding
x
g ( x)
ŷ
y
Compressor
Uniform
Quantizer
-Law & A-Law Companding
-Law
–
–
A North American PCM standard
Used by North America and Japan
A-Law
–
–
An ITU PCM standard
Used by Europe
g 1 ( x)
Expander
x̂
x
g ( x)
ŷ
y
Compressor
Uniform
Quantizer
-Law & A-Law Companding
-Law (=255 in U.S. and Canada)
A North American PCM standard
ln 1 | x |
C ( xby
) North America
signand
( x) Japan
–y
Used
ln(1 )
–
A-Law (A=87.56 in Europe)
An ITU PCM
x|
1
A |standard
sign( x)
0 | x |
– Used by Europe
A
1 ln A
y C A ( x)
1 ln A | x | sign( x) 1 | x | 1
1 ln A
A
–
g 1 ( x)
Expander
x̂
x
g ( x)
Compressor
ŷ
y
Uniform
Quantizer
y C ( x )
y C A ( x)
-Law & A-Law Companding
x
x
g 1 ( x)
Expander
x̂
x
g ( x)
ŷ
y
-Law Companding
Compressor
| x|
ln 1
X max
y C ( x) X max
ln(1 )
Uniform
Quantizer
sign( x)
X max
y C ( x )
x ( n) 0 y ( n) 0
x(n) X max y(n) X max
0 y ( n) x ( n)
x ( n)
X max
g 1 ( x)
Expander
x̂
x
ŷ
y
g ( x)
g 1 ( x)
-Law Companding
Compressor
| x|
ln 1
X max
y C ( x) X max
ln(1 )
sign( x)
Uniform
Quantizer
x̂
Expander
z
ln 1 z
ln z
z
1
z
1
X max
y C ( x )
1 | x|
X
max ln X sign( x)
max
C ( x )
X 1 ln | x | sign( x)
max ln X max
x ( n)
X max
| x|
X max
| x|
X max
1
1
x
ŷ
y
g ( x)
g 1 ( x)
-Law Companding
Compressor
| x|
ln 1
X max
y C ( x) X max
ln(1 )
sign( x)
Uniform
Quantizer
x̂
Expander
z
ln 1 z
ln z
z
1
z
1
Linear
X max
y C ( x )
1 | x|
X
max ln X sign( x)
max
C ( x )
X 1 ln | x | sign( x)
max ln X max
Log
x ( n)
X max
| x|
X max
| x|
X max
1
1
x
g ( x)
Compressor
ŷ
y
Uniform
Quantizer
g 1 ( x)
Expander
Histogram for -Law Companding
x(n)
y(n)
x̂
g ( x)
x
Compressor
ŷ
y
Uniform
Quantizer
g 1 ( x)
Expander
-law Approximation to Log
yˆ (n)
Distribution of
quantization level for a
-law 3-bit quantizer.
x ( n)
x̂
SQNR of -law Quantizer
X 2
X max
max
SQNRdB 6.02b 4.77 20log ln(1 ) 10log 1
2
x
x
6.02b dependence on b good
Much less dependence on Xmax/x good
For large SQNR is less sensitive to the
changes in Xmax/x good
Linear
SQNRdB 6.02b 4.77 20 log
X max
x
Comparison of
Linear and -law Quantizers
X 2
X max
max
SQNRdB 6.02b 4.77 20log ln(1 ) 10log 1
2
x
x
A-Law Companding
1
A| x|
0 | x |
1 ln A sign( x)
A
y C A ( x)
1 ln A | x | sign( x) 1 | x | 1
1 ln A
A
A-Law Companding
Linear
1
A| x|
0 | x |
1 ln A sign( x)
A
y C A ( x)
1 ln A | x | sign( x) 1 | x | 1
1 ln A
A
Log
y C A ( x)
y C ( x )
A-Law Companding
x
x
SQNR of A-Law Companding
SQNRdB 6.02b 4.77 20log(1 A)
Demonstration
PCM Demo
Speech Coding (Part I)
Waveform Coding
Max-Lloyd
Algorithm
Q(x): Quantization (Reconstruction) Level
How to design a nonuniform quantizer?
Q(x)
ck
qk
qk1
xk qk xk 1
ck1
qk
xk1 xk
xk+1
x
Q(x): Quantization (Reconstruction) Level
How to design a nonuniform quantizer?
Q(x)
qk1
xk qk xk 1
?
ck1
qk
xk1 xk
?
?
ck
qk
xk+1
x
How to design a nonuniform quantizer?
Major tasks:
1. Determine the decision thresholds xk’s
2. Determine the reconstruction levels qk’s
Related task:
3. Determine codewords ck’s
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
Optimal Nonuniform Quantization
Major tasks:
1. Determine the decision thresholds xk’s
2. Determine the reconstruction levels qk’s
An optimal quantizer is the one that minimizes the
following quantization-error variance.
E X Q( X )
2
e
2
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
Optimal Nonuniform Quantization
2
E X Q( X ) e( x) p( x)dx
2
2
e
N
k 1
xk 1
xk
x qk
2
p( x)dx
N
*
1
(x ,
*
N
*
1
, x ,q ,
, q ) arg min
*
N
x1 xN
q1 qN
k 1
xk 1
xk
x qk
2
p( x)dx
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
Necessary Conditions for an Optimum
e2
0
qk
leads to the “centroid” condition
e2
0
xk
leads to the “nearest neighborhood” condition
N
*
1
(x ,
*
N
*
1
, x ,q ,
, q ) arg min
*
N
x1 xN
q1 qN
k 1
xk 1
xk
x qk
2
e2
p( x)dx
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
Necessary Conditions for an Optimum
e2
0
qk
leads to the “centroid” condition
xk 1
qk
e2
0
xk
xk
xk 1
xk
xp( x)dx
, k 1,
,N
p( x)dx
leads to the “nearest neighborhood” condition
qk 1 qk
xk
,
2
k 1,
,N
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
Optimal Nonuniform Quantization
e2
0
qk
leads to the “centroid” condition
xk 1
qk
e2
0
xk
xk
xk 1
xk
xp( x)dx
, k 1,
,N
p( x)dx
leads to the “nearest neighborhood” condition
qk 1 qk
xk
,
2
k 1,
,N
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
The Max-Lloyd algorithm
1.
Initialize a set of decision levels {xk} and set e2
xk 1
2.
Calculate reconstruction levels {qk} by qk
xk
xk 1
xk
xk 1
xp( x)dx
p( x)dx
x qk p( x)dx
3.
Calulate mse by
4.
2
2
If e e , exit.
5.
Set e2 e2 and adjust decision levels {xk} by xk
6.
Go to 2
2
e
xk
2
qk 1 qk
2
ck2
ck1
ck
ck+1
ck+2
ck+3
qk2
qk1
qk
qk+1
qk+2
qk+3
xk2
xk1
xk
xk+1
xk+2
xk+3
xk+4
The Max-Lloyd algorithm
1.
Initialize a set of decision levels {xk} and set e2
xk 1
2.
3.
Calculate reconstruction levels {qk} by qk
Calulate mse by
2
e
x x qk
xk 1
2
xk
xk 1
xk
xp( x)dx
p( x)dx
p( x)dx
k
4.
2
2
If e e , exit.
5.
Set e2 e2 and adjust decision levels {xk} by xk
6.
Go to 2
qk 1 qk
2
The Max-Lloyd algorithm
(Practical Version)
Exercise
Speech Coding (Part I)
Waveform Coding
Differential PCM
(DPCM)
Do you find any correlation and/or
redundancy among the samples?
Typical Audio Signals
0.25
0.2
0.15
A segment of audio signals
0.1
0.05
0.6
0
0.4
0.2
-0.05
0
-0.1
-0.2
-0.15
-0.4
-0.2
-0.6
-0.8
1250 1300 1350 1400 1450 1500 1550 1600 1650 1700 1750
0
500
1000
1500
2000
2500
The Basic Idea of DPCM
Adjacent samples exhibit a high degree of
correlation.
Removing this adjacent redundancy before
encoding, a more efficient coded signal can
be resulted.
How?
–
Accompanying with prediction (e.g., linear prediction)
–
Encoding prediction error only
Linear Prediction
p
sˆ(n) ak s(n k )
sˆ( n)
k 1
e(n) s (n) sˆ(n)
n1
np
n2
p
s (n) ak s (n k )
n3
k 1
N
E p e 2 ( n)
n 1
a* arg min E p
a
a (a1 ,
, a p )
s (n)
Linear Predictor
p
sˆ(n) ak s(n k )
k 1
s (n)
Predictor
sˆ( n)
s (n)
Predictor
Predictor
sˆ( n)
DPCM Codec
e( n )
s (n)
+
Quantizer
sˆ(n) sˆ ( n)
+
Predictor
Channel
e ( n ) e( n )
+
s ( n) s ( n)
s ( n) s ( n)
e ( n)
+
A/D
converter
+
sˆ ( n)
Channel
Predictor
The dynamic range of prediction
error is much smaller than the
DPCM Codec
signal’s.
Less quantization levels needed
e( n )
s (n)
+
Quantizer
sˆ(n) sˆ ( n)
+
Predictor
Channel
e ( n ) e( n )
+
s ( n) s ( n)
s ( n) s ( n)
e ( n)
+
A/D
converter
+
sˆ ( n)
Channel
Predictor
Performance of DPCM
By using a logarithmic compressor and a 4bit quantizer for the error sequence e(n),
DPCM results in high-quality speech at a
rate of 32,000 bps, which is a factor of two
lower than logarithmic PCM
Speech Coding (Part I)
Waveform Coding
Adaptive PCM
(ADPCM)
( n) ( n)
Basic Concept
The power level in a speech signal varies
slowly with time.
(n)
Let the quantization step dynamically adapt
to the slowly time-variant power level.
Adaptive Quantization Schemes
Feed-forward-adaptive quantizers
–
estimate (n) from x(n) itself
–
step size must be transmitted
Feedback-adaptive quantizers
–
adapt the step size, , on the basis of the
quantized signal xˆ (n)
–
step size needs not to be transmitted
Feed Forward Adaptation
x ( n)
Quantizer
Step-Size
Adaptation
System
c (n)
(n)
xˆ (n)
Encoder
(n)
(n)
Decoder
c (n)
xˆ (n)
The source signal is not available
at receiver. So, the receiver
can’t evaluate (n) by itself.
Feed Forward Adaptation
x ( n)
Quantizer
Step-Size
Adaptation
System
c (n)
(n)
xˆ (n)
Encoder
c (n)
(n)
(n)
(n) has to be transmitted.
Decoder
xˆ (n) x(n)
Quantization error
e(n) xˆ (n) x(n)
(n) 0 (n)
The Step-Size Adaptation System
x ( n)
Quantizer
Step-Size
Adaptation
System
xˆ (n)
Encoder
c (n)
(n)
(n)
(n) has to be transmitted.
2(n),
Estimate
signal’s
short-time
energy,
c (n)
xˆ (n) x(n)
Decoder
and make (n) (n).
Quantization error
(n)
e(n) xˆ (n) x(n)
(n) 0 (n)
The Step-Size Adaptation System
Low-Pass Filter Approach
2 ( n)
n
h(n) n , n 0,0 1
x 2 ( m) h ( n m )
m
n
nm 2
x ( m)
m
n 1
n 1
nm 2
2
x
(
m
)
x
( n)
m
n m 1 2
2
x
(
m
)
x
( n)
m
2 (n 1) x 2 (n)
(n) 0 (n)
The Step-Size Adaptation System
Low-Pass Filter Approach
= 0.99
= 0.9
(n) 0 (n)
The Step-Size Adaptation System
Moving Average Approach
n
( n)
2
x ( m) h ( n m)
2
m n M 1
1
M
n
m n M 1
x 2 ( m)
1
h( n) , 0 0 M 1
M
1
( n)
M
2
n
x 2 ( m)
m n M 1
(n) 0 (n)
Feed-Forward Quantizer
(n) evaluated every M Samples
Use M=128, 1024 for estimates
Suitable choosing of min and max
1
( n)
M
2
n
x 2 ( m)
m n M 1
(n) 0 (n)
Feed-Forward Quantizer
(n) evaluated every M Samples
Use M=128, 1024 for estimates
Suitable choosing of min and max
Too
long
(n) can be evaluated at both sides using the same
alogorithm. Hence, it needs not to be transmitted.
Feedback Adaptation
x ( n)
Quantizer
xˆ (n)
Encoder
c (n)
Step-Size
Adaptation
System
(n)
Decoder
c (n)
Step-Size
Adaptation
System
(n)
xˆ (n)
The same as feed-forward adaptation
except that the input changes.
The Step-Size Adaptation System
x ( n)
Quantizer
xˆ (n)
Encoder
c (n)
Step-Size
Adaptation
System
(n)
Decoder
c (n)
Step-Size
Adaptation
System
(n)
xˆ (n)
Alternative Approach to Adaptation
(n) P(n) (n 1)
P(n){P1, P2, …} depends on c(n1).
Needs to impose the limits
min (n) max
The ratio max/min controls the
dynamic range of the quantizer.
Alternative Approach to Adaptation
(n) P(n) (n 1)
P(n){P1, P2, …} depends on c(n1).
Needs to impose the limits
P1
P2
P3
P4
P5
P
P67
P8
min (n) max
The ratio max/min controls the
dynamic range of the quantizer.
Alternative Approach to Adaptation
Speech Coding (Part I)
Waveform Coding
Delta
Modulation
(DM)
Delta Modulation
Simplest form of DPCM
–
The prediction of the next is simply the current
Sampling rate chosen to be many times (e.g., 5) the
Nyquist rate, adjacent samples are quite correlated,
i.e., s(n)s(n1).
–
1-bit (2-level) quantizer is used
–
Bit-rate = sampling rate
Review DPCM
e( n )
s (n)
+
Quantizer
sˆ(n) sˆ ( n)
+
Predictor
Channel
e ( n ) e( n )
+
s ( n) s ( n)
s ( n) s ( n)
e ( n)
+
A/D
converter
+
sˆ ( n)
Channel
Predictor
DM Codec
e( n )
s (n)
+
e ( n) 1
Quantizer
sˆ ( n)
+
Predictor
z1
Channel
+
s ( n)
Channel
s ( n)
e ( n)
+
+
sˆ ( n)
Predictor
z1
A/D
converter
Distortions of DM
T
step size
time
0
1
1
1
1
1
0
0
1 e(n) 1
code words: c(n)
0 e(n) 1
0
0
1
0
0
1
0
Distortions of DM
slope overload
condition
step size
T
granular noise
time
0
1
1
1
1
1
0
0
1 e(n) 1
code words: c(n)
0 e(n) 1
0
0
1
0
0
1
0
Choosing of Step Size
time
Needs large
step size
Needs small
step size
Adaptive DM (ADM)
time
(n) (n 1) K
e ( n ) e ( n 1)
(n) (n 1) K
e ( n ) e ( n 1)
Adaptive DM (ADM)
K 2